哈Ha! 我向您介绍Matic Lubej撰写的文章“ 用eo-learn进行土地覆盖分类:第1部分 ”的翻译。
第二部分
第三部分
前言
大约六个月前,对GitHub上的eo-learn存储库进行了第一次提交。 如今, eo-learn已发展成为一个了不起的开源库,可供对EO(地球观测等译)数据感兴趣的任何人使用。 Sinergise团队中的每个人都在等待从构建必要工具的阶段过渡到其用于机器学习的阶段的时刻。 现在该向您介绍有关使用eo-learn进行土地覆盖分类的一系列文章
eo-learn是一个开放源代码的Python库,它充当将地球观测/遥感与Python机器学习库的生态系统连接的桥梁。 我们已经在Blog上写了一篇单独的文章,建议您熟悉一下。 该库使用numpy库和shapely库中的基元来存储和处理卫星数据。 目前,它可以在GitHub存储库中找到 ,并且可以在指向ReadTheDocs的适当链接处找到该文档。

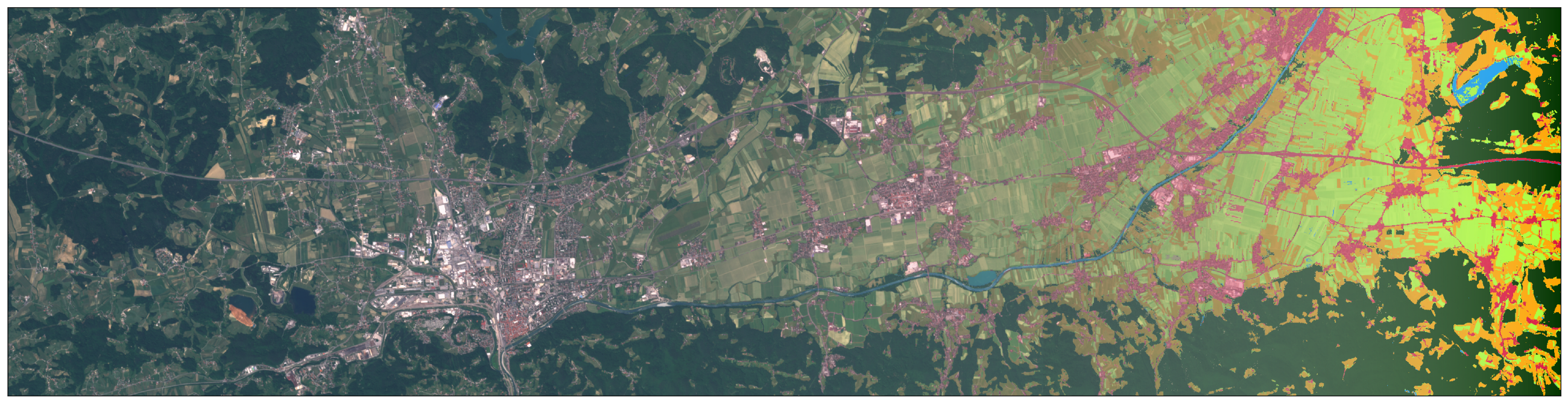
斯洛文尼亚冬季小区域的Sentinel-2卫星图像和NDVI掩模
为了展示eo-learn的功能,我们决定使用多时相输送机,使用2017年的数据对斯洛文尼亚共和国(我们居住的国家)的领土范围进行分类。 由于完整的过程对于一篇文章来说可能太复杂了,因此我们决定将其分为三部分。 因此,无需跳过这些步骤并立即进行机器学习-首先,我们必须真正了解要使用的数据。 每篇文章都将附有Jupyter Notebook示例。 此外,对于感兴趣的人,我们已经准备了一个涵盖所有阶段的完整示例 。
- 在第一篇文章中,我们将指导您完成选择/分割感兴趣区域(以下简称AOI,感兴趣区域)的过程,并获取必要的信息,例如来自卫星传感器和云罩的数据。 我们还将展示一个示例,说明如何根据矢量数据在实际覆盖区域上创建数据的栅格掩码。 所有这些都是获得可靠结果的必要步骤。
- 在第二部分中,我们将深入研究机器学习过程的数据准备。 此过程包括获取随机样本以训练\验证像素,移除云图像,对时间数据进行插值以填充“空洞”等。
- 在第三部分中,我们将考虑分类器的训练和验证,当然还有精美的图形!

夏季斯洛文尼亚小区域的Sentinel-2卫星图像和NDVI掩模
感兴趣的领域? 选择!
eo-learn库允许您将AOI拆分为小片段,可以在计算资源有限的情况下对其进行处理。 在此示例中,斯洛文尼亚边界取自“ 自然地球” ,但是,您可以选择任何大小的区域。 我们还向边界添加了一个缓冲区,之后AOI尺寸约为250x170 km。 利用geopandas的魔力和shapely库,我们创建了一个打破AOI的工具。 在这种情况下,我们将区域划分为相同大小的25x17正方形,结果我们收到了300个1000x1000像素的片段,分辨率为10m。 有关拆分成碎片的决定取决于可用的计算能力。 作为此步骤的结果,我们得到了覆盖AOI的正方形列表。

AOI(斯洛文尼亚地区)被划分为小方块,大小约为1000x1000像素,分辨率为10m。
从Sentinel卫星接收数据
确定平方后, eo-learn允许您自动从Sentinel卫星下载数据。 在此示例中,我们获取了2017年拍摄的所有Sentinel-2 L1C图像。 值得注意的是,可以通过类似的方式将Sentinel-2 L2A产品以及其他数据源(Landsat-8,Sentinel-1)添加到管道中。 还值得注意的是,使用L2A产品可以改善分类结果,但是我们决定使用L1C来解决方案的普遍性。 这是使用sentinelhub-py ,该库的工作方式类似于Sentinel-Hub服务的包装器。 研究机构和初创公司免费使用这些服务,但在其他情况下,则需要订阅。

一个片段在不同日期的彩色图像。 有些图像是多云的,这意味着需要云探测器。
除了Sentinel数据外, s2cloudless库, eo-learn使您可以透明地访问云和云概率数据。 该库提供了用于自动逐像素检测云的工具。 详细信息可以在这里阅读。
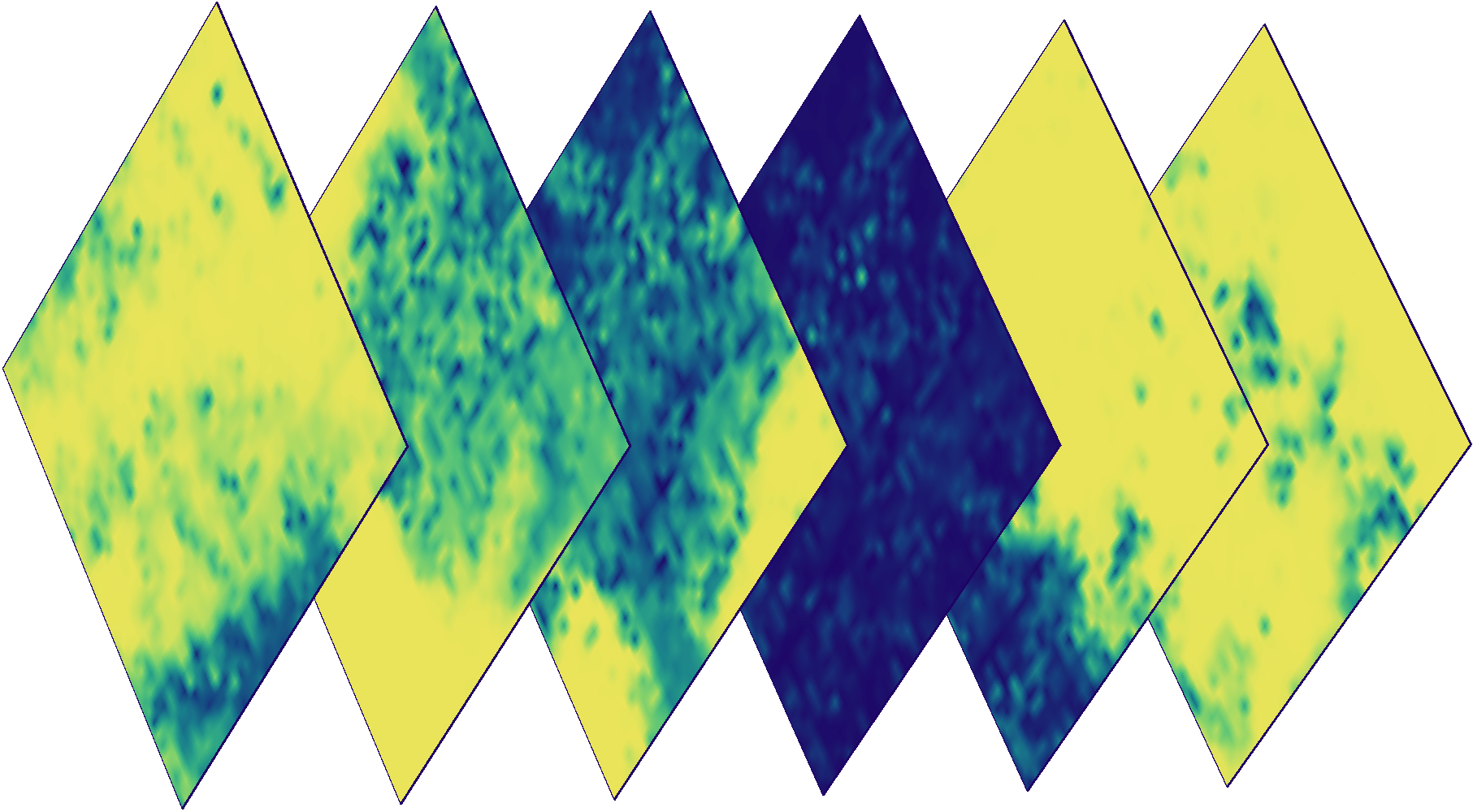
上面图像的云遮罩。 颜色表示特定像素出现浑浊的概率(蓝色-低概率,黄色-高)。
添加真实数据
与老师一起教学需要一张带有真实数据或真相的卡片。 不应从字面上理解最后一个术语,因为实际上,数据只是表面上的近似值。 不幸的是,分类器的行为在很大程度上取决于该卡的质量( 但是,对于机器学习中的大多数其他任务 )。 带标签的地图通常以shapefile格式(例如,由州或社区提供)作为矢量数据提供。 eo-learn包含用于以光栅掩码形式对矢量数据进行光栅化的工具。

以一个正方形为例将数据栅格化为蒙版的过程。 向量文件中的多边形显示在左侧图像中,每个标签的光栅蒙版显示在中间-黑色和白色分别表示存在或不存在特定属性。 右图显示了一个组合的光栅蒙版,其中不同的颜色表示不同的标签。
全部放在一起
所有这些任务的行为都像构建块,可以组合为每个正方形执行的便捷操作序列。 由于此类碎片的数量可能非常多,因此绝对需要管道自动化
了解实际数据是处理此类任务的第一步。 通过将云遮罩与Sentinel-2的数据配对使用,您可以确定所有像素的质量观测值的数量,以及特定区域中云的平均概率。 因此,您可以更好地了解现有数据,并在调试其他问题时使用它。

彩色图像(左),2017年质量测量值的掩码(中)和AOI中随机碎片的2017年平均云层覆盖率(右)。
可能有人对任意区域的平均NDVI感兴趣,而忽略了云层。 使用云遮罩,您可以计算任何功能的平均值,而忽略没有数据的像素。 因此,由于有了掩模,我们几乎可以清除数据中任何特征的图像。
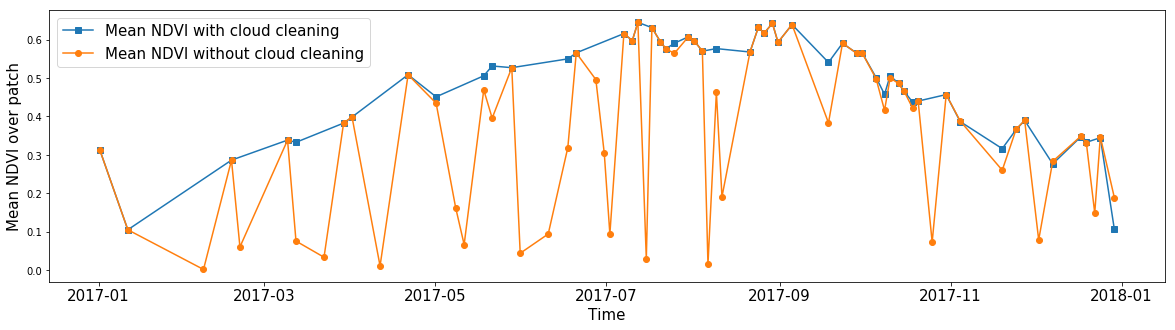
全年随机AOI片段中所有像素的平均NDVI。 蓝线表示忽略云内部的值而获得的计算结果。 当考虑所有像素时,橙色线显示平均值。
“但是缩放呢?”
在我们以一个碎片为例设置输送机之后,剩下的要做的就是自动为所有碎片启动一个类似的过程(如果资源允许的话,并行执行),同时您放松地喝杯咖啡,想一想老板多大可以感到惊喜工作的结果。 管道结束后,您可以将您感兴趣的数据导出为GeoTIFF格式的单个图像。 脚本gdal_merge.py接收图像并将其组合,从而生成覆盖整个国家的图片。
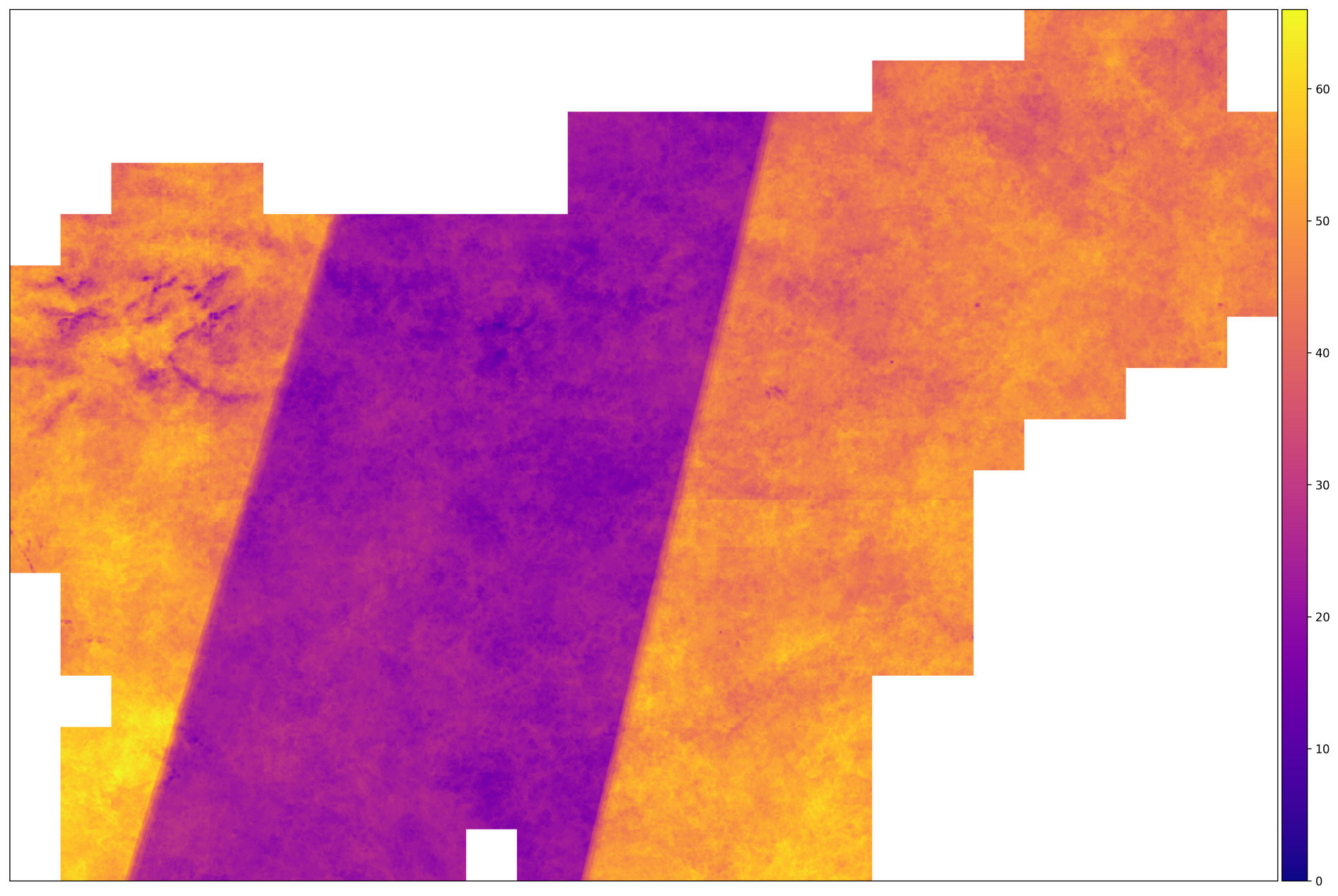
2017年AOI的正确拍摄数量。 包含大量图像的区域位于Sentinel-2A和Sentinel-2B卫星的轨迹相交的区域。 在这种情况下不会发生。
从上面的图像中,我们可以得出结论,输入数据是异构的-对于某些片段,图像的数量是其他图像的两倍。 这意味着我们需要采取措施对数据进行归一化-例如沿时间轴的插值。
指定的流水线执行一个片段大约需要140秒,在整个AOI中启动该过程总共需要大约12个小时。 大多数时间是在下载卫星数据。 具有上述配置的平均未压缩片段大约需要3 GB,这对于整个AOI总共提供〜1 TB的空间。
Jupyter笔记本中的示例
为了更简单地介绍eo-learn代码,我们准备了一个示例,涵盖了本文中讨论的主题。 该示例被设计为Jupyter笔记本,您可以在eo-learn软件包的examples目录中找到它。