在短时间内,我们的团队从十几名员工到了近200名员工的整个团队,我们希望分享这条道路上的一些里程碑。 另外,我们将讨论现在大数据究竟需要谁以及什么是真正的入门门槛。

在新领域取得成功的秘诀
处理大数据是一个相对较新的技术领域,就像所有事物一样,它随着发展而经历了成长的周期。
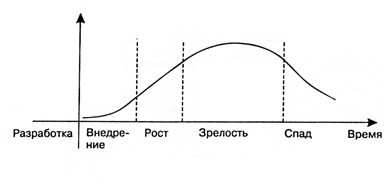
从特定专家的角度来看,此周期每个阶段在技术领域中的工作都有其优点和缺点。
阶段1.实施在第一阶段,这是研发部门的产物,但仍未提供实际利润。
从专家那里:很多钱都投入了。 除投资外,人们对于解决以前无法完成的任务并获得投资回报的希望也越来越高。
缺点:任何技术,不管它在一开始的前景如何,都有其自身的局限性:它不能用来消除所有存在的问题。 随着采用新想法的实验的进行,这些限制得以揭示,这导致了所谓的“高期望峰”之后对技术的兴趣降温。
第二阶段。成长真正的腾飞将只针对那些将克服由于其实际功能而不是营销噪音而导致的失望失望的技术。
优点:现阶段,技术吸引了长期投资:不仅是金钱,而且是劳动力市场专家的时间。 当很明显这不仅是炒作,而且是一种新方法甚至是一个细分市场时,是时候让专家融入“趋势”了。 这是掌握职业发展方面有希望的技术的理想时机。
缺点:在现阶段,该技术的文献还很少。
第三阶段。成熟的技术是市场的真正动力。
优点:随着年龄的增长,累积的文档数量会增加,还会出现培训和课程,因此更容易进入该技术。
缺点:与此同时,劳动力市场的竞争正在加剧。
阶段4.经济衰退下降阶段(日落)发生在所有技术中,尽管它们继续起作用。
优点:至此,该技术已得到充分描述,界限很明确,有大量文档和课程可供选择。
缺点:从获取新知识和新前景的角度来看,它不再那么有吸引力。 实际上,这是伴奏。
成长阶段对每个想要开始新技术领域工作的人都是最有吸引力的:年轻的专家和相关领域已经建立的专业人员。
大数据的开发现在才刚刚开始。 寄予厚望。 商业已经证明大数据可以获利,因此未来的生产力将达到稳定状态。 此刻为劳动力市场的专家提供了绝佳的机会。
我们的故事大数据在任何一家公司中引入技术实质上都会重复整个成长过程。 我们在这里的经验很典型。
一年半以前,我们开始在X5中建立大数据团队。 那时只有一小撮关键专家,现在我们有将近200名。
我们的项目团队经历了几个发展阶段,在此期间我们对角色和任务有了更深入的了解。 因此,我们拥有自己的团队格式。 我们选择了敏捷方法。 主要思想是团队具有解决问题的全部能力,而他们在专家之间的准确分配并不那么重要。 在此基础上,考虑到技术的发展,逐渐形成了团队角色的组成。 现在我们有:
- 产品负责人(产品负责人)-了解主题领域,制定总体业务构想并预测如何将其货币化。
- 业务分析师(业务分析师)-正在执行此任务。
- 数据质量(数据质量专家)-检查是否可以使用现有数据来解决问题。
- 直接进行数据科学/数据分析师(数据科学家/数据分析师)-建立数学模型(存在不同的亚种,包括仅适用于电子表格的亚种)。
- 测试经理。
- 开发者
在我们的案例中,所有团队都使用基础架构和数据,并且将以下角色作为服务实现: - 基础设施
- ETL(数据加载命令)。
 我们是如何来到梦之队的
我们是如何来到梦之队的
梦想不是梦想,但是,正如我所说,团队的组成因大数据分析的成熟及其在X5和我们的分销网络的日常生活中的渗透而发生了变化。
“快速入门” -最低角色,最高速度
第一小组仅包括两个角色:
- 产品负责人提出了一个模型,提出了建议。
- 数据分析师-根据现有数据收集统计信息。
一切都在业务中快速计划并手动实施。
“我们是这样认为的吗?” -我们学会了了解业务并产生最有用的结果
与业务互动出现了新角色:
- 业务分析师-描述的流程要求。
- 数据质量-进行了数据一致性检查。
- 根据任务,数据分析师/数据科学家在本地工作站上分析数据统计/执行模型计算。
“需要更多资源” -本地计算任务移至集群并开始接触外部系统
要支持所需的缩放:
- 引发HADOOP服务器的基础结构。
- 开发人员-他们实现了与外部IT系统的集成,并在此阶段自己检查了用户界面。
现在,数据分析师/数据科学家可以检查几个选项来计算集群上的模型,尽管仍然保留了业务中的手动实施。
“负载继续增长” -出现新数据,需要新的容量来处理它们
这些更改无法反映在团队中:
- 基础架构在不断增长的负载下开发了HADOOP集群。
- ETL团队开始定期进行数据下载和更新。
- 功能测试已经出现。
“万物自动化” -技术已扎根,是时候实现业务自动化
在这个阶段,DevOps出现在团队中,该团队设置了自动组装,测试和安装功能。
团队建设的关键思想1.如果从一开始就没有合适的专家,那么我们可以组建一支团队,这并不是事实,这一切都会奏效。 这是肌肉开始生长的骨骼。
2.大数据市场是完全绿色的,因此每个角色没有足够的“现成”专家。 当然,招募整个高级部门很方便,但是,显然,这样的“明星”团队不能建立太多。 我们决定不只追逐“现成的”人员。 正如我们提到的,坚持敏捷,我们应该只关心整个团队具有解决特定问题的能力。 换句话说,我们可以聘用(和接受)具有一定技术和数学基础的团队专业人士和初学者,以便他们共同形成一组获得所需结果所需的能力。
3.每个角色都意味着对使用大数据的原理的理解,但是需要这种理解的深度。 在经典开发中具有直接类比的角色(测试人员,分析人员等)最大的可变性 对于他们来说,有些任务几乎不属于大数据,而您需要更深入地研究。 一种或另一种方式来开始职业,一定的经验,对IT的理解,对学习的渴望以及有关所使用工具的一些理论知识(可以通过阅读文章获得)就足够了。
4.实践表明,尽管该技术是众所周知的,并且许多人都愿意这样做,但并不是每一个适合于在大数据领域开始职业生涯(并愿意在那工作的人)的专家都真正尝试来到这里。 。
许多优秀的候选人认为,在BigData团队中工作完全是数据科学。 什么是进入门槛高的基本活动变化。 但是,他们低估了自己的能力,或者根本不知道大数据需要各种档案的人,因此,担任上述任职的其他职位将更容易开始职业。
一个 实际上,要开始在多个角色的混合团队中工作,您不需要在大数据领域进行狭narrow的专业培训。
b。 我们秉承建造混合结构单元的想法,积极扩展团队。 最有趣的是,完成我们任务的人员,以前从未使用过大数据,在应付任务后完美地扎根于公司。 他们能够快速学习大数据的实践。
5.即使没有很多经验,您也可以更深入地学习,学习必要的语言和工具,并有动力在这一领域中成长,以便处理项目中更多的战略任务。 积累的经验有助于转而担任大数据所需知识并理解该方向逻辑的那些角色。 顺便说一句,从这个意义上说,混合团队为加速发展提供了很多帮助。
如何进入BigData?
在我们的案例中,由不同级别的专家组成的均衡团队的想法“开始了”-该小组已经实施了多个内部项目。 在我看来,由于现成的人员短缺,并且对于这类团队的业务需求也在增加,其他公司也会遇到同样的情况。
如果您真的想选择这个方向,那么将自己投入到Data Sciense中-Kaggle,ODS和其他专业资源将为您提供帮助。 此外,如果在不久的将来您看不到自己扮演数据科学家的角色,但是您对自身的发展方向感兴趣,那么大数据仍然需要您!
增加价值:
- 更新您的数学知识。 为了解决大数据的普通问题,不需要博士学位,但是仍然需要高等数学的基础知识。 了解统计信息的基础机制后,您将更容易了解流程。
- 选择最接近您当前专业的角色。 找出您在此职位(以及您想去的特定公司)中将面临的挑战。 而且,如果您以前解决过类似的问题,则应在简历中强调这些问题;
- 特定于所选角色的工具非常重要,即使这似乎与大数据无关。 例如,在开发内部解决方案时,事实证明,我们需要大量使用复杂接口的前端开发人员。
- 请记住,市场正在积极发展。 有人在内部组建和抽水,而有人希望在劳动力市场上找到现成的专家。 如果您是初学者,请尝试加入一支强大的团队,在那里将有机会获得更多的知识。
PS顺便说一句,目前,我们正在继续积极发展,并正在寻找
数据工程师 ,
测试专家 ,
React开发人员和
UI / UX专家 。 在5月10日至11日,我们将与大家在
DataFest展位上讨论#bigdatax5中的工作。