我们开始撰写一系列文章,描述各种情况,在这些情况下,为开发人员使用英特尔工具极大地提高了软件的速度并提高了质量。
我们的第一个故事发生在新西伯利亚大学,研究人员开发了一种软件工具,用于对氢离子化过程中的磁流体动力学问题进行数值模拟。 这项工作是作为对天体物理对象
AstroPhi进行建模的全球项目的一部分进行的;
英特尔至强融核处理器被用作硬件平台。 使用
Intel Advisor和
Intel Trace Analyzer and Collector的结果是,计算性能提高了3倍,解决一个问题的速度从一周减少到了两天。
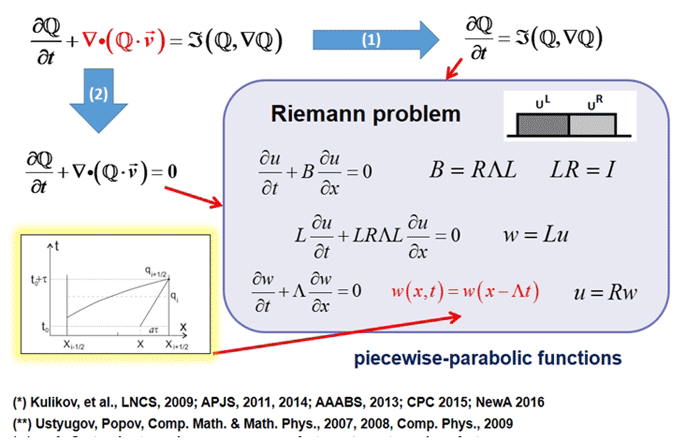
任务说明
就像任何科学一样,数学建模在现代天体物理学中起着重要作用。 这是研究宇宙中非线性演化过程的通用工具。 复杂的天体过程的高分辨率建模需要大量的计算资源。 NSU的AstroPhi项目正在为基于Intel Xeon Phi处理器的超级计算机开发天体软件代码。 学生将学习为极度并行化的运行时编写仿真程序,从而获得与其他超级计算机一起使用时所需要的重要知识。
该项目中使用的数值建模方法具有许多重要的优点:
- 缺乏人造粘度,
- 伽利略不变性
- 保证不降低熵,
- 简单并行化
- 潜在的无限扩展性。
前三个因素是对天体物理问题中的重大物理效应进行现实建模的关键。
该研究团队已经基于Intel Xeon Phi创建了一个用于多并行架构的新建模工具。 它的主要任务是避免节点之间数据交换的瓶颈,并尽可能简化代码优化。 并行化解决方案使用MPI,并且对于矢量化,英特尔高级矢量扩展512(Intel AVX-512)指令增加了对512位SIMD的支持,并允许程序打包8个双精度浮点数或16个单精度浮点数(32位) )向量为512位长。 因此,每条指令处理的数据元素是使用AVX / AVX2时的两倍,是使用SSE时的四倍。
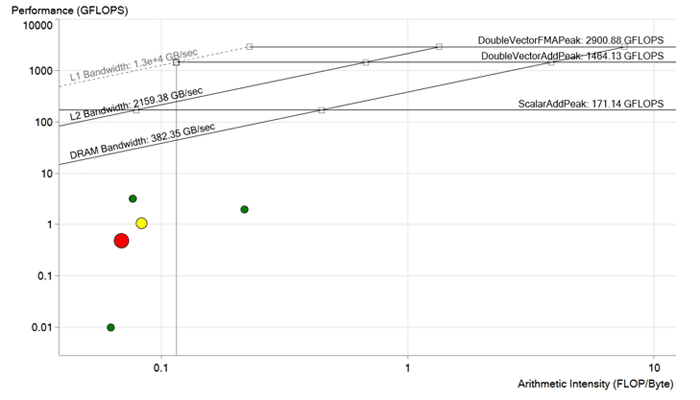 优化前的图片。 每个点都是一个处理周期。 点越大和越红,循环持续的时间越长,其优化效果越明显。 红点位于DRAM带宽限制之下,并且计算得出的性能低于1 GFLOP。 它有很大的改进潜力。
优化前的图片。 每个点都是一个处理周期。 点越大和越红,循环持续的时间越长,其优化效果越明显。 红点位于DRAM带宽限制之下,并且计算得出的性能低于1 GFLOP。 它有很大的改进潜力。代码优化
在优化之前,代码在依赖项和向量大小方面存在某些问题。 优化目标是使用针对Xeon Phi的最佳矢量和数组大小,消除矢量的依赖性,并改善将数据加载到内存的操作。 为了进行优化,我们使用了
Intel Advisor和
Intel Trace Analyzer and Collector (这是
Intel Parallel Studio XE的两个工具)。
顾名思义,
英特尔顾问是一个顾问-一种评估优化程度的软件工具-矢量化(使用AVX或SIMD指令)和并行化以实现最佳性能。 使用此工具,团队可以对循环进行概述分析,突出显示那些生产率较低的循环,指出改进的潜力,并确定可以改进的地方以及游戏是否值得。 英特尔智能顾问按潜在的,已添加的消息的来源对周期进行了排序,以提高编译器报告的可读性。 他还提供了重要信息,例如周期时间,数据依存关系以及用于安全有效地矢量化的内存访问模式。
英特尔跟踪分析器和收集器是优化代码的另一种方法。 它包括对MPI通信和分析功能进行概要分析,以改善弱扩展和强扩展。 该图形工具帮助团队了解应用程序的MPI行为,快速发现瓶颈,最重要的是,提高了英特尔架构的性能。
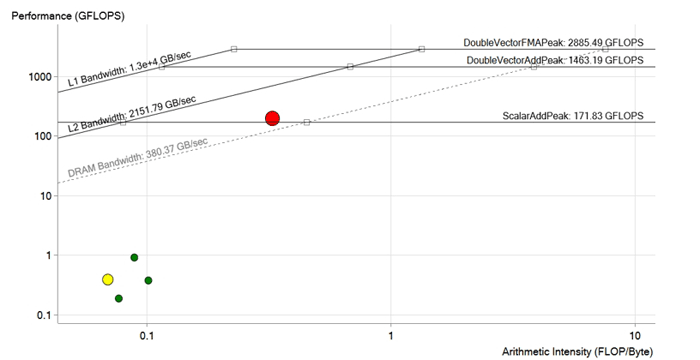 优化后的图片。 在红色循环优化过程中,移除了矢量化依赖性,优化了向内存的加载操作,针对Intel Xeon Phi和AVX-512指令调整了矢量和数组的大小。 性能提高到190 GFLOPS,即大约200倍。 现在它已超出DRAM限制,很可能受L2缓存的特性限制
优化后的图片。 在红色循环优化过程中,移除了矢量化依赖性,优化了向内存的加载操作,针对Intel Xeon Phi和AVX-512指令调整了矢量和数组的大小。 性能提高到190 GFLOPS,即大约200倍。 现在它已超出DRAM限制,很可能受L2缓存的特性限制结果
因此,经过所有的改进和优化,该团队获得了190 GFLOPS的性能,算术强度为0.3 FLOP / b,利用率为100%,内存带宽为573 GB / s。
 优化的代码段
优化的代码段