
哈Ha! 逻辑上将继续描述大型支付平台内部的运行,并继续描述所有这些组件在物理硬件上在现实世界中如何工作。 在本文中,我将讨论平台应用程序的放置方式和位置,以及来自外部世界的流量如何到达它们,并且还将为我们提供一个位于我们任何数据中心的设备的标准机架方案。
方法和局限性

在开发平台之前,我们制定的第一个要求听起来像是“能够线性扩展计算资源以确保处理任意数量的交易”。
市场参与者使用的付费系统的经典方法暗示了上限的存在,尽管根据声明,该上限相当高。 通常听起来像这样:“我们的处理每秒可以接受1000个事务。”
这种方法不适合我们的业务目标和体系结构。 我们不想有任何限制。 实际上,从Yandex或Google听到“我们每秒可以处理100万次搜索”的说法会很奇怪。 由于架构的原因,该平台目前可以处理业务需求量的请求,简单来说,这可以让IT员工携带一台服务器推车,他将这些服务器安装在机架中,连接到交换机并离开。 平台的协调器将把业务应用程序实例的副本部署到新的容量,从而使我们获得所需的RPS增加。
第二个重要要求是确保所提供服务的高可用性。 创建一个可以接受/ dev / null中的无数次付款的支付平台会很有趣,但不太有用。
实现高可用性的最有效方法也许是多次复制为服务提供服务的实体,以使任何合理数量的应用程序,设备或数据中心的故障都不会影响平台的整体可用性。
应用程序的多次复制需要大量的物理服务器和相关的网络设备。 这种铁要花钱,我们当然要花这么多钱,所以我们买不起很多昂贵的铁。 因此,该平台的设计方式使得可以轻松容纳大量廉价且不太强大的熨斗,甚至在公共云中并感觉良好。
使用计算能力不是最强的服务器有其优势-服务器的故障不会对整个系统的总体状况产生关键影响。 想象一下有什么更好的解决方案-如果一台昂贵,大型且超可靠的品牌服务器被烧毁,根据主从方案运行DBMS(根据Murphy的法律,它肯定会烧毁,并在12月31日晚上),或者在30个节点的群集中的几台服务器按无主服务器运行图?
基于此逻辑,我们决定不以集中式磁盘阵列的形式创建另一个重大故障点。 Ceph集群为我们提供了通用的块设备,该集群以超融合的方式部署在同一台服务器上,但具有独立的网络基础架构。
因此,我们在逻辑上得出了通用机架的通用方案,该通用机架具有计算资源,其形式为数据中心中价格便宜且功能不强的服务器。 如果我们需要更多的资源,我们要么结束服务器的所有空闲机架,要么放置另一个(最好是更靠近机架)。

好吧,最后,它只是美丽。 当在机架中安装大量相同的熨斗时,这可以帮助您解决高质量的线束敷设问题,可以消除燕窝和缠结导线以及掉落处理的危险。 从工程的角度来看,这是一件好事,该系统在任何地方都应该是漂亮的-从内部以代码的形式,在外部以服务器和网络硬件的形式。 一个漂亮的系统可以更好,更可靠地工作,我有足够的示例可以根据我的经验进行验证。
请不要以为我们是骗子,也不要以为企业受到融资的挤压。 开发和维护分布式平台实际上是非常昂贵的乐趣。 实际上,这比拥有一个经典系统要昂贵得多,经典系统是有条件地在具有Oracle / MSSQL,应用服务器和其他绑定的强大品牌硬件上构建的。
我们的方法具有很高的可靠性,非常灵活的水平扩展功能,每秒支付次数没有上限,而且听起来很奇怪-对于IT团队来说是很多乐趣。 对我而言,开发人员和开发人员从其创建的系统中获得的愉悦程度与预测的开发时间,推出的功能的数量和质量同样重要。
服务器基础架构

从逻辑上讲,我们的服务器容量可以分为两大类:用于虚拟机管理程序的服务器,其中每个单元的CPU和RAM核心的密度很重要;以及存储服务器,其中的重点是每个单元的磁盘空间量,并且已经选择了CPU和RAM磁盘数。
目前,我们用于计算能力的经典服务器如下所示:
- 2个Xeon E5-2630 CPU;
- 128G RAM;
- 3个SATA SSD(Ceph SSD池);
- 1个NVMe SSD(dm缓存)
用于存储状态的服务器:
- 1个XEeon E5-2630 CPU;
- 12-16硬盘;
- 2个SSD用于block.db;
- 32G RAM。
网络基础设施
在选择网络硬件时,我们的方法有所不同。 我们仍然使用品牌交换机在vlan-s之间进行切换和路由,现在是SAN中的Cisco SG500X-48和Cisco Nexus C5020。
在物理上,每个服务器通过4个物理端口连接到网络:
- 2x1GbE-应用程序之间的管理网络和RPC;
- 2x10GbE-存储网络。
机器内部的接口通过绑定进行组合,然后标记的流量根据所需的VLAN发生分歧。
也许这是我们基础架构中唯一可以看到著名供应商标签的地方。 因为在路由,网络过滤和流量检查方面,我们使用Linux主机。 我们不购买专用路由器。 我们需要的所有内容都在运行Gentoo的服务器上进行配置(用于过滤的iptables,用于动态路由的BIRD,作为IDS / IPS的Suricata,作为WAF的Wallarm)。
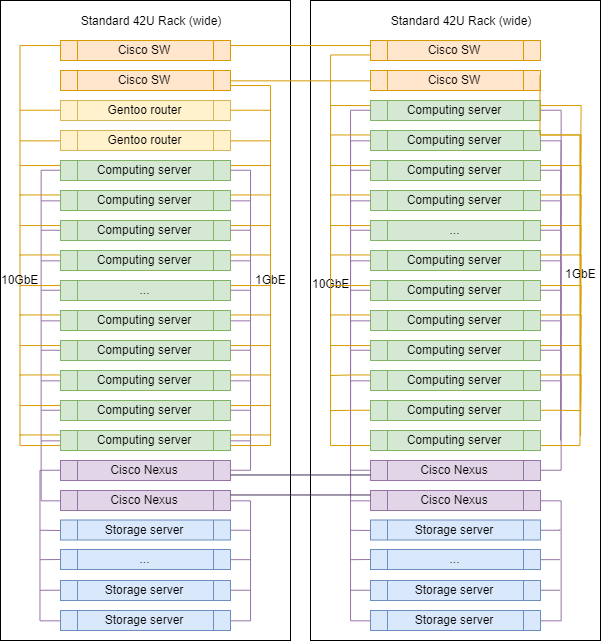
典型的直流机架
扩大规模时,DC中的机架几乎没有区别,只是上行链路路由器安装在其中之一上。
不同类别的服务器的确切比例可能有所不同,但通常会保留逻辑-用于计算的服务器多于用于存储数据的服务器。
块设备和资源共享
让我们尝试将所有内容放在一起。 想象一下,我们需要将一些微服务放置在基础架构中,为了更加清晰,这些微服务将是需要通过RPC相互通信的微服务,其中之一是Machinegun,它将状态存储在Riak集群中,以及一些辅助服务,例如如ES和Consul节点。
典型的布局如下所示:
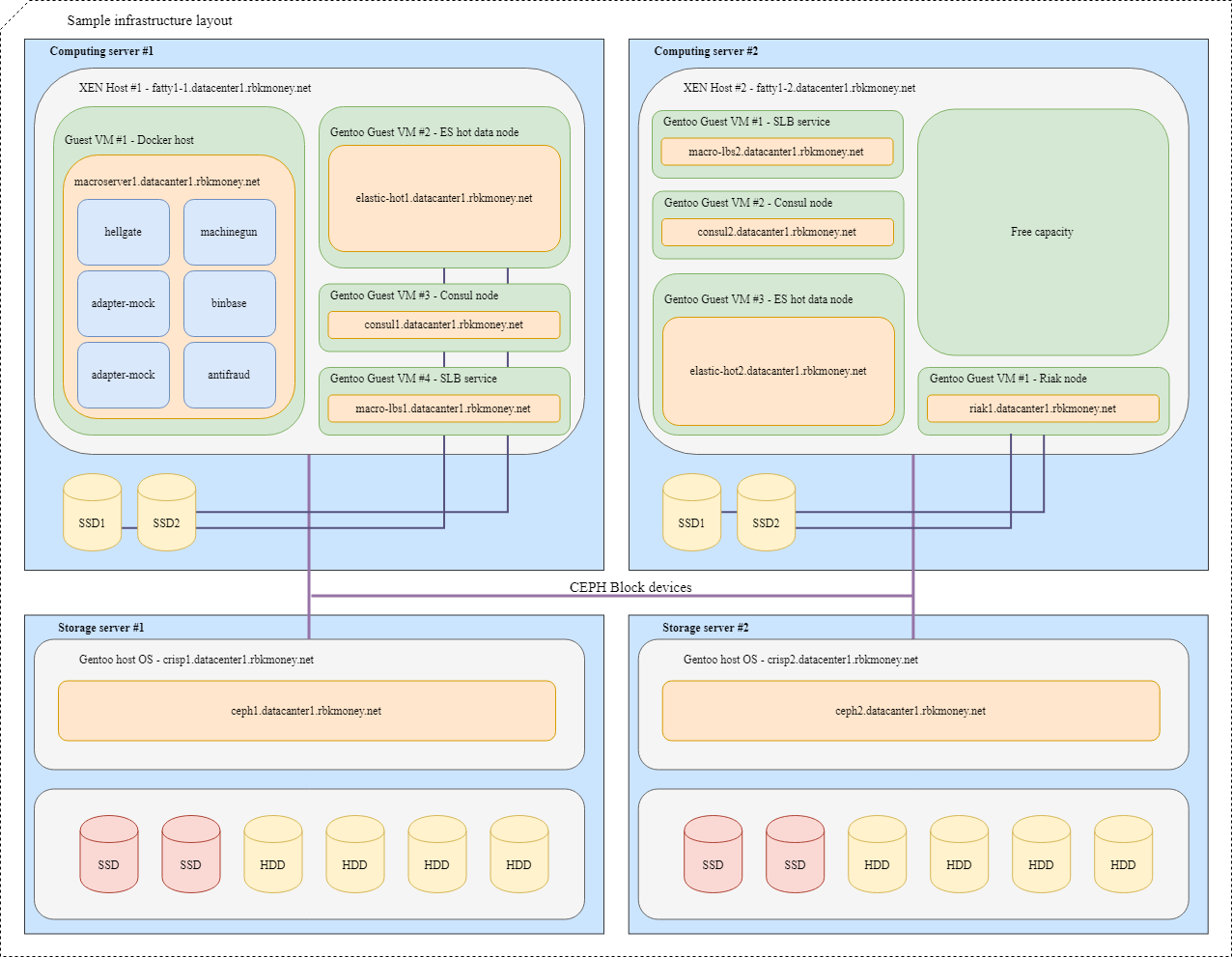
对于具有需要块设备最大速度的应用程序的VM(例如Riak和热Elasticsearch节点),将使用本地NVMe磁盘上的分区。 此类VM紧密连接到其虚拟机监控程序,而应用程序本身负责其数据的可用性和完整性。
对于常见的块设备,我们使用Ceph RBD,通常在本地NVMe磁盘上使用直写dm-cache。 设备的OSD可以是全闪存或具有SSD日志的HDD,具体取决于所需的响应时间。
向应用程序传递流量
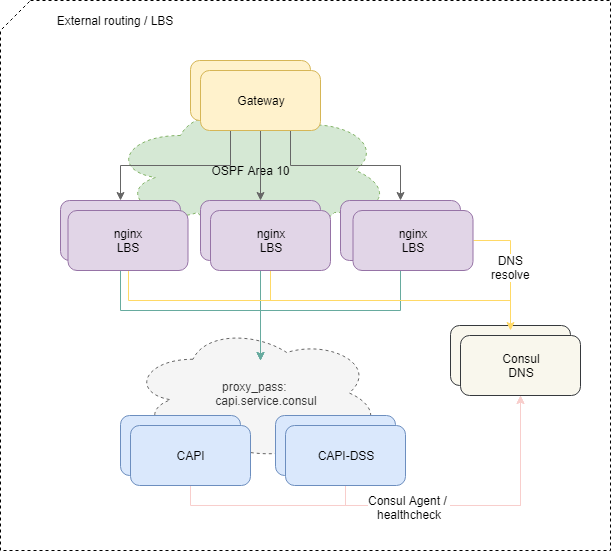
为了平衡来自外部的请求,我们使用标准的OSPFv3 ECMP方案。 带有Nginx,Bird,Consul的小型虚拟机在OSPF云中从lo接口通告公共的任意播地址。 在路由器上,bird为这些地址创建多跳路由,以提供按流平衡,其中流为“ src-ip src-port dst-ip dst-port”。 为了快速禁用丢失的平衡器,使用了BFD协议。
当添加或使任何均衡器发生故障时,上游路由器都会出现或删除相应的路由,并且根据等价多路径方法将网络流量传递给它们。 如果我们不特别干预,那么所有网络流量都会通过每个IP流平均分配给所有可用的平衡器。
顺便说一句,具有ECMP平衡的方法存在明显的陷阱 ,可能导致某些流量的完全明显的损失,尤其是在系统之间的路由上有其他路由器或配置错误的防火墙的情况下。
为了解决该问题,我们在基础结构的这一部分中使用了PMTUD守护程序 。
此外,流量会根据平衡器上的nginx配置进入平台内部的特定微服务。
而且,如果平衡外部流量或多或少简单易懂,那么很难向内扩展这种方案-我们不仅需要在网络级别检查具有微服务的容器的可用性。
为了使微服务开始接收和处理请求,它必须在Service Discovery中注册(我们使用Consul ),每秒进行一次运行状况检查,并具有合理的RTT。
如果微服务感觉良好并且运行良好,则Consul在通过服务名称访问其DNS时开始解析其容器的地址。 我们使用内部区域service.consul ,例如,通用API版本2微服务将命名为capi-v2.service.consul 。
关于平衡的Nginx配置看起来像这样:
location = /v2/ { set $service_hostname "${staging_pass}capi-v2.service.consul"; proxy_pass http://$service_hostname:8022; }
因此,如果我们再次不故意干预,则来自平衡器的流量会在Service Discovery中注册的所有微服务之间平均分配,完全自动化添加或删除必要微服务的新实例。
如果来自平衡器的请求流向上游,并且在途中死亡,我们将返回502-处于该级别的平衡器无法确定该请求是否等幂,因此我们将此类错误的处理提高到更高的逻辑层次。
幂等和期限
通常,我们不担心并且会毫不犹豫地使用API发出5xx错误,如果您在RPC业务逻辑级别正确处理此类错误,则这是系统的正常部分。 此处理的原理在我们的表格中称为“错误重试策略”小手册,我们将其分发给商户客户并在我们的服务中实现。
为了简化此过程,我们实现了几种方法。
首先,对于对我们的API进行的任何状态更改请求,您都可以在帐户中指定一个唯一的幂等密钥,该密钥可以永久保存,并且可以确保重复调用同一数据集会返回相同的答案。
其次,我们以付款会话的唯一标识符的形式实施了另一种机制,该机制保证了借记资金请求的等幂性,即使您没有生成和传输单独的等幂密钥,也可以防止重复的错误借记。
第三,我们决定以时间截断参数的形式启用对API的任何外部调用的可预测且受外部控制的响应时间,该参数确定了请求完成操作的最大等待时间。 例如,传输HTTP标头X-Request-Deadline: 10s就足够了,以确保您的请求将在10秒内执行或被平台内部的某个平台杀死,此后,我们可以在请求转发策略。
我们将SaltStack用作配置和整个基础架构的管理工具。 尽管我们已经知道,我们将朝着这个方向前进,但尚未开发出用于自动控制平台计算能力的单独工具。 凭借我们对Hashicorp产品的热爱,这很可能是游牧民族。
主要的基础架构监视工具是Nagios中的检查,但是对于业务实体,我们主要在Grafana中配置警报。 它具有用于设置条件的非常方便的工具,并且基于事件的平台模型使您可以将所有内容写入Elasticsearch并配置选择条件。
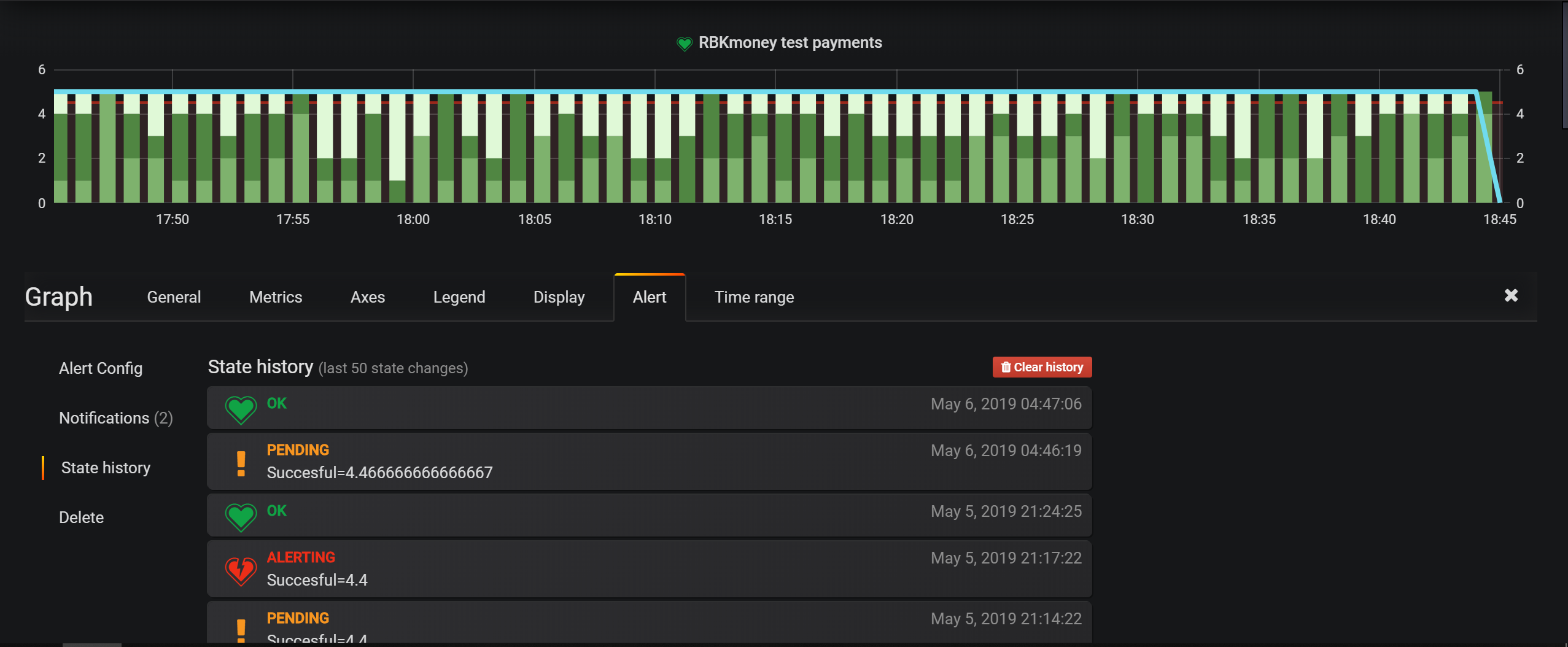
数据中心位于莫斯科,我们在其中租用机架空间,独立安装和管理所有设备。 我们不在任何地方使用深色光学器件,只有本地提供商在外部提供互联网。
否则,我们的监视,管理和相关服务的方法对于业界来说是相当标准的,我不确定在下一篇文章中是否值得提及这些服务的集成。
在本文中,我可能会结束有关如何安排我们的付款平台的一系列评论文章。
我认为周期实在是很坦率,我见过很少的文章可以详细揭示大型支付系统的内部结构。
我认为,总的来说,高度开放和坦率对于支付系统来说是非常重要的事情。 这种方法不仅可以提高合作伙伴和付款人的信任度,还可以约束团队,服务的创建者和运营者。
因此,在这一原则的指导下,我们最近公开了平台的状态和服务的正常运行时间历史记录。 我们的正常运行时间,更新和崩溃的所有后续历史现已公开,并可在https://status.rbk.money/上获得 。
希望您感兴趣,也许有人会发现我们的方法和所描述的错误有用。 如果您对帖子中描述的任何领域感兴趣,并且希望我更详细地公开它们,请不要犹豫在评论中或PM中写。
感谢您与我们在一起!

PS为方便起见,该系列前面几篇文章的指针为: