引言
部署下一个系统时,需要处理大量的各种日志。 作为工具选择了ELK。 本文将讨论我们在调整此堆栈方面的经验。
我们并没有设定一个描述其所有可能性的目标,但我们想专注于解决实际问题。 这是由于以下事实:存在大量的文档和现成的图像,存在很多陷阱,至少我们发现了这些陷阱。
我们通过docker-compose部署了堆栈。 而且,我们有一个写得很好的docker-compose.yml,它使我们几乎没有问题地提升了堆栈。 对我们来说,胜利似乎已经迫在眉睫,现在我们将稍作调整以适应我们的需求,仅此而已。
不幸的是,尝试调整系统以从我们的应用程序接收和处理日志的尝试并未获得成功。 因此,我们认为值得分别研究每个组件,然后返回它们之间的关系。
因此,我们从logstash开始。
环境,部署,在容器中启动Logstash
为了进行部署,我们使用docker-compose,此处描述的实验是在MacOS和Ubuntu 18.0.4上进行的。
在原始docker-compose.yml中向我们注册的logstash映像是docker.elastic.co/logstash/logstash:6.3.2
我们将其用于实验。
为了运行logstash,我们编写了一个单独的docker-compose.yml。 当然,可以从命令行启动映像,但是我们确实解决了一个特定的问题,其中启动了docker-compose中的所有内容。
简要介绍配置文件
从描述中可以看出,logstash可以在一个通道中运行,在这种情况下,它需要传输* .conf文件,或者在多个通道中运行,在这种情况下,它需要传输pipelines.yml文件,该文件又将链接到文件.conf每个频道。
我们走了第二条路。 在我们看来,它似乎更具通用性和可扩展性。 因此,我们创建了pipelines.yml,并创建了pipelines目录,我们将在其中放置每个通道的.conf文件。
容器内还有另一个配置文件-logstash.yml。 我们不触摸它,而是按原样使用它。
因此,目录的结构为:
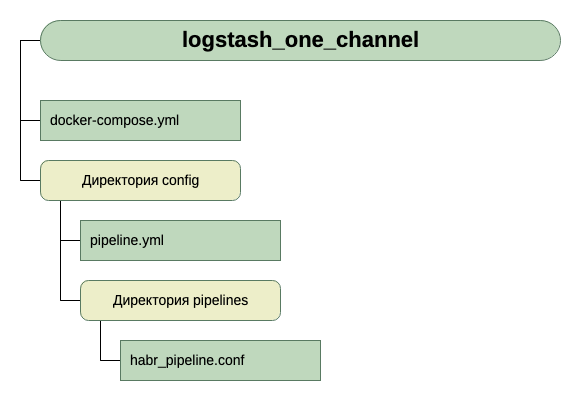
为了获得输入,目前,我们认为它是端口5046上的tcp,对于输出,我们将使用stdout。
这是第一次运行时的简单配置。 由于初始任务是启动。
所以,我们有了这个docker-compose.yml
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro
我们在这里看到什么?
- 网络和卷取自原始的docker-compose.yml(启动整个堆栈的那个),我认为它们不会显着影响此处的整体情况。
- 我们从docker.elastic.co/logstash/logstash:6.3.2映像创建一个logstash服务,并将其命名为logstash_one_channel。
- 我们将容器内的端口5046转发到相同的内部端口。
- 我们将通道设置文件./config/pipelines.yml映射到容器内的文件/usr/share/logstash/config/pipelines.yml中,logstash将在其中将其选中并设为只读,以防万一。
- 在/ usr / share / logstash / config / pipelines目录中,我们显示./config/pipelines目录,其中包含通道设置文件,并且也将其设置为只读。
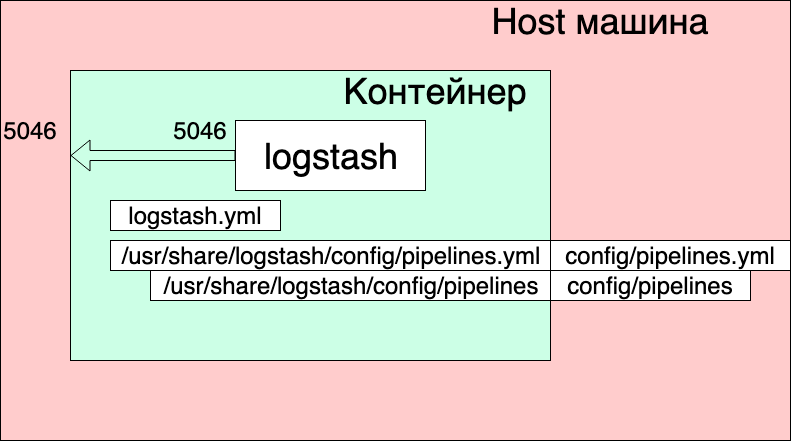
Pipelines.yml文件
- pipeline.id: HABR pipeline.workers: 1 pipeline.batch.size: 1 path.config: "./config/pipelines/habr_pipeline.conf"
在此,将描述具有HABR标识符的一个通道及其配置文件的路径。
最后是文件“ ./config/pipelines/habr_pipeline.conf”
input { tcp { port => "5046" } } filter { mutate { add_field => [ "habra_field", "Hello Habr" ] } } output { stdout { } }
现在让我们不进入他的描述,尝试运行:
docker-compose up
我们看到了什么?
容器启动。 我们可以检查其操作:
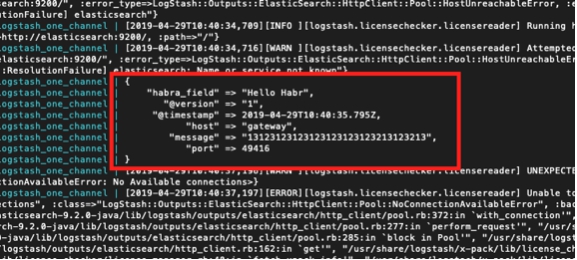
echo '13123123123123123123123213123213' | nc localhost 5046
我们在容器控制台中看到了答案:
但同时,我们还看到:
logstash_one_channel | [2019-04-29T11:28:59,790]
[错误] [logstash.licensechecker.licensereader]无法从许可证服务器获取许可证信息{:message =>“ Elasticsearch Unreachable:[http:// elasticsearch:9200 /] [Manticore :: ResolutionFailure] elasticsearch“,...
logstash_one_channel | [2019-04-29T11:28:59,894] [INFO] [logstash.pipeline]
管道已成功启动 {:pipeline_id =>“。Monitoring-logstash” ,: thread =>“#<Thread:0x119abb86 run>”}
logstash_one_channel | [2019-04-29T11:28:59,988] [INFO] [logstash.agent]正在运行的管道{:count => 2 ,: running_pipelines => [:HABR ,:“。Monitoring-logstash”] ,: non_running_pipelines => [ ]}
logstash_one_channel | [2019-04-29T11:29:00,015]
[错误] [logstash.inputs.metrics] X-Pack已安装在Logstash上,但未安装在Elasticsearch上。 请在Elasticsearch上安装X-Pack以使用监视功能。 其他功能可能可用。logstash_one_channel | [2019-04-29T11:29:00,526] [INFO] [logstash.agent]已成功启动Logstash API端点{:port => 9600}
logstash_one_channel | [2019-04-29T11:29:04,478] [INFO] [logstash.outputs.elasticsearch]运行状况检查以查看Elasticsearch连接是否正常工作{:healthcheck_url => http:// elasticsearch:9200 / ,: path => “ /”}
l
ogstash_one_channel | [2019-04-29T11:29:04,487]
[WARN] [logstash.outputs.elasticsearch]试图恢复与死掉的ES实例的连接,但出现错误。 {:url =>“ elasticsearch:9200 /” ,: error_type => LogStash ::输出:: ElasticSearch :: HttpClient :: Pool :: HostUnreachableError ,: error =>“ Elasticsearch Unreachable:[http:// elasticsearch:9200 / ] [Manticore :: ResolutionFailure] elasticsearch”}logstash_one_channel | [2019-04-29T11:29:04,704] [INFO] [logstash.licensechecker.licensereader]运行状况检查以查看Elasticsearch连接是否正常工作{:healthcheck_url => http:// elasticsearch:9200 / ,: path => “ /”}
logstash_one_channel | [2019-04-29T11:29:04,710]
[WARN] [logstash.licensechecker.licensereader]试图恢复与死掉的ES实例的连接,但出现错误。 {:url =>“ elasticsearch:9200 /” ,: error_type => LogStash ::输出:: ElasticSearch :: HttpClient :: Pool :: HostUnreachableError ,: error =>“ Elasticsearch Unreachable:[http:// elasticsearch:9200 / ] [Manticore :: ResolutionFailure] elasticsearch”}而且我们的日志一直在爬。
在这里,我以绿色突出显示一条消息,表示管道已成功启动,红色(一条错误消息,黄色)一条有关尝试联系
elasticsearch的消息:9200。
发生这种情况是因为图像中包含的logstash.conf会检查Elasticsearch的可用性。 毕竟,logstash假定它是Elk堆栈的一部分,因此我们将其分开。
您可以工作,但不方便。
解决方案是通过XPACK_MONITORING_ENABLED环境变量禁用此检查。
对docker-compose.yml进行更改,然后再次运行:
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro
现在,一切都很好。 容器已准备好进行实验。
我们可以再次输入下一个控制台:
echo '13123123123123123123123213123213' | nc localhost 5046
并查看:
logstash_one_channel | { logstash_one_channel | "message" => "13123123123123123123123213123213", logstash_one_channel | "@timestamp" => 2019-04-29T11:43:44.582Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "host" => "gateway", logstash_one_channel | "port" => 49418 logstash_one_channel | }
在一个渠道内工作
因此,我们开始了。 现在,您实际上可以花时间直接配置logstash。 我们暂时不会触摸pipelines.yml文件,我们将看到使用一个通道可以得到什么。
我必须说,在官方指南中对使用通道配置文件的一般原理进行了很好的说明,
此处如果您想用俄语阅读,那么我们
在这里使用了这篇
文章 (但是查询语法在那里太旧了,我们必须考虑到这一点)。
让我们依次从“输入”部分开始。 我们已经看到了有关tcp的工作。 这里还有什么有趣的?
使用心跳测试消息
产生自动测试消息的机会非常有趣。
为此,您需要在输入部分中包含heartbean插件。
input { heartbeat { message => "HeartBeat!" } }
打开,每分钟启动一次即可接收
logstash_one_channel | { logstash_one_channel | "@timestamp" => 2019-04-29T13:52:04.567Z, logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "HeartBeat!", logstash_one_channel | "@version" => "1", logstash_one_channel | "host" => "a0667e5c57ec" logstash_one_channel | }
我们希望得到更多的频率,我们需要添加interval参数。
这是我们每10秒会收到一条消息的方式。
input { heartbeat { message => "HeartBeat!" interval => 10 } }
从文件中检索数据
我们还决定查看文件模式。 如果该文件可以正常使用,则可能至少在本地使用时不需要代理。
根据描述,操作模式应类似于tail -f,即。 读取换行符,或者作为一个选择,读取整个文件。
所以我们想要得到:
- 我们想要获取附加到一个日志文件的行。
- 我们希望接收写入多个日志文件的数据,同时能够共享数据来源。
- 我们要检查的是,重新启动logstash时,它将不会再次收到此数据。
- 我们要检查是否禁用了logstash,并且数据继续写入文件中,然后在运行它时,我们将获得此数据。
要进行实验,请在docker-compose.yml中添加另一行,以打开用于放置文件的目录。
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro - ./logs:/usr/share/logstash/input
并在habr_pipeline.conf中更改输入部分
input { file { path => "/usr/share/logstash/input/*.log" } }
我们开始:
docker-compose up
要创建和记录日志文件,我们将使用以下命令:
echo '1' >> logs/number1.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:28:53.876Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log" logstash_one_channel | }
是的,它有效!
同时,我们看到我们自动添加了路径字段。 因此,将来我们可以通过它过滤记录。
让我们再试一次:
echo '2' >> logs/number1.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:28:59.906Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "2", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log" logstash_one_channel | }
现在到另一个文件:
echo '1' >> logs/number2.log
{ logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "@timestamp" => 2019-04-29T14:29:26.061Z, logstash_one_channel | "@version" => "1", logstash_one_channel | "message" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log" logstash_one_channel | }
太好了! 文件被拾取,路径正确,一切都很好。
停止logstash并重新启动。 等一下 沉默。 即 我们不会再收到这些记录。
现在是最大胆的实验。
我们放入logstash并执行:
echo '3' >> logs/number2.log echo '4' >> logs/number1.log
再次运行logstash,请参阅:
logstash_one_channel | { logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "3", logstash_one_channel | "@version" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number2.log", logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.589Z logstash_one_channel | } logstash_one_channel | { logstash_one_channel | "host" => "ac2d4e3ef70f", logstash_one_channel | "habra_field" => "Hello Habr", logstash_one_channel | "message" => "4", logstash_one_channel | "@version" => "1", logstash_one_channel | "path" => "/usr/share/logstash/input/number1.log", logstash_one_channel | "@timestamp" => 2019-04-29T14:48:50.856Z logstash_one_channel | }
万岁! 一切都捡了。
但是,我们必须警告以下内容。 如果删除了带有logstash的容器(docker stop logstash_one_channel && docker rm logstash_one_channel),则将不会进行任何操作。 在容器内部,保存了读取文件的位置。 如果从头开始,它将仅接受换行。
读取现有文件
假设我们是第一次运行logstash,但是我们已经有了日志,我们想对其进行处理。
如果我们使用上面使用的输入部分来运行logstash,那么我们将一无所获。 仅换行符将由logstash处理。
为了从现有文件中提取行,请在输入部分添加另一行:
input { file { start_position => "beginning" path => "/usr/share/logstash/input/*.log" } }
而且,有一个细微差别,这只会影响logstash尚未看到的新文件。 对于已经落入logstash视野中的相同文件,他已经记住了它们的大小,现在只在其中添加新条目。
让我们专注于输入部分的研究。 还有更多选择,但是对我们来说,现在进行进一步的实验就足够了。
路由和数据转换
让我们尝试解决以下问题,假设我们从一个渠道收到消息,其中一些是参考消息,部分是错误消息。 标签不同。 一些信息,其他错误。
我们需要在输出处将它们分开。 即 我们在一个通道中编写参考消息,而在另一通道中编写错误消息。
为此,请从输入部分转到过滤器并输出。
使用过滤器部分,我们将解析传入的消息,从中获取哈希(键值对),您已经可以使用它,即 根据条件拆卸。 在输出部分,我们选择消息并将其发送到我们的频道。
使用grok解析消息
为了解析文本字符串并从中获取一组字段,过滤器部分中有一个特殊的插件-grok。
我不打算在这里给出详细说明(为此,我参考
官方文档 ),我将给出一个简单的示例。
为此,您需要确定输入行的格式。 我有它们:
1条信息消息1
2错误消息2
即 标识符首先出现,然后是INFO / ERROR,然后是一些没有空格的单词。
不难,但足以理解其工作原理。
因此,在过滤器部分的grok插件中,我们需要定义一种模式来解析行。
它看起来像这样:
filter { grok { match => { "message" => ["%{INT:message_id} %{LOGLEVEL:message_type} %{WORD:message_text}"] } } }
这本质上是一个正则表达式。 使用现成的模式,例如INT,LOGLEVEL,WORD。 它们的描述以及其他模式可以在
这里找到
。现在,通过此过滤器,我们的字符串将变成三个字段的哈希:message_id,message_type,message_text。
它们将显示在输出部分。
使用if命令在输出部分中路由消息
我们记得在输出部分,我们将消息分成两个流。 有些-iNFO,我们将输出到控制台,如果有错误,我们将输出到文件。
我们如何拆分这些职位? 问题的状况已经提示解决方案-我们已经选择了message_type字段,该字段只能使用两个值INFO和ERROR。 对于他来说,我们将使用if语句进行选择。
if [message_type] == "ERROR" { # } else { # stdout }
有关使用字段和运算符的说明,可在
官方手册的此部分中找到。
现在,关于实际结论本身。
输出到控制台,一切都在这里清楚了-stdout {}
这是文件的输出-请记住,我们都是从容器运行所有文件,因此可以从外部访问写入结果的文件,我们需要在docker-compose.yml中打开此目录。
总计:
文件的输出部分如下所示:
output { if [message_type] == "ERROR" { file { path => "/usr/share/logstash/output/test.log" codec => line { format => "custom format: %{message}"} } } else {stdout { } } }
在docker-compose.yml中添加另一个卷以输出:
version: '3' networks: elk: volumes: elasticsearch: driver: local services: logstash: container_name: logstash_one_channel image: docker.elastic.co/logstash/logstash:6.3.2 networks: - elk environment: XPACK_MONITORING_ENABLED: "false" ports: - 5046:5046 volumes: - ./config/pipelines.yml:/usr/share/logstash/config/pipelines.yml:ro - ./config/pipelines:/usr/share/logstash/config/pipelines:ro - ./logs:/usr/share/logstash/input - ./output:/usr/share/logstash/output
我们开始,尝试,我们看到分成两个流程。