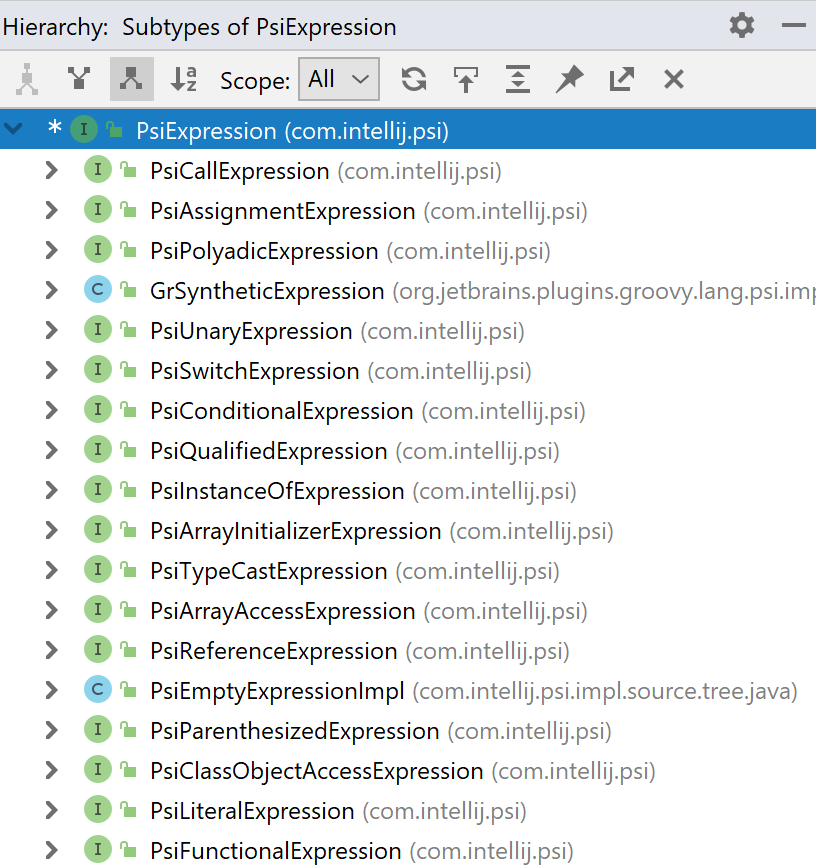
 代码搜索和导航是任何IDE的重要功能。 在Java中,常用的搜索选项之一是搜索接口的所有实现。 此功能通常称为“类型层次结构”,它看起来就像右边的图像一样。
代码搜索和导航是任何IDE的重要功能。 在Java中,常用的搜索选项之一是搜索接口的所有实现。 此功能通常称为“类型层次结构”,它看起来就像右边的图像一样。
调用此功能时,遍历所有项目类的效率很低。 一种选择是在编译期间将完整的类层次结构保存在索引中,因为无论如何编译器都会构建它。 当编译是由IDE运行而不是委托给Gradle时,我们将执行此操作。 但这仅在编译后模块中未进行任何更改的情况下有效。 通常,源代码是最新的信息提供者,而索引基于源代码。
如果我们不处理功能接口,那么找到直子是一个简单的任务。 在搜索Foo接口的实现时,我们需要找到所有implements Foo的类和extends Foo接口,以及new Foo(...) {...}匿名类。 为此,预先构建每个项目文件的语法树,找到相应的构造,然后将它们添加到索引中就足够了。 但是,这里有一个复杂之处:您可能正在寻找com.example.goodcompany.Foo接口,而实际上是在使用org.example.evilcompany.Foo 。 我们可以预先将父接口的全名放入索引中吗? 这可能很棘手。 例如,使用该接口的文件可能如下所示:
仅通过查看文件,就无法确定Foo的实际完全限定名称是什么。 我们将不得不研究几个软件包的内容。 每个包都可以在项目中的多个位置定义(例如,在多个JAR文件中)。 如果我们在分析此文件时执行正确的符号解析,则索引将花费大量时间。 但是主要的问题是,基于MyFoo.java构建的索引MyFoo.java将依赖于其他文件。 例如,我们可以将Foo接口的声明从org.example.foo包移动到org.example.bar包,而无需更改MyFoo.java文件中的任何内容,但是Foo的完全限定名称会更改。
在IntelliJ IDEA中,索引仅取决于单个文件的内容。 一方面,这非常方便:更改文件时,与特定文件关联的索引无效。 另一方面,它对可放入索引的内容施加了主要限制。 例如,它不允许将父类的完全限定名称可靠地保存在索引中。 但是,总的来说,还不错。 请求类型层次结构时,我们可以通过短名称找到与请求相匹配的所有内容,然后对这些文件执行正确的符号解析,并确定这是否是我们要查找的内容。 在大多数情况下,冗余符号不会太多,检查不会花费很长时间。
 但是,当我们要寻找其孩子的班级是一个功能接口时,情况就变了。 然后,除了显式和匿名子类外,还将有lambda表达式和方法引用。 我们现在将什么放入索引中,以及在搜索过程中要评估什么?
但是,当我们要寻找其孩子的班级是一个功能接口时,情况就变了。 然后,除了显式和匿名子类外,还将有lambda表达式和方法引用。 我们现在将什么放入索引中,以及在搜索过程中要评估什么?
假设我们有一个功能接口:
@FunctionalInterface public interface StringConsumer { void consume(String s); }
该代码包含不同的lambda表达式。 例如:
() -> {}
这意味着我们可以快速筛选出参数数量不合适或返回类型明显不合适的lambda,例如,void而非non-void。 通常不可能更精确地确定返回类型。 例如,在s -> list.add(s)您将必须解析list和add ,并且有可能运行常规的类型推断过程。 这需要时间,并取决于其他文件的内容。
如果函数接口接受五个参数,我们很幸运。 但是,如果只用一个,过滤器将保留大量不必要的lambda。 当涉及到方法引用时,情况甚至更糟。 从外观上看,无法确定方法引用是否合适。
为了弄清楚事情,可能值得研究一下lambda周围的东西。 有时,它可以工作。 例如:
在所有这些情况下,可以从当前文件中确定相应功能接口的简称,并将其放在功能表达式旁边的索引中,无论是lambda还是方法引用。 不幸的是,在现实生活中的项目中,这些情况仅占所有lambda的很小一部分。 在大多数情况下,lambda用作方法参数:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
三个lambda中的哪一个可以包含StringConsumer ? 显然没有。 在这里,我们有一个Stream API链,它仅具有标准库中的功能接口,而不能具有自定义类型。
但是,IDE应该能够看透窍门并为我们提供准确的答案。 如果list并非完全是java.util.List ,并且list.stream()返回与java.util.stream.Stream不同的东西怎么办? 然后,我们将不得不解析list ,众所周知,仅根据当前文件的内容就无法可靠地完成list 。 即使我们这样做,搜索也不应依赖于标准库的实现。 如果在这个特定项目中我们用自己的类替换了java.util.List ,该怎么办? 搜索必须考虑到这一点。 而且,自然地,lambda不仅在标准流中使用:它们还传递给许多其他方法。
结果,我们可以在索引中查询所有使用lambda的Java文件的列表,这些文件具有必需的参数数量和有效的返回类型(实际上,我们仅搜索四个选项:void,non-void,boolean和任何)。 接下来呢? 我们是否需要为每个文件构建完整的PSI树(一种具有符号解析,类型推断和其他智能功能的解析树),并对lambda执行正确的类型推断? 对于大型项目,即使只有两个接口实现列表,也要花费很多时间。
因此,我们需要采取以下步骤:
- 询问指数(不昂贵)
- 建立PSI(成本高)
- 推断lambda类型(非常昂贵)
对于Java 8和更高版本,类型推断是一项非常昂贵的操作。 在复杂的调用链中,可能会有许多替代通用参数,这些参数的值必须使用规范第18章中所述的强制步骤来确定。 对于当前文件,这可以在后台完成,但是以这种方式处理数千个未打开的文件将是一项昂贵的任务。
但是,在这里可以稍微偷工减料:在大多数情况下,我们不需要具体的类型。 除非方法接受将lambda传递给它的通用参数,否则可以避免最后的参数替换步骤。 如果我们推断出java.util.function.Function<T, R> lambda类型,则不必评估替换参数T和R的值:已经很清楚是否将lambda包含在搜索结果中或不。 但是,它不适用于这样的方法:
static <T> void doSmth(Class<T> aClass, T value) {}
可以使用doSmth(Runnable.class, () -> {})调用此方法。 然后,lambda类型将被推断为T ,仍然需要替换。 但是,这种情况很少见。 实际上,我们可以在这里节省一些CPU时间,但只能节省大约10%,因此这本质上不能解决问题。
或者,当精确类型推断太复杂时,可以使其近似。 与规范所建议的不同,让它仅适用于已擦除的类类型,并且不减少约束集,而仅遵循调用链即可。 只要擦除的类型不包含通用参数,一切都很好。 让我们考虑上面示例中的流,并确定最后一个lambda是否实现StringConsumer :
list变量-> java.util.List类型List.stream()方法→ java.util.stream.Stream类型Stream.filter(...)方法-> java.util.stream.Stream类型,我们不必考虑filter参数- 同样,
Stream.map(...)方法→ java.util.stream.Stream类型 Stream.forEach(...)方法→存在这样的方法,其参数具有Consumer类型,这显然不是StringConsumer 。
这就是我们不进行常规类型推断就可以做到的方式。 但是,使用这种简单方法,很容易遇到重载方法。 如果我们不执行正确的类型推断,则无法选择正确的重载方法。 但是,有时这是可能的:如果方法具有不同数量的参数。 例如:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));
在这里我们可以看到:
- 有两个
CompletableFuture.supplyAsync方法; 第一个有一个参数,第二个有两个参数,因此我们选择第二个。 它返回CompletableFuture 。 thenRunAsync方法也有两种,我们可以类似地选择采用一个参数的方法。 相应的参数具有Runnable类型,这意味着它不是StringConsumer 。
如果几种方法采用相同数量的参数或具有可变数量的参数但看上去合适,那么我们将必须搜索所有选项。 通常情况并不那么可怕:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));
new StringBuilder()显然会创建java.lang.StringBuilder 。 对于构造函数,我们仍然解析该引用,但是这里不需要复杂的类型推断。 即使有new Foo<>(x, y, z) ,我们也不会推断类型参数的值,因为我们只对Foo感兴趣。- 有很多采用一个参数的
StringBuilder.append方法,但是它们都返回java.lang.StringBuilder类型,因此我们不在乎foo和bar的类型。 - 有一个
StringBuilder.chars方法,它返回java.util.stream.IntStream 。 - 有一个
IntStream.forEach方法,它采用IntConsumer类型。
即使剩下几个选项,您仍然可以跟踪它们。 例如,传递给ForkJoinPool.getInstance().submit(...)的lambda类型可以是Runnable或Callable ,并且如果我们正在寻找其他选项,我们仍然可以丢弃此lambda。
当该方法返回通用参数时,情况会变得更糟。 然后,该过程将失败,您必须执行正确的类型推断。 但是,我们支持一种情况。 它在我的StreamEx库中得到了很好的展示,该库具有AbstractStreamEx<T, S extends AbstractStreamEx<T, S>>抽象类,其中包含诸如S filter(Predicate<? super T> predicate) 。 通常,人们使用具体的StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>>类。 在这种情况下,您可以替换type参数并找出S = StreamEx 。
这就是我们在许多情况下摆脱昂贵的类型推断的方式。 但是我们在PSI的构建上还没有做任何事情。 解析具有500行代码的文件只是发现第480行的lambda与我们的查询不匹配,这令人失望。 让我们回到我们的流:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
如果list是局部变量,方法参数或当前类中的字段(已经在索引阶段),则可以找到其声明并确定短类型名称为List 。 因此,我们可以将以下信息放入最后一个lambda的索引中:
此lambda类型是forEach方法的参数类型,该方法采用一个参数,在使用一个参数的map方法的结果上调用,在使用一种参数的filter方法的结果上调用,在stream方法的结果上调用它接受零个参数,在List对象上调用。
所有这些信息都可以从当前文件中获得,因此可以放置在索引中。 在搜索时,我们从索引中请求有关所有lambda的此类信息,并尝试在不构建PSI的情况下还原lambda类型。 首先,我们必须使用短List名称对类进行全局搜索。 显然,我们不仅可以找到java.util.List而且可以找到java.awt.List或项目代码中的某些内容。 接下来,所有这些类将经历与我们之前使用的相同的近似类型推断过程。 冗余类经常被快速过滤掉。 例如, java.awt.List没有stream方法,因此将其排除在外。 但是,即使有多余的东西,并且我们找到了lambda类型的多个候选者,也没有一个可能与搜索查询匹配,并且我们仍将避免构建完整的PSI。
全局搜索可能成本很高(当一个项目包含太多List类时),或者无法在一个文件的上下文中解析链的开头(例如,这是父类的一个字段),或者该方法返回通用参数时,链可能会断开。 我们不会放弃,并且将尝试从全球搜索开始寻找链的下一个方法。 例如,对于map.get(key).updateAndGet(a -> a * 2)链,以下指令进入索引:
此lambda类型是updateAndGet方法的单个参数的类型,该方法在具有一个参数的get方法的结果上调用,该方法在Map对象上调用。
假设我们很幸运,该项目只有一个Map类型java.util.Map 。 它确实具有get(Object)方法,但是不幸的是,它返回通用参数V 然后,我们将丢弃该链,并在全局范围内寻找带有一个参数的updateAndGet方法(当然使用索引)。 我们很高兴发现项目中只有三种方法:分别在AtomicInteger , AtomicLong和AtomicReference类中使用参数类型IntUnaryOperator , LongUnaryOperator和UnaryOperator 。 如果我们正在寻找其他任何类型,我们已经发现该lambda与请求不匹配,并且我们不必构建PSI。
令人惊讶的是,这是一个功能随时间推移变慢的很好示例。 例如,当您在寻找功能接口的实现并且在项目中只有三个时,IntelliJ IDEA会花十秒钟的时间来找到它们。 您还记得三年前它们的数量相同,但是IDE在同一台计算机上仅两秒钟就为您提供了搜索结果。 尽管您的项目规模巨大,但这些年来它仅增长了5%。 开始抱怨IDE开发人员做错了什么使它变得如此缓慢非常合理。
虽然我们可能什么都没有改变。 搜索工作与三年前一样。 事实是,三年前,您刚切换到Java 8,而您的项目中只有100个lambda。 到目前为止,您的同事已经将匿名类转换为lambda,开始使用流或某些反应式库。 结果,不是一百个lambda,而是一万个。 现在,要找到三个必要的选项,IDE必须搜索一百倍以上的选项。
我说“我们可以”,是因为我们自然会不时返回此搜索并尝试加快搜索速度。 但这就像在溪流中划船,或者是在瀑布上划船一样。 我们尽力而为,但是项目中的lambda数量一直在快速增长。