
我一直对如何从内部安排Habr,如何构建工作流,如何构建通信,如何应用标准以及如何在此处编写代码感兴趣。 幸运的是,这样的机会出现在我眼前,因为最近我成为了habracommand的一部分。 以移动版本的少量重构为例,我将尝试回答这个问题:在这里进行前端工作感觉如何。 在程序中:Node,Vue,Vuex和SSR,以及有关Habré个人经历的笔记。
关于开发团队,您需要了解的第一件事是我们很少。 哈勃-巴克斯利的三场比赛中很少有三场比赛,两场比赛以及技术比赛。 当然,还有一个测试人员,设计师,三个瓦迪姆,一个奇迹般的扫帚,一个商人和其他Bumburums。 但是,只有六个直接贡献者是哈布拉族。 这是非常罕见的-一个拥有数百万美元受众的项目,看起来像是一个来自外部的巨大企业,实际上更像是一个组织结构最扁平的舒适型创业公司。
像其他许多IT公司一样,Habr秉承敏捷的思想,CI的实践,仅此而已。 但是根据我的感觉,Habr作为产品的发展比持续发展的起伏更大。 因此,对于连续的几个冲刺,我们努力进行编码,设计和重新设计,破坏某些事物并进行修复,解决票证和开始新的冲刺工作,踏上耙子,朝自己的腿射击,最终将功能发布到产品中。 然后是一段停顿,一段重新开发的时期,是时候做“重要而非紧急”象限中的事情了。
下面将讨论这种“淡季”冲刺。 这次它重构了Habr的移动版本。 总的来说,该公司对其寄予厚望,并且将来它将取代整个Habr化身动物园,成为一个通用的跨平台解决方案。 有一天,将会出现自适应布局,PWA,离线模式,用户自定义以及许多有趣的东西。
我们设定任务
有一次,在一个普通的站台上,一个前沿谈到了移动版本的注释组件的体系结构中的问题。 从这次演讲中,我们以小组心理治疗的形式组织了一次微型会议。 每个人依次说他感到疼痛的地方,所有的东西都固定在纸上,表示同情,理解,除了没有人鼓掌。 输出结果列出了20个问题,这清楚表明移动Habr必须走很长而棘手的成功之路。
我主要关心的是资源效率和所谓的“平滑界面”。 每天在“在家工作—回家”路线上,我看到我的旧电话拼命试图在信息流中显示20个标题。 它看起来像这样:
重构之前的移动Habr界面这是怎么回事 简而言之,无论用户是否登录,服务器都以相同的方式将HTML页面提供给所有人。 然后,加载客户端JS并再次请求必要的数据,但需要进行授权修改。 也就是说,实际上,我们做了两次相同的工作。 界面闪烁,用户下载了额外的数百KB。 在细节上,一切看起来都更加令人毛骨悚然。
旧的SSR-CSR电路。 只有在节点JS不忙于生成HTML并可以代理API请求时,才可以在阶段C3和C4进行授权。Habr的一位用户非常准确地描述了我们当时的架构:
移动版本是狗屎。 我按原样说话。 SSR和CSR的可怕组合。
我们不得不承认这一点,无论它多么悲伤。
我想出了办法,在“吉拉”中给自己订了一张票,上面的描述是“现在很糟糕,制定规则”,然后我用宽大的笔触分解了任务:
- 重用数据
- 尽量减少重画次数,
- 排除重复的请求
- 使加载过程更加明显。
重用数据
从理论上讲,服务器端渲染旨在解决两个问题:不遭受搜索引擎在
SPA索引方面的局限性,并改善
FMP指标(不可避免地使
TTI恶化)。 在经典场景中(最终
于2013年在Airbnb中提出) (返回Backbone.js),SSR是在Node环境中运行的同构JS应用程序。 服务器仅返回生成的布局作为对请求的响应。 然后在客户端发生补液,然后一切正常而无需重新加载页面。 对于Habr以及许多其他文本填充资源,服务器渲染是与搜索引擎建立友好关系的关键要素。
尽管自该技术问世以来已经过去了六年多的时间,并且在这段时间内,前端世界确实流了很多水,但对于许多开发人员来说,这个想法仍然笼罩在保密的面纱中。 我们没有袖手旁观,而是向产品推出了具有SSR支持的Vue应用程序,但缺少一个小细节:我们没有将初始状态交给客户端。
怎么了 这个问题没有确切答案。 他们要么不想增加服务器响应的大小,要么是由于其他一系列体系结构问题,或者根本就没有采取行动。 一种或另一种方式,抛出状态并重用服务器所做的一切似乎是非常适当和有用的。 任务实际上是微不足道的-
只是将自身注入到执行上下文中,而Vue会将其作为全局变量自动添加到生成的布局中:
window.__INITIAL_STATE__ 。
出现的问题之一是无法将
循环结构转换为JSON。 通过简单地将此类结构替换为其平面类似物即可解决。
另外,在处理UGC内容时,请记住,应将数据转换为HTML实体,以免破坏HTML。 为此,我们使用
他 。
最小化重绘
从上图可以看出,在我们的示例中,一个Node JS实例执行两项功能:API中的SSR和“代理”,在此用户被授权。 这种情况使得在服务器上执行JS代码时无法进行授权,因为节点是单线程的并且SSR功能是同步的。 也就是说,当调用堆栈忙于某些事情时,服务器根本无法向自己发送请求。 原来,我们跳过了状态,但是界面没有停止抽动,因为应该考虑到用户会话来更新客户端上的数据。 有必要教导我们的应用程序将正确的数据置于初始状态,同时考虑到用户的登录信息。
该问题只有两种解决方案:
- 将授权数据保留在服务器间请求中;
- 将Node JS图层拆分为两个单独的实例。
第一个解决方案要求在服务器上使用全局变量,第二个解决方案将完成任务所需的时间至少延长了一个月。
如何选择? 哈伯经常沿着阻力最小的路径前进。 非正式地,人们普遍希望最小化从构思到原型的周期。 对产品的态度模型有点让人联想到booking.com的假设,唯一的区别是,Habr对用户反馈的重视程度更高,并相信采纳这样的决定对您作为开发人员是正确的。
遵循这种逻辑以及我自己希望快速解决问题的愿望,我选择了全局变量。 而且,正如这种情况经常发生的那样,他们迟早要为它们付费。 我们几乎立即付款:我们在周末工作,收集后果,撰写
事后调查报告,然后开始将服务器分为两部分。 这个错误非常愚蠢,与她一起参与的错误不容易重现。 是的,由于这样的羞耻,但由于某种原因而tum绊绊和gr不休,我的带有全局变量的PoC仍投入生产,并且在成功过渡到新的“两天”体系结构方面非常成功。 这是重要的一步,因为正式实现了目标-SSR学会了提供一个完全可以使用的页面,并且UI变得更加平静。
重构第一阶段后的移动Habr接口最终,移动版本的SSR-CSR体系结构导致了此图:

“两天” SSR-CSR计划。 节点JS API始终为异步I / O做好准备,并且不受SSR函数的阻塞,因为后者处于单独的实例中。 不需要查询链3。排除重复的请求
操作后,最初的页面渲染不再引起癫痫病。 但是在SPA模式下进一步使用Habr仍然引起困惑。
由于用户流基于
文章→文章→注释的表单
列表的转换,反之亦然,因此最重要的是优化此链的资源消耗。
返回到发布提要会引发新的数据请求我不必深究。 在上面的截屏视频中,可以看到该应用程序在向后滑动时会重新查询文章列表,并且在请求期间我们看不到该文章,因此先前的数据消失在某处。 似乎商品列表组件使用本地状态,并在销毁时丢失。 实际上,该应用程序使用了全局状态,但是Vuex体系结构建立在额头上:模块与页面相关联,而页面又与路由相关联。 此外,所有模块都是“一次性的”-每次对该页面的后续访问都会重写整个模块:
ArticlesList: [ { Article1 }, ... ], PageArticle: { ArticleFull1 },
总的来说,我们有
ArticlesList模块,其中包含
Article类型的对象,以及
PageArticle模块,后者是
Article对象的扩展版本,即
ArticleFull 。 总的来说,这种实现本身并不具有任何可怕的东西-它非常简单,甚至可能天真地说,但它非常清楚。 如果您在每次更改路线时都将模块归零,那么您甚至可以忍受它。 但是,由于我们只能通过一个
ArticlesList来放置新数据,因此可以保证文章供稿之间的过渡(例如
/ feed→/ all )会丢弃与个人供稿有关的所有内容。 这再次导致重复的查询。
将我在该主题上能够发掘出的所有东西放在一起,我制定了一个新的状态结构并将其呈现给我的同事。 讨论时间很长,但最后,“赞成”的理由胜过了所有疑问,于是我开始执行。
解决方案的逻辑最好分两个阶段公开。 首先,我们尝试从页面上解开Vuex模块,然后直接绑定到路由。 是的,存储中将有更多数据,getter会变得更加复杂,但是我们不会两次加载文章。 对于移动版本,这可能是最有力的论据。 它看起来像这样:
ArticlesList: { ROUTE_FEED: [ { Article1 }, ... ], ROUTE_ALL: [ { Article2 }, ... ], }
但是,如果文章列表可以在多个路径之间重叠,又如何,如果我们想重用
Article对象的数据来呈现帖子页面,将其变成
ArticleFull怎么办? 在这种情况下,使用这样的结构会更合乎逻辑:
ArticlesIds: { ROUTE_FEED: [ '1', ... ], ROUTE_ALL: [ '1', '2', ... ], }, ArticlesList: { '1': { Article1 }, '2': { Article2 }, ... }
ArticlesList这里只是某种文章存储库。 用户会话期间上载的所有文章。 我们会尽可能谨慎地对待它们,因为这可能是由于站点之间地铁之间某处的痛苦而造成的交通负荷,并且我们绝对不希望再次引起用户这种痛苦,从而迫使他加载已经下载的数据。
ArticlesIds对象只是指向
Article对象的标识符(如“链接”)的数组。 通过此结构,在通过将扩展数据合并到邮政页面中时,您不必复制路由通用的数据并重用
Article对象。
商品列表的输出也变得更加透明:迭代器组件使用商品ID在数组上进行迭代,并绘制商品预告片组件,将Id作为props传递,而子组件又从
ArticlesList中检索必要的数据。 当您转到发布页面时,我们从
ArticlesList获取现有日期,请求丢失的数据,然后将其简单地添加到现有对象中。
为什么这种方法更好? 就像我在上面写的那样,这种方法在下载的数据方面更加谨慎,并且允许您重用它。 除此之外,它还为一些新机会打开了道路,这些机会非常适合这种架构。 例如,在文章出现时对其进行轮询并将其上载到提要。 我们可以简单地将新帖子添加到
ArticlesList “商店”中,在
ArticlesIds中保存新ID的单独列表,然后将此通知用户。 当您单击“显示新出版物”按钮时,我们只需在当前文章列表的数组的开头插入新ID,一切就将神奇地工作。
使下载更有趣
重构蛋糕上的樱桃是骨骼的概念,这使在慢速Internet上下载内容的过程变得不那么令人讨厌。 没有关于这个主题的讨论,从构思到原型的整个过程花了两个小时。 该设计几乎是我们自己绘制的,并且我们教会了我们的组件如何在等待数据的同时渲染朴实,几乎没有闪烁的div块。 从主观上讲,这种加载方式确实减少了用户体内压力荷尔蒙的数量。 骨架看起来像这样:
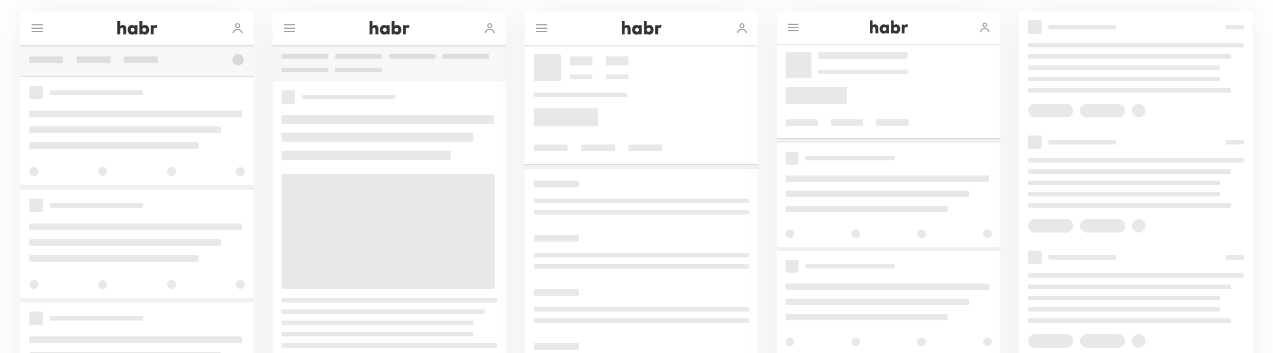 Habraloading
Habraloading反映
我已经在哈布雷(Habré)工作了六个月,而朋友们仍然在问:嗯,您感觉如何? 好,舒适-是的。 但是,有些东西使这项工作与其他工作有所区别。 我所在的团队完全不关心他们的产品,不了解也不了解他们的用户。 但是这里的一切都不同。 在这里,您对所做的事情负有责任。 在开发功能的过程中,您将部分成为其所有者,参加与功能有关的所有产品会议,提出建议并自己做出决定。 制作自己每天使用的产品非常酷,为可能会更好的人编写代码只是一种令人难以置信的感觉(没有讽刺意味)。
在发布所有这些更改之后,我们收到了积极的反馈,这非常非常好。 令人鼓舞。 谢谢你 写更多。
让我提醒您,在全局变量之后,我们决定更改体系结构并将代理层分离为单独的实例。 “两天”架构已经以公开Beta测试的形式发布。 现在,任何人都可以切换到它,并帮助我们改进移动Habr。 今天就这些了。 我很乐意在评论中回答您的所有问题。