当今的AI从技术上讲是“弱”的-但是,它很复杂并且会严重影响社会
 您无需成为赛勒斯·杜利(Cyrus Dully)即可知道如何使智能情报变得可怕[美国演员在电影《太空漫游2001》中扮演扮演宇航员戴夫·鲍曼的角色。 perev。]
您无需成为赛勒斯·杜利(Cyrus Dully)即可知道如何使智能情报变得可怕[美国演员在电影《太空漫游2001》中扮演扮演宇航员戴夫·鲍曼的角色。 perev。]人工智能(AI)现在是最重要的知识领域之一。 解决了“无法解决的”问题,投资了数十亿美元,微软甚至
聘请 Common来平静地告诉我们,AI真是太好了。 没错
并且,与任何新技术一样,很难克服所有这些炒作。 我多年来一直在无人机和AI领域进行研究,但即使是这样,我也很难跟上这一切。 近年来,我花了很多时间来寻找最简单的问题的答案,例如:
- 人们说“ AI”是什么意思?
- AI,机器学习和深度学习之间有什么区别?
- 深度学习有什么好处?
- 以前哪些难题现在很容易解决,还有哪些难题呢?
我知道没有人对此感兴趣。 因此,如果您对所有关于AI的热情在最简单的层次上有什么联系感兴趣,那么该是幕后的时候了。 如果您是AI专家,并且在神经信息处理(NIPS)会议上阅读了报告的乐趣,那么这篇文章对您来说并不是什么新鲜事物-但是,我们希望您在评论中进行澄清和更正。
什么是AI?
在计算机科学中有一个古老的笑话:AI和自动化之间有什么区别? 自动化是可以使用计算机完成的事情,而AI是我们希望能够做到的事情。 一旦我们学习了如何做某事,它就会从AI领域转移到自动化领域。
由于AI的定义不够清晰,因此这个笑话在今天仍然有效。 人工智能根本不是一个技术术语。 如果您进入Wikipedia,它会说AI是“机器展示的情报,而不是人和其他动物展示的自然情报”。 您不能说得不太清楚。
通常,有两种类型的AI:强AI和弱AI。 大多数人在听说AI时都会想到强大的AI-这是一种类似于天神的无所不知的智力,例如天网或Hal 9000,能够推理并与人类相提并论,同时又超越了人类的能力。
弱AI是高度专业化的算法,旨在回答狭窄定义区域中的特定有用问题。 例如,一个很好的国际象棋程序就属于此类。 可以非常准确地调整保险金的软件也可以这样说。 在它们的领域中,这样的AI取得了令人印象深刻的结果,但是总的来说它们非常有限。
除了好莱坞的异议外,今天我们甚至还没有接近强大的AI。 到目前为止,任何AI都是薄弱的,这个领域的大多数研究人员都同意,我们发明的创建强大的弱AI的技术不可能使我们更接近创建强大的AI。
因此,当今的AI不仅仅是技术术语,更是营销术语。 公司宣传其AI而不是自动化的原因是因为他们希望将Hollywood AI引入公众的视野。 但是,这还不错。 如果对此采取的措施不是很严格,那么这些公司只是想说,尽管我们离强大的AI仍然相去甚远,但如今的弱AI却比几年前的能力要强大得多。
而且,如果您分散了市场营销的注意力,那么也是如此。 在某些领域,机器的功能得到了极大的提高,这主要归功于现在流行的另外两个短语:机器学习和深度学习。
 从Facebook工程师的短视频中拍摄,展示了实时AI如何识别猫(这项任务也被称为互联网的圣杯)
从Facebook工程师的短视频中拍摄,展示了实时AI如何识别猫(这项任务也被称为互联网的圣杯)机器学习
MO是创建机器智能的一种特殊方法。 假设您要发射火箭,并预测它的去向。 总的来说,它并不那么困难:对重力的研究非常深入,您可以根据几个变量(例如速度和初始位置)写下等式并计算其去向。
但是,如果我们转到规则不太为人所知和清楚的区域,这种方法将变得很尴尬。 假设您希望计算机告诉您某些图像上是否有猫。 您如何写下关于胡须和耳朵的所有可能组合的,以所有可能的观点描述视图的规则?
如今,MO方法已广为人知:您无需尝试写下所有规则,而是可以创建一个可以在研究大量示例之后独立得出一组内部规则的系统。 无需描述猫,您只需向AI显示一堆猫的照片,然后让他自己了解什么是猫,什么不是猫。
今天,这是一种完美的方法。 通过添加数据,可以改善基于数据的自学系统。 如果我们的物种能够做得很好,那就是生成,存储和管理数据。 是否想学习如何更好地识别猫? 互联网目前正在生成数百万个示例。
数据流量的不断增长是近来MO算法爆炸式增长的原因之一。 其他原因与该数据的使用有关。
除了数据之外,莫斯科地区还有两个与此相关的问题:
- 我怎么记得我学到的东西? 如何将我从数据中推断出的通信和规则存储并呈现在计算机上?
- 我该如何学习? 如何响应新示例来更改存储的表示形式并进行改进?
换句话说,根据所有这些数据到底要训练什么?
在MO中,我们存储的训练的计算表示形式是一个模型。 使用的模型类型非常重要:它决定了AI的学习方式,可以从中学习哪些数据以及可以提出哪些问题。
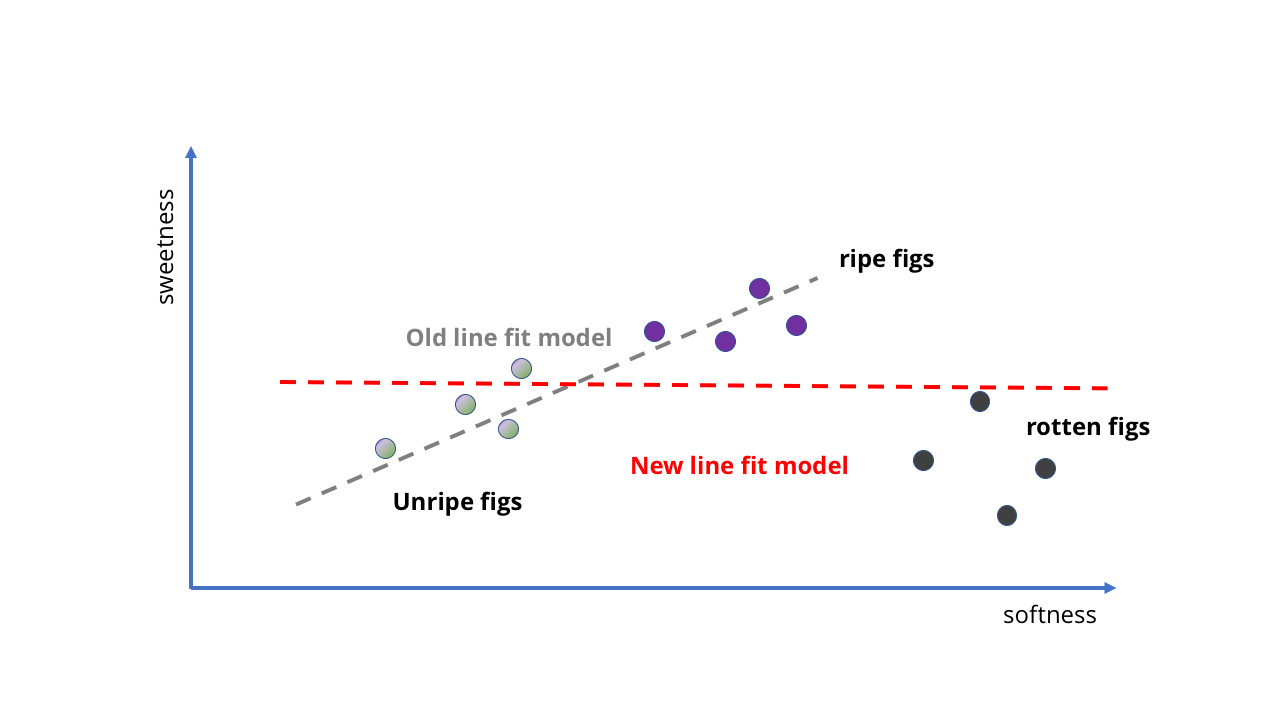
让我们看一个非常简单的例子。 假设我们在一家杂货店购买无花果,并希望通过MO制作一个AI,该AI可以告诉我们是否成熟。 这应该很容易做到,因为在无花果的情况下,越软越甜。
我们可以从几个成熟而未成熟的无花果中取样,看看它们有多甜,然后将它们放在图表上并为其调整直线。 这条线将成为我们的模型。
 以“越软越甜”的形式出现的AI胚
以“越软越甜”的形式出现的AI胚 随着新数据的添加,任务变得更加复杂。
随着新数据的添加,任务变得更加复杂。看一看! 直线暗示着“它们越柔软,越甜”的想法,我们甚至不必写下任何东西。 我们的AI胎儿对糖含量或成熟的水果一无所知,但可以通过挤压水果来预测它的甜度。
如何训练模型使其变得更好? 我们可以收集更多样本并绘制另一条直线以获得更准确的预测(如上图所示)。 但是,问题立即变得显而易见。 到目前为止,我们已经在无花果AI上训练优质浆果-如果我们从果园获取数据该怎么办? 突然,我们不仅成熟了,而且烂了水果。 它们非常柔软,但绝对不适合食用。
我们该怎么办? 好吧,由于这是一个MO模型,我们可以向她提供更多数据,对吗?
如下图所示,在这种情况下,我们将获得完全没有意义的结果。 该行根本不适合描述当水果变得太成熟时发生的情况。 我们的模型不再适合数据结构。
相反,我们必须更改它,并使用更好和更复杂的模型-可能是抛物线或类似的东西。 这种变化使学习变得复杂,因为绘制曲线比绘制直线需要更复杂的数学。
 好吧,可能对复杂的AI使用直线的想法不是很成功
好吧,可能对复杂的AI使用直线的想法不是很成功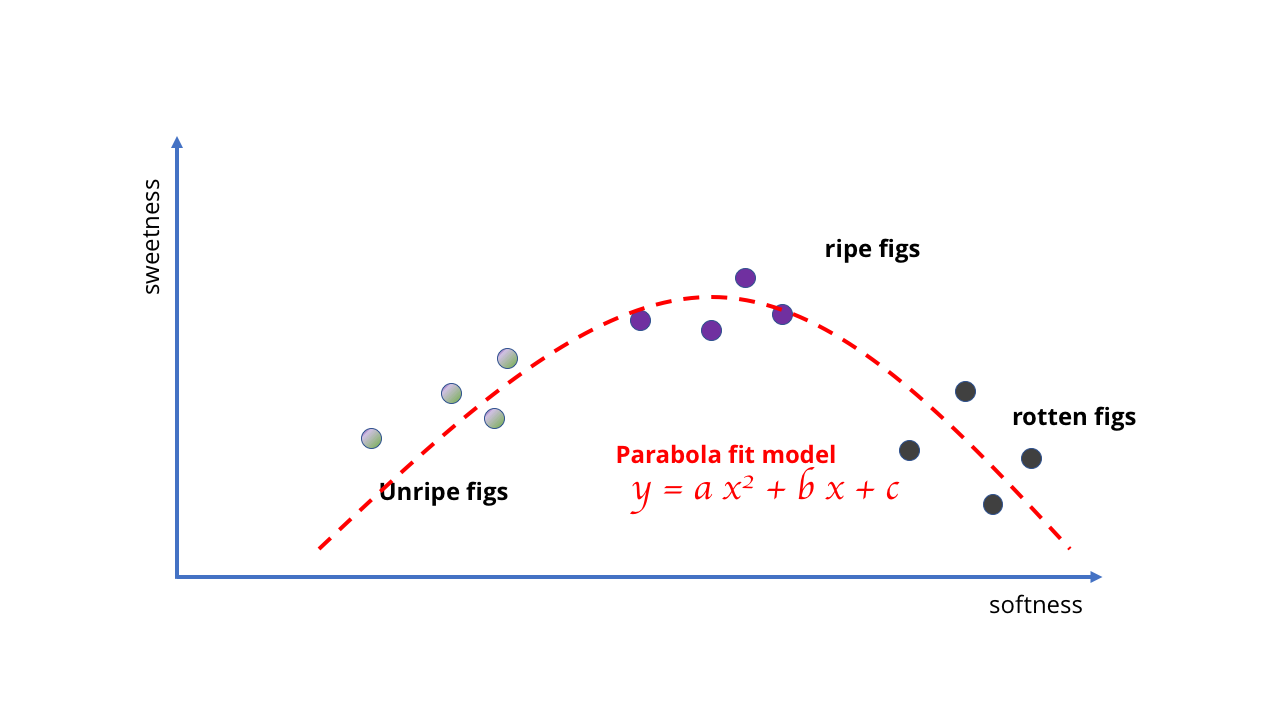 需要更复杂的数学
需要更复杂的数学这个例子很愚蠢,但是它表明模型的选择决定了学习的可能性。 在无花果的情况下,数据很简单,模型也很简单。 但是,如果您想学习更复杂的知识,则需要更复杂的模型。 正如没有大量数据可以使线性模型反映出腐烂浆果的行为一样,不可能选择与一堆图片相对应的简单曲线来创建计算机视觉算法。
因此,MO的困难在于为相应的任务创建并选择正确的模型。 我们需要一个足够复杂的模型来描述真正复杂的关系和结构,但又要足够简单,以便您可以使用它并进行培训。 因此,尽管Internet,智能手机等已经创建了令人难以置信的大量数据来学习,但我们仍然需要合适的模型来利用这些数据。
这是深度学习发挥作用的地方。

深度学习
深度学习是使用某种模型的机器学习:深度神经网络。
神经网络是一种MO模型,它使用类似于大脑神经元的结构进行计算和预测。 神经网络中的神经元是分层组织的:每一层执行一组简单的计算,并将答案传递给下一层。
分层模型允许进行更复杂的计算。 具有少量神经元层的简单网络足以重现我们上面使用的直线或抛物线。 深度神经网络是具有许多层的神经网络,具有数十甚至数百层。 因此,他们的名字。 拥有如此多的图层,您可以创建功能强大的模型。
这次机会是近来深度神经网络大受欢迎的主要原因之一。 他们可以学习各种复杂的事物,而无需强迫研究人员定义任何规则,这使我们能够创建可以解决计算机以前无法解决的各种问题的算法。
但是,另一方面也为神经网络的成功做出了贡献:训练。
模型的“内存”是一组数字参数,这些参数确定了模型如何提供对所提问题的答案。 训练模型意味着微调这些参数,以便模型给出可能的最佳答案。
在带有无花果的模型中,我们搜索了直线方程。 这是一个简单的回归任务,并且有一些公式可以一步一步给您答案。
 简单神经网络和深度神经网络
简单神经网络和深度神经网络对于更复杂的模型,事情并不是那么简单。 一条直线和一条抛物线可以很容易地用几个数字表示,但是一个深度神经网络可以具有数百万个参数,并且用于训练的数据集还可以包含数百万个示例。 一个步骤中没有一种分析解决方案。
幸运的是,有一个奇怪的窍门:您可以从不良的神经网络开始,然后通过逐步的调整来改善它。
以这种方式学习MO模型类似于使用测试对学生进行测试。 每次我们通过比较模型认为的答案与训练数据中的“正确”答案来获得评估时, 然后我们进行改进并再次运行测试。
我们如何知道要调整哪些参数以及调整多少? 神经网络具有很酷的功能,对于许多类型的训练,您不仅可以在测试中获得评估,还可以计算出随着每个参数的变化而变化的程度。 用数学术语来说,估计是值的函数,对于大多数这些函数,我们可以轻松地计算出该函数相对于参数空间的梯度。
现在,我们确切地知道了需要使用哪种方法来调整参数以增加得分,并且可以在所有最佳和最佳“方向”上通过连续的步骤调整网络,直到达到无法改善的地步。 这通常被称为爬山,因为这确实就像是爬上一座小山:如果不断地向上爬,您最终将身处山顶。
 你看到了吗 顶!
你看到了吗 顶!因此,很容易改善神经网络。 如果您的网络结构良好,并且已接收到新数据,则无需从头开始。 您可以从可用参数开始,然后从新数据中重新学习。 您的网络将逐渐完善。 当今最杰出的AI就是基于这个简单的事实,从Facebook上的猫识别到亚马逊(可能)在没有卖家的商店中使用的技术。
这是GO之所以如此迅速和如此广泛传播的另一个原因的关键:爬坡使您可以将一个训练有素的神经网络用于一项任务,然后对其进行再培训以执行另一项但相似的任务。 如果您已经训练了AI以很好地识别猫,则可以使用该网络来训练识别狗或长颈鹿的AI,而无需从头开始。 从猫的AI开始,通过狗识别的质量对其进行评估,然后爬上山,改善网络!
因此,在过去的5-6年中,AI的功能有了极大的提高。 几个难题以协同的方式组合在一起:互联网产生了大量的数据可供学习。 计算,尤其是GPU上的并行计算,使得处理这些庞大的集合成为可能。 最终,深度神经网络使利用这些工具包并创建难以置信的强大MO模型成为可能。
所有这些都意味着以前非常困难的某些事情现在很容易完成。
现在我们该怎么办? 模式识别
深度学习也许对计算机视觉领域尤其是对照片中物体的识别影响最深(对双关语很抱歉)和最早的影响。 几年前,这张xkcd漫画完美地描述了计算机科学的前沿:

如今,识别鸟类甚至某些类型的鸟类已经是一项微不足道的任务,正确动机的高中生可以解决。 有什么变化?
视觉识别对象的想法很容易描述,但难以实现:复杂的对象由一组较简单的对象组成,而这些对象又由较简单的形状和线条组成。 人脸由眼睛,鼻子和嘴巴组成,而人脸则由圆圈和线条组成,依此类推。
因此,面部识别成为识别眼睛和嘴巴位于其中的图案的问题,这可能需要从线条和圆圈识别出眼睛和嘴巴的形状。
这些模式称为功能,在进行深度学习以进行识别之前,必须手动描述所有功能并对计算机进行编程以找到它们。 例如,有一种著名的
Viola-Jones人脸识别算法,其基于以下事实:眉毛和鼻子通常比眼窝轻,因此它们形成带有两个暗点的明亮T形。 实际上,该算法正在寻找相似的T形。
Viola-Jones方法效果很好,速度惊人得惊人,是廉价相机等中人脸识别的基础。 但是,显然,并不是您需要识别的每个对象都可以简化操作,因此人们想到了越来越复杂和低级的模式。 为了使算法正确运行,需要一组科学博士,它们非常敏感并且容易失败。
重大突破归功于民防,尤其是某种类型的神经网络,称为卷积神经网络。 卷积神经网络SNS是具有一定结构的深层网络,其结构受到哺乳动物大脑视觉皮层结构的启发。 这种结构使SNA可以独立学习用于识别对象的线条和图案的层次结构,而不必等待科学博士花费数年的时间研究最适合此功能的特征。
例如,经过培训的SNA将学习其在眼睛,耳朵和鼻子等中形成的线条和圆圈的内部表示形式。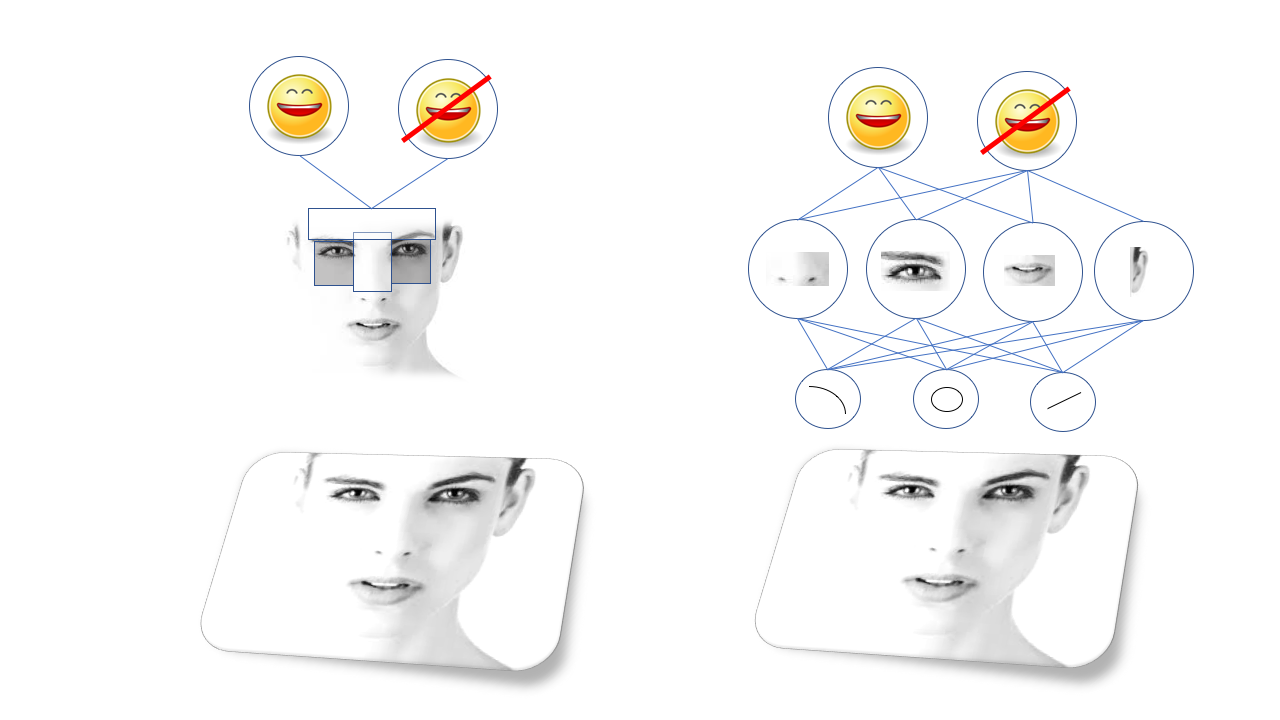 旧的视觉算法(左侧的Viola-Jones方法)依赖于手动选择的功能,而深层次的神经网络(右侧)则基于由更简单的SNA 组成的更复杂特征的自身层次结构,非常适合计算机视觉,很快研究人员就能够训练它们执行各种各样的视觉识别任务,从在照片中寻找猫到识别在机动车辆相机中被困的行人。这一切都很棒,但是SNA如此迅速而广泛地传播还有另一个原因-这就是它们适应的难易程度。还记得爬山吗?如果我们的高中生想识别某种鸟类,他可以使用开放代码访问众多视觉网络中的任何一个,并在自己的数据集上对其进行训练,甚至无需了解其基础的数学原理。自然,这可以进一步扩展。
旧的视觉算法(左侧的Viola-Jones方法)依赖于手动选择的功能,而深层次的神经网络(右侧)则基于由更简单的SNA 组成的更复杂特征的自身层次结构,非常适合计算机视觉,很快研究人员就能够训练它们执行各种各样的视觉识别任务,从在照片中寻找猫到识别在机动车辆相机中被困的行人。这一切都很棒,但是SNA如此迅速而广泛地传播还有另一个原因-这就是它们适应的难易程度。还记得爬山吗?如果我们的高中生想识别某种鸟类,他可以使用开放代码访问众多视觉网络中的任何一个,并在自己的数据集上对其进行训练,甚至无需了解其基础的数学原理。自然,这可以进一步扩展。谁啊 (人脸识别)
假设您想训练一个不仅可以识别人脸而且可以识别一张特定人脸的网络。您可以训练网络以识别特定人员,然后识别另一个人,依此类推。但是,培训网络需要时间,这意味着对于每个新手,都必须对网络进行重新培训。不,真的。相反,我们可以从训练有素的网络开始,该网络通常可以识别人脸。她的神经元被配置为识别所有面部结构:眼睛,耳朵,嘴巴等。然后,您只需更改输出:而不是强迫她识别某些面部,而是命令她以数百个数字的形式给出面部描述,这些数字描述了鼻子的弯曲或眼睛的形状,等等。网络可以做到这一点,因为它已经“知道”了脸部由什么组成。当然,您不必直接定义所有这些。相反,您可以通过显示一组面孔来训练网络,然后比较输出。您还教她,使她对同一人的描述彼此相似,而对不同人的描述彼此差异很大。从数学上讲,您训练网络以构建与空间空间中点的脸部图像的对应关系,其中点之间的笛卡尔距离可用于确定它们的相似性。 将神经网络从人脸识别(左侧)更改为人脸描述(右侧)仅需更改输出数据的格式,而无需更改其基础,
将神经网络从人脸识别(左侧)更改为人脸描述(右侧)仅需更改输出数据的格式,而无需更改其基础, 现在您可以通过比较神经网络创建的每个人脸的描述来识别人脸训练好网络后,您可以轻松识别脸部。您选择原始人并获得他的描述。然后换个新面孔,将网络提供的描述与原始描述进行比较。如果他们足够亲近,则表示您是同一个人。现在,您已经从能够识别一张脸的网络转变为可以识别任何一张脸的网络!这种结构上的灵活性是使用深度神经网络的另一个原因。已经开发了大量用于计算机视觉的各种MO模型,尽管它们的发展方向截然不同,但其中许多模型的基本结构都基于Alexnet和Resnet等早期SNA。我什至听说过有关人们使用视觉神经网络处理时间序列数据或传感器测量的故事。他们没有创建用于分析数据流的特殊网络,而是训练了一种为计算机视觉设计的开源神经网络,可以从字面上查看线形图的形状。这样的灵活性是一件好事,但不是无限的。要解决其他一些问题,您需要使用其他类型的网络。
现在您可以通过比较神经网络创建的每个人脸的描述来识别人脸训练好网络后,您可以轻松识别脸部。您选择原始人并获得他的描述。然后换个新面孔,将网络提供的描述与原始描述进行比较。如果他们足够亲近,则表示您是同一个人。现在,您已经从能够识别一张脸的网络转变为可以识别任何一张脸的网络!这种结构上的灵活性是使用深度神经网络的另一个原因。已经开发了大量用于计算机视觉的各种MO模型,尽管它们的发展方向截然不同,但其中许多模型的基本结构都基于Alexnet和Resnet等早期SNA。我什至听说过有关人们使用视觉神经网络处理时间序列数据或传感器测量的故事。他们没有创建用于分析数据流的特殊网络,而是训练了一种为计算机视觉设计的开源神经网络,可以从字面上查看线形图的形状。这样的灵活性是一件好事,但不是无限的。要解决其他一些问题,您需要使用其他类型的网络。 到目前为止,虚拟助手花费了很长时间
到目前为止,虚拟助手花费了很长时间你说什么 (语音识别)
图像分类和计算机视觉并不是AI复苏的唯一领域。语音识别,特别是在将语音转换为书写方面,是计算机发展的另一个领域。语音识别的基本思想与计算机视觉的原理非常相似:以一组较简单的形式识别复杂的事物。在语音的情况下,句子和短语的识别是基于单词的识别,而单词的识别是基于音节(或更确切地说是音素)的识别。因此,当有人说“ Bond,James Bond”时,我们实际上听到的是BON + DUH + JAY + MMS + BON + DUH。在视觉上,要素是按空间组织的,并且SNA会处理此结构。有传言说,这些功能是及时组织的。人们可以快速或缓慢地讲话,而没有清晰的开头和结尾。我们需要一个模型,该模型能够以一个人的身份感知声音的到达,而不是等待并在其中寻找完整的句子。我们不能像物理学那样说空间和时间是相同的。识别单个音节非常容易,但是很难隔离。例如,“你好,那里”可能听起来像“他们不知道” ...因此,对于任何声音序列,通常实际上会说出几种音节组合。为了理解所有这些,我们需要有机会在一定的背景下研究序列。如果我听到声音,则该人更有可能说“你好,亲爱的”或“不知道他们是鹿吗?”再一次,机器学习将助您一臂之力。有了足够多的口语模式集,您就可以学习最可能的短语。而且,您拥有的示例越多,结果就会越好。为此,人们使用递归神经网络RNS。在大多数类型的神经网络中,例如计算机视觉中涉及的SNA,神经元之间的连接在一个方向上起作用,从输入到输出(从数学上讲,这些是有向无环图)。在RNS中,神经元的输出可以重定向回相同级别的神经元,也可以重定向到自身,甚至进一步重定向。这允许RNS拥有自己的内存(如果您熟悉二进制逻辑,则这种情况类似于触发器的操作)。SNA采用一种方法:我们为她提供图像,并给出一些说明。 RNS保留了以前给她的内容的内部记忆,并根据她已经看到的内容以及现在看到的内容给出答案。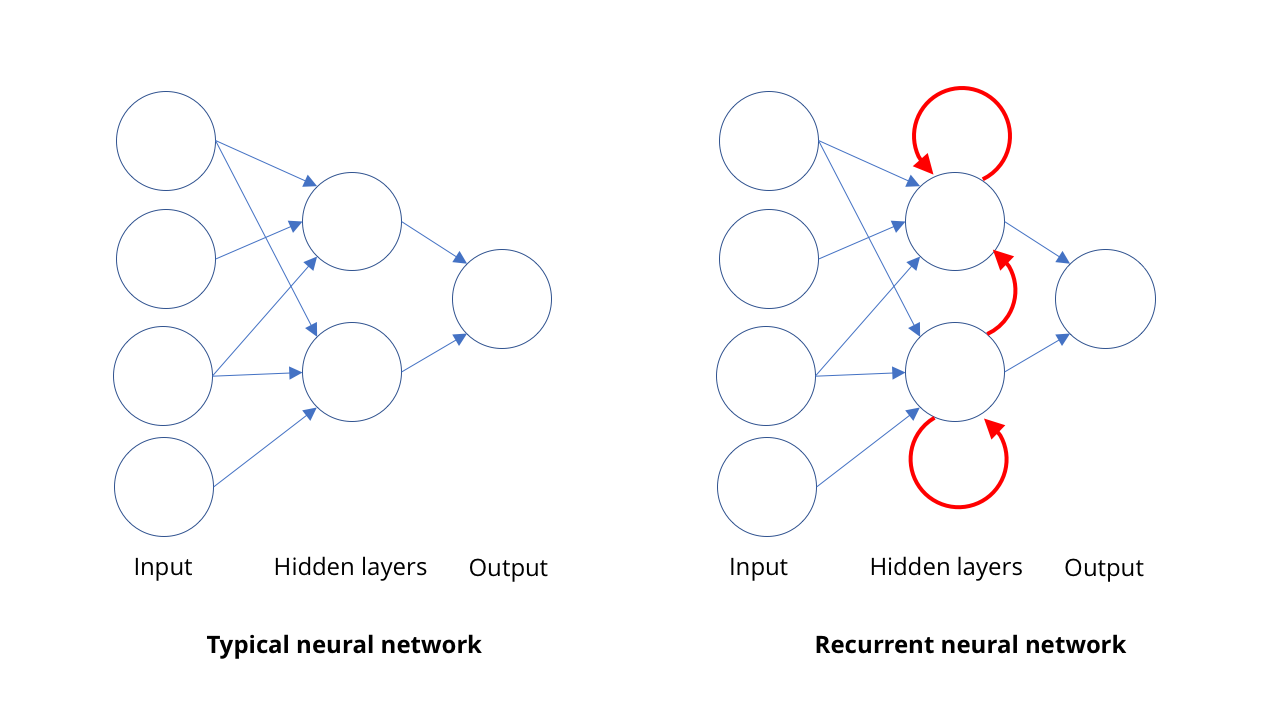 RNS中的内存属性使他们不仅可以“听”到一个音节。这使网络可以了解哪些音节一起组成一个单词,以及某些序列的可能性。使用RNS,有可能获得非常出色的人类语音转录-某种程度上,计算机在转录准确性的某些测量方面现在可以胜过人类。当然,声音不是出现序列的唯一区域。如今,RNS还用于确定运动序列以识别视频上的动作。
RNS中的内存属性使他们不仅可以“听”到一个音节。这使网络可以了解哪些音节一起组成一个单词,以及某些序列的可能性。使用RNS,有可能获得非常出色的人类语音转录-某种程度上,计算机在转录准确性的某些测量方面现在可以胜过人类。当然,声音不是出现序列的唯一区域。如今,RNS还用于确定运动序列以识别视频上的动作。告诉我如何移动(深层的假货和生成网络)
到目前为止,我们一直在讨论为识别而设计的MO模型:告诉我图片中显示的内容,告诉我这个人说的是什么。但是这些模型具有更多功能-今天的GO模型也可以用于创建内容。这是人们谈论Deepfake的时候-令人难以置信的逼真的假视频和使用GO创建的图像。前段时间,一名德国电视官员制作了一个假冒的视频,引发了广泛的政治讨论其中希腊财政部长向德国伸出了中指。要制作此视频,我们需要一个编辑团队来制作电视节目,但是在现代世界中,只要有中型游戏机的访问者,都可以在几分钟之内完成该视频。在这方面,所有这一切都让人很难过,但并不那么令人沮丧-顶部显示了我最喜欢的有关该技术的视频。这个团队创建了一个模型,该模型能够处理一个人的跳舞动作的视频,并与另一个人重复这些动作的视频创建,从而在专家级别上神奇地执行它们。阅读随附的科学著作也很有趣。可以想象,使用我们讨论的所有技术,可以训练一个网络,该网络接收舞者的图像并告诉他的胳膊和腿在哪里。在这种情况下,很明显,在某种程度上,网络学习了如何将图像中的像素与人体四肢的位置联系起来。假设神经网络只是存储在计算机上的数据,而不是生物大脑,那么应该有可能获取这些数据并朝相反的方向前进-以获取与四肢位置相对应的像素。从一个从人物图像中提取姿势的网络开始。
可以做到这一点的MO模型称为生成模型。生成-生成,生成,创建/大约翻译]。我们以前考虑的所有先前模型都称为歧视性[eng。区分-区分/近似。翻译]。它们之间的区别可以想象如下:猫的歧视模型查看照片,并区分包含猫的照片和不包含猫的照片。生成模型会根据对猫的表情的描述来创建猫的图像。 使用与用于识别这些对象的模型相同的SNA结构创建“绘制”对象图像的生成模型。这些模型的训练方式与其他MO模型几乎相同。但是,诀窍是要对他们的培训进行“评估”。训练歧视模型时,有一种简单的方法可以评估答案的正确性和不正确性-例如网络是否正确区分了狗和猫。但是,如何评估生成的猫图片的质量或其准确性?对于一个热爱阴谋论并相信我们都注定要失败的人来说,情况变得有些可怕。您会发现,我们发明的用于学习生成网络的最好方法不是自己做。为此,我们仅使用不同的神经网络。这项技术称为生成对抗网络或GSS。您迫使两个神经网络相互竞争:例如,一个网络试图通过根据旧姿势绘制新的舞者来制造假货。训练了另一个网络,使用大量真实的舞者示例来查找真实示例与伪示例之间的差异。而这两个网络都在竞争。因此标题中的“对抗性”一词。生成网络试图制造令人信服的假货,而歧视性网络则试图了解假货在哪里以及真品在哪里。对于带有舞者的视频,在培训过程中会创建一个单独的歧视性网络,给出简单的是/否答案。她查看了该人的图像及其四肢位置的描述,并确定该图像是真实的照片还是生成模型绘制的照片。
使用与用于识别这些对象的模型相同的SNA结构创建“绘制”对象图像的生成模型。这些模型的训练方式与其他MO模型几乎相同。但是,诀窍是要对他们的培训进行“评估”。训练歧视模型时,有一种简单的方法可以评估答案的正确性和不正确性-例如网络是否正确区分了狗和猫。但是,如何评估生成的猫图片的质量或其准确性?对于一个热爱阴谋论并相信我们都注定要失败的人来说,情况变得有些可怕。您会发现,我们发明的用于学习生成网络的最好方法不是自己做。为此,我们仅使用不同的神经网络。这项技术称为生成对抗网络或GSS。您迫使两个神经网络相互竞争:例如,一个网络试图通过根据旧姿势绘制新的舞者来制造假货。训练了另一个网络,使用大量真实的舞者示例来查找真实示例与伪示例之间的差异。而这两个网络都在竞争。因此标题中的“对抗性”一词。生成网络试图制造令人信服的假货,而歧视性网络则试图了解假货在哪里以及真品在哪里。对于带有舞者的视频,在培训过程中会创建一个单独的歧视性网络,给出简单的是/否答案。她查看了该人的图像及其四肢位置的描述,并确定该图像是真实的照片还是生成模型绘制的照片。 GSS迫使两个网络相互竞争:一个网络制造假货,另一个网络试图区分假货和假货,
GSS迫使两个网络相互竞争:一个网络制造假货,另一个网络试图区分假货和假货,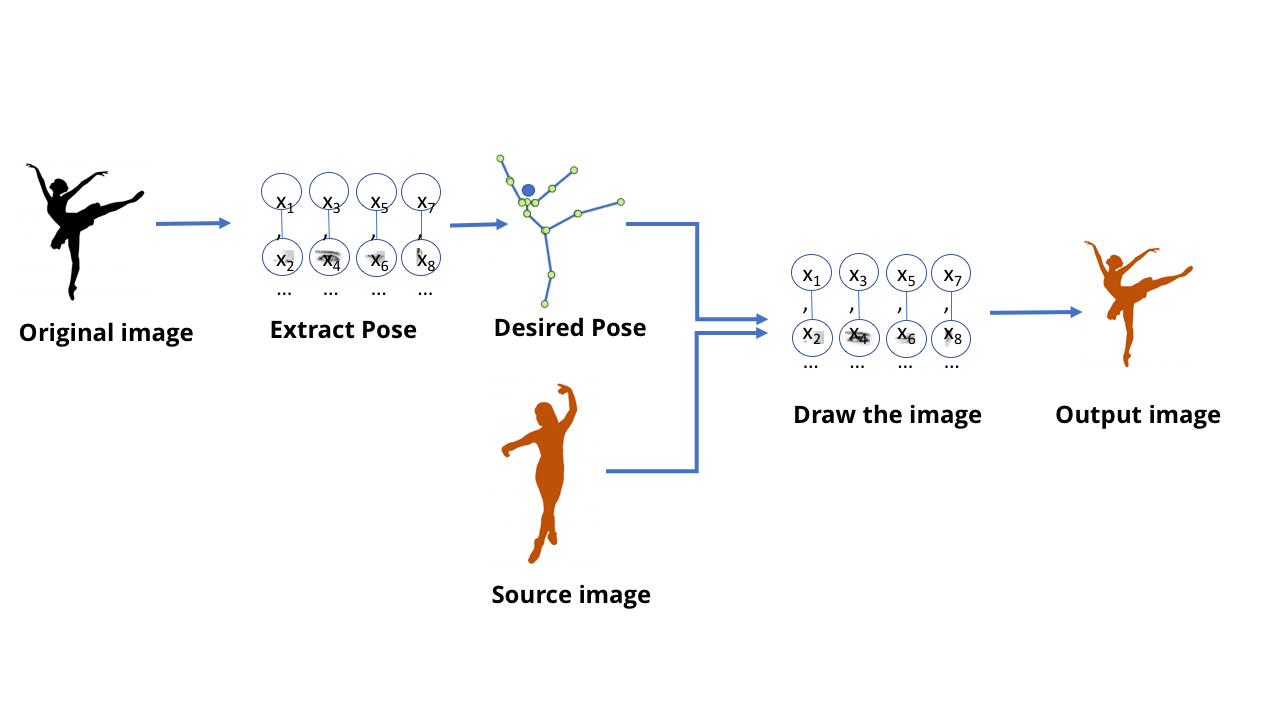 在最终的工作流程中,仅使用生成模型来创建必要的图像在反复的训练中,模型变得越来越好。这类似于珠宝专家和估价专家之间的竞争-与强大的对手竞争,他们每个人都变得更加强大和精明。最后,当模型运行良好时,您可以采用生成模型并将其单独使用。训练后的生成模型对于创建内容可能非常有用。例如,他们可以生成人脸图像(可用于训练人脸识别程序)或视频游戏背景。为了使所有这些正常工作,需要进行大量的调整和更正工作,但实际上,此人是仲裁员。正是AI相互对抗,取得了重大进步。
在最终的工作流程中,仅使用生成模型来创建必要的图像在反复的训练中,模型变得越来越好。这类似于珠宝专家和估价专家之间的竞争-与强大的对手竞争,他们每个人都变得更加强大和精明。最后,当模型运行良好时,您可以采用生成模型并将其单独使用。训练后的生成模型对于创建内容可能非常有用。例如,他们可以生成人脸图像(可用于训练人脸识别程序)或视频游戏背景。为了使所有这些正常工作,需要进行大量的调整和更正工作,但实际上,此人是仲裁员。正是AI相互对抗,取得了重大进步。, Skynet Hal 9000?
在每部关于自然的纪录片中,最后都有一集,作者谈到由于人们的可怕程度,这种宏伟的美很快将消失。 我认为,本着同样的精神,每一次有关人工智能的负责任讨论都应包括有关其局限性和社会后果的一节。
首先,让我们再次强调AI的当前局限性:我希望您从阅读本文中学到的主要思想是MO或AI的成功在很大程度上取决于我们选择的训练模型。 如果人们不能很好地组织网络或使用不合适的材料进行培训,那么这些失真对每个人都是非常明显的。
深度神经网络具有难以置信的灵活性和强大功能,但没有神奇的特性。 尽管您将深层神经网络用于RNS和SNA,但它们的结构却大不相同,因此,人们还是应该确定它。 因此,即使您可以将SNA应用于汽车并对其进行重新训练以进行鸟类识别,也无法采用此模型并对其进行重新训练以进行语音识别。
如果我们用人类的术语来描述它,那么一切看起来就好像我们了解了视觉皮层和听觉皮层是如何工作的,但是我们不知道大脑皮层是如何工作的,以及我们在哪里可以开始使用它。
这意味着在不久的将来,我们可能不会看到像好莱坞神一样的AI。 但这并不意味着以目前的形式,人工智能不会对社会产生严重影响。
我们经常想像AI是如何“替代”我们的,也就是说,机器人实际上是如何完成我们的工作的,但实际上这不会发生。 例如,以放射学为例:有时人们看着计算机视觉的成功,说人工智能将取代放射线医生。 也许我们将无法达到完全没有一名放射线医师的地步。 但是,未来很有可能,对于今天的一百名放射科医生来说,人工智能将允许其中五到十名从事其他所有人的工作。 如果实现了这种情况,剩下的90名医生将去哪儿?
即使现代AI不能实现其最乐观的支持者的希望,它仍然会导致非常广泛的后果。 我们将必须解决这些问题,因此一个良好的开端可能是掌握该领域的基础知识。