文章的标题可能看起来很奇怪,并且有充分的理由-它之所以精美,恰恰是因为它不是我写的,而是LSTM神经网络(或者,它在“或”之前的部分)写的。
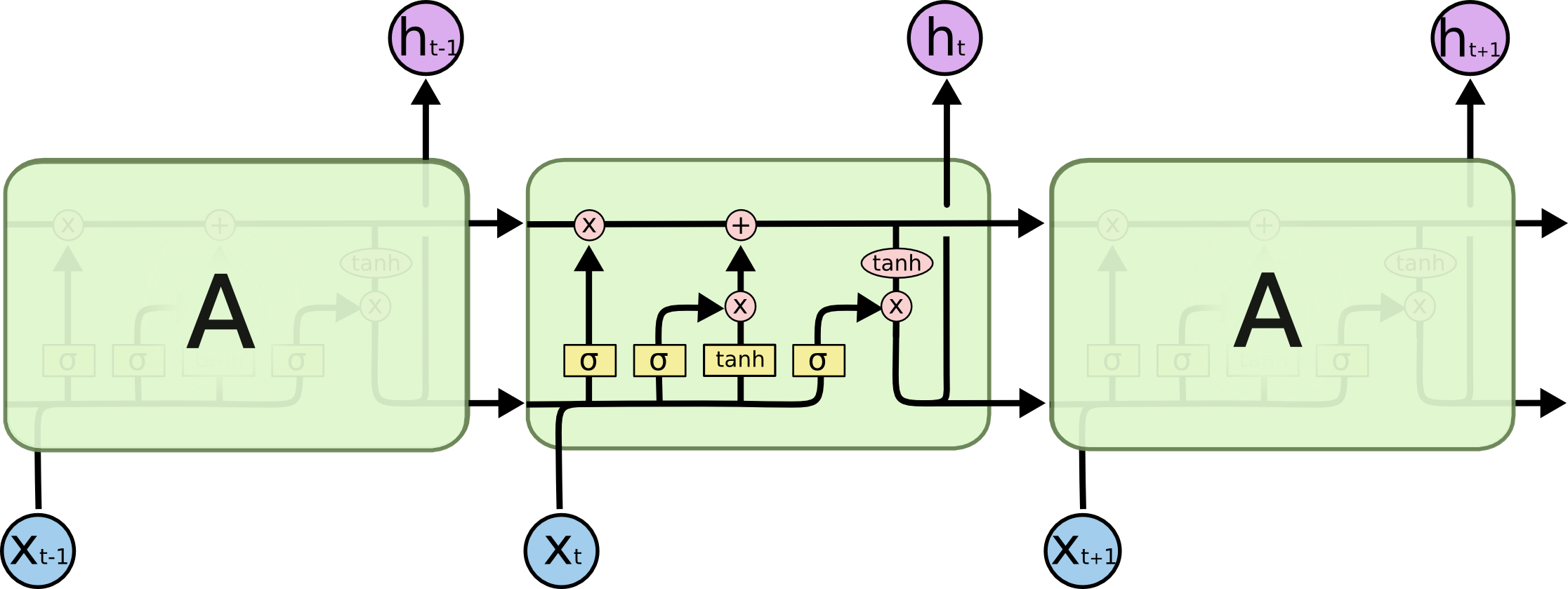
(来自理解LSTM网络的 LSTM方案)
今天,我们将弄清楚如何生成Habr文章的标题(原则上,文本本身可以由同一神经体系结构生成)。 所有代码都可以在Google的笔记本中在线运行。 像往常一样,数据在github上打开。
在这里,您可以在Google的GPU上运行已经训练有素的模型(免费且无SMS),并实际生成标头。
关键链接
本文中神经网络(特别是LSTM)的理论和描述基于
资料说明
总共收集了约4万篇文章标题 :每个标题在开头和结尾处都添加了两个特殊字符<START_CHAR>和<END_CHAR>,并在<END_CHAR>之后添加了<PADDING_CHAR>,以达到标题的最大大小。
收集的数据示例:
Google IT . Now it's official
LSTM理论
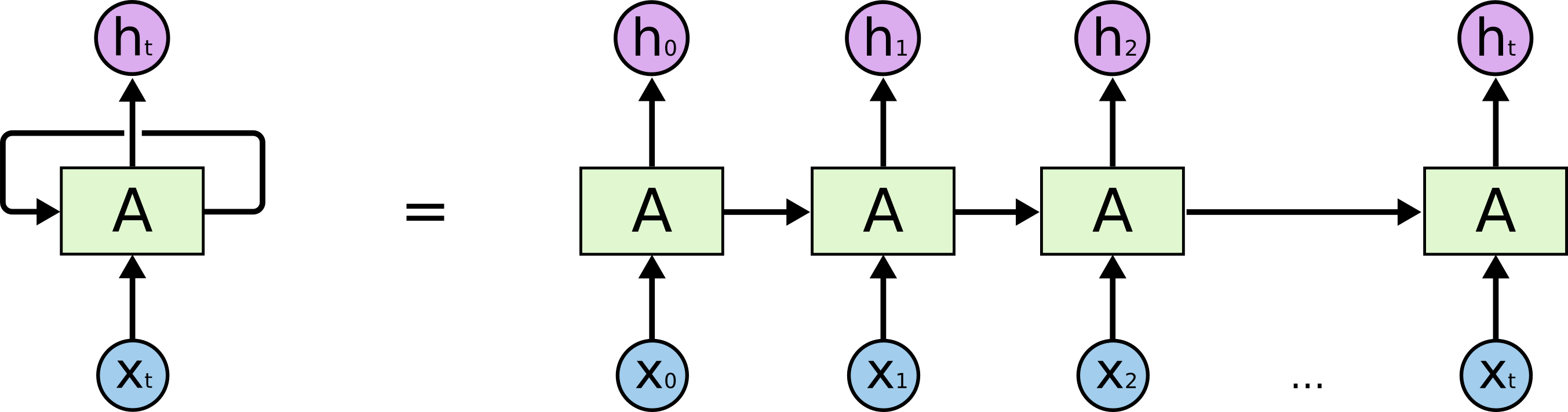
让我们从解决的实际任务开始:我们希望以L个字符为单位来预测第(N + 1)行,从LSTM模型的角度来看,如下图所示:X下方-输入数据; 以上是周末; 它们之间是网络的内部状态。 更详细一点-左侧的图像带有反馈环,等效于右侧的详细链。
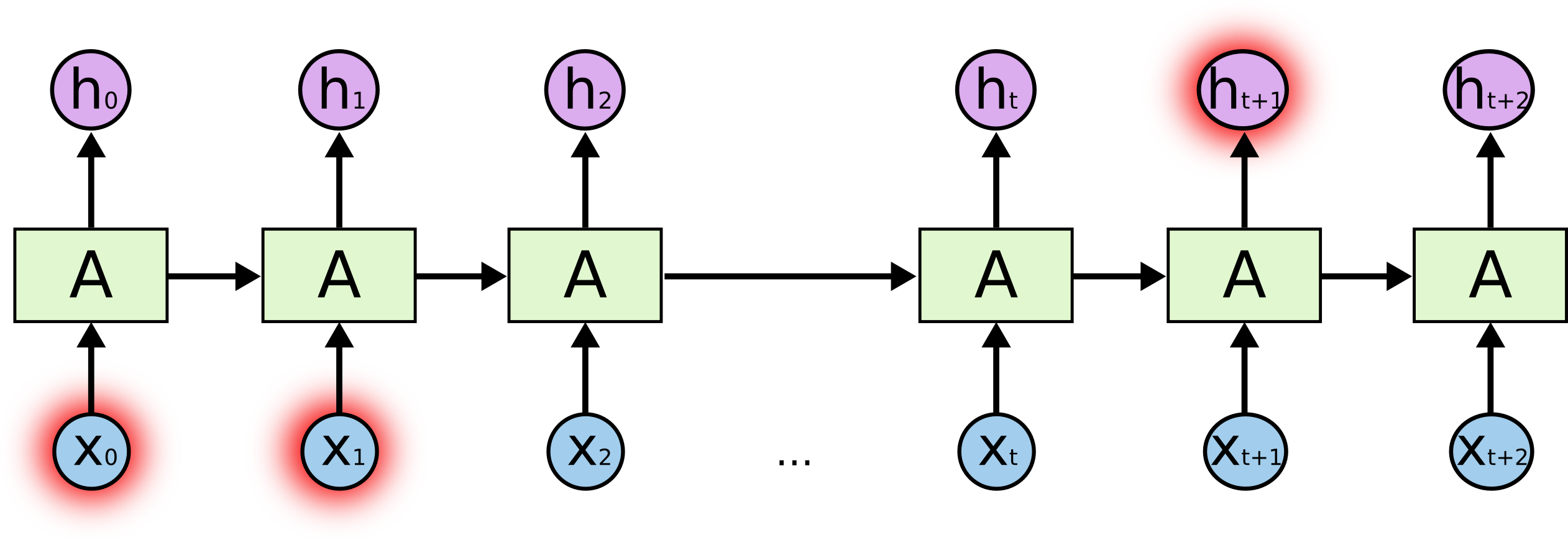
什么盐? 在预测末尾突出显示的字符时,在末尾突出显示的字符可以发挥关键作用-因此是长期依赖项。 显然,紧挨在它们旁边的字符通常起着重要的作用-这种依赖性称为短期依赖性。
LSTM电池内部零件:
整个单元包含四个基本元素。
- 遗忘之门-一个元素决定它将耗尽内存
- 传入门-它创建了一组“候选值”,可用于写入和更新内存
- 记忆-一个元素决定什么以及我们如何保存
- 输出元素-定义模型的输出
名称:

遗忘之门
如果我们试图预测单词的结尾-重要的是要知道当前名词的性别,如果我们看到一个新名词-则应忘记先前的含义:

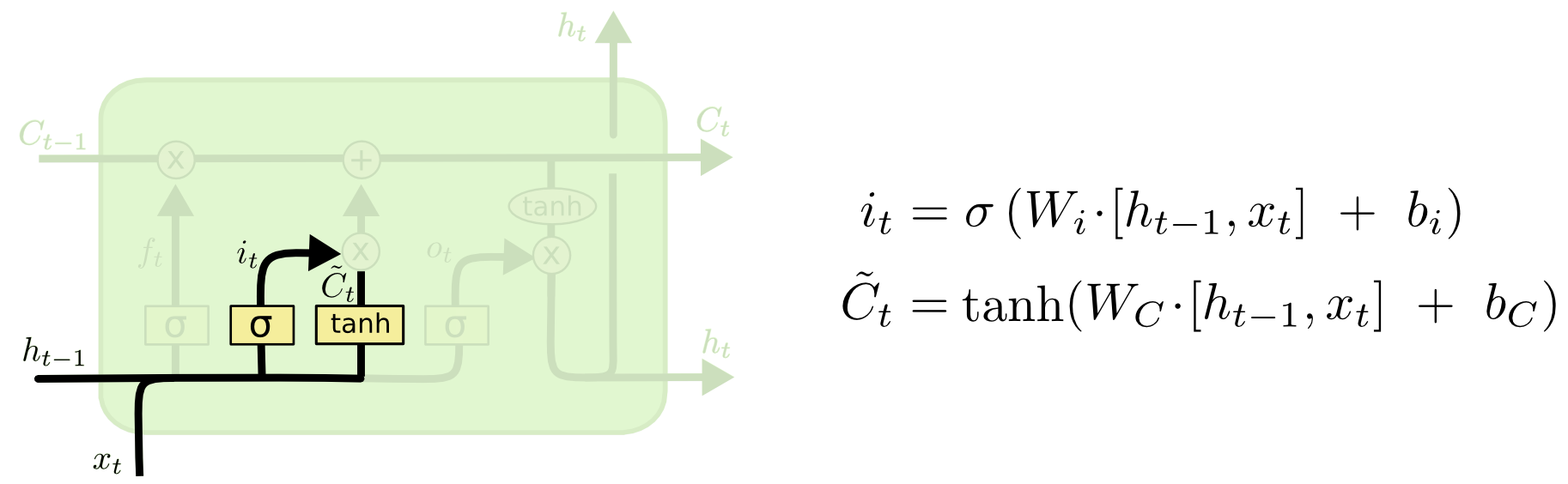
进门
接下来,我们计算i t ,它将确定我们要更新的存储单元的值,以及
计算更新的候选值。
记忆单元
接下来,内存值是我们在当前状态中忘记的内容和我们添加的内容的叠加

模型输出
什么是模型推断-结合三件事:当前输入符号,先前的预测和模型内存

代号
通常,该模型的基本逻辑如下所示-大约占整个代码的5-10%,其余代码用于清洗,准备和处理数据以及以人类可读的形式输出。
在这里,您可以使用已经训练好的模型来运行代码。
model = Sequential()
创建的标题示例
个人抽样:
python powershell
(对Strangelove博士的随机模型引用特别令人高兴)
什么是温度(在DL中)
在输出中,模型生成单词w的权重x w-我们可以选择如何将这些权重转换为概率p(w),例如,使用以下公式:
其中T是一个自由参数(在物理上,这是通过统计学方法确定温度的方法-因此得名),温度越低-指数越大,权重越高,“带走”所有概率,即,该模型将仅预测最大的几个单词重量,如果温度高,则分布将移动到均匀且更“创意”的位置。 这使我们有机会控制准确地跟踪可用数据与模型的条件创造力之间的平衡。
模型输出示例 using temperature 0.03 python sql azure federations 2 temperature 0.04 devcon 2013 temperature 0.05 python temperature 0.06 jbreak 2 10 19 temperature 0.07 temperature 0.08 php 10 temperature 0.09 unix oracle temperature 0.1 php temperature 0.11 android android studio github vue js php ruby temperature 0.12 asp net temperature 0.13 google glass using temperature 0.14 android temperature 0.15 python android sql azure federations 2 temperature 0.16 windows python using temperature 0.17 scala apache solr 1 c, 2 3 temperature 0.18 python cpatext content security policy temperature 0.190 52 28 27 nes c 1 3 scanner temperature 0.2 google chrome ms ie
结论
- LSTM体系结构对序列进行了清晰清晰的建模
- 语法和逻辑经常遭受-最有可能在两个地方出现问题:首先,存储设备非常简单,无法捕获所有规则和上下文。 其次,案例的力量-数据集非常小,而且不太多样化
- 看看“ 更好的语言模型”的版本及其在大型俄语案例中的含义会很有趣-了解体系结构和功能更强大的案例是否可以解决这些问题
- 一些头条新闻出人意料的荒谬和自嘲,例如,“……以及为什么对此负责”
- 我们在哈伯语的标题中看到了某些模式,例如“我们做了\创建了\建造了”,这清楚地表明人们喜欢在哈伯语上分享个人故事