你好
您是否知道广告平台经常复制竞争对手的内容以增加其托管的广告数量? 他们以这种方式进行:他们致电卖家并提供他们在平台上结算的权利。 有时,他们会在未经用户许可的情况下完全复制广告。 阿维托(Avito)是一个受欢迎的场所,我们经常遇到这种不公平的竞争。 阅读有关如何应对这种现象的信息,请仔细阅读。

问题所在
将内容从Avito复制到其他平台存在于几种商品和服务中。 本文仅关注汽车。 在上一篇文章中,我谈到了如何在汽车上进行自动数字隐藏。

但是事实证明(根据其他平台的搜索结果),我们立即在三个公告站点上启动了此功能。

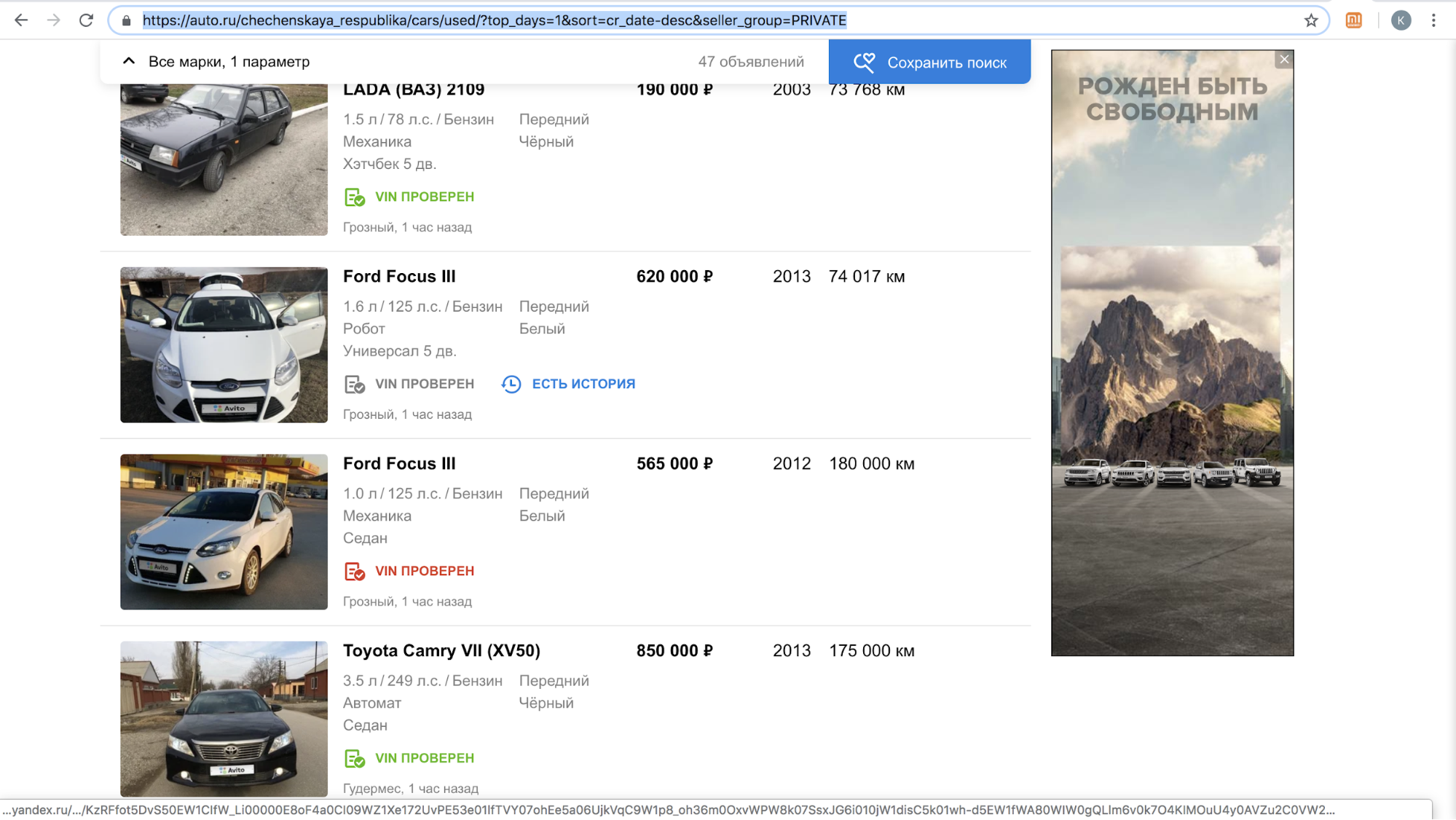
在启动一项功能后,这些网站之一暂时暂停了向我们的用户的致电,以提供在其平台上复制公告的优惠:他们网站上带有Avito徽标的内容太多了,仅在2018年11月,就有超过70,000个广告。 例如,这就是他们每天在车臣共和国的搜索结果的样子。
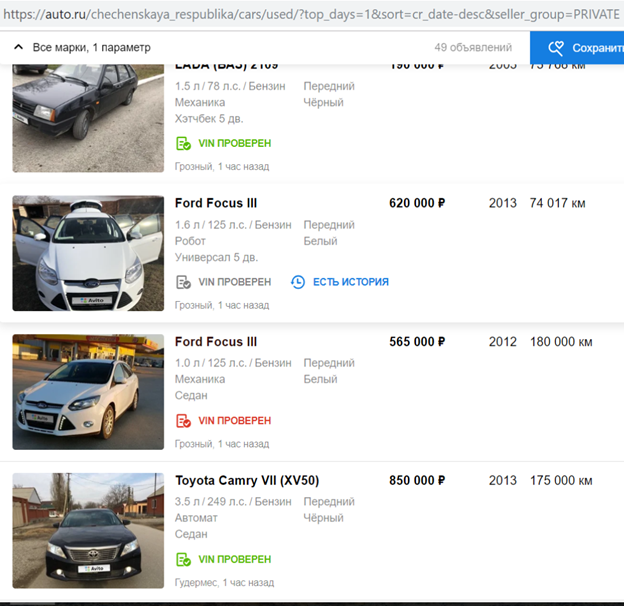
在完成了隐藏车牌的算法以使其自动检测并关闭Avito徽标后,他们恢复了该过程。

从我们的角度来看,复制竞争对手的内容并将其用于商业目的是不道德且不可接受的。 在我们的支持下,我们收到了用户对此不满意的投诉。 这是其中一个故事的反应示例。
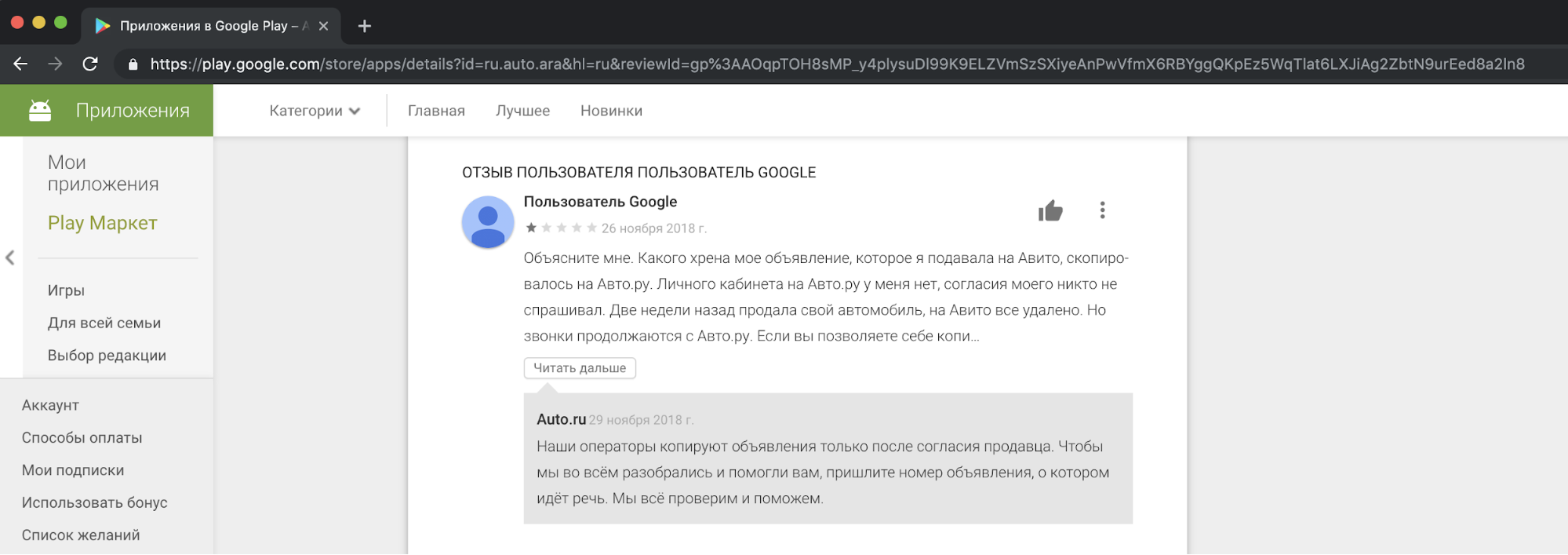
我必须说,要求人们复制广告的要求不能证明采取此类行动是合理的。 这违反了“关于广告”和“关于个人数据”的法律,Avito规则,商标权和广告数据库。
我们无法与竞争对手和平达成共识,但我们不想让局势保持现状。
解决问题的方法
第一种方法是合法的。 在其他国家已经有类似的先例。 例如,著名的美国分类网站Craigslist已从复制其内容的网站中扣押了大量金钱。
解决复制问题的第二种方法是在图像上添加较大的水印,以使其无法被裁剪。
第三种方法是技术。 我们可能会使复制内容的过程复杂化。 逻辑上假设某种模型正在向竞争对手隐藏Avito徽标。 还众所周知,许多模型容易受到“攻击”,从而无法正常工作。 本文将只涉及它们。
对抗攻击

理想情况下,网络的对抗示例看起来像人眼无法分辨的噪声,但对于分类器,它向不在图中的分类添加了足够的信号。 结果,例如具有熊猫的图片被高信度地分类为长臂猿。 不仅对于图片分类网络,而且对于分割,检测,都可能产生对抗性噪声。 一个有趣的例子是基恩实验室(Keen Labs)的最新作品:他们通过显示这种对抗性噪音欺骗了特斯拉自动驾驶仪,该自动驾驶仪的人行道上有点,还有雨水探测器。 也有针对其他领域的攻击,例如声音:对亚马逊Alexa和其他语音助手的著名攻击包括人耳无法区分的游戏团队(提供在亚马逊上购买东西的饼干)。
由于非标准使用训练模型所需的梯度,可能会为模型分析图片而产生对抗性噪声。 通常,在误差的反向传播方法中,使用目标函数的计算出的梯度,仅更改网络层的权重,以便在训练数据集上减少错误。 与网络层一样,您可以根据输入图像计算目标函数的梯度并进行更改。 使用梯度改变输入图像被用于各种众所周知的算法。 还记得Deepdream吗?

如果我们从输入图像中迭代计算目标函数的梯度并将此梯度添加到其中,则会在图像中出现有关ImageNet盛行类别的更多信息:出现更多的狗脸,因此损失函数的值减小,并且模型对``狗''类变得更有信心。 为什么在例子中是狗? 仅在ImageNet中有1000 个分类的狗-120个分类的狗 。 主要由于Prisma应用而在样式转移算法中使用了类似的图像修改方法。
要创建对抗性示例,您还可以使用更改输入图像的迭代方法。
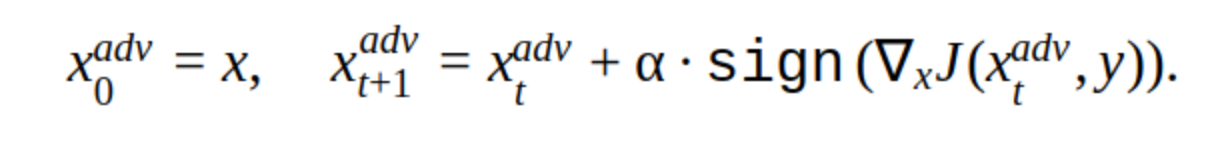
此方法有多种修改,但是基本思想很简单:在步骤α中,原始图像在分类器函数J的损失梯度(因为仅使用符号)的方向上迭代移动。 “ y”是图像中表示的类,用于减少网络对正确答案的信心。 这种攻击称为非针对性攻击。 您可以选择最佳步长和迭代次数,以使输入图像的变化与人的通常情况没有区别。 但是从时间成本的角度来看,这种攻击并不适合我们。 产品中一张图片的5-10次迭代是很长时间的。
迭代方法的替代方法是FGSM方法。

这是单发方法,即 要使用它,您需要为输入图像计算一次损失函数的梯度,并且可以将对抗性噪声添加到图像中。 这种方法显然更有效。 可用于生产。
创建对抗性例子
我们决定从破解我们自己的模型开始。
这是减少了为我们的模型找到车牌的可能性的图片。

显然,这种方法有一个缺点:它添加到图片上的更改是肉眼可见的。 同样,此方法不是针对性的,但可以更改为定向攻击。 然后,模型将预测车牌在另一个位置的位置。 这是T-FGSM方法。
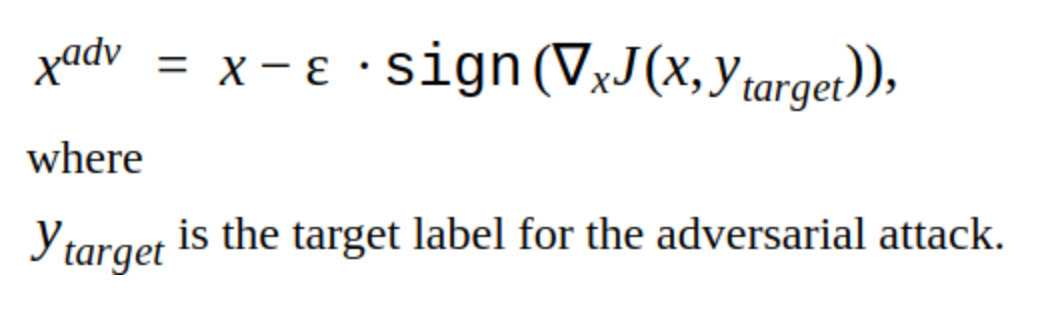
为了用这种方法打破我们的模型,您需要稍微多一点地改变输入图像。

尚不能说结果理想,但至少已经验证了方法的效率。 我们还尝试了现成的库来入侵Foolbox,CleverHans和ART-IBM网络,但是在他们的帮助下,不可能破坏我们的网络进行检测。 此处给出的方法对于分类网络更好。 这是网络黑客攻击的普遍趋势:对于对象检测而言,进行攻击更加困难,尤其是涉及复杂模型(例如Mask RCNN)时。
攻击测试
到目前为止,所描述的所有内容都没有超出我们的内部实验范围,但是有必要弄清楚如何测试对其他广告平台的检测器的攻击。
事实证明,在申请其中一种平台时,会自动检测到车牌,因此您可以上传多次照片,并检查检测算法如何应对新的对抗示例。
太好了! 但是...
在另一个平台上测试时,对我们的模型有效的攻击均无效。 为什么会这样呢? 这是由于模型不同以及对抗性攻击如何泛化到不同网络体系结构的结果。 由于攻击复制的复杂性,它们分为两类:白盒和黑盒。

我们对模型进行的攻击-这是一个白框。 我们需要的是一个黑匣子,推理上有其他限制:没有API,您所能做的就是手动上传照片并检查攻击。 如果有一个API,则可以创建一个替代模型。

这个想法是创建一个输入图像和黑匣子模型的答案的数据集,您可以在该数据集上训练几种不同体系结构的模型,以便近似黑匣子模型。 然后,您可以对这些模型进行白盒攻击,它们更有可能在黑盒上工作。 在我们的情况下,这意味着需要大量的人工工作,因此此选项不适合我们。
打破僵局
在寻找有关黑匣子攻击的有趣作品时,发现了一篇文章《 ShapeShifter:对更快的R-CNN对象检测器的强大物理对抗攻击》。
该文章的作者通过将除真类之外的图像迭代添加到停车标志的背景来攻击自动驾驶机器网络的对象检测。


人眼可以清楚地看到这种攻击,但是,它成功地打破了我们需要的对象检测网络的工作。 因此,为了工作量,我们决定忽略所需的攻击隐身性。
我们想检查检测模型的训练量,是否使用了有关汽车的信息,还是仅需要使用Avito板?
为此,创建了以下图像:

我们将其作为机器上传到带有黑匣子模型的广告平台。 收到:

这意味着您只能更换Avito板,输入图像中的其余信息对于检测黑匣子模型不是必需的。
经过几次尝试,出现了将通过FGSM方法获得的对抗噪声添加到Avito板的想法,这打破了我们自己的模型,但是具有相当大的系数ε。 原来是这样的:

开车,看起来像这样:

我们将带有黑匣子模型的照片上传到平台。 结果是成功的。

将这种方法应用于其他几张照片,我们发现它并不经常使用。 然后,经过几次尝试,我们决定将重点放在问题的另一个最引人注目的部分-边界。 众所周知,网络的初始卷积层具有对简单对象(如直线,角度)的激活。 通过“断开”边界线,我们可以防止网络正确检测数字区域。 例如,可以通过在房间的整个边界上以随机大小的白色正方形的形式添加噪声来完成此操作。

通过将此类图片上传到具有黑匣子模型的平台,我们得到了一个成功的对抗示例。

在一组其他图片上尝试了这种方法后,我们发现黑匣子模型无法再检测到Avito印版(该套件是手动组装的,不到一百张图片,虽然虽然不具有代表性,但要花费更多时间才能制作更多图片)。 有趣的观察:只有将Avito字母中的噪声与帧中的随机白方块组合在一起时,攻击才会成功,分别使用这些方法不会获得成功的结果。
结果,我们在产品中推出了该算法,结果如下:)
找到多个广告


一些新鲜的东西:
我们甚至进入了广告平台:
合计
结果,我们设法进行了对抗攻击,这在我们的实现中并没有增加图像处理时间。 我们花时间进行攻击的时间是在新年之前的两个星期。 如果在此期间无法执行此操作,则他们将放置水印。 现在,对抗性车牌已被禁用,因为现在有竞争对手致电用户,让他们自己将照片上传到广告中,或者用Internet上的库存照片替换汽车的照片。