不幸的是,现在性能调整和数据库故障排除中的专家作用只被减少到了最后一个-故障排除:只有在问题已经达到临界点并且需要在“昨天”解决时,他们才几乎总是求助于专家。 即使这样,如果他们转身也很好,不要购买价格昂贵且功能强大的硬件,而无需进行详细的性能审核和压力测试,就不会延迟问题。 的确,挫败感经常就够了:他们购买的设备价格昂贵了2-5倍,而性能却只获得了30-40%,而用户数量的增加或数据的指数级增长以及逻辑的复杂性在几个月内就抵消了全部增长。
而现在,在架构师,测试人员和DevOps工程师的数量迅速增长的同时,Java Core开发人员甚至在优化
使用字符串的过程中也很缓慢,但肯定是数据库优化器的时机到了。 每个版本的DBMS都变得更加智能和复杂,以至于研究已记录和未记录的细微差别和优化都需要大量时间。 每月发表大量文章,并举行专门讨论Oracle的大型会议。 很抱歉,这种平庸的比喻,但是在这种情况下,当数据库管理员变得与拥有无数拨动开关,按钮,指示灯和屏幕的飞机飞行员相似时,就已经不足以为它们加载性能优化的微妙之处。
当然,与飞行员一样,DBA在大多数情况下都可以轻松地解决显而易见的简单问题,只要可以轻松地将其诊断出来或在各种“顶部”(顶部事件,顶部SQL,顶部段...)中将其注意到即可。 即使他们不知道解决方案,也可以在MOS或Google上轻松找到它们。 当症状甚至隐藏在系统复杂性的背后并且需要从Oracle DBMS本身收集的大量诊断信息中剔除时,情况就更加复杂了。
最简单,最生动的示例之一就是对过滤器和访问预测的分析:在大型且负载较大的系统中,经常会轻易忽略此问题,因为 负载相当平均地分布在不同的请求上(具有针对各种表的联接,条件略有不同等),并且最上面的段没有显示任何特殊内容,他们说:“是的,从这些表中最经常需要数据,并且还有更多数据” 。 在这种情况下,可以使用来自SYS.COL_USAGE $:
col_usage.sql的统计信息开始分析。
col owner format a30 col oname format a30 heading "Object name" col cname format a30 heading "Column name" accept owner_mask prompt "Enter owner mask: "; accept tab_name prompt "Enter tab_name mask: "; accept col_name prompt "Enter col_name mask: "; SELECT a.username as owner ,o.name as oname ,c.name as cname ,u.equality_preds as equality_preds ,u.equijoin_preds as equijoin_preds ,u.nonequijoin_preds as nonequijoin_preds ,u.range_preds as range_preds ,u.like_preds as like_preds ,u.null_preds as null_preds ,to_char(u.timestamp, 'yyyy-mm-dd hh24:mi:ss') when FROM sys.col_usage$ u , sys.obj$ o , sys.col$ c , all_users a WHERE a.user_id = o.owner
但是,仅对该信息进行全面分析是不够的,因为 它不显示谓词的组合。 在这种情况下,对v $ active_session_history和v $ sql_plan的分析可以帮助我们:
with ash as ( select sql_id ,plan_hash_value ,table_name ,alias ,ACCESS_PREDICATES ,FILTER_PREDICATES ,count(*) cnt from ( select h.sql_id ,h.SQL_PLAN_HASH_VALUE plan_hash_value ,decode(p.OPERATION ,'TABLE ACCESS',p.OBJECT_OWNER||'.'||p.OBJECT_NAME ,(select i.TABLE_OWNER||'.'||i.TABLE_NAME from dba_indexes i where i.OWNER=p.OBJECT_OWNER and i.index_name=p.OBJECT_NAME) ) table_name ,OBJECT_ALIAS ALIAS ,p.ACCESS_PREDICATES ,p.FILTER_PREDICATES
从查询本身可以看到,它显示前50个搜索列,并根据最近3个小时ASH命中的次数来作为谓词。 尽管ASH仅每秒存储一次快照,但以已加载的基准进行采样还是很有代表性的。 它可以阐明以下几点:
- cols字段-显示搜索列本身,total_by_cols-这些列的上下文中条目的总和。
- 我认为很明显,这些信息本身不足以解决问题,因为 例如,几次一次性全扫描很容易破坏统计信息,因此您绝对必须考虑查询本身及其频率(v $ sqlstats,dba_hist_sqlstat)
- 在SQL_ID内按OBJECT_ALIAS进行分组,plan_hash_value对于按对象组合索引和表谓词很重要,因为 通过索引访问表时,谓词将分为计划的不同行:
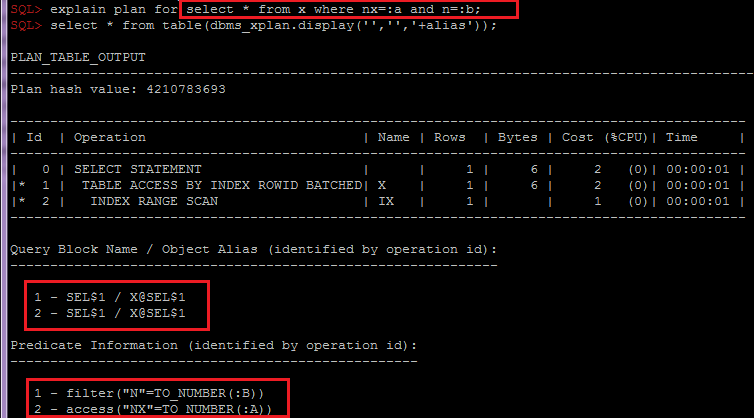
根据需要,可以轻松修改此脚本以收集其他部分中的其他信息,例如,考虑分区或期望值。 并且已经分析了这些信息,再加上对表统计信息及其索引,常规数据方案和业务逻辑的分析,您可以将建议传递给开发人员或架构师以选择解决方案,例如:用于非规范化或更改分区方案或索引的选项。
分析SQL *网络流量也经常被遗忘,并且还有很多细微之处,例如:fetch-size,SQLNET.COMPRESSION,扩展的数据类型,这些数据类型可减少往返次数,等等,但这是另一篇文章的主题。
总之,我想说的是,由于用户对延迟的容忍度越来越低,优化性能已成为一项竞争优势。