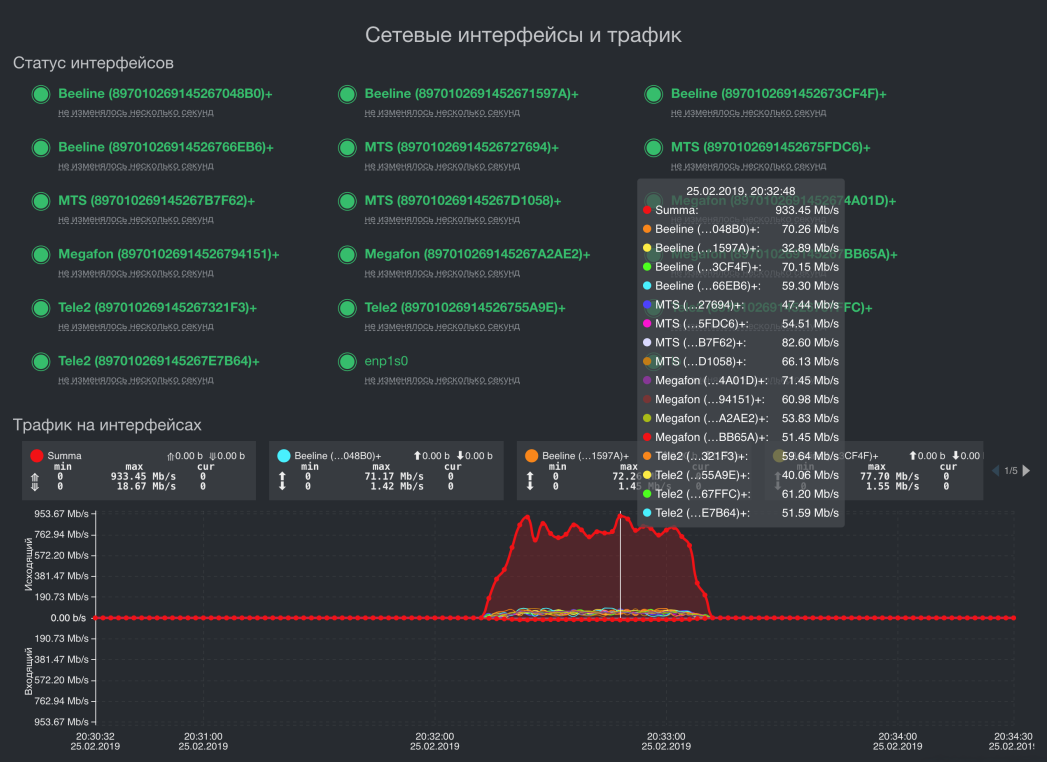
4个移动运营商的16个调制解调器上的速度求和。 一条流的输出速度-933.45 Mbps
引言
你好 本文是关于我们如何为自己编写一个新的监视系统的。 它与现有方法的不同之处在于可以高频同步获取指标,并且资源消耗非常低。 轮询频率可以达到0.1毫秒,指标之间的同步精度为10纳秒。 所有二进制文件占用6兆字节。
关于项目
我们有一个相当具体的产品。 我们提供了一个全面的解决方案来总结数据通道的吞吐量和容错能力。 这是当存在多个通道时,例如,Operator1(40Mbit / s)+ Operator2(30Mbit / s)+其他(5 Mbit / s),结果是一个稳定且快速的通道,其速度将是这样的:(40+ 30 + 5)x0.92 = 75x0.92 = 69 Mbps。
在任一信道的容量不足的情况下,需要这样的解决方案。 例如,运输,实时视频监视和视频流系统,直播电视和广播节目,电信运营商仅代表四大巨头的任何城外物体,并且一个调制解调器/通道上的速度不够。
对于每个领域,我们都会生产单独的设备系列,但是,它们的软件部分几乎相同,而高质量的监视系统是其主要模块之一,如果没有正确实施该产品,将是不可能的。
几年来,我们设法创建了一个多层次的快速,跨平台,轻量级的监视系统。 我们想与知名社区分享的内容。
问题陈述
监视系统为两个根本不同的类提供度量:实时度量和所有其他度量。 监视系统具有以下要求:
- 实时度量的高频同步采集,并将其无延迟地传输到通信控制系统。
不同指标的高频和同步不仅重要,而且对于分析数据传输通道的熵也至关重要。 如果一个数据通道的平均延迟为30毫秒,则其余度量之间的同步错误仅1毫秒,将导致所得通道的速度降低5%。 如果在4个通道中在1毫秒内同步出错,则速度下降很容易降至30%。 此外,通道中的熵变化非常快,因此,如果每隔0.5毫秒测量一次熵,则在延迟较小的快速通道上,我们会出现高速降级。 当然,并非所有指标都不需要这种准确性,并非在所有情况下都需要这样的准确性。 当通道中的延迟为500毫秒,并且我们使用这种延迟时,几乎不会注意到1毫秒的错误。 同样,对于生命支持系统的度量标准,仅2秒的轮询和同步频率就足够了,但是,监视系统本身应该能够以超高的轮询频率和超精确的度量同步工作。 - 最少的资源消耗和单个堆栈。
最终设备可以是功能强大的车载综合系统,可以分析路况或记录人的生物特征信息,也可以是特种部队士兵身穿防弹衣穿戴的单板掌上型计算机,可以在通讯条件恶劣的情况下传输实时视频。 尽管架构和计算能力多种多样,但我们希望拥有相同的软件堆栈。 - 雨伞建筑
应收集指标并将其汇总到最终设备上,并具有本地存储系统并实时且具有追溯性。 如果可以进行通讯,则将数据传输到中央监控系统。 没有连接时,发送队列应该累积而不消耗RAM。 - 一种用于集成到客户的监控系统中的API,因为没人需要很多监控系统。 客户必须在一次监视中从任何设备和网络收集数据。
发生什么事了
为了加载本已令人印象深刻的长距离比赛,我将不提供所有监视系统的示例和度量。 这将拉出另一篇文章。 我只是说我们找不到能够同时获取两个指标且误差小于1毫秒的监视系统,并且该监视系统在具有64 MB RAM的ARM体系结构和具有32 GB RAM的x86_64体系结构上均能有效地工作。 因此,我们决定编写自己的代码,可以做到这一点。 这是我们得到的:
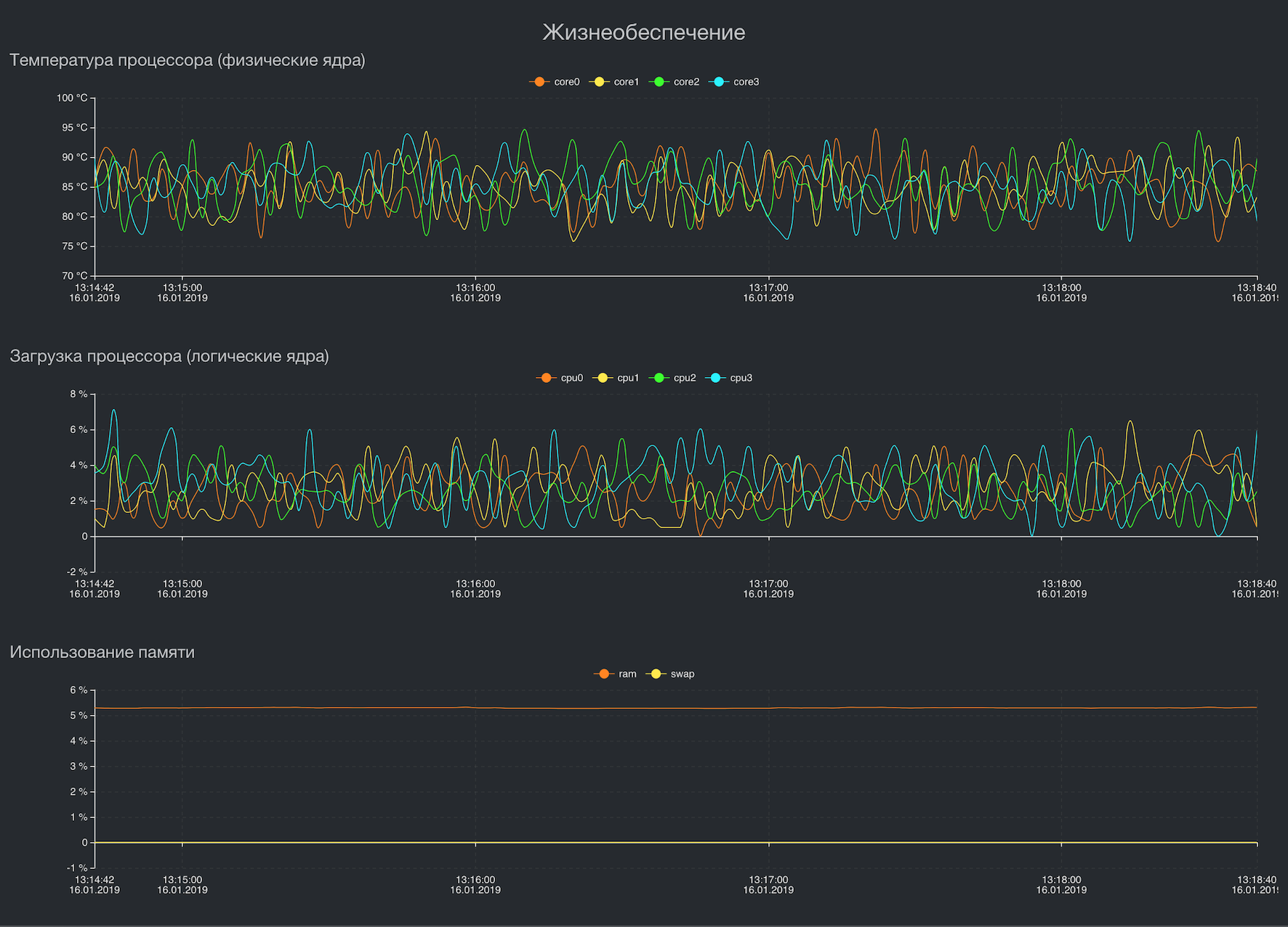
总结不同网络拓扑的三个通道的吞吐量
可视化一些关键指标
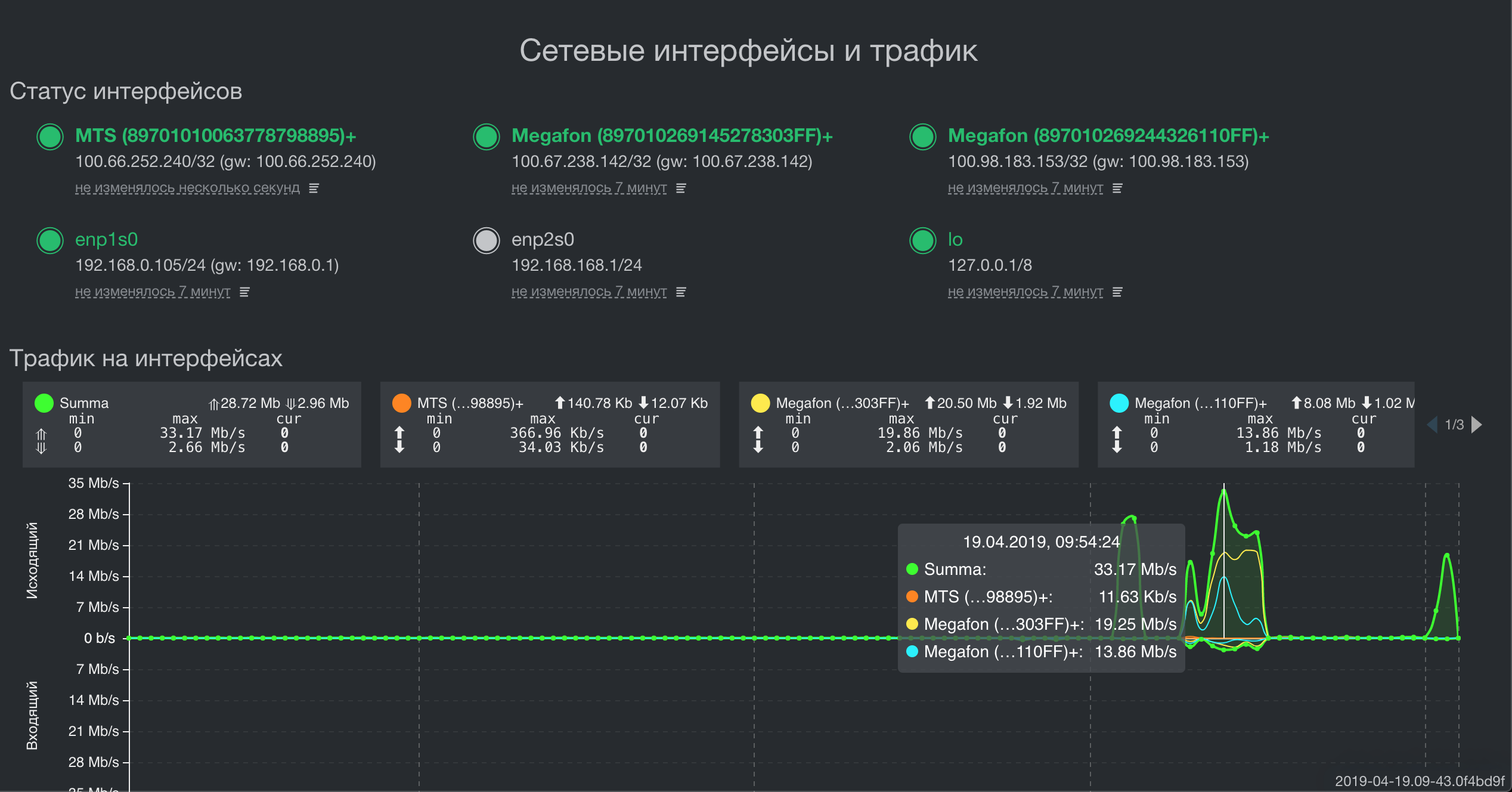
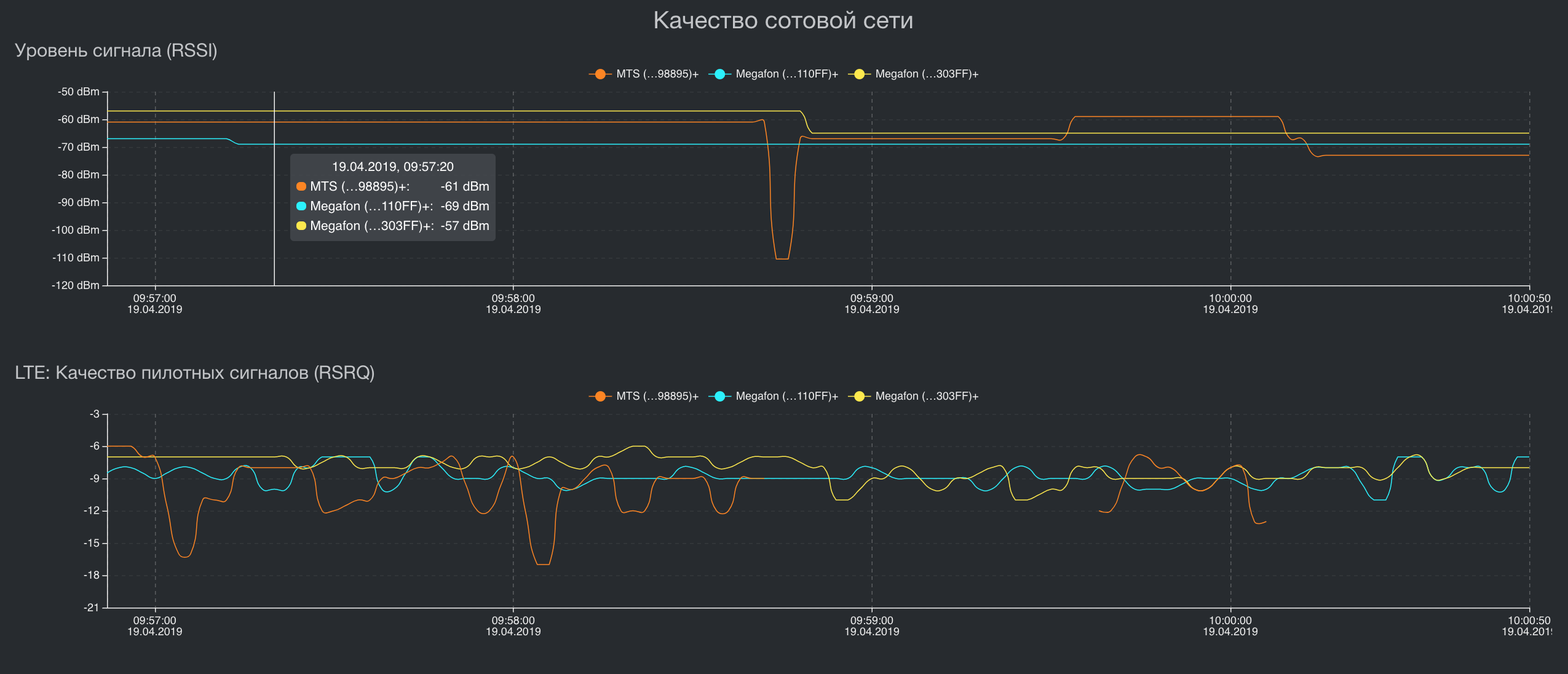
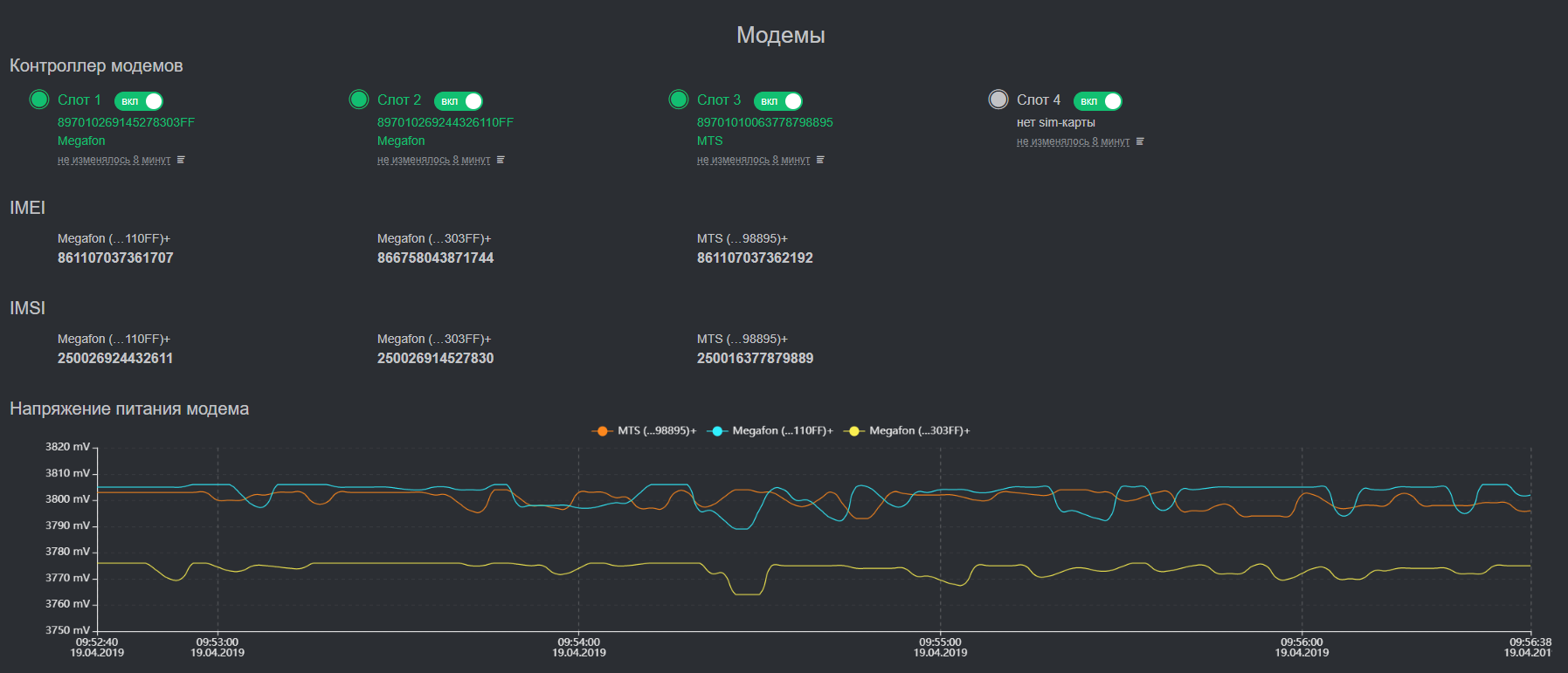
建筑学
作为设备和数据中心的主要编程语言,我们使用Golang。 他通过实现多任务处理以及为每个服务获取一个静态链接的可执行二进制文件的能力,极大地简化了他的生活。 结果,我们显着节省了将资源,方法和服务部署到终端设备的流量,开发时间和代码调试。
该系统根据经典的模块化原理实现,并包含几个子系统:
- 度量标准的注册。
每个指标由其自己的流提供服务,并通过渠道进行同步。 我们设法使同步精度达到10纳秒。 - 公制存储
我们选择为时间序列编写存储库,还是使用可用的存储库之一。 需要数据库来存储追溯数据,该数据库可以进行后续可视化显示,即,它没有每0.5毫秒的通道延迟数据或传输网络中的错误指示,但每个接口每500毫秒都有一个速度。 除了对跨平台的高要求和低资源消耗之外,对于我们而言,进行处理也非常重要。 数据存储在同一位置。 这极大地节省了计算资源。 自2016年以来,我们一直在该项目中使用Tarantool DBMS,到目前为止,我们还没有看到替代它的机会。 灵活,以最佳方式消耗资源,而不仅仅是足够的技术支持。 Tarantool还具有GIS模块。 它当然不如PostGIS强大,但足以满足我们存储与位置(与运输相关)相关的某些指标的任务。 - 指标可视化
这里的一切都相对简单。 我们从存储中获取数据,并实时或回顾性地显示它们。 - 与中央监控系统进行数据同步。
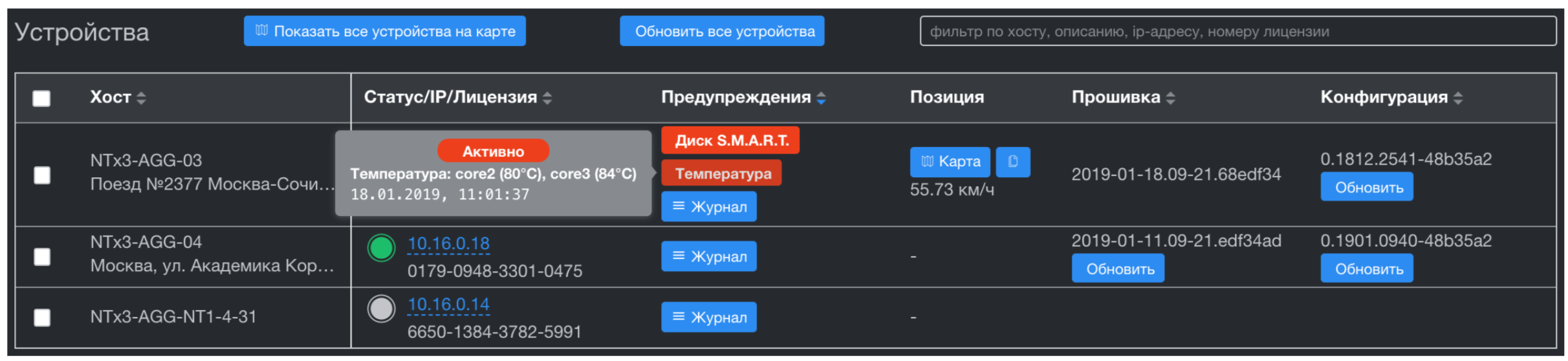
中央监控系统从所有设备接收数据,以给定的回顾进行存储,然后通过API将其发送到客户的监控系统。 与传统的监视系统不同,在传统的监视系统中,“头部”会走动并收集数据-我们有相反的方案。 连接时,设备本身会发送数据。 这是非常重要的一点,因为它允许您在设备不可用的那些时间段内从设备接收数据,并且在设备不可用时不加载通道和资源。 作为中央监控系统,我们使用Influx监控服务器。 与类似物不同,它可以导入回顾性数据(即,时间戳不同于接收度量的那一刻)。收集的度量可以通过修改的Grafana文件可视化。 之所以选择此标准堆栈,是因为它具有现成的集成API与几乎所有客户监控系统。 - 与中央设备管理系统的数据同步。
设备管理系统实现零接触配置(更新固件,配置等),并且与监控系统不同,它仅接收设备问题。 这些是板载硬件监视程序服务和所有生命支持系统指标的触发因素:CPU和SSD温度,CPU负载,可用空间和磁盘上的SMART运行状况。 子系统存储也建立在Tarantool上。 这使我们可以在数千个设备中进行时间序列的聚合,并且可以彻底解决与这些设备进行数据同步的问题。 Tarantool具有出色的排队系统并保证交付。 我们提供了这个重要功能,太好了!
网络管理系统
接下来是什么
到目前为止,我国最薄弱的环节是中央监测系统。 它在标准堆栈上的实现率为99.9%,它具有许多缺点:
- 关闭电源后,InfluxDB会丢失数据。 通常,客户会立即获取来自设备的所有内容,并且数据库本身中没有超过5分钟的数据,但是将来这可能会很麻烦。
- Grafana在数据聚合和显示同步方面存在许多问题。 最常见的问题是,当数据库包含一个时间序列,该时间序列的间隔为2秒,例如从00:00:00开始,并且Grafana从+1秒开始显示聚合数据。 结果,用户看到舞动图表。
- 与第三方监视系统进行API集成的过多代码。 可以变得更紧凑,当然也可以重写为Go)
我想你们所有人都能很好地看到Grafana的模样,没有我,您就知道她的问题,因此,我不会在帖子中加图片。
结论
我故意不描述技术细节,而仅描述该系统的支持设计。 首先,为了从技术上全面描述该系统,还需要一篇文章。 其次,并不是每个人都会感兴趣。 在评论中写下您想知道的技术细节。
如果有人对本文有任何疑问,我可以写信给a.rodin @ qedr.com