有几种了解口语语音机器的方法:经典的三组件方法(包括语音识别组件,自然语言理解组件和负责某种业务逻辑的组件)和End2End方法,涉及四个实现模型:直接,协作,多阶段和多任务。 让我们考虑一下这些方法的所有优缺点,包括基于Google实验的优缺点,并详细分析End2End方法为何解决了经典方法的问题。

我们请AI MTS中心Nikita Semenov的领先开发人员发言。
你好 作为序言,我想引用著名的科学家Jan Lekun,Joshua Benjio和Jeffrey Hinton-这是人工智能的三位先驱,他们最近获得了信息技术领域最负盛名的奖项之一-图灵奖。 在2015年《自然》杂志的其中一期中,他们发表了一篇非常有趣的文章“深度学习”,其中有一个有趣的短语:“深度学习伴随着它有能力处理原始信号而无需手工制作的功能。” 很难正确地翻译它,但是含义是这样的:“深度学习带来了应付原始信号的能力,而无需手动创建信号的希望。” 我认为,对于开发人员而言,这是所有现有开发人员的主要动力。
经典方法
因此,让我们从经典方法开始。 当我们谈论理解使用机器讲话时,是指我们有一个人想要借助他的声音来控制某些服务,或者感到需要某种系统以某种逻辑来响应他的声音命令。
这个问题如何解决? 在经典版本中,使用了一个系统,如上所述,它由三个大组件组成:语音识别组件,用于理解自然语言的组件以及负责某种业务逻辑的组件。 显然,首先,用户创建了某个声音信号,该声音信号落在语音识别组件上并从声音转换为文本。 然后,文本进入理解自然语言的组件,从中提取出某种语义结构,这对于负责业务逻辑的组件是必需的。
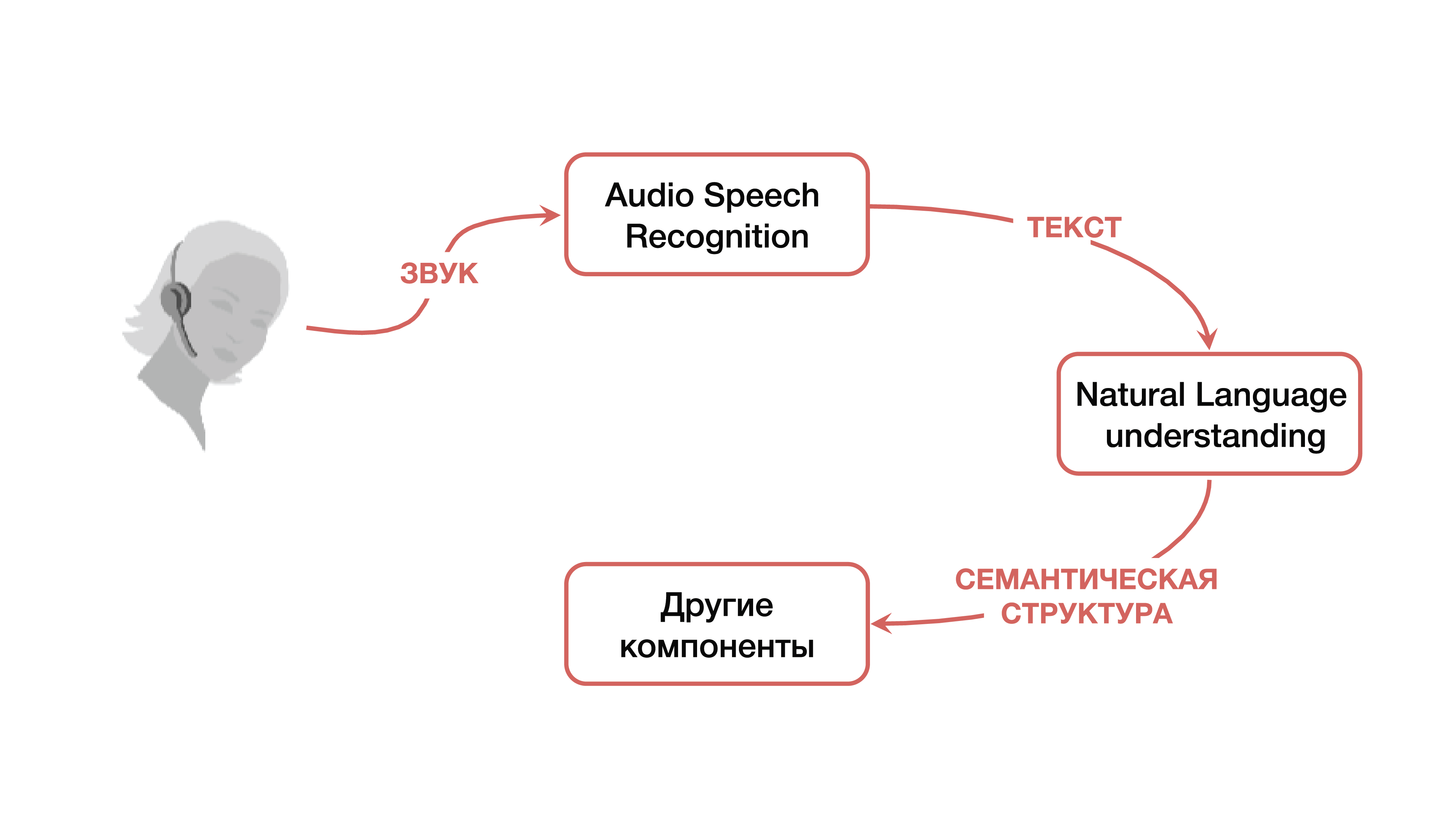
什么是语义结构? 这是将几项任务概括/聚合为一种-为了易于理解。 该结构包括三个重要部分:领域的分类(主题的某种定义),意图的分类(理解需要完成的工作)以及命名实体的分配,以填写下一阶段特定业务任务所需的卡片。 要了解什么是语义结构,可以考虑一个简单的示例,该示例是Google最常引用的示例。 我们有一个简单的要求:“请播放某些歌手的歌曲。”

此请求中的领域和主题是音乐; 目的-播放歌曲; “播放歌曲”卡的属性-哪种歌曲,哪种艺术家。 这种结构是理解自然语言的结果。
如果我们要讨论解决理解口语语音的复杂且多阶段的问题,那么正如我所说,它包括两个阶段:第一个阶段是语音识别,第二个阶段是理解自然语言。 经典方法涉及这些阶段的完全分离。 第一步,我们有一个确定的模型,该模型在输入端接收声音信号,并在输出端使用语言和声音模型以及词典,从该声音信号中确定最可能的言语假设。 这是一个完全概率的故事-可以根据众所周知的贝叶斯公式将其分解,并获得一个公式,该公式可让您编写样本的似然函数并使用最大似然法。 假设单词序列W乘以该单词序列的概率,我们就有信号X的条件概率。

我们经历的第一阶段-我们从声音信号中得到了一个口头假设。 接下来是第二个组件,它采用了这种非常口头的假设,并试图提出上述语义结构。
如果语言序列W在输入处,我们就有语义结构S的可能性。

由这两个要素/步骤组成的经典方法的坏处是什么,这两个要素/步骤是分开教授的(即我们首先训练第一个要素的模型,然后训练第二个要素的模型)?
- 自然语言理解组件可与ASR生成的高级口头假设一起使用。 这是一个很大的问题,因为第一个组件(ASR本身)使用低级别的原始数据并生成高级的语言假设,而第二个组件则将假设作为输入-不是原始来源的原始数据,而是第一个模型给出的假设-并建立了其假设。在第一阶段的假设。 这是一个相当有问题的故事,因为它变得太“有条件”了。
- 下一个问题:建立语义结构所必需的单词的重要性与构建我们的言语假设时第一个成分所喜欢的词之间没有任何联系。 也就是说,如果您改写,我们就会得出假设已经建立。 正如我所说的那样,它是基于三个组成部分构建的:声学部分(进入输入并以某种方式建模的部分),语言部分(完全建模任何语言的字母-语音的可能性)和词典(单词的发音)。 这是需要组合的三个大部分,并且在其中找到了一些假设。 但是没有办法影响相同假设的选择,因此该假设对于下一阶段很重要(原则上,这是因为他们完全独立地学习并且不会以任何方式相互影响)。
End2End方法
我们了解经典方法是什么,它有什么问题。 让我们尝试使用End2End方法解决这些问题。
通过End2End,我们的意思是一个将各种组件组合为单个组件的模型。 我们将使用由包含注意(注意)模块的编码器-解码器体系结构组成的模型进行建模。 这种体系结构通常用于语音识别问题和与自然语言处理有关的任务,尤其是机器翻译。
实施此类方法有四种选择,可以解决经典方法摆在我们面前的问题:这是直接,协作,多阶段和多任务的模型。
直接模型
直接模型采用输入的低层原始属性,即 低级音频信号,并在输出处立即获得语义结构。 也就是说,我们获得了一个模块-经典方法的第一个模块的输入和相同经典方法的第二个模块的输出。 就是这样的“黑匣子”。 从这里开始有一些优点和缺点。 该模型不会学习完全转录输入信号-这是一个明显的优点,因为我们不需要收集大而又大的标记,我们不需要收集大量的音频信号,然后将其提供给访问器进行标记。 我们只需要此音频信号和相应的语义结构。 仅此而已。 这多次减少了标记数据的工作量。 这种方法最大的缺点可能是任务对于这样的“黑匣子”来说太复杂了,黑匣子试图立即有条件地解决两个问题。 首先,他在自己内部尝试建立某种转录,然后从该转录中揭示出非常语义的结构。 这提出了一个相当困难的任务-学习忽略转录的某些部分。 这是非常困难的。 这个因素是此方法的一个相当大而巨大的缺点。
如果我们讨论概率,那么该模型解决了从具有模型参数θ的声学信号X中找到最可能的语义结构S的问题。
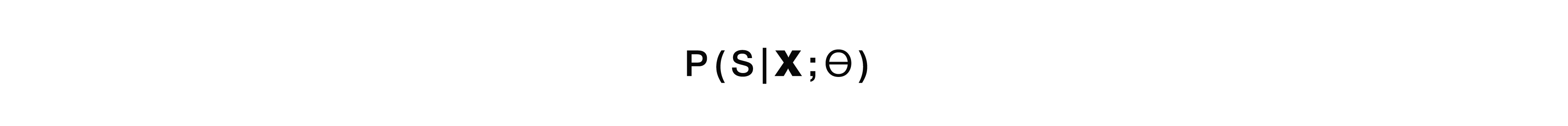
联合模型
有什么选择? 这是一个协作模型。 也就是说,某些模型与直线非常相似,但是有一个例外:我们的输出已经由语言序列组成,并且语义结构只是连接到它们。 也就是说,在输入处我们有一个声音信号和一个神经网络模型,在输出处已经给出了语言转录和语义结构。
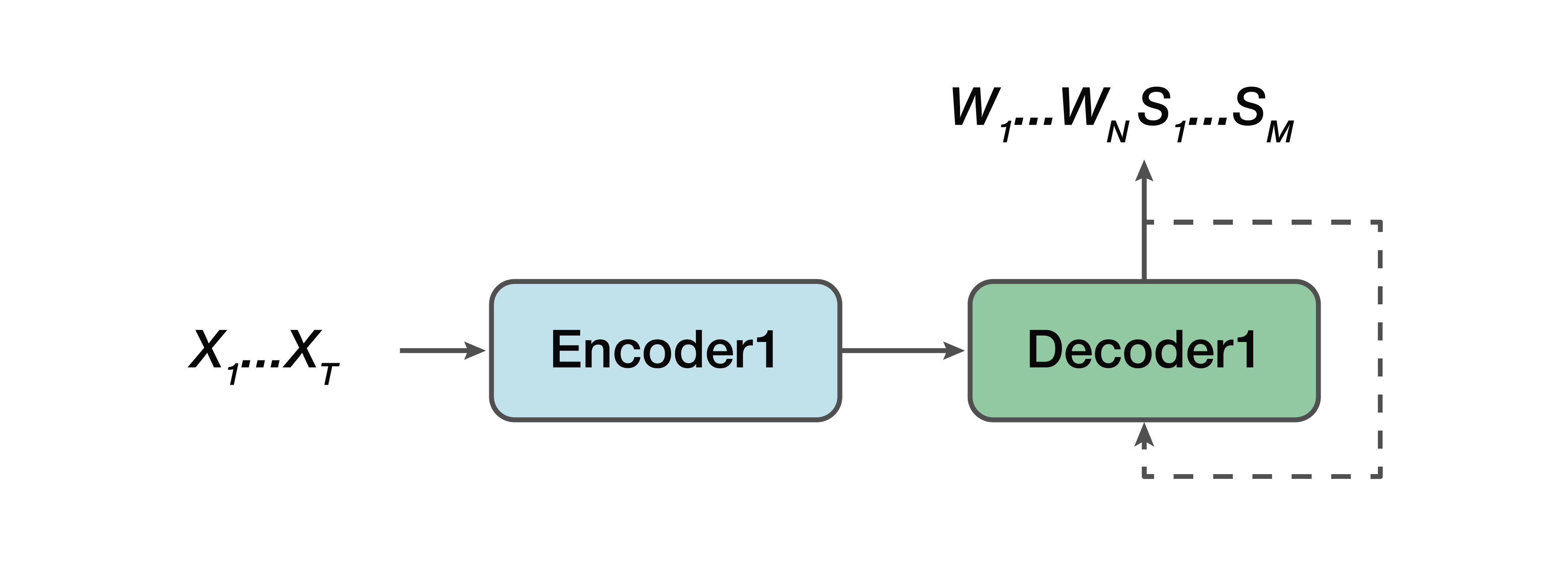
优点:我们仍然有一个简单的编码器,一个简单的解码器。 因为该模型不会像直接模型那样一次尝试解决两个问题,所以有助于学习。 另一个优点是,仍然存在语义结构对低级声音属性的这种依赖性。 因为又是一个编码器,一个解码器。 并且,因此,有一个优点是可以预见到这种语义结构及其对转录本身的影响的预测存在依赖性-这在经典方法中不适合我们。
再次,我们需要从带有参数θ的声音信号X中找到单词W的最可能序列和相应的语义结构S。
多任务处理模型
下一种方法是多任务模型。 同样,采用编码器-解码器方法,但有一个例外。
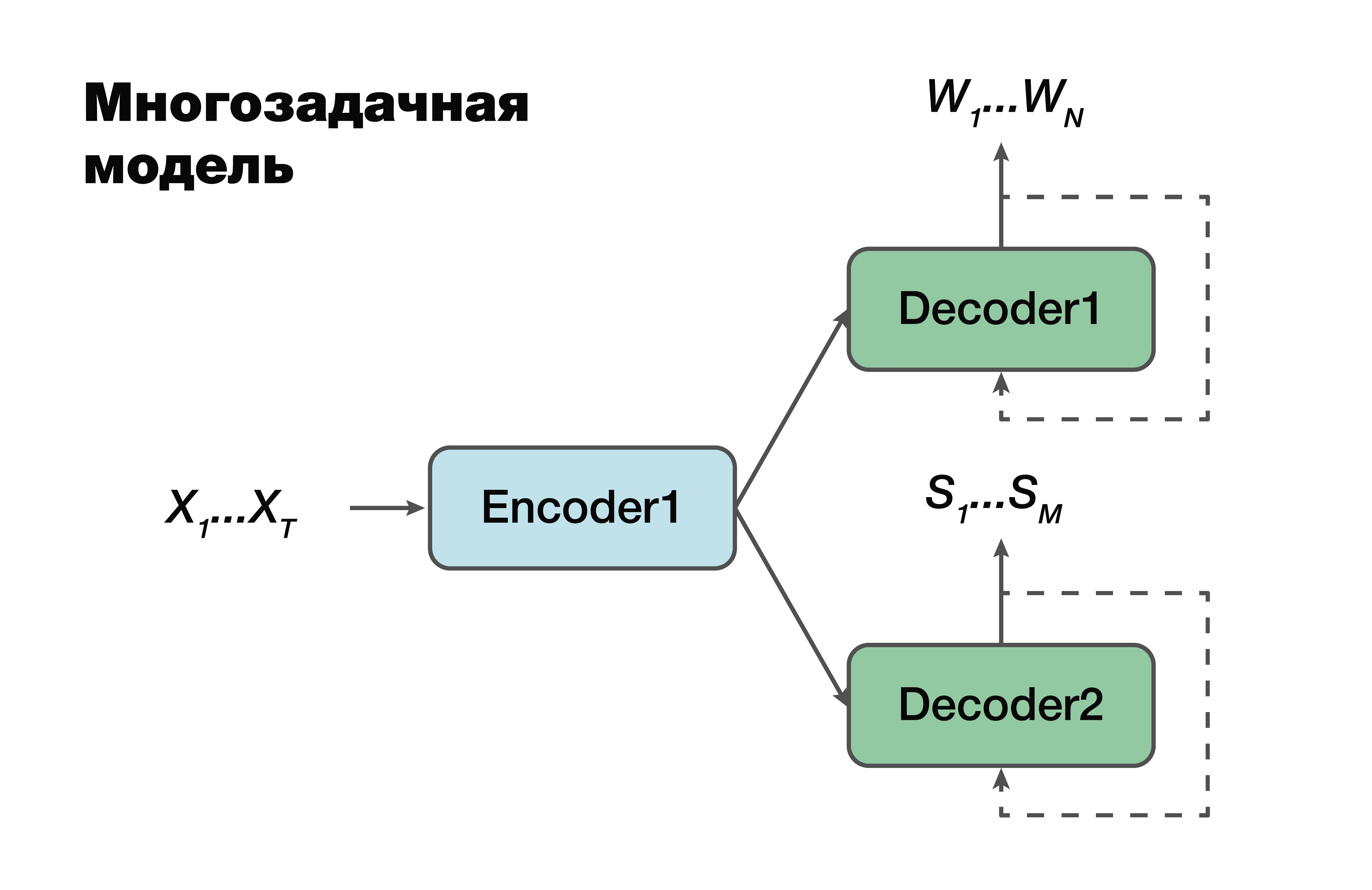
对于每个任务,即创建语言序列,创建语义结构,我们都有自己的解码器,该解码器使用一个常见的隐藏表示形式生成单个编码器。 机器学习中的一个非常著名的技巧,经常在工作中使用。 一次解决两个不同的问题有助于更好地查找源数据中的依存关系。 因此,这是最佳的泛化能力,因为一次为多个任务选择了最佳参数。 此方法最适合于数据量较少的任务。 解码器使用编码器在其中创建的一个隐藏矢量空间。

重要的是要注意,已经有可能依赖于编码器和解码器模型的参数。 这些参数很重要。
多阶段模型
我认为,我们将转向最有趣的方法:多阶段模型。 如果仔细看,您会发现实际上这是相同的两部分经典方法,但有一个例外。
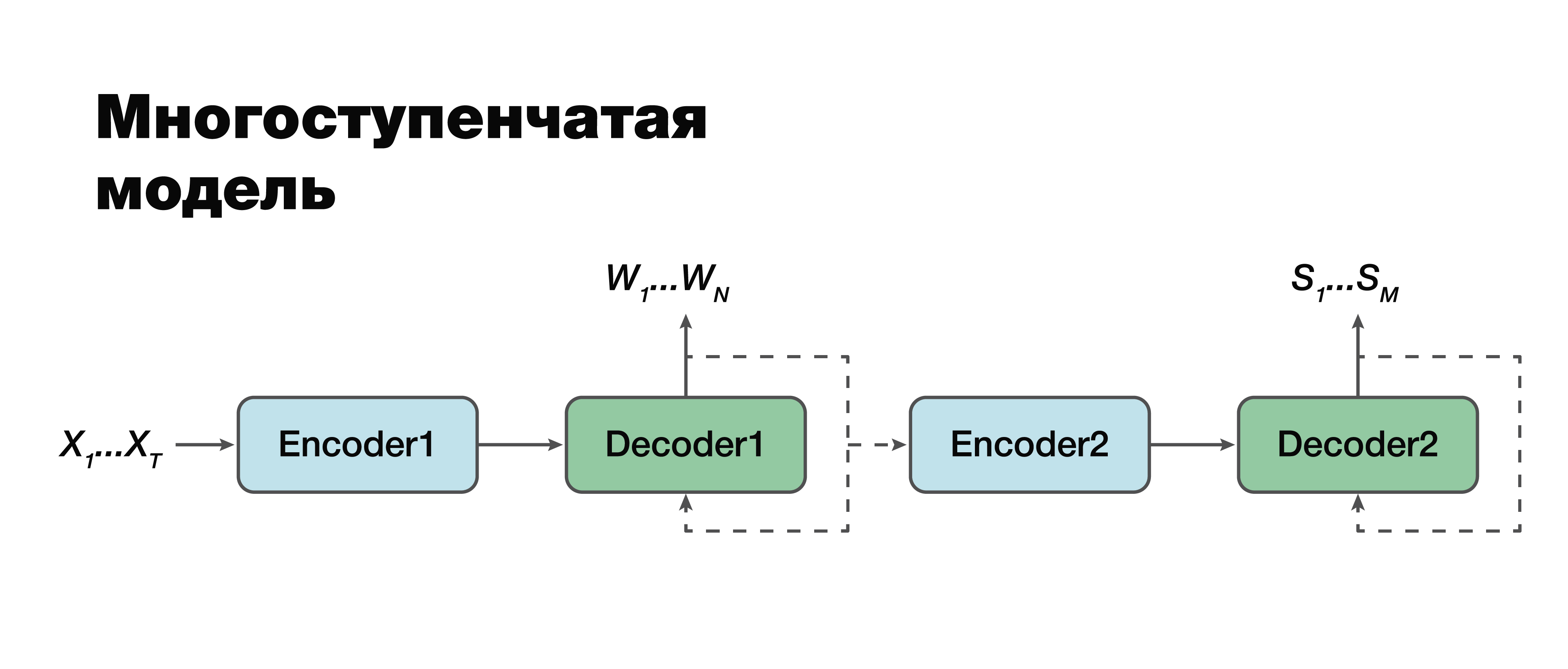
在这里可以在模块之间建立连接并使它们成为单模块。 因此,认为语义结构有条件地取决于转录。 使用此模型有两个选择。 我们可以分别训练这两个迷你块:第一个和第二个编码器-解码器。 或将它们组合在一起并同时训练两个任务。
在第一种情况下,两个任务的参数不相关(我们可以使用不同的数据进行训练)。 假设我们有大量的声音以及相应的言语序列和转录。 我们“驾驶”它们,我们只训练第一部分。 我们进行了良好的转录模拟。 然后,我们进行第二部分,在另一个案例上进行训练。 我们连接并得到一个解决方案,该解决方案采用这种方法与经典方法100%一致,因为我们分别接受并训练了第一部分,并分别训练了第二部分。 然后,我们在该案例上训练了连接的模型,该模型已经包含三元组数据:音频信号,相应的转录和相应的语义结构。 如果我们有这样的建筑物,我们可以针对特定的小型任务重新训练在大型建筑物上进行单独训练的模型,并以这种棘手的方式获得最大的准确性。 这种方法使我们能够通过
考虑第一阶段中第二阶段
的错误,来
考虑转录不同部分的重要性及其对语义结构预测的影响。
重要的是要注意,最终任务与经典方法非常相似,只是有一个很大的不同:我们函数的第二项-语义结构的概率的对数-假设输入声信号X也取决于
第一阶段模型的参数。

同样重要的是,这里的第二部分取决于第一模型和第二模型的参数。
评估方法准确性的方法
现在,应该确定评估准确性的方法了。 实际上,如何测量这种准确性以考虑经典方法中不适合我们的特征? 这些单独的任务都有经典的标签。 要评估语音识别组件,我们可以采用经典的WER指标。 这是一个字错误率。 我们根据一个不是很复杂的公式来考虑一个单词的插入,替换,排列的数量,然后将它们除以所有单词的数量。 并且我们得到了我们认可质量的某种估计特征。 对于语义结构而言,我们可以简单地考虑F1分数。 这也是分类问题的一些经典指标。 在这里,所有的正负都是清楚的。 有充实,有准确性。 这只是它们之间的谐波平均值。
但是,当输入转录和输出自变量不匹配或输出为音频数据时,出现了一个问题,即如何测量准确性。 Google提出了一种指标,该指标将通过评估语音识别的第一部分对第二部分本身的影响来考虑预测语音识别的第一部分的重要性。 他们称其为Arg WER,也就是说,它将WER权衡在语义结构实体上。
接受请求:“将闹钟设置为5个小时。” 此语义结构包含一个参数,例如“五个小时”,类型为“日期时间”。 重要的是要理解,如果语音识别组件生成此自变量,则该自变量的误差度量(即WER)为0%。 如果此值不对应五个小时,则该度量标准具有100%WER。 因此,我们仅考虑所有自变量的加权平均值,并且一般而言,获得某种聚合度量,该度量可以估计创建语音识别组件的转录错误的重要性。
让我举一个Google在该主题研究中进行的实验示例。 他们使用了来自五个领域,五个主题的数据:媒体,媒体控制,生产力,愉悦性,无-与训练测试数据集上的数据对应分布。 重要的是要注意,所有模型都是从头开始训练的。 使用了Cross_entropy,波束搜索参数是8,这是他们使用的优化器,当然是Adam。 当然,在其TPU的庞大云中考虑过。 结果如何? 这些是有趣的数字:
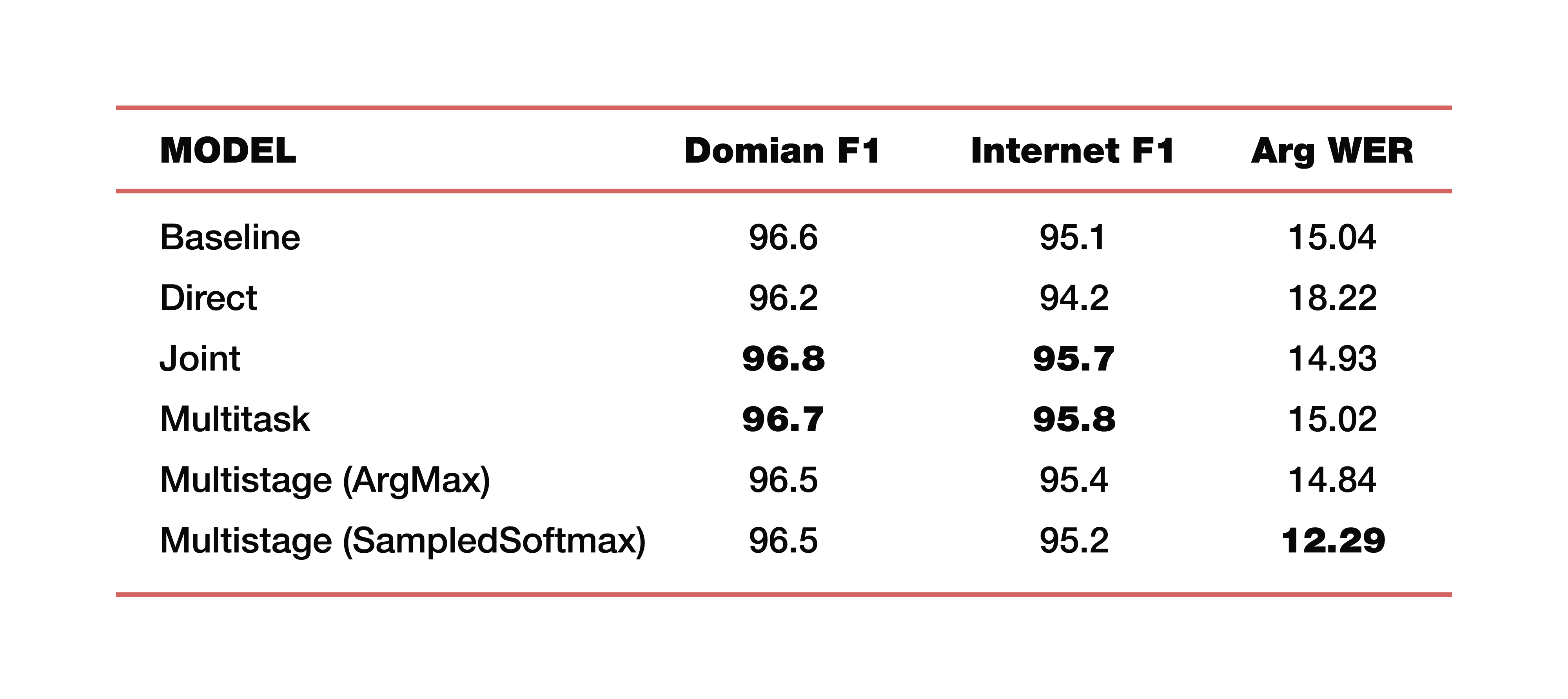
为了理解,基线是一种经典方法,它由两个部分组成,就像我们一开始所说的那样。 以下是直接模型,连接模型,多任务模型和多阶段模型的示例。
两个多阶段模型多少钱? 在第一部分和第二部分的交界处,使用了不同的层。 第一种情况是ArgMax,第二种情况是SampedSoftmax。
需要注意什么? 经典方法在所有三个指标中都丢失了,这是对这两个组件直接协作的估计。 是的,我们对在那里的转录效果不感兴趣,仅对预测语义结构的元素的效果如何感兴趣。 它由三个度量标准评估:F1-按主题,F1-按意图和ArgWer度量标准,实体的参数考虑该度量标准。 F1被认为是准确性和完整性之间的加权平均值。 也就是说,标准是100。相反,ArgWer不是成功,而是错误,即这里的标准是0。
值得注意的是,我们的耦合和多任务模型完全优于主题和意图的所有分类模型。 而且该模型是多阶段的,总ArgWer大大增加。 为什么这很重要? 因为在与理解口语相关的任务中,将在负责业务逻辑的组件中执行的最终操作很重要。 它不直接取决于ASR产生的转录,而是取决于ASR和NLU组件协同工作的质量。 因此,argWER指标中几乎三点的差异是一个非常酷的指标,表明该方法的成功。 还值得注意的是,根据主题和意图的定义,所有方法都具有可比的价值。
我将举几个使用这种算法来理解会话语音的示例。 Google在谈论理解对话性语音的任务时,主要会注意人机界面,即这些都是虚拟助手,例如Google Assistant,Apple Siri,Amazon Alexa等。 作为第二个示例,值得一提的是诸如交互式语音响应之类的任务池。 也就是说,这是一个涉及呼叫中心自动化的特定故事。
因此,我们研究了可能使用联合优化的方法,这有助于模型关注于对于SLU更重要的错误。 这种用于理解口语的任务的方法大大简化了总体复杂性。
我们有机会做出合理的结论,即获得某种结果,而无需诸如词典,语言模型,分析器等额外资源(即所有这些都是经典方法中固有的因素)。 任务“直接”解决。
实际上,您不能止步于此。 如果现在我们将这两种方法(一个共同结构的两个组成部分)组合在一起,那么我们可以针对更多目标。 将这三个组成部分与这四个组成部分结合在一起-只要继续将这个逻辑链结合起来,并考虑到错误的严重性,就将错误的重要性“推向”更低的水平。 这将使我们提高解决问题的准确性。