每天,来自全球数千个组织的数万名员工在Pyrus工作。 我们认为服务的响应能力(处理请求的速度)是一项重要的竞争优势,因为它直接影响用户体验。 对我们而言,关键指标是“慢查询的百分比”。 在研究其行为时,我们注意到应用程序服务器上每隔一分钟就有大约1000 ms的暂停时间。 在这些时间间隔内,服务器不响应,并且出现几十个请求的队列。 本文将讨论在应用程序中寻找由垃圾收集引起的瓶颈的原因并消除瓶颈。

现代编程语言可以分为两组。 在诸如C / C ++或Rust的语言中,使用了手动内存管理,因此程序员花费更多的时间编写代码,管理对象的生存期,然后进行调试。 同时,由于内存使用不当引起的错误是最难以调试的,因此,大多数现代开发都是使用具有自动内存管理功能的语言进行的。 这些包括,例如,Java,C#,Python,Ruby,Go,PHP,JavaScript等。 程序员可以节省开发时间,但是您必须支付程序通常在垃圾回收上花费的额外执行时间-释放程序中没有链接的对象所占用的内存。 在小型程序中,这个时间可以忽略不计,但是随着对象数量的增加和其创建强度的增加,垃圾回收开始对程序的总执行时间做出显着贡献。
Pyrus Web服务器在.NET平台上运行,该平台使用自动内存管理。 大多数垃圾收集都是``阻止世界'',即 在工作时,他们停止了应用程序的所有线程。 非阻塞(后台)程序集实际上也会停止所有线程,但是会持续很短的时间。 在线程阻塞期间,服务器不处理请求,现有请求被冻结,新请求被添加到队列中。 结果,直接降低了垃圾收集时处理的请求,并且由于累积的队列,垃圾收集完成后立即处理请求的速度变慢。 这会使指标“慢查询的百分比”恶化。
有了最近出版的《
Konrad Kokosa:Pro .NET内存管理》 (关于我们如何在两天内将其第一份副本带到俄罗斯,您可以写一篇单独的文章)的书,我们完全致力于.NET中的内存管理,我们开始研究此问题。
测量值
为了分析Pyrus Web服务器,我们使用了PerfView实用程序(
https://github.com/Microsoft/perfview ),该实用程序经过了改进,可用于分析.NET应用程序。 该实用程序基于Windows事件跟踪(ETW)引擎,并且对配置文件应用程序的性能影响很小,因此可以在战斗服务器上使用。 此外,对性能的影响取决于事件的类型和收集的信息。 我们不收集任何东西-该应用程序照常工作。 另外,PerfView不需要重新编译或重新启动应用程序。
使用/ GCCollectOnly参数运行PerfView跟踪(跟踪时间为1.5小时)。 在这种模式下,它仅收集垃圾收集事件,并且对性能的影响最小。 让我们看一下“内存组/ GCStats”跟踪报告,并在其中总结垃圾收集器事件:
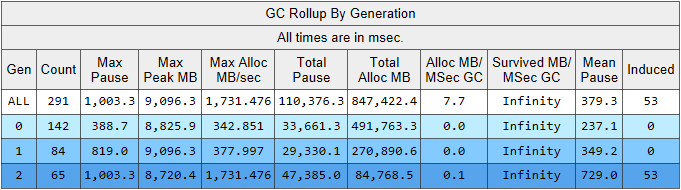
在这里,我们可以立即看到几个有趣的指标:
- 第二代的平均构建暂停时间为700毫秒,最大暂停时间约为一秒钟。 该图显示了.NET应用程序中所有线程停止的时间,特别是,此暂停将添加到所有已处理的请求中。
- 第2代的装配件数与第1代相当,并且略少于第0代的装配件数。
- 诱导列列出了第二代中的53个装配。 诱导程序集是显式调用GC.Collect()的结果。 在我们的代码中,没有找到对该方法的单个调用,这意味着应归咎于应用程序使用的某些库。
让我们解释一下有关垃圾收集数量的观察。 将对象除以它们的生存期的想法是基于
世代假设的 :创建的对象中有很大一部分会很快死亡,而其他大多数对象的寿命很长(换句话说,具有“平均”生存期的对象很少)。 在这种模式下,.NET垃圾收集器将被监禁,并且在这种模式下,第二代程序集应该比第0代小得多。 也就是说,为了使垃圾收集器最佳运行,我们必须根据世代假设调整应用程序的工作。 让我们将规则表述如下:对象必须要么死掉而又不存活到老一代,要么必须生存下去并永远存在。 该规则也适用于其他使用自动内存管理并按代分离的平台,例如Java。
我们感兴趣的数据可以从GCStats报告中的另一个表中提取:

在某些情况下,应用程序尝试创建大对象(在.NET Framework中,在LOH中创建了大于85,000字节的对象-大对象堆),它必须等待第二代程序集的完成,该程序在后台并行发生。 分配器的这些暂停没有垃圾回收器的暂停那么重要,因为它们仅影响一个线程。 在此之前,我们使用.NET Framework 4.6.1版本,并且在Microsoft 4.7.1版本中最终确定了垃圾收集器,现在它允许您在第二代的后台构建期间在大对象堆中分配内存:
https :
//docs.microsoft.com / ru-ru / dotnet /框架/最新消息/#common-language-runtime-clr因此,我们当时升级到了最新版本4.7.2。
第二代构建
为什么我们有这么多的上一代产品? 第一个假设是我们有内存泄漏。 为了检验这个假设,让我们看一下第二代的大小(我们在Zabbix中设置了对相应性能计数器的监视)。 从2台Pyrus服务器的第二代大小的图表中可以看出,它的大小先增大(主要是由于缓存的填充),然后又稳定了(图形上的大故障-定期重启Web服务以更新版本):
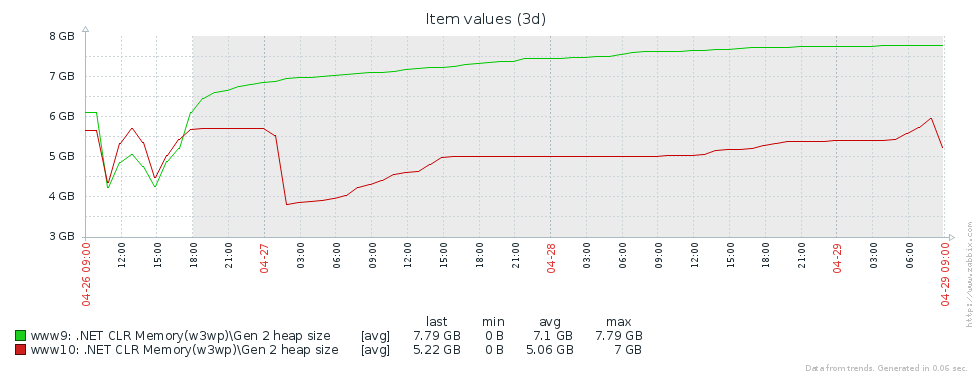
这意味着没有明显的内存泄漏,即,由于另一个原因,发生了大量的第二代程序集。 下一个假设是存在大量内存流量,即许多对象属于第二代,并且许多对象在那里死亡。 PerfView具有/ GCOnly模式来查找此类对象。 在跟踪报告中,我们要注意“第二代对象死亡(粗采样)堆栈”,其中包含第二代中死亡的对象的选择,以及这些对象创建位置的调用堆栈。 在这里,我们看到以下结果:
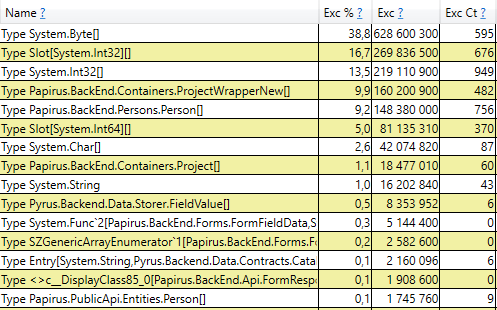
打开该行之后,我们在内部看到了代码中那些位置的调用堆栈,这些位置创建了直到第二代的对象。 其中包括:
- System.Byte []如果查看内部,我们将看到一半以上是用于JSON序列化的缓冲区:
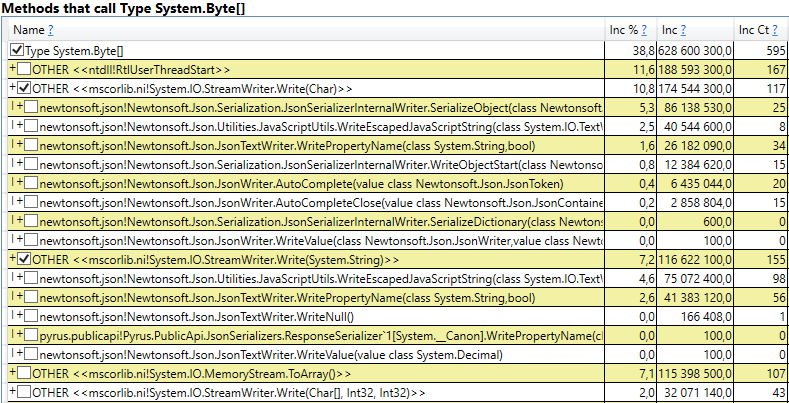
- 插槽[System.Int32] [](这是HashSet实现的一部分),System.Int32 []等。 这是我们的代码,用于计算客户端缓存-该用户看到的目录,表单,列表,朋友等,并在其浏览器或移动应用程序中缓存:

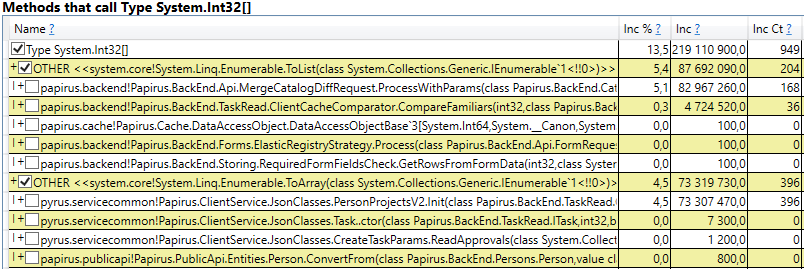
有趣的是,JSON和计算客户端缓存的缓冲区都是存在于同一请求上的所有临时对象。 他们为什么不辜负第二代? 请注意,所有这些对象都是相当大的数组。 并且在大于85000字节的大小下,用于它们的内存分配在大对象堆中,该对象仅与第二代一起收集。
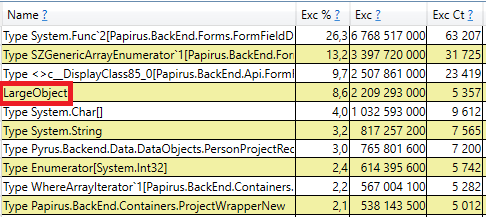
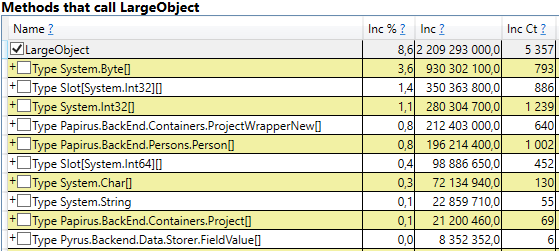
要进行检查,请在perfview / GCOnly结果中打开“ GC Heap Alloc忽略免费(粗采样)堆栈”部分。 在这里,我们看到LargeObject行,其中PerfView将大对象的创建分组,在内部,我们看到的是与之前分析中相同的所有数组。 我们承认垃圾收集器出现问题的根本原因:我们创建了许多临时的大对象。
Pyrus系统的变化
根据测量结果,我们确定了进一步工作的主要领域:在计算客户端缓存和JSON序列化时与大型对象的斗争。 有几种解决此问题的方法:
- 最简单的事情是不创建大型对象。 例如,如果在顺序数据转换A-> B-> C中使用大缓冲区B,则有时可以通过将它们转换为A-> C并消除对象B的创建来组合这些转换。此选项并非始终适用,但是最简单,最有效的方法。
- 对象池。 无需不断创建新对象并扔掉它们,而是加载垃圾收集器,我们可以存储自由对象的集合。 在最简单的情况下,当我们需要一个新对象时,我们从池中获取它,如果池为空,则创建一个新对象。 当我们不再需要该对象时,我们将其返回到池中。 一个很好的例子是.NET Core中的ArrayPool,它也可以作为.System.Buffers Nuget包的一部分在.NET Framework中使用。
- 使用小物体代替大物体。
让我们分别考虑大型对象的两种情况-计算客户端缓存和JSON序列化。
客户端缓存计算
Pyrus Web客户端和移动应用程序缓存用户可用的数据(项目,表单,用户等)。缓存用于加快工作速度,在脱机模式下工作也是必需的。 缓存在服务器上计算,然后传输到客户端。 它们对于每个用户都是独立的,因为它们取决于他们的访问权限,并且经常在例如更改其有权访问的目录时进行更新。
因此,在服务器上定期执行许多客户端缓存计算,并且创建了许多临时的短期对象。 如果用户是一个大型组织,则他可以分别访问许多对象,因此对他而言客户端缓存将很大。 这就是为什么我们在大型对象堆中看到了为大型临时数组分配内存的原因。
让我们分析为摆脱大型对象的创建而提议的选项:
- 彻底处理大物件。 此方法不适用,因为数据准备算法除其他外使用集的排序和并集,并且它们需要临时缓冲区。
- 使用对象池。 这种方法有困难:
- 使用了各种集合以及其中的元素类型:使用了HashSet,List和Array(可以将后两个集合结合使用)。 Int32,Int64以及各种数据类都存储在集合中。 对于每种使用的类型,您将需要自己的池,该池还将存储不同大小的集合。
- 收藏品的使用寿命很困难。 为了从池中获得收益,池中的对象将在使用后返回。 如果将对象用于一种方法,则可以完成此操作。 但是在我们的情况下情况更加复杂,因为许多大对象在方法之间移动,被放入数据结构中,然后被转移到其他结构等。
- 实施。 有Microsoft的ArrayPool,但我们仍然需要List和HashSet。 我们找不到合适的库,因此我们必须自己实现这些类。
- 使用小物件。 一个大数组可以分为几个小块,我不会加载大对象堆,而是在第0代中创建,然后在第1和第2代中遵循标准路径。 我们希望它们不会辜负第二代,但会在第0代,或者在极端情况下在第1代被垃圾收集器收集。 这种方法的优点是对现有代码的更改最少。 难点:
- 实施。 我们找不到任何合适的库,因此我们必须自己编写类。 缺少库是可以理解的,因为方案“不加载大对象堆的集合”的范围非常狭窄。
我们决定走第三条路线,
发明自行车来编写List和HashSet,而不是加载大对象堆。
件清单
我们的ChunkedList <T>实现了标准接口,包括IList <T>,该接口只需对现有代码进行最少的更改即可。 是的,我们使用的Newtonsoft.Json库能够自动序列化它,因为它实现了IEnumerable <T>:
public sealed class ChunkedList<T> : IList<T>, ICollection<T>, IEnumerable<T>, IEnumerable, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T> {
标准列表<T>具有以下字段:元素数组和填充元素的数量。 在ChunkedList <T>中,有一个元素数组数组,完全填充的数组数量,最后一个数组中的元素数量。 每个少于85,000个字节的元素数组:

private T[][] chunks; private int currentChunk; private int currentChunkSize;
由于ChunkedList <T>相当复杂,因此我们在上面编写了详细的测试。 任何操作都必须在至少两种模式下进行测试:如果“整个”列表可容纳多达85,000个字节,则以“小”模式运行;如果包含多个以上的内容,则以“大”模式进行测试。 此外,对于更改大小的方法(例如,添加),方案甚至更大:“小”->“小”,“小”->“大”,“大”->“大”,“大”->“小。” 在这里,有很多令人困惑的边界案例,它们的单元测试效果很好。
由于不使用IList接口中的某些方法,因此可以简化这种情况,并且可以将其省略(例如Insert,Remove)。 它们的实施和测试将是相当大的开销。 另外,由于不需要编写新功能,因此简化了编写单元测试的过程,ChunkedList <T>的行为应与List <T>相同。 也就是说,所有测试的组织方式如下:创建List <T>和ChunkedList <T>,对它们执行相同的操作并比较结果。
我们使用BenchmarkDotNet库测量了性能,以确保从List <T>切换到ChunkedList <T>时,我们不会降低代码的速度。 让我们测试一下,例如,将项目添加到列表中:
[Benchmark] public ChunkedList<int> ChunkedList() { var list = new ChunkedList<int>(); for (int i = 0; i < N; i++) list.Add(i); return list; }
与相同的测试使用List <T>进行比较。 添加500个元素时的结果(所有元素都适合一个数组):
添加50,000个元素(拆分为多个数组)时的结果:
结果列的详细说明 BenchmarkDotNet=v0.11.4, OS=Windows 10.0.17763.379 (1809/October2018Update/Redstone5) Intel Core i7-8700K CPU 3.70GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores [Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0 DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
如果您查看显示平均测试执行时间的“平均值”列,您会发现我们的实施仅比标准实施慢2-2.5倍。 考虑到在实际代码中,带有列表的操作仅是所有执行的动作的一小部分,因此这种差异变得微不足道。 但是``Gen 2 / 1k op''(每1000次测试运行中第二代的程序集数量)一栏表明我们已经实现了目标:拥有大量元素的ChunkedList不会在第二代中创建垃圾,这是我们的任务。
件套
同样,ChunkedHashSet <T>实现ISet <T>接口。 在编写ChunkedHashSet <T>时,我们重用了ChunkedList中已实现的小块逻辑。 为此,我们从.NET参考源中获取了现成的HashSet <T>的实现(可从MIT许可下获得),并将其中的数组替换为ChunkedLists。
在单元测试中,我们还使用与列表相同的技巧:我们将ChunkedHashSet <T>与参考HashSet <T>的行为进行比较。
最后是性能测试。 我们使用的主要操作是集合的并集,这就是我们对其进行测试的原因:
public ChunkedHashSet<int> ChunkedHashSet(int[][] source) { var set = new ChunkedHashSet<int>(); foreach (var arr in source) set.UnionWith(arr); return set; }
与标准HashSet完全相同的测试。 小套的第一次测试:
var source = new int[][] { Enumerable.Range(0, 300).ToArray(), Enumerable.Range(100, 600).ToArray(), Enumerable.Range(300, 1000).ToArray(), }
大型集合的第二项测试导致了一堆大型对象出现问题:
var source = new int[][] { Enumerable.Range(0, 30000).ToArray(), Enumerable.Range(10000, 60000).ToArray(), Enumerable.Range(30000, 100000).ToArray(), }
结果与清单类似。 ChunkedHashSet的速度慢了2-2.5倍,但同时在大型集合上,它对第二代的负载减少了2个数量级。
JSON中的序列化
Pyrus Web服务器提供了几个使用不同序列化的API。 我们发现了在漫游器使用的API和同步实用程序(以下称为“公共API”)中创建了大型对象。 请注意,API基本上使用自己的序列化,不受此问题的影响。 我们在
https://habr.com/en/post/227595/中的文章“ 2。 您不知道应用程序的瓶颈在哪里。” 也就是说,主要API已经运行良好,并且随着请求数量和响应中数据量的增加,该问题出现在Public API中。
让我们优化公共API。 通过使用主API的示例,我们知道您可以以流模式将响应返回给用户。 也就是说,您无需创建包含整个响应的中间缓冲区,而是将响应立即写入流中。
通过仔细检查,我们发现在序列化响应的过程中,我们为中间结果创建了一个临时缓冲区(“ content”是一个字节数组,其中包含UTF-8编码的JSON):
var serializer = Newtonsoft.Json.JsonSerializer.Create(...); byte[] content; var sw = new StreamWriter(new MemoryStream(), new UTF8Encoding(false)); using (var writer = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(writer, result); writer.Flush(); content = ms.ToArray(); }
让我们看看在哪里使用内容。 由于历史原因,公共API基于WCF,因此XML是标准的请求和响应格式。 在我们的例子中,XML响应只有一个'Binary'元素,在其中写入了以Base64编码的JSON:
public class RawBodyWriter : BodyWriter { private readonly byte[] _content; public RawBodyWriter(byte[] content) : base(true) { _content = content; } protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { writer.WriteStartElement("Binary"); writer.WriteBase64(_content, 0, _content.Length); writer.WriteEndElement(); } }
请注意,此处不需要临时缓冲区。 JSON可以立即写入WCF提供给我们的XmlWriter缓冲区,并在Base64中即时对其进行编码。 因此,我们将走第一种方式,摆脱内存分配:
protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { var serializer = Newtonsoft.Json.JsonSerializer.Create(...); writer.WriteStartElement("Binary"); Stream stream = new Base64Writer(writer); Var sw = new StreamWriter(stream, new UTF8Encoding(false)); using (var jsonWriter = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(jsonWriter, _result); jsonWriter.Flush(); } writer.WriteEndElement(); }
这里的Base64Writer是XmlWriter的简单包装,实现了Stream接口,该接口以Base64的形式写入XmlWriter。 同时,从整个接口来看,仅实现一个Write方法就足够了,该方法在StreamWriter中被调用:
public class Base64Writer : Stream { private readonly XmlWriter _writer; public Base64Writer(XmlWriter writer) { _writer = writer; } public override void Write(byte[] buffer, int offset, int count) { _writer.WriteBase64(buffer, offset, count); } <...> }
诱导GC
让我们尝试处理神秘的垃圾收集。 我们针对GC.Collect调用重新检查了10次代码,但这失败了。 我设法在PerfView中捕获了这些事件,但是调用堆栈的指示性不是很好(DotNETRuntime / GC /触发事件):
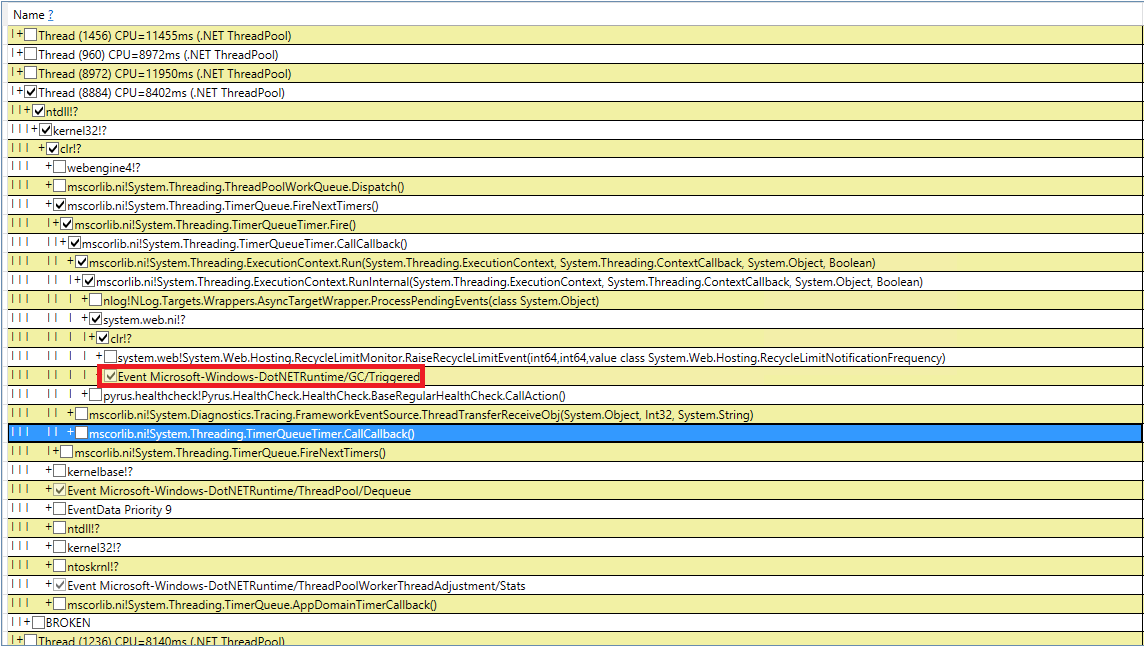
有一个小提示-在引发垃圾回收之前调用RecycleLimitMonitor.RaiseRecycleLimitEvent。 让我们跟踪对RaiseRecycleLimitEvent方法的调用堆栈:
RecycleLimitMonitor.RaiseRecycleLimitEvent(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.AlertProxyMonitors(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.CollectInfrequently(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.PBytesMonitorThread(...)
方法的名称与其功能一致:
- 在RecycleLimitMonitor.RecycleLimitMonitorSingleton的构造函数中,创建一个计时器,该计时器以特定间隔调用PBytesMonitorThread。
- PBytesMonitorThread收集有关内存使用情况的统计信息,在某些情况下,不经常调用CollectIn。
- CollectInfrequently调用AlertProxyMonitors,结果为布尔值,如果为true,则调用GC.Collect()。 他还监视自上次调用垃圾收集器以来经过的时间,并且不经常调用它。
- AlertProxyMonitors遍历正在运行的IIS Web应用程序的列表,每个都引发相应的RecycleLimitMonitor对象,然后调用RaiseRecycleLimitEvent。
- RaiseRecycleLimitEvent引发IObserver <RecycleLimitInfo>列表。 处理程序接收RecycleLimitInfo作为参数,在其中可以设置RequestGC标志,该标志将返回到CollectInfrequently,从而引发垃圾回收。
进一步的调查显示,IObserver <RecycleLimitInfo>处理程序已添加到RecycleLimitMonitor.Subscribe()方法中,该方法在AspNetMemoryMonitor.Subscribe()方法中被调用。 另外,默认的IObserver <RecycleLimitInfo>处理程序(RecycleLimitObserver类)挂在AspNetMemoryMonitor类中,该类清除ASP.NET缓存,有时还要求进行垃圾收集。
诱导GC的难题几乎解决了。 仍然需要找出为什么调用此垃圾回收的问题。 RecycleLimitMonitor监视IIS内存的使用(更精确地讲,专用字节数),并且当其使用达到某个限制时,它会以一种相当混乱的算法开始,以引发RaiseRecycleLimitEvent事件。 AspNetMemoryMonitor.ProcessPrivateBytesLimit的值用作内存限制,并且依次包含以下逻辑:
- 如果IIS中的“应用程序池”设置为“专用内存限制(KB)”,则从那里获取以千字节为单位的值
- 否则,对于64位系统,将占用60%的物理内存(对于32位系统,逻辑会更复杂)。
调查的结论是:ASP.NET接近其内存限制,并开始定期调用垃圾回收。 未设置“专用内存限制(KB)”,因此ASP.NET被限制为物理内存的60%。 该问题被以下事实掩盖了:在任务管理器服务器上,它显示了很多可用内存,并且似乎丢失了。 我们已将IIS中“应用程序池”设置中的“专用内存限制(KB)”值增加到物理内存的80%。 这鼓励ASP.NET使用更多的可用内存。 我们还添加了对性能计数器“ .NET CLR内存/#诱导的GC”的监视,以免下次ASP.NET决定其接近内存使用限制时不会丢失。
重复测量
让我们看看所有这些更改之后垃圾回收发生了什么。 让我们从perfview / GCCollectOnly(跟踪时间-1小时)开始,GCStats报告:
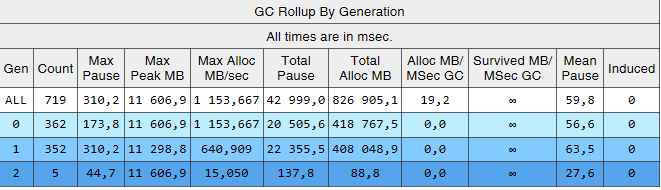
可以看出,第二代的组件现在比第0代和第1代小2个数量级。 而且,这些组装的时间减少了。 不再观察到诱导组装。 让我们看一下第二代的程序集列表:
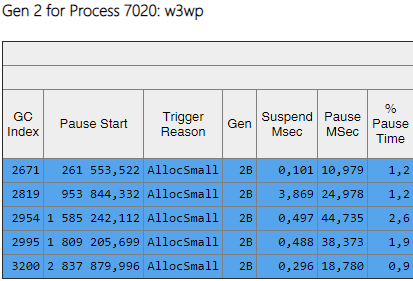
“ Gen”列显示第二代的所有装配都已成为背景(“ 2B”表示第二代,背景)。 即,大多数工作与应用程序的执行并行执行,并且所有线程都在短时间内被阻塞(列“ Pause MSec”)。 让我们看一下创建大对象时的停顿:

可以看出,创建大型对象时,此类暂停的次数大大减少了。
总结
由于文章中描述的更改,可以显着减少第二代组件的数量和持续时间。 我设法找到引起装配的原因并消除它们。 第0代和第1代的程序集数量增加了,但是它们的平均持续时间却减少了(从〜200 ms到〜60 ms)。 第0代和第1代的最大装配时间有所减少,但并没有那么明显。 第二代装配变得更快,长达1000ms的长时间停顿完全消失了。
至于关键指标“慢查询的百分比”,经过所有更改后,它下降了40%。
由于我们的工作,我们意识到需要使用性能计数器来评估内存和垃圾回收情况,并将其添加到Zabbix进行连续监视。 以下是我们需要注意并找出原因的最重要列表(例如,请求流增加,大量传输的数据,应用程序中的错误):