据
统计 ,分布式计算和大数据市场每年以18-19%的速度增长。 因此,出于这些目的选择软件的问题仍然很重要。 在本文中,我们从为何需要分布式计算开始,然后详细介绍软件的选择,并讨论将Hadoop与Cloudera一起使用,最后讨论如何选择硬件以及它如何以不同的方式影响性能。
为什么我们在常规业务中需要分布式计算? 一切同时简单而复杂。 简单-因为在大多数情况下,我们对每单位信息执行相对简单的计算。 很难,因为有很多这样的信息。 很多 结果,您必须
在1000个线程中处理TB级的数据 。 因此,使用场景非常普遍:可以在需要考虑甚至更大数据数组的大量指标的任何地方应用计算。
最近的一个例子:披萨店连锁店Dodo Pizza是根据对客户订单基础的分析确定的,当选择具有任意馅料的比萨时,用户通常只使用六种基本原料加上一些随机原料。 据此,比萨店调整了购买量。 此外,她能够更好地向用户推荐在订购阶段提供的其他产品,这有助于增加利润。
另一个例子:商品位置
分析使H&M商店在保持销售水平的同时,将单个商店的范围减少了40%。 这是通过消除不良的销售头寸来实现的,并且在计算中考虑了季节性。
工具选择
此类计算的行业标准是Hadoop。 怎么了 因为Hadoop是一个出色的,有据可查的框架(相同的Habr对此主题也发表了很多详细的文章),但它还带有一整套实用程序和库。 您可以输入大量的结构化和非结构化数据,系统本身将在计算能力之间分配它们。 而且,可以随时增加或禁用这些相同的容量-实际具有相同的水平可伸缩性。
在2017年,颇具影响力的咨询公司Gartner
得出结论 ,Hadoop将很快过时。 原因很平庸:分析师认为,公司将大规模迁移到云,因为在那里他们可以为使用计算能力的事实付出代价。 第二个重要因素,据称能够“掩埋” Hadoop-是工作速度。 因为像Apache Spark或Google Cloud DataFlow这样的选项比MapReduce基础Hadoop更快。
Hadoop基于几个支柱,其中最引人注目的是MapReduce技术(用于在服务器之间进行计算的数据分发系统)和HDFS文件系统。 后者专门用于存储在群集中的节点之间分布的信息:固定大小的每个块都可以放置在多个节点上,并且由于复制,系统不受单个节点故障的影响。 代替文件表,使用一个名为NameNode的特殊服务器。
下图显示了MapReduce工作流程。 在第一阶段,根据特定特征对数据进行划分,在第二阶段-根据计算能力对数据进行分配,在第三阶段-执行计算。
MapReduce最初是由Google根据其搜索需求创建的。 然后MapReduce进入了免费代码,Apache接管了该项目。 好的,Google已经逐渐迁移到其他解决方案。 一个有趣的细微差别:目前Google有一个名为Google Cloud Dataflow的项目,它是Hadoop之后的下一个步骤,可以作为快速替代项目。
仔细研究发现,Google Cloud Dataflow基于各种Apache Beam,而Apache Beam包含一个有据可查的Apache Spark框架,它使我们可以谈论几乎相同的决策执行速度。 好吧,Apache Spark在HDFS文件系统上可以正常工作,它允许您将其部署到Hadoop服务器。
我们在此添加了针对Google Cloud Dataflow的针对Hadoop和Spark的大量文档和交钥匙解决方案,该工具的选择显而易见。 此外,工程师可以根据任务,经验和资格,自行决定在Hadoop或Spark下执行哪些代码。
云或本地服务器
普遍向云过渡的趋势甚至产生了一个有趣的术语,例如Hadoop即服务。 在这种情况下,连接服务器的管理变得非常重要。 因为尽管如此,纯Hadoop尽管很受欢迎,但它仍然是配置起来非常困难的工具,因为很多事情都需要您亲自完成。 例如,分别配置服务器,监视其性能,仔细配置许多参数。 通常,为业余人员工作是搞砸某事或错过某件事的绝好机会。
因此,最初配备了便利的部署和管理工具的各种发行版都非常受欢迎。 Cloudera是支持Spark并使事情变得简单的最受欢迎的发行版之一。 它具有付费版本和免费版本-在后者中,所有基本功能均可用,并且不限制节点数量。

在设置过程中,Cloudera Manager将通过SSH连接到您的服务器。 有趣的一点:在安装过程中,最好指出要由所谓的
包裹执行 :特殊包裹,每个
包裹都包含配置为相互配合使用的所有必要组件。 实际上,这是软件包管理器的改进版本。
安装后,我们将获得集群管理控制台,您可以在其中查看按集群进行的遥测,已安装的服务,还可以添加/删除资源以及编辑集群配置。
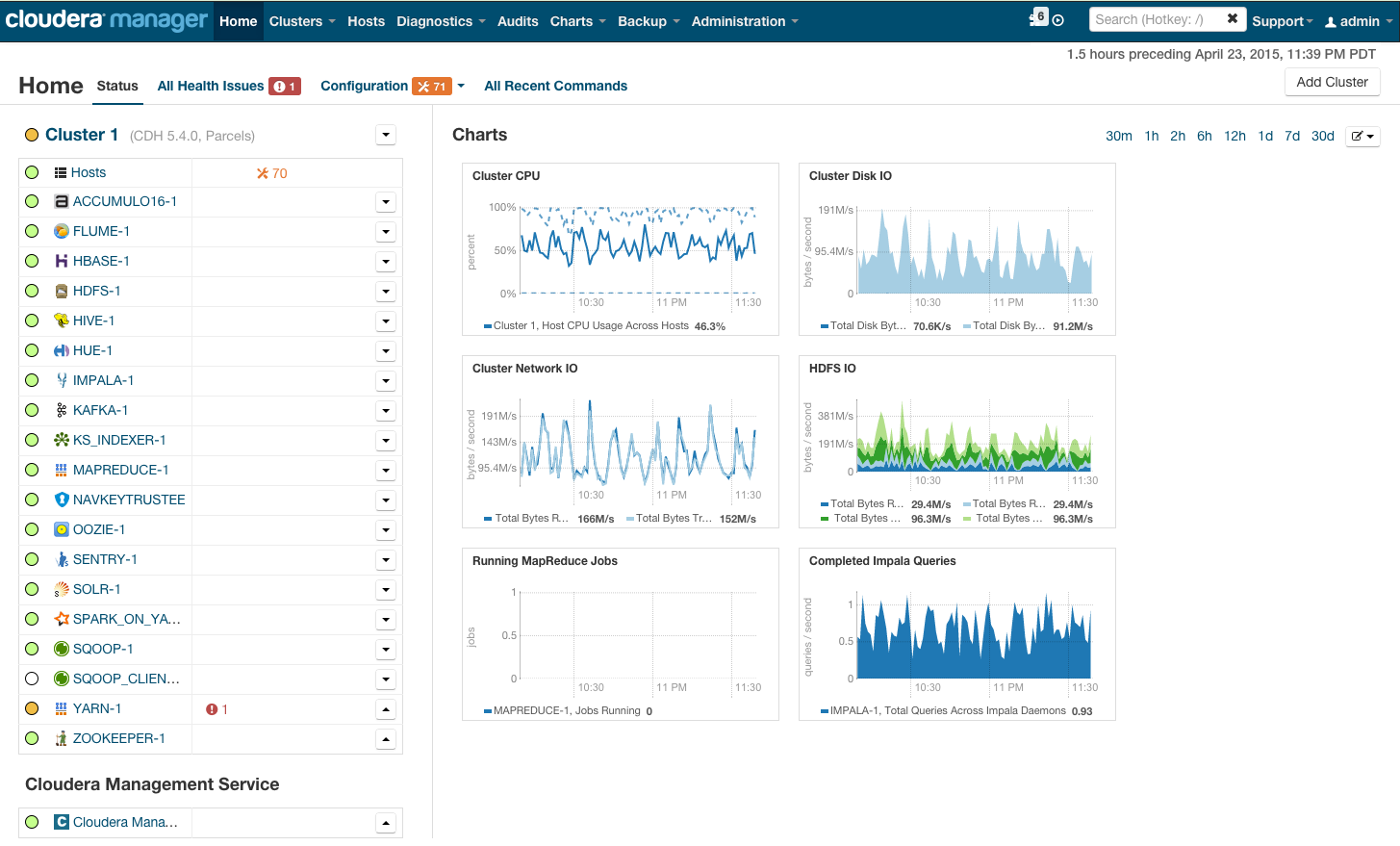
结果,您会看到火箭舱,它将带您进入BigData的光明前景。 但是,在您说“放手”之前,让我们先了解一下。
硬件要求
Cloudera在其网站上提到了各种可能的配置。 下图显示了构建它们的一般原理:
要润滑这张乐观图片,可以使用MapReduce。 如果您再次看一下上一节中的图表,很明显,在几乎所有情况下,从磁盘或网络读取数据时,MapReduce作业都可能会遇到瓶颈。 Cloudera博客上也对此进行了介绍。 结果,对于任何快速计算(包括通过Spark进行的实时计算)而言,I / O速度非常重要,其中Spark通常用于实时计算。 因此,在使用Hadoop时,平衡和快速的计算机进入群集非常重要,从总体上讲,它并不总是在云基础架构中提供。
通过在具有强大的多核CPU的服务器上使用Openstack虚拟化,可以实现负载均衡。 为数据节点分配了处理器资源和特定磁盘。 在我们的
Atos Codex Data Lake Engine解决方案中,可以实现广泛的虚拟化,这就是为什么我们在性能(将网络基础架构的影响最小化)和TCO(消除了不必要的物理服务器)上均获胜的原因。
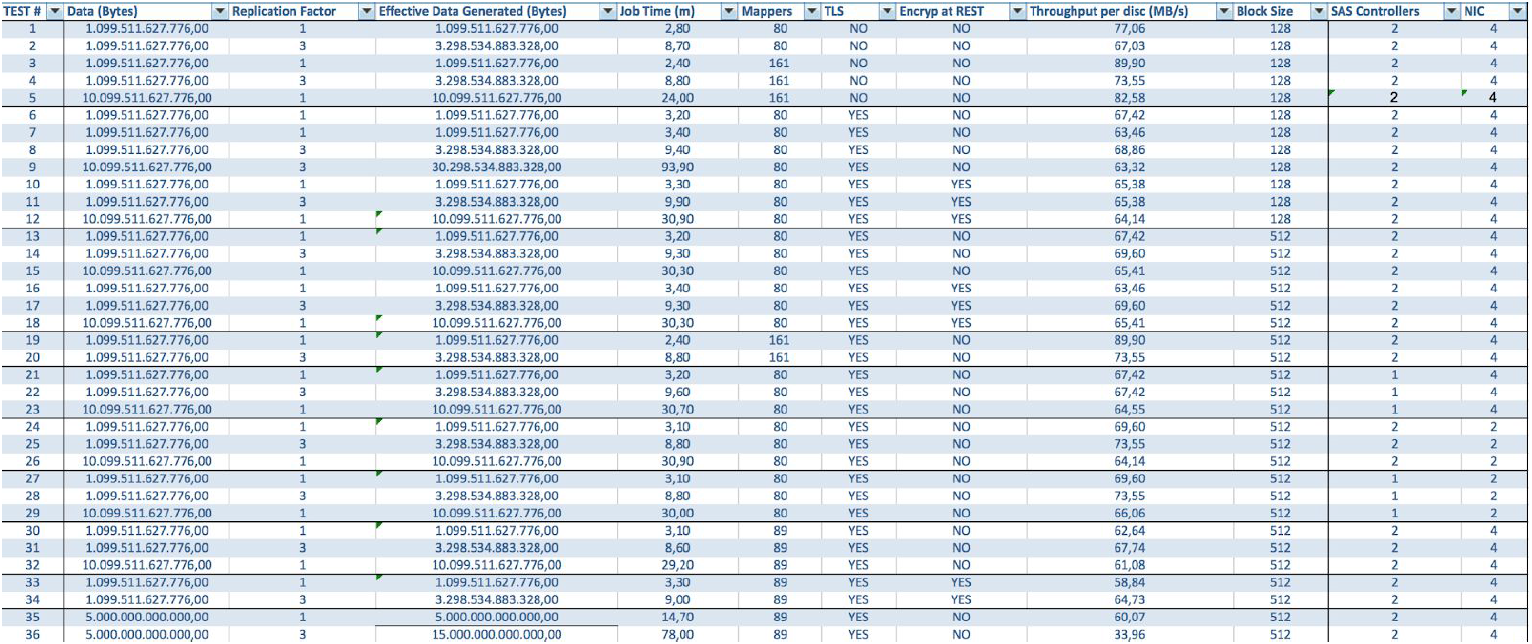
在使用BullSequana S200服务器的情况下,我们将获得非常均匀的负载,没有任何瓶颈。 最低配置包括3个BullSequana S200服务器,每个服务器具有两个JBOD,另外还可以选择连接包含四个数据节点的可选附加S200。 这是TeraGen测试中的示例负载:
在群集节点之间的负载平衡方面,具有不同数据量和复制值的测试显示相同的结果。 下图是通过性能测试得出的磁盘访问分布图。
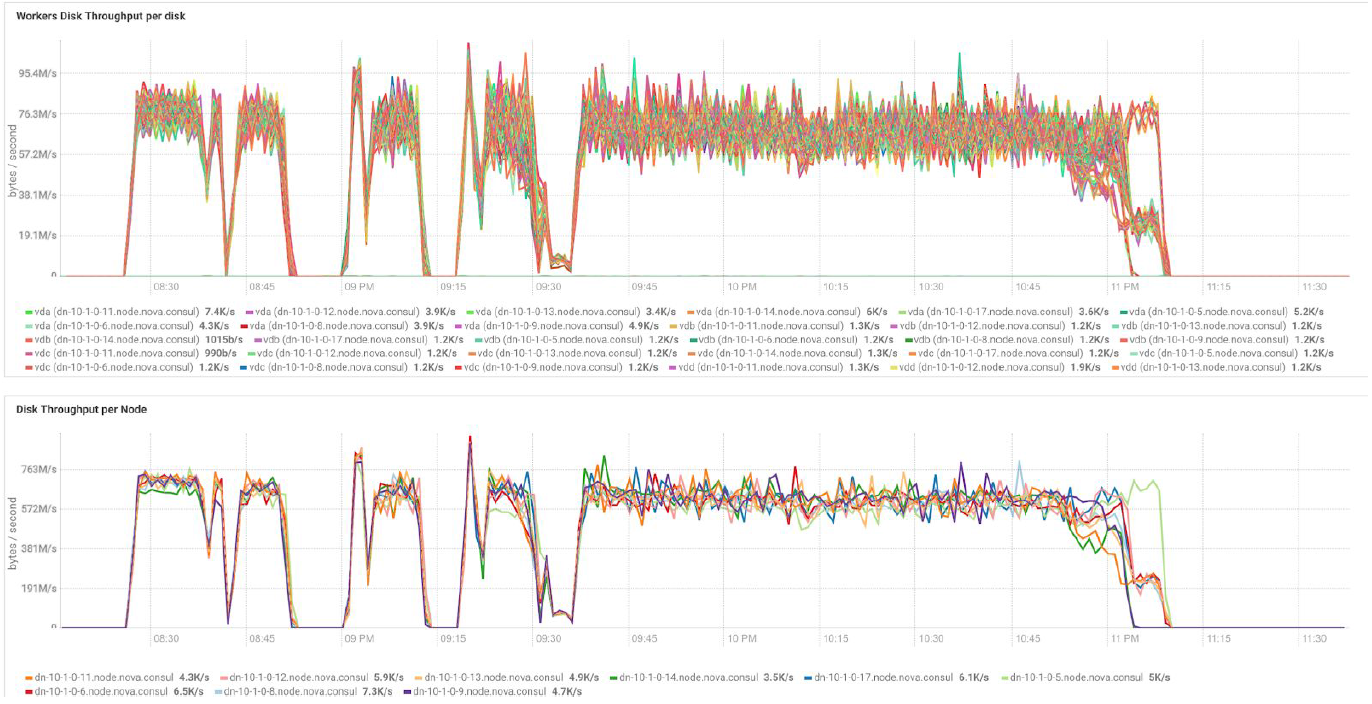
计算基于3台BullSequana S200服务器的最低配置。 它包括9个数据节点和3个主节点,以及在基于OpenStack虚拟化部署保护的情况下保留的虚拟机。 TeraSort测试结果:512 MB块大小的三个复制系数具有加密功能,为23.1分钟。
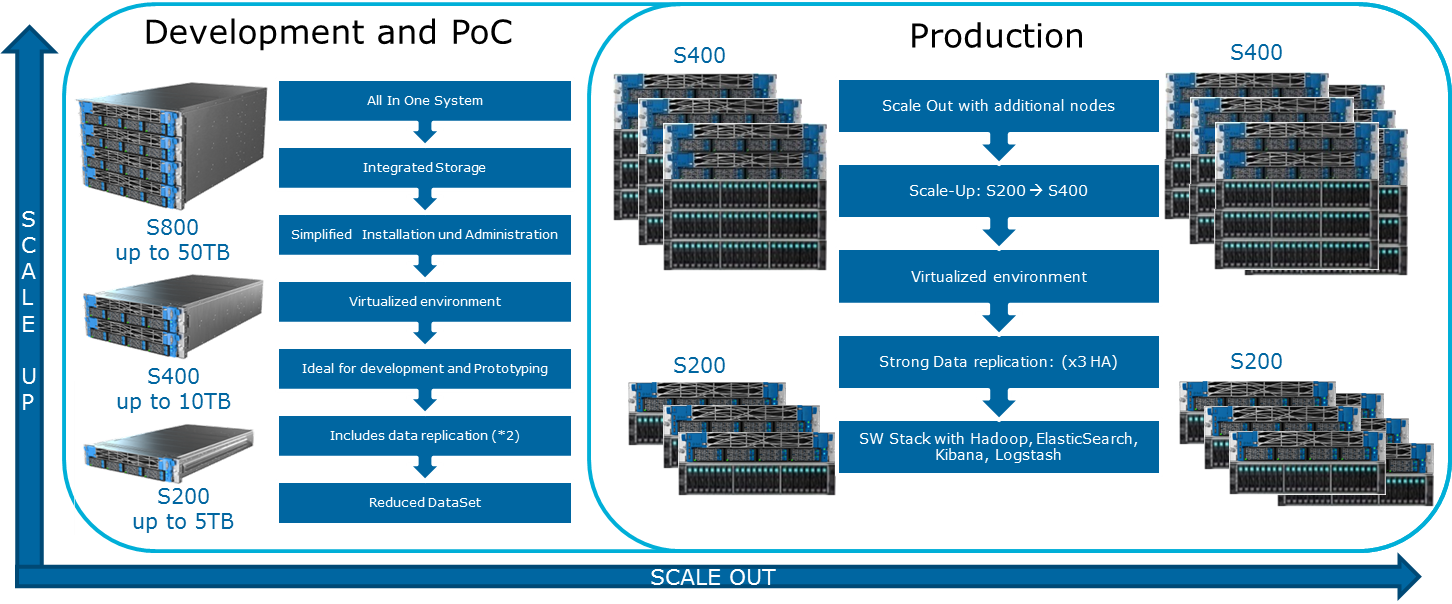
如何扩展系统? 各种类型的扩展可用于Data Lake Engine:
- 数据节点:每40 TB可用空间
- 能够安装GPU的分析节点
- 根据业务需要的其他选项(例如,如果您需要Kafka等)
Atos Codex Data Lake Engine包括服务器本身和预安装的软件,包括许可的Cloudera套件; Hadoop本身,OpenStack,具有基于RedHat Enterprise Linux内核的虚拟机,数据复制系统和备份(包括使用备份节点和Cloudera BDR-备份和灾难恢复)。 Atos Codex Data Lake Engine是第一个通过
Cloudera认证的虚拟化解决方案。
如果您对这些细节感兴趣,我们将很乐意在评论中回答我们的问题。