有问题的文章。
引言
现代识别系统仅限于分类为相对少量的语义无关的类。 吸引文字信息,甚至与图片无关,都可以丰富模型并在一定程度上解决以下问题:
- 如果识别模型出错,那么该错误通常在语义上不接近正确的类;
- 无法预测训练数据集中未包含的属于新类的对象。
所提出的方法建议在丰富的语义空间中显示图像,在该语义空间中,相似度较低的类别的标签比相似度较低的类别的标签彼此更靠近。 结果,该模型在语义上与真实预测类别的距离较小。 此外,考虑到视觉和语义上的接近性,该模型可以正确地分类与训练数据集中未表示的类别相关的图像。
演算法 建筑学
- 我们预先训练了语言模型,该模型提供了良好的语义上有意义的嵌入。 空间的维数是n。 接下来,将取n等于500或1000。
- 我们预训练了视觉模型,该模型将对象很好地分为1000个类。
- 我们从预先训练的视觉模型中切除了最后一个softmax层,并添加了一个从4096到n个神经元的完全连接层。 我们为每个图像训练结果模型,以预测对应于图像标签的嵌入。
让我们在映射的帮助下进行解释。 令LM为语言模型,VM为具有截止softmax并添加完全连接层的可视模型,I-图像,L-图像标签,LM(L)-标签嵌入语义空间。 然后在第三步中,我们训练VM,以便:
架构:
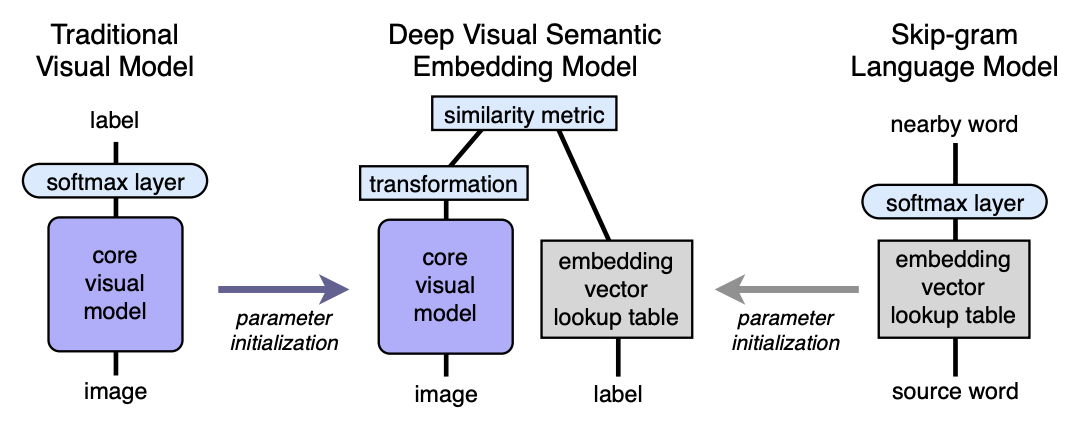
语言模型
为了学习语言模型,使用了跳过语法模型,这是一个来自Wikipedia.org的54亿个单词的语料库。 该模型使用分层的softmax层来预测相关概念,一个窗口-20个单词,通过人体的次数-1。通过实验确定,嵌入大小最好取500-1000。
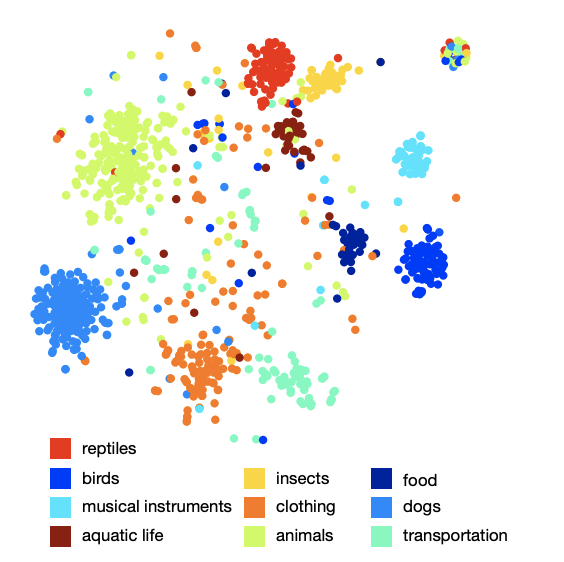
类别在空间中的排列图显示该模型已学习了定性且丰富的语义结构。 例如,对于在所得语义空间中的某些种类的鲨鱼,其他9种类型的鲨鱼是9个最近的邻居。
视觉模型
赢得2012年ILSVRC竞赛的架构被视为视觉模型。 移除其中的Softmax,并添加一个完全连接的层,以在输出处获得所需的嵌入大小。
损失函数
事实证明,损失函数的选择很重要。 使用余弦相似度和铰链秩损失的组合。 损失函数鼓励在视觉网络的结果向量和相应的标签嵌入之间使用较大的标量积,并对在视觉网络的结果和随机可能的图像标签的嵌入之间使用较大的标量产品进行罚款。 任意随机标签的数量不是固定的,但受以下条件的限制:带有错误标签的标量积之和大于带有有效标签的标量积减去固定边距(常数等于0.1)。 当然,所有向量都已预先标准化。
培训过程
刚开始时,仅训练了最后一个添加的全连接层,网络的其余部分未更新权重。 在这种情况下,将使用SGD优化方法。 然后,使用Adagrad优化器解冻和训练整个可视网络,以便在网络的不同层上反向传播期间,渐变可以正确缩放。
预言
在预测过程中,使用视觉网络从图像中获取语义空间中的某些向量。 接下来,我们找到最近的邻居,即一些可能的标签,并以特殊方式将它们显示回ImageNet同义词集中以进行评分。 上一次显示的过程不是那么简单,因为ImageNet中的标签是一组同义词,而不仅仅是一个标签。 如果读者有兴趣了解详细信息,建议您阅读原始文章(附录2)。
结果
将DEVISE模型的结果与两个模型进行了比较:
- Softmax基线模型-最新的视觉模型(SOTA-发布时)
- 随机嵌入模型是所描述的DEVISE模型的一种版本,其中嵌入不是由语言模型学习的,而是被任意初始化的。
为了评估质量,使用了“平坦”匹配@ k指标和分层精度@ k指标。 度量“平坦”命中@ k是在前k个预测选项中存在正确标签的测试图像的百分比。 分层精度@ k度量用于评估语义对应的质量。 此指标基于ImageNet中的标签层次结构。 对于每个真标签和固定k,
语义正确的标签-基本事实列表。 得到预测(最近的邻居)是与地面真相列表相交的百分比。

作者期望softmax模型应在扁平度量上显示最佳结果,因为它使交叉熵损失最小,这非常适合“扁平” hit @ k度量。 作者感到惊讶的是,DEVISE模型与softmax模型多么接近,在k大时达到奇偶校验,甚至在k = 20时超车。
在分层度量标准上,DEVISE模型在所有方面都展现出了自己的魅力,并且在k = 5时超过了softmax棒球,在k = 20时超过了7%。
零镜头学习
DEVISE模型的一个特殊优势是能够为训练期间网络从未见过的图像提供足够的预测。 例如,在训练期间,网络看到标记为虎鲨,公牛鲨和蓝鲨的图像,但从未达到鲨鱼标记。 由于语言模型在语义空间中具有鲨鱼的表示并且接近不同类型鲨鱼的嵌入,因此该模型很可能给出适当的预测。 这称为泛化能力-泛化。
让我们演示零发散预测的一些示例:

请注意,即使在错误假设下,DEVISE模型也比softmax模型的错误假设更接近正确答案。
因此,所提出的模型在平面度量标准上损失了一些到softmax到基线的水平,但是在k度量标准上的分层精度上却明显获胜。 该模型具有泛化能力,可以为网络标签未满足的图像产生足够的预测(零镜头学习)。
所描述的方法很容易实现,因为它基于两个预先训练的模型-语言和视觉。