
随着移动电话中高品质相机的出现,我们越来越多地拍摄照片,拍摄有关我们生活中最重要的瞬间的视频。 我们中的许多人都有可追溯到数十年的照片档案,上千张照片,在其中浏览变得越来越困难。 记住几年前找到正确的照片通常要花多长时间。
Mail.ru Cloud的目标之一是在照片和视频档案中提供最方便的访问和搜索。 为此,我们Mail.ru机器视觉团队已创建并实施了智能照片处理系统:按对象,场景,面部等进行搜索。另一种引人注目的技术是对景点的识别。 今天,我将讨论如何在深度学习的帮助下解决此问题。
想象一下情况:您去度假并带来了一堆照片。 在与朋友的交谈中,他们要求您展示您如何参观宫殿,城堡,金字塔,寺庙,湖泊,瀑布,山脉等。 您开始疯狂地滚动浏览包含照片的文件夹,尝试找到合适的文件夹。 最有可能的是,您没有在数百张图像中找到它,而是说您稍后再显示。
我们通过将自定义照片分组到相册中来解决此问题。 只需单击几下,即可轻松找到合适的图片。 现在,我们在面部,物体和场景以及景点上都有专辑。
具有地标的照片很重要,因为它们经常显示我们生活中的重要时刻(例如旅行)。 这些可以是某些建筑结构背景下的照片,也可以是人类未曾接触过的自然角落。 因此,我们需要找到这些照片并为用户提供方便快捷的访问方式。
特征识别
但有一个细微差别:您不能仅仅训练并训练一些模型来识别景点,这有很多困难。
- 首先,我们不能清楚地描述什么是“地标”。 我们不能说为什么一栋建筑物是地标,而站在它旁边却不是。 这不是一个形式化的概念,这会使识别问题的制定复杂化。
- 其次,景点千差万别。 它可以是历史建筑或文化建筑-寺庙,宫殿,城堡。 这些可能是最多样化的古迹。 它可以是自然物体-湖泊,峡谷,瀑布。 一个模型必须能够找到所有这些景点。
- 第三,根据我们的计算,几乎没有带景点的图像,它们仅在1-3%的用户照片中被发现。 因此,我们不能允许自己犯错误识别,因为如果我们向某人展示没有兴趣点的照片,它会立即被注意到,并会引起困惑和负面反应。 或者,相反,我们向该人展示了一张在纽约具有里程碑意义的照片,而他从未去过美国。 因此,识别模型必须具有较低的FPR(误报率)。
- 第四,约50%甚至更多的用户在拍照时关闭了地理信息存储。 我们需要考虑到这一点,并仅根据图像确定位置。 如今,由于地理数据,大多数设法以某种方式与感兴趣的地方一起工作的服务都可以做到这一点。 我们最初的要求更加严格。
我现在将举例说明。
这是三座法国哥特式大教堂。 左边是兰斯大教堂中间的亚眠大教堂,右边是巴黎圣母院。

甚至一个人也需要一些时间来查看它们,并理解它们是不同的大教堂,并且该机器还必须能够应对它,并且比一个人更快。
这是另一个困难的例子:幻灯片上的三张照片是巴黎圣母院,从不同的角度拍摄。 原来照片有很大的不同,但都需要被识别和发现。

自然对象与建筑对象完全不同。 左边是以色列的凯撒利亚,右边是慕尼黑的英吉利公园。

在这些照片中,模型可以“抓住”的特征细节很少。
我们的方法
我们的方法完全基于深度卷积神经网络。 作为一种学习方法,他们选择了所谓的课程学习-分几个阶段进行学习。 为了在存在和不存在地理数据的情况下均能更有效地工作,我们进行了特殊的推断(结论)。 我将详细介绍每个阶段。
数据中心
机器学习的动力是数据。 首先,我们需要收集用于模型训练的数据集。
我们将世界分为4个区域,每个区域都用于不同的培训阶段。 然后,在每个区域中收集国家/地区,为每个国家/地区编制城市清单,并收集其景点图片数据库。 数据示例如下所示。

首先,我们尝试在结果基础上训练我们的模型。 结果很差。 他们开始分析,结果发现数据非常“脏”。 每个景点都有大量垃圾。 怎么办 手动检查大量数据非常昂贵,沉闷并且不是很聪明。 因此,我们对基座进行了自动清洁,在此过程中,仅一步进行了手动处理:对于每个吸引力,我们手动选择了3-5张参考照片,这些照片在或多或少正确的角度上准确地包含了所需的吸引力。 事实证明很快,因为此类参考数据的数量相对于整个数据库而言很小。 然后,已经执行了基于深度卷积神经网络的自动清洗。
此外,我将使用术语“嵌入”,通过它我将理解以下内容。 我们有一个卷积神经网络,我们对其进行了分类训练,切除了最后一个分类层,拍摄了一些图像,穿过该网络,并在输出处获得了数值矢量。 我将其称为嵌入。
正如我所说,我们的培训分几个阶段进行,对应于数据库的各个部分。 因此,首先我们采用上一阶段的神经网络或初始化网络。
我们将通过网络运行景点的照片,并进行一些嵌入。 现在您可以清洁底座了。 我们从该景点的数据集中获取所有图片,并且还通过网络驱动每张图片。 我们得到了一堆嵌入,对于每个嵌入,我们都考虑到嵌入标准的距离。 然后我们计算平均距离,如果平均距离大于算法的参数某个阈值,那么我们认为这不是一个旅游胜地。 如果平均距离小于阈值,则留下这张照片。
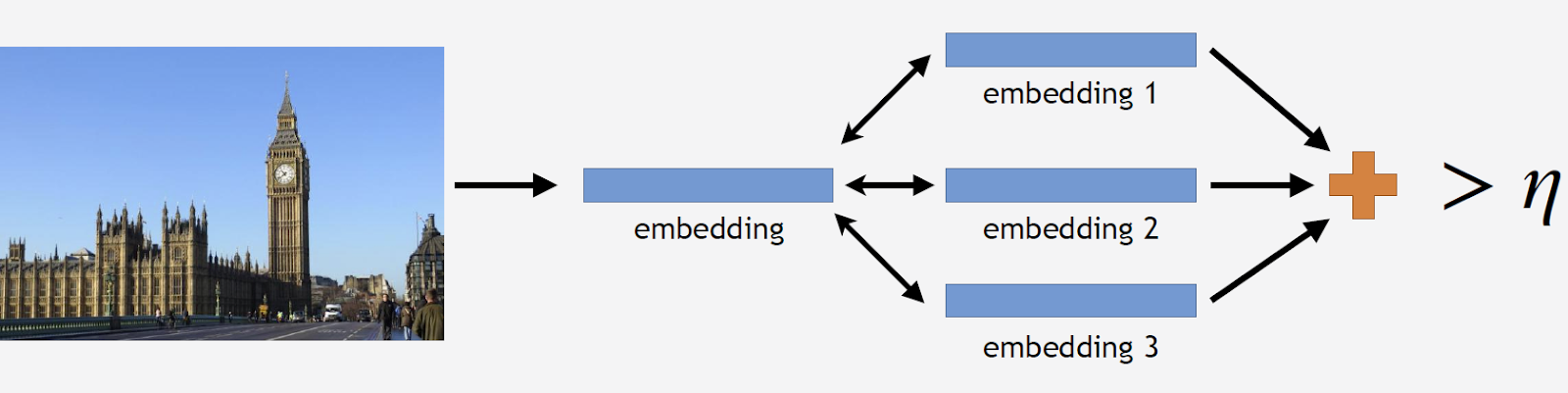
结果,我们得到了一个数据库,其中包含来自世界70个国家/地区的500多个城市的11000多个景点-超过230万张照片。 现在是时候记住大多数照片根本不包含景点了。 该信息需要以某种方式与我们的模型共享。 因此,我们向数据库中添加了90万张无视的照片,并在结果数据集上训练了模型。
为了衡量培训质量,我们引入了离线测试。 基于仅在大约1-3%的照片中发现景物这一事实,我们手动编辑了290张显示景物的照片。 这些是不同的,非常复杂的照片,具有从不同角度拍摄的大量对象,因此对于模型而言,测试要尽可能地困难。 出于同样的原则,我们选择了11千张没有瞄准镜的照片,这些照片也相当复杂,我们试图找到与数据库中的瞄准镜非常相似的对象。
为了评估培训的质量,我们从有和没有瞄准具的照片中测量模型的准确性。 这是我们的两个主要指标。
现有方法
在科学文献中,关于视力识别的信息相对较少。 大多数解决方案基于本地功能。 这个想法是,我们有一个特定的请求图片和一个来自数据库的图片。 在这些图片中,我们找到了局部标志-关键点,并进行了比较。 如果比赛次数足够多,我们认为我们已经找到了兴趣点。
迄今为止,最好的方法是Google提出的方法DELF(深度局部特征),其中将局部特征的比较与深度学习相结合。 通过卷积网络运行输入图像,我们得到一些DELF符号。

如何识别景点? 我们有照片和输入图像的数据库,我们想了解上面是否有旅游胜地。 我们通过DELF运行所有图片,我们获得了基础和输入图像的相应符号。 然后,我们使用最近邻居的方法执行搜索,并在输出中获得带有符号的候选图像。 我们在几何验证的帮助下将这些符号进行比较:如果它们成功通过,则我们认为图片中存在一个关注点。
卷积神经网络
对于深度学习,预培训至关重要。 因此,我们以场景为基础并对其进行了神经网络预训练。 为什么这样 场景是一个复杂的对象,其中包含大量其他对象。 吸引力是场景的特例。 在这样的基础上进行预训练模型,我们可以为模型提供一些低层特征的概念,然后可以对其进行概括以成功识别景点。
作为模型,我们使用了残差网络家族的神经网络。 它们的主要特征是使用残差块,其中包括跳过连接,该残差块允许信号自由通过而不会进入具有权重的层。 使用此架构,您可以定性训练深层网络并处理渐变模糊的影响,这在学习时非常重要。
我们的模型是Wide ResNet 50-2,它是ResNet 50的改进版,其中内部瓶颈模块中的卷积数增加了一倍。

网络非常有效。 我们在场景数据库上进行了测试,结果如下:
事实证明,Wide ResNet的速度几乎是相当大的ResNet 200网络的两倍,并且操作速度对于操作非常重要。 基于这些情况的总和,我们将Wide ResNet 50-2作为主要的神经网络。
培训课程
要训练网络,我们需要损失(损失函数)。 为了选择它,我们决定使用度量学习方法:对神经网络进行训练,以便将同一类别的代表聚集在一起。 同时,不同类别的群集应尽可能地远。 对于景点,我们使用了中心损失,它将相同类别的点汇总到某个中心。 这种方法的一个重要特点是不需要负采样,这在培训的后期是一个相当困难的过程。
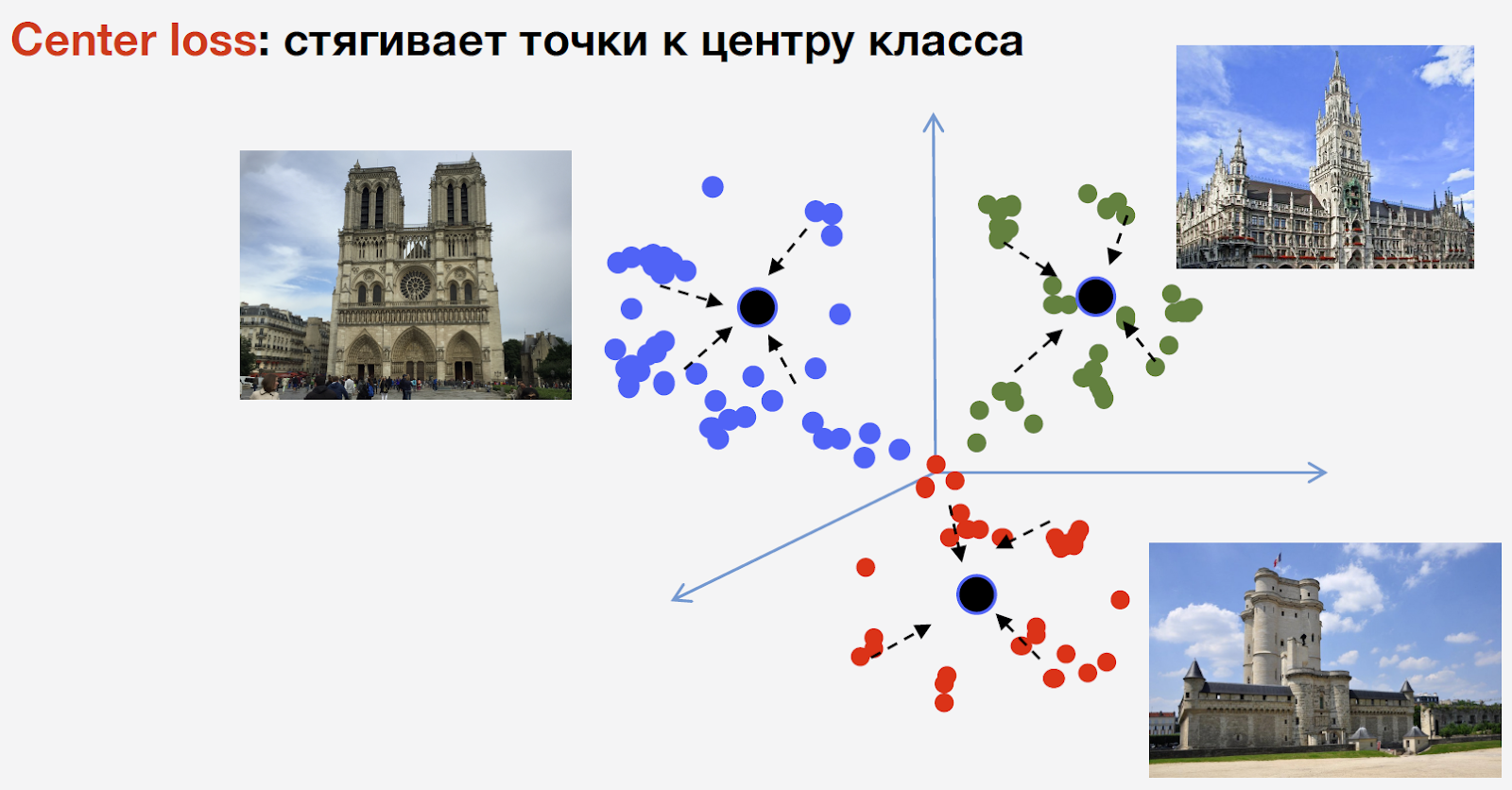
让我提醒您,我们有n个景点,还有另一个“非景点”,中心损失不用于此。 我们的意思是,地标是一个相同的对象,并且内部具有结构,因此建议考虑其中心。 但是,没有一个旅游胜地可以是任何事情,并且为他考虑中心是不合理的。
然后,我们将它们放在一起,并得到了训练模型。 它包括三个主要部分:
- 根据场景预先训练的卷积神经网络Wide ResNet 50-2;
- 嵌入部分由完全连接的层和批处理规范层组成;
- 分类器,是一个完全连接的层,后面是一对Softmax损耗和Center损耗。

您还记得,我们的基地按世界各地分为四个部分。 我们将这四个部分用作课程学习范式的一部分。 在每个阶段,我们都有当前的数据集,我们向世界添加了另一部分,并获得了一个新的训练数据集。
该模型包括三个部分,对于每个部分,我们都在训练中使用自己的学习率。 这是必要的,以便网络不仅可以从我们添加的数据集的新部分中学习景点,而且还可以不忘记已经学习的数据。 经过多次实验,这种方法被证明是最有效的。
因此,我们训练了模型。 您需要了解其工作原理。 让我们使用类激活图来查看图像的哪个部分对我们的神经网络最敏感。 在下面的图片中,第一行是输入图像,第二行是来自网格的叠加的类激活图,我们在上一步中对其进行了训练。

热图显示网络需要更多关注图像的哪些部分。 从类激活图可以看出,我们的神经网络已成功学习了吸引的概念。
推论
现在,您需要以某种方式使用此知识来获得结果。 由于我们使用中心损失进行训练,因此推断吸引力的tserotoid也很合逻辑。
为此,我们从训练集中获取了一部分图像,以吸引人们,例如青铜骑士。 我们通过网络运行它们,获取嵌入,取平均值并获得质心。
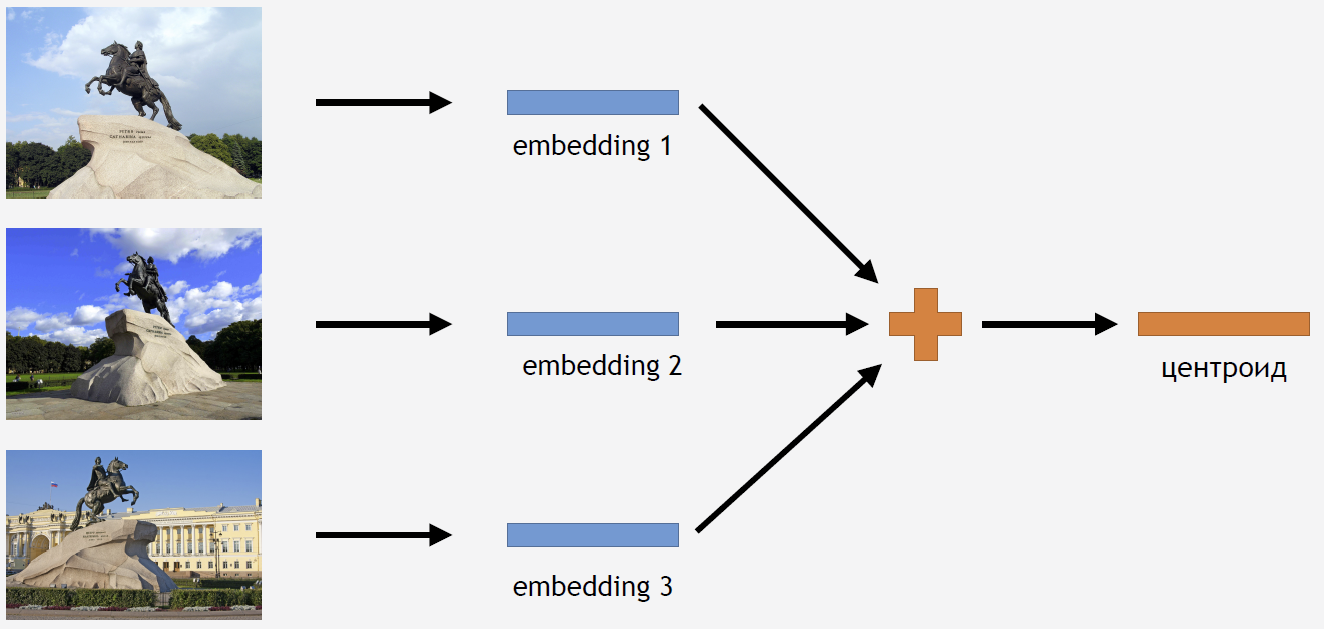
但是问题来了:一个吸引力有多少个质心才有意义? 最初,答案似乎很明确且合乎逻辑:一个质心。 但是事实并非如此。 起初,我们还决定制作一个质心,并取得了不错的效果。 那么,为什么需要几个质心呢?
首先,我们的数据并不完全干净。 尽管我们清理了数据集,但仅删除了完全垃圾。 而且,我们可能会有无法被视为垃圾的图像,但这会使结果恶化。
例如,我有一个冬宫地标课程。 我想为他数个质心。 但是布景包括许多与宫殿广场和总参谋部大楼拱门合影的照片。 如果我们在所有图像中都考虑质心,结果将不会太稳定。 有必要对它们的嵌入进行聚类,这些嵌入是从常规网格中获得的,仅采用负责冬宫的质心,并根据这些数据计算平均值。

其次,可以从不同角度拍摄照片。
我将引用布鲁日的Belfort钟楼作为这种行为的例证。 她算出两个质心。 图像的上排是靠近第一个质心的那些照片,第二排是靠近第二个质心的那些照片:

第一个质心负责从布鲁日市场广场拍摄的更“智能”的特写照片。 第二个质心负责从远处,相邻街道拍摄的照片。
事实证明,通过计算兴趣点的每个类的几个质心,我们可以在推理中显示该兴趣点的不同角度。
那么,我们如何找到这些集合来计算质心? 我们将分层聚类应用于每个兴趣点的数据集-完整链接。 在它的帮助下,我们找到了有效的聚类,以此可以计算质心。 有效聚类是指由于聚类而包含至少50张照片的聚类。 其余的群集将被丢弃。 结果,事实证明,大约20%的景点具有不止一个质心。
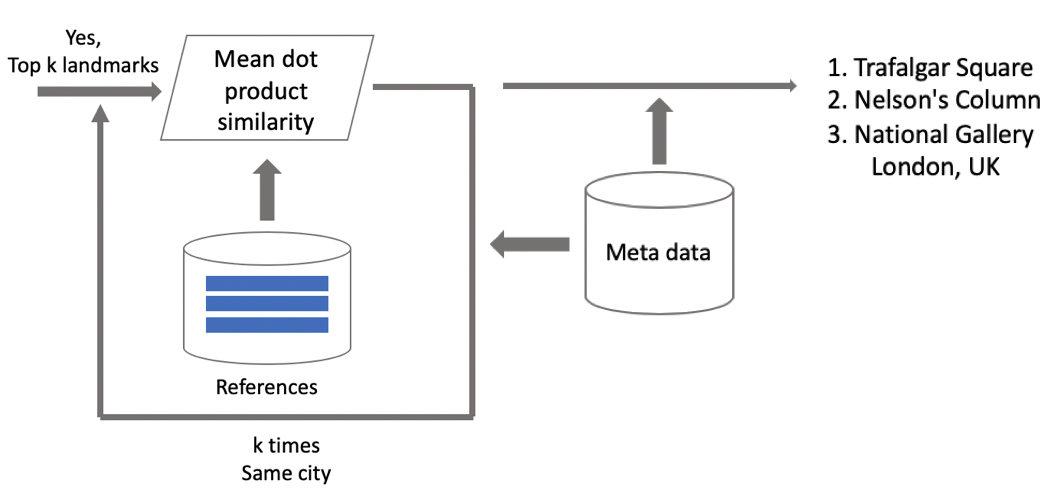
现在推断。 我们分两个阶段进行计算:首先,通过卷积神经网络运行输入图像并进行嵌入,然后使用标量积将嵌入与质心进行比较。 如果图像包含地理数据,则我们将搜索限制为质心,质心与距拍摄位置每1公里1个正方形中的景点有关。 这使您可以更精确地搜索,选择较低的阈值以进行后续比较。 如果获得的距离大于阈值(这是算法的参数),那么我们说照片中存在一个关注点,其标量积的最大值。 如果少于,那么这不是一个旅游胜地。
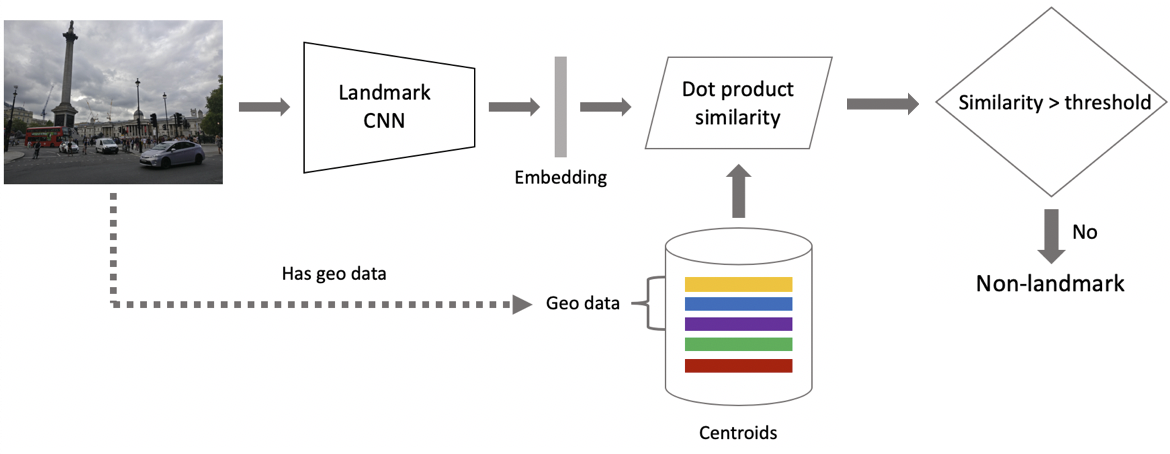
假设照片包含一个地标。 如果我们有地理数据,那么我们将使用它们并显示答案。 如果没有地理数据,那么我们将另外进行检查。 清理数据集时,我们为每个景点类别制作了一组参考图像。 对于它们,我们可以对嵌入进行计数,然后计算从它们到请求图片的嵌入的平均距离。 如果超过某个阈值,那么将通过验证,我们将包含元数据并显示结果。 重要的是要注意,我们可以对图像中发现的多个吸引力执行此过程。
测试结果
我们将模型与DELF进行了比较,为此我们采用了在测试中显示最佳结果的参数。 结果几乎相同。
然后,我们将景点分为两种类型:频繁(超过100张照片),占测试中所有景点的87%;罕见。通常,我们的模型运行良好:准确度为85.3%。很少看到的东西,我们得到了46%,这也非常好-即使有少量数据,我们的方法也显示出不错的效果。/B- . 10 %, 3 %, 13 %.
DELF. GPU DELF 7 , 7 , 1 . CPU DELF . CPU 15 . , .
:
. .
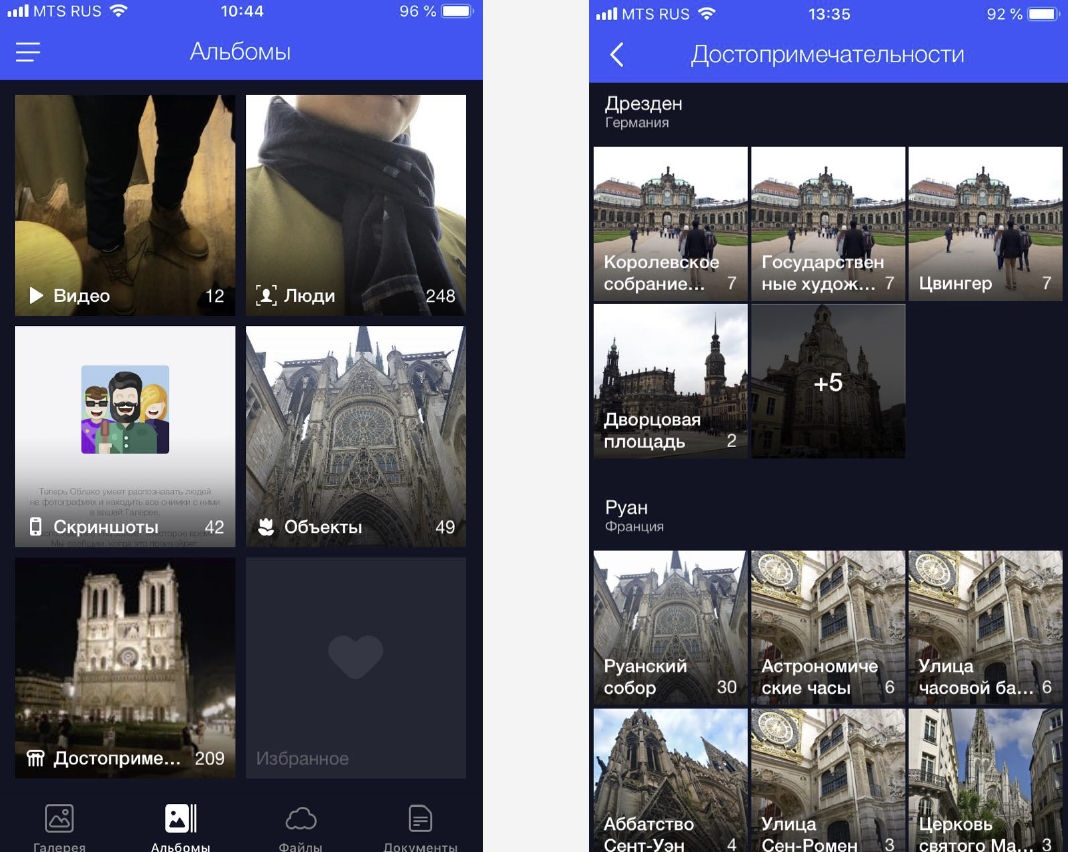
, . «», «», «». , . , .
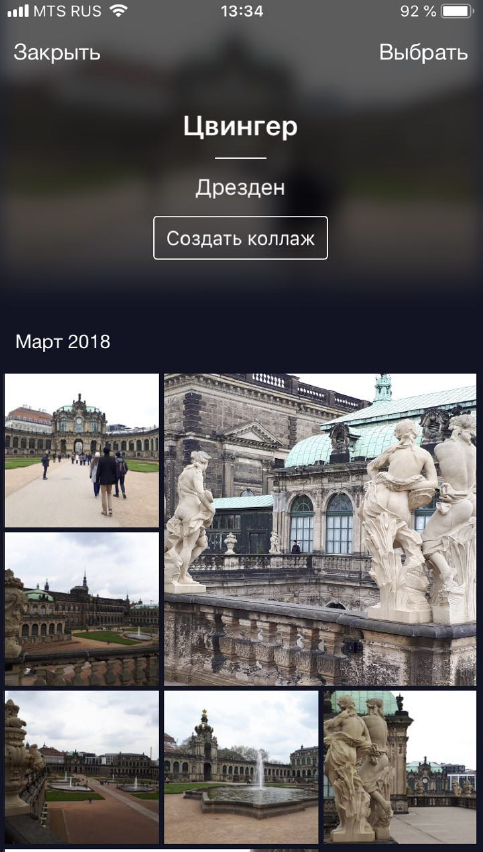
: , , . Instagram , , — .
.
- . , . .
- deep metric learning, .
- curriculum learning — . . inference , .
, — . , , . - . !