与
大多数帖子一样 ,分布式服务存在问题,我们称此服务为Alvin。 这次我自己没有发现问题,客户部分的人通知了我。
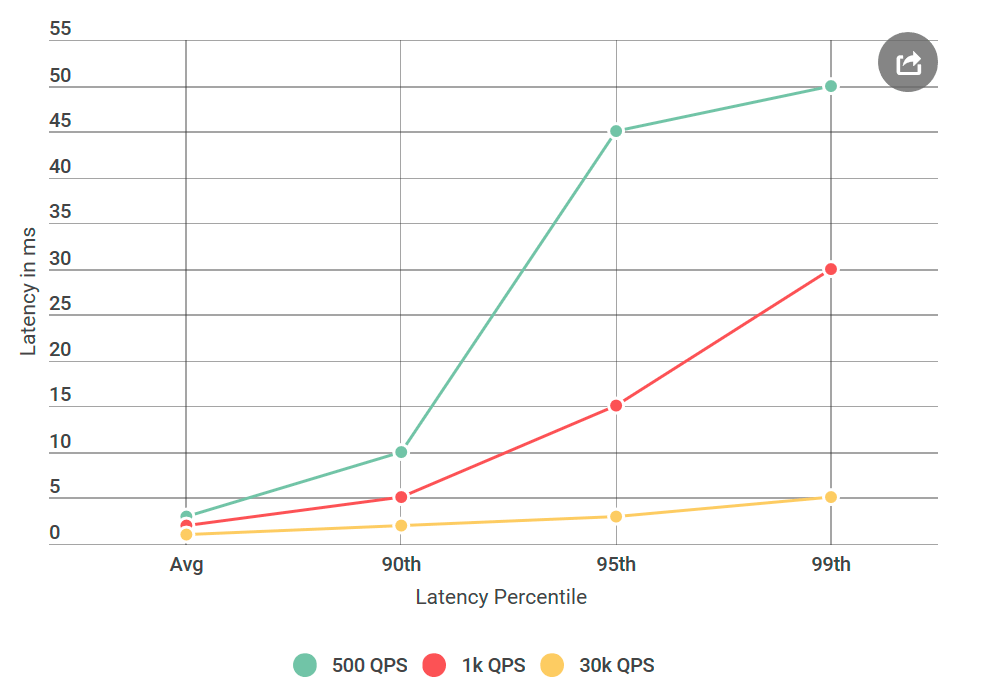
由于Alvin的严重拖延,我从不满的信中醒来后,我们计划在不久的将来推出该产品。 特别是,客户在50毫秒左右遇到了第99个百分位数的延迟,远高于我们的延迟预算。 这是令人惊讶的,因为我对服务进行了彻底的测试,尤其是对于延迟,因为这是经常抱怨的主题。
在给Alvin进行测试之前,我进行了许多实验,每秒处理4万个请求(QPS),所有这些请求的延迟都小于10毫秒。 我准备宣布我不同意他们的结果。 但是我再次看了这封信,我提请注意一些新的东西:我绝对没有测试他们提到的条件,他们的QPS远低于我的。 我在40k QPS上进行了测试,而在1k上才进行了测试。 我进行了另一个实验,这次是用较低的QPS,只是为了取悦他们。
自从我在博客上撰写此书以来,您可能已经了解了:事实证明它们的数量是正确的。 我一次又一次地测试了虚拟客户端,所有结果都相同:请求数量少不仅增加了延迟,而且增加了请求数量,延迟超过10毫秒。 换句话说,如果在40k QPS每秒约有50个请求超过50毫秒,则在每秒1k QPS时,有50毫秒以上的100个请求。 矛盾!
缩小搜索范围
面对具有许多组件的分布式系统中的延迟问题,您需要做的第一件事是列出可疑对象的简短列表。 我们对Alvin的体系结构进行更深入的研究:
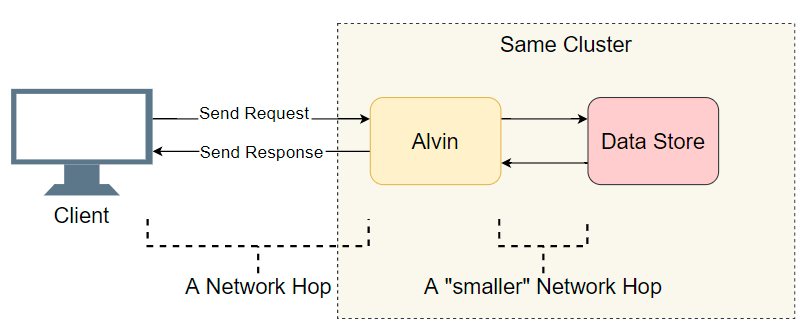
一个很好的起点是完整的I / O转换(网络调用/磁盘搜索等)的列表。 让我们尝试找出延迟在哪里。 除了与客户端进行明显的I / O操作外,Alvin还采取了另外一个步骤:他访问数据仓库。 但是,此存储与Alvin在同一群集中工作,因此延迟应少于客户端。 因此,犯罪嫌疑人名单:
- 客户到Alvin的网络通话。
- 从Alvin到数据仓库的网络通话。
- 在数据仓库中的磁盘上搜索。
- 从数据仓库到Alvin的网络通话。
- 从Alvin到客户端的网络呼叫。
让我们尝试消除一些观点。
数据仓库
我做的第一件事是将Alvin转换为不处理请求的ping-ping服务器。 收到请求后,它将返回一个空响应。 如果延迟减少,那么Alvin或数据仓库实施中的错误就不会被听到。 在第一个实验中,我们得到下图:
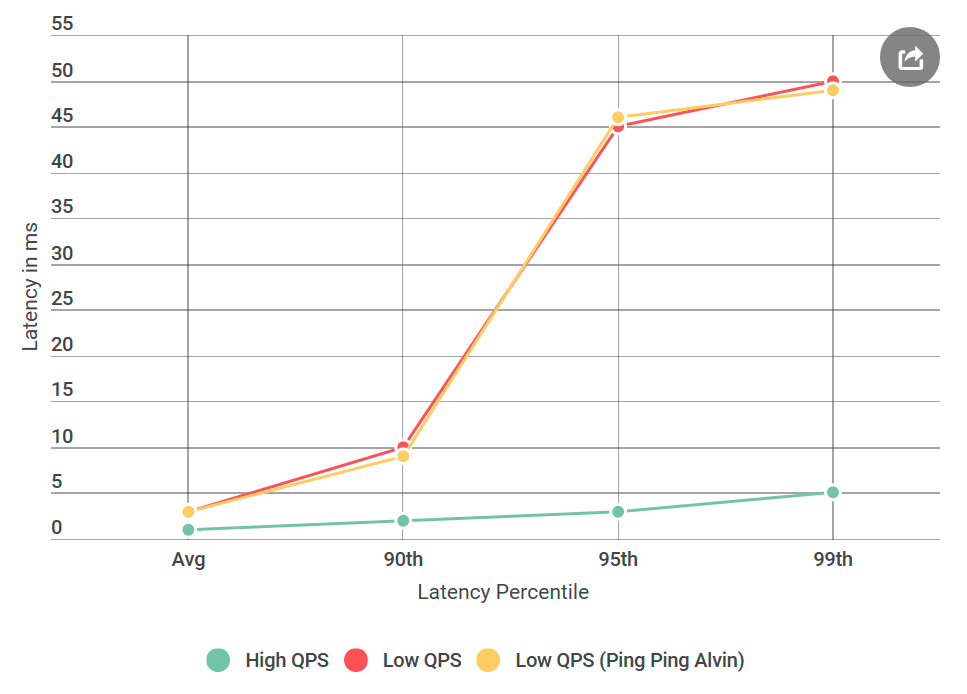
如您所见,使用ping-ping服务器时没有任何改进。 这意味着数据仓库不会增加延迟,并且可疑者列表减半:
- 客户到Alvin的网络通话。
- 从Alvin到客户端的网络呼叫。
哇! 名单正在迅速缩小。 我以为我几乎想通了原因。
gRPC
现在是时候向您介绍一个新的播放器:
gRPC 。 这是Google的开放源代码库,用于进程内
RPC通信。 尽管
gRPC很好的优化和广泛使用,但我还是第一次在如此规模的系统上使用了它,并且我希望我的实现
gRPC理想-稍微说一下。
gRPC在堆栈中的存在提出了一个新问题:也许这是我的实现,还是
gRPC本身会引起延迟问题? 添加到新的可疑列表中:
- 客户端调用
gRPC库
- 客户端上的
gRPC库对服务器上的gRPC库进行网络调用
gRPC库访问Alvin(在乒乓服务器中不执行任何操作)
为了使您理解代码的外观,我的client / Alvin实现与
异步 client-server
示例没有太大区别。
注意:上面的列表有些简化,因为gRPC允许您使用自己的(模板?)流模型,其中gRPC执行gRPC和用户实现相互交织。 为了简单起见,我们将坚持该模型。
分析将解决所有问题
划掉数据仓库,我以为我快完成了: 我们将应用该配置文件,并找出延迟发生的位置。” 我非常支持
精确的性能分析,因为CPU速度非常快,而且通常它们不是瓶颈。 大多数延迟发生在处理器必须停止处理以执行其他操作时。 为此,对CPU进行了精确的性能分析:它可以准确记录所有
上下文切换 ,并明确出现延迟的位置。
我采用了四个配置文件:在高QPS(低延迟)下和在低QPS(高延迟)下使用乒乓服务器,无论是在客户端还是在服务器端。 以防万一,我还提取了一个样本处理器配置文件。 比较配置文件时,我通常会寻找异常的调用堆栈。 例如,在具有高延迟的不利方面,存在更多的上下文切换(10次或更多次)。 但就我而言,上下文切换的数量几乎是一致的。 令我恐惧的是,那里没有什么重要的东西。
附加调试
我很绝望。 我不知道可以使用其他什么工具,我的下一个计划实质上是重复具有不同变体的实验,而不是清楚地诊断问题。
如果呢
从一开始,我就担心50 ms的特定延迟时间。 这是一个非常重要的时期。 我决定将代码中的片段删掉,直到我能确切地找出引起此错误的部分。 然后进行了有效的实验。
像往常一样,有了后脑,一切似乎都是显而易见的。 我将客户端与Alvin放在同一台计算机上,并将请求发送到
localhost 。 而且延迟的增加已经消失了!
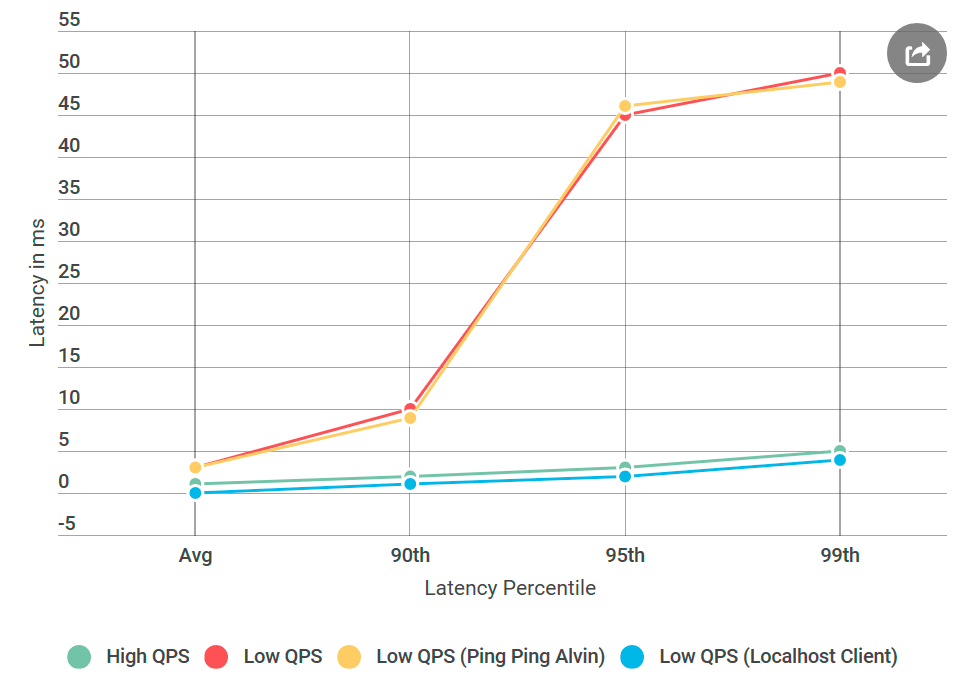
网络出了点问题。
学习网络工程师的技能
我必须承认:我对网络技术的了解非常糟糕,尤其是考虑到我每天与他们合作的事实。 但是网络是主要的可疑对象,我需要学习如何调试它。
幸运的是,互联网喜欢那些想学习的人。 ping和tracert的结合似乎是调试网络传输问题的足够好的开始。
首先,我在
Alvin的TCP端口上运行了
PsPing 。 我使用了默认选项-没什么特别的。 在超过一千次的ping中,除了第一次进行预热之外,没有一个超过10 ms。 这与在第99个百分位中观察到的50 ms延迟的增加相矛盾:在那里,对于每100个请求,我们应该看到大约一个请求具有50 ms的延迟。
然后我尝试了
tracert :也许问题出在Alvin和客户端之间的路由中的一个节点上。 但是示踪剂却空手而归。
因此,延迟的原因不是我的代码,不是gRPC的实现,也不是网络。 我已经开始担心我永远不会理解这一点。
现在我们在用什么操作系统
gRPC在Linux上
gRPC广泛使用,但在Windows上却是奇特的。 我决定进行一个有效的实验:我创建了Linux虚拟机,为Linux编译了Alvin并进行了部署。
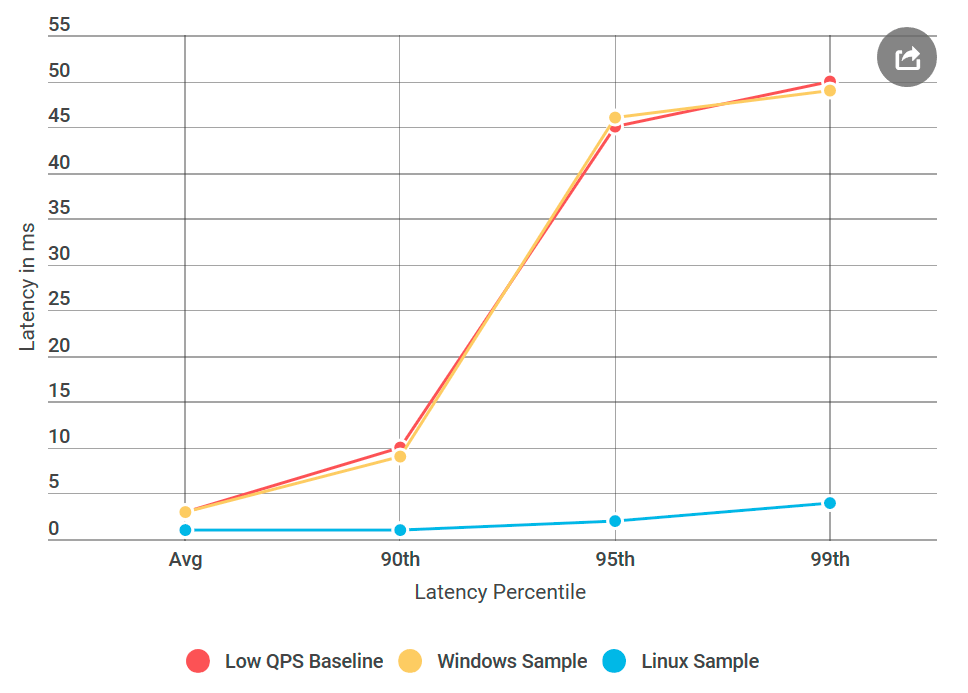
发生了什么:乒乓Linux服务器没有类似Windows节点的延迟,尽管数据源没有不同。 事实证明,问题出在为Windows实施gRPC。
Nagle算法
一直以来,我都以为我错过了
gRPC标志。 现在我意识到这
gRPC在
gRPC缺少Windows标志。 我找到了内部RPC库,在其中我确定它对于所有已安装的
Winsock标志都适用。 然后,他将所有这些标志添加到gRPC中,并将Alvin部署到Windows的固定Windows固定乒乓服务器中!
 差不多
差不多完成了:我开始一次删除一个添加的标志,直到回归回归,所以我可以查明其原因。 那是臭名昭著的
TCP_NODELAY ,是Nagle算法的一个开关。
Neigl算法试图通过延迟消息的传输直到数据包大小超过一定的字节数来减少通过网络发送的数据包的数量。 尽管这对于普通用户而言可能是令人愉快的,但它对实时服务器具有破坏性,因为操作系统将延迟某些消息,从而导致低QPS的延迟。
gRPC在Linux实现中为TCP套接字设置了此标志,但对于Windows没有设置。 我
修好了 。
结论
低QPS的较大延迟是由操作系统优化引起的。 回顾一下,分析没有检测到延迟,因为它是在内核模式下而不是在
用户模式下执行的 。 我不知道是否可以通过ETW捕获来观察Nagle算法,但这很有趣。
至于本地主机实验,它可能没有接触实际的网络代码,并且Neigl算法没有启动,因此当客户端通过本地主机联系Alvin时,延迟问题消失了。
下次您看到延迟增加而每秒请求数量减少时,Neigl算法应该列在可疑列表中!