第一部分
第三部分
从数据转移到结果而无需离开计算机

斯洛文尼亚一个小区域的图像堆栈,以及使用本文中介绍的方法获得的带有分类土地覆盖的地图。
前言
有关使用eo-learn库进行土地覆盖分类的系列文章的第二部分。 我们提醒您,第一篇文章演示了以下内容:
- 将AOI(感兴趣的区域)划分为称为EOPatch的片段
- 从Sentinel-2卫星接收图像和云遮罩
- 计算其他信息,例如NDWI , NDVI
- 创建参考遮罩并将其添加到源数据
此外,我们对数据进行了表面研究,这是开始深入研究机器学习之前极其重要的一步。 以上任务得到了Jupyter Notebook形式的示例的补充, 该示例现在包含本文的材料。
在本文中,我们将完成数据的准备工作,还将构建第一个模型,用于在2017年构建斯洛文尼亚的土地覆盖图。
资料准备
与完整程序相比,与机器学习直接相关的代码量很小。 这项工作的主要任务是清除数据,以确保与分类器无缝使用的方式处理数据。 这部分工作将在下面描述。

机器学习管道图显示,使用ML的代码本身仅占整个过程的一小部分。 来源
云图像过滤
云是通常以超过我们的平均EOPatch(1000x1000像素,分辨率10m)的比例出现的实体。 这意味着在任意日期,任何区域都可能被云完全覆盖。 这样的图像不包含有用的信息,仅消耗资源,因此我们根据有效像素与总数之比跳过它们并设置阈值。 我们可以将所有未归类为云且位于卫星图像内的像素称为有效像素。 还要注意,我们不使用Sentinel-2图像随附的蒙版,因为它们是按完整图像级别计算的(完整S2图像的大小为10980×10980像素,大约110×110 km),这意味着在大多数情况下,我们的AOI不需要使用这些蒙版。 为了确定云,我们将使用s2cloudless包中的算法来获取云像素的蒙版。
在我们的笔记本中,阈值设置为0.8,因此我们只选择填充了正常数据80%的图片。 这听起来似乎是很高的价值,但是由于云对我们的AOI来说并不是太大的问题,因此我们可以负担得起。 值得考虑的是,这种方法不能无所顾忌地应用于地球上的任何一点,因为您选择的区域在一年中的大部分时间都可能被云层覆盖。
时间插值
由于在某些日期可能会跳过图像,以及由于AOI采集日期不一致,因此数据缺乏是地球观测领域中非常普遍的现象。 解决此问题的一种方法是强加像素有效性的掩码(来自上一步),然后将值插值为“填充孔”。 作为插值过程的结果,可以计算丢失的像素值以创建一个EOPatch,其中包含均匀分布的日子的快照。 在此示例中,我们使用了线性插值,但是还有其他方法,其中一些方法已经在eo-learn中实现。

左侧是一堆来自随机选择的AOI的Sentinel-2图像。 透明像素表示由于云而丢失数据。 右图显示了插值后的堆栈,其中考虑了云掩码。
时间信息在覆盖物的分类中非常重要,在识别发芽文化的任务中甚至更重要。 这完全是由于以下事实:在整个年度中,地块的变化都隐藏着大量的土地覆盖信息。 例如,当查看插值的NDVI值时,您可以看到森林和田地中的值在春季/夏季达到最大值,并在秋季/冬季急剧下降,而水和人造表面在全年中使这些值保持大致恒定。 与水相比,人造表面的NDVI值略高,并且部分重复了森林和田野的发展,因为在城市中经常可以找到公园和其他植被。 您还应该考虑与图像分辨率相关的限制-通常在一个像素覆盖的区域中,您可以同时观察几种类型的覆盖率。
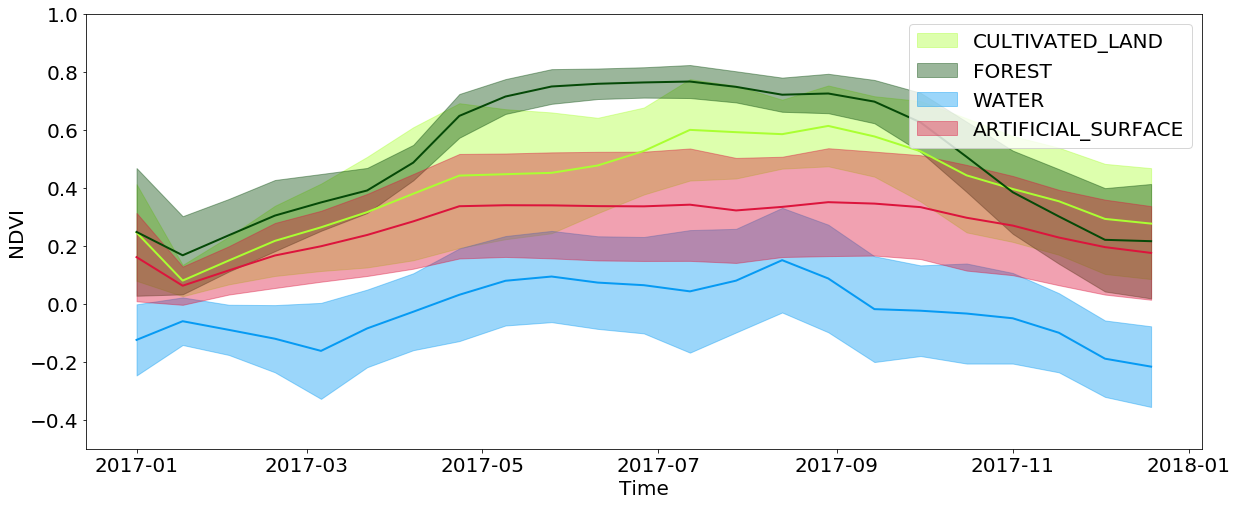
全年特定类型土地覆盖的像素NDVI值的时间变化
负缓冲
尽管10m的图像分辨率足以完成非常广泛的任务,但是小物体的副作用却非常明显。 此类对象位于不同类型的封面之间的边界上,并且仅为这些像素分配了其中一种类型的值。 因此,在训练分类器时,输入数据中会存在过多的噪声,这会使结果恶化。 此外,原始地图上还存在宽度为1像素的道路和其他对象,尽管它们很难从图像中识别出来。 我们将1像素负缓冲应用于参考图,从输入中删除几乎所有问题区域。
负缓冲之前(左)和之后(右)的AOI参考图
随机数据选择
如前一篇文章所述,完整的AOI分为大约300个片段,每个片段由〜1百万个像素组成。 这些相同的像素可观的数量,因此我们为每个EOPatch平均获取40,000像素,以获得1200万份的数据集。 由于像素是均匀拍摄的,因此在参考图上的像素数量并不重要,因为该数据是未知的(或在上一步之后丢失了)。 过滤掉这些数据以简化分类器的训练是很有意义的,因为我们不需要教它定义“无数据”标签。 对测试集重复相同的过程,因为此类数据会人为地降低分类器预测的质量指标。
我们在EOPatch级别分别将输入数据按80/20%的比率分为训练/测试集,这保证了我们这些输入集不相交。 我们还以相同的方式将训练像素集中的像素分为测试集和交叉验证集。 分离后,我们得到一个尺寸为(p,t,w,h,d)的numpy.ndarray数组,其中:
p是数据集中的EOPatch数
t每个EOPatch的插值图像数
* w, h, d分别为图片中的宽度,高度和层数。
选择子集后,宽度w对应于选定像素的数量(例如40,000),而尺寸h为1。阵列形状的差异不会改变任何东西,此过程仅是简化图像处理所必需的。
来自任何图像t中的传感器和遮罩d的数据确定用于训练的输入数据,其中此类情况的总和为p*w*h 。 为了将数据转换为可用于分类器的形式,我们必须将数组的维数从5减小为形式的矩阵(p*w*h, d*t) 。 使用以下代码很容易做到:
import numpy as np p, t, w, h, d = features_array.shape
这样的过程将使得可以对相同形式的新数据进行预测,然后将其转换回并以标准方式将其可视化。
创建机器学习模型
分类器的最佳选择在很大程度上取决于特定的任务,即使选择正确,我们也不应忘记特定模型的参数,该参数必须随任务而变化。 通常需要使用不同的参数集进行许多实验,以便准确地说出特定情况下的需求。
在本系列文章中,我们使用LightGBM软件包,因为它是用于基于决策树构建模型的直观,快速,分布式且高效的框架。 要选择分类器超参数,可以使用不同的方法,例如网格搜索 ,应在测试集上进行测试。 为简单起见,我们将跳过此步骤并使用默认参数。
LightGBM中的决策树工作方案。 来源
该模型的实现非常简单,并且由于数据已经以矩阵的形式出现,因此我们只需将该数据输入模型的输入并等待。 恭喜你! 现在,您可以告诉每个人您正在从事机器学习,并且将成为聚会上最时髦的人,而您的母亲会对机器人的叛逆和人类的死亡感到不安。
模型验证
在机器学习中训练模型很容易。 困难在于训练他们。 为此,我们需要合适的算法,可靠的参考卡和足够的计算资源。 但是即使在这种情况下,结果也可能不是您想要的,因此,对于至少对工作结果有一定信心的情况,绝对必须使用错误矩阵和其他度量来检查分类器。
误差矩阵
评估分类器质量时,首先要考虑错误矩阵。 它们显示参考卡中每个标签正确和错误预测的标签数量,反之亦然。 通常,使用归一化矩阵,其中行中的所有值均除以总量。 这表明分类器相对于另一种类型的覆盖物是否没有偏见
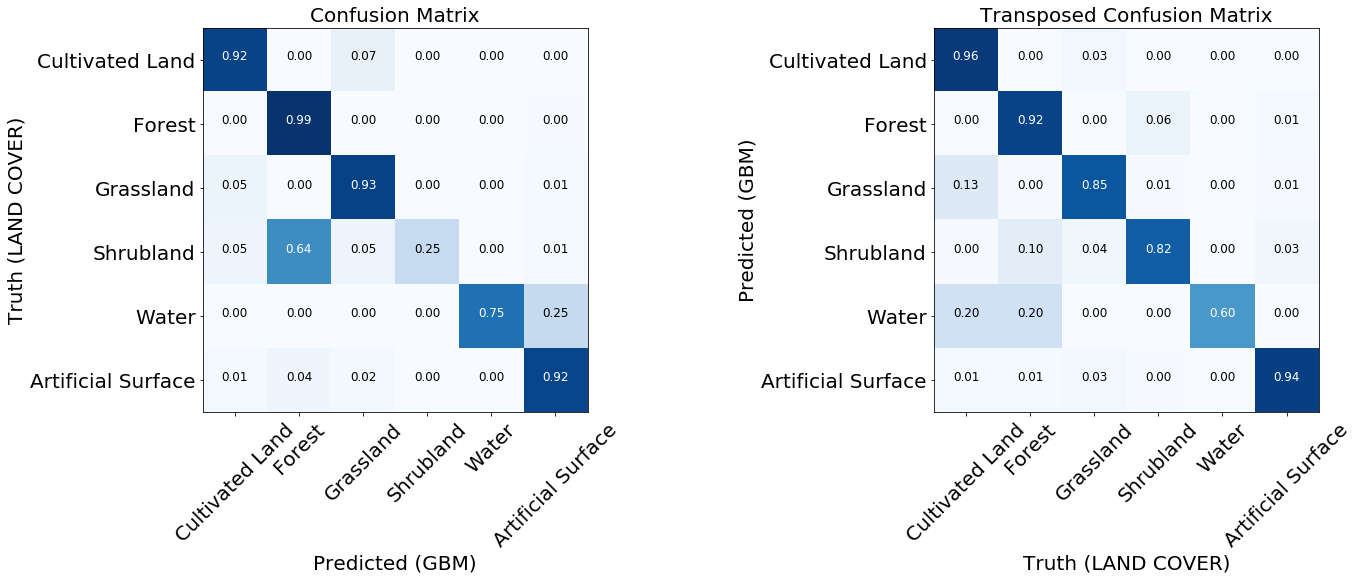
训练模型的两个归一化误差矩阵。
对于大多数课程,该模型显示出良好的结果。 对于某些类别,由于输入数据的不平衡而发生错误。 我们看到问题出在例如灌木丛和水,模型经常为此混淆像素标签并错误地识别它们。 另一方面,标记为灌木或水的东西与参考图很好地相关。 从下图可以看出,训练实例数量少的类会出现问题-这主要是由于示例中的数据量少,但是在任何实际任务中都可能发生此问题。
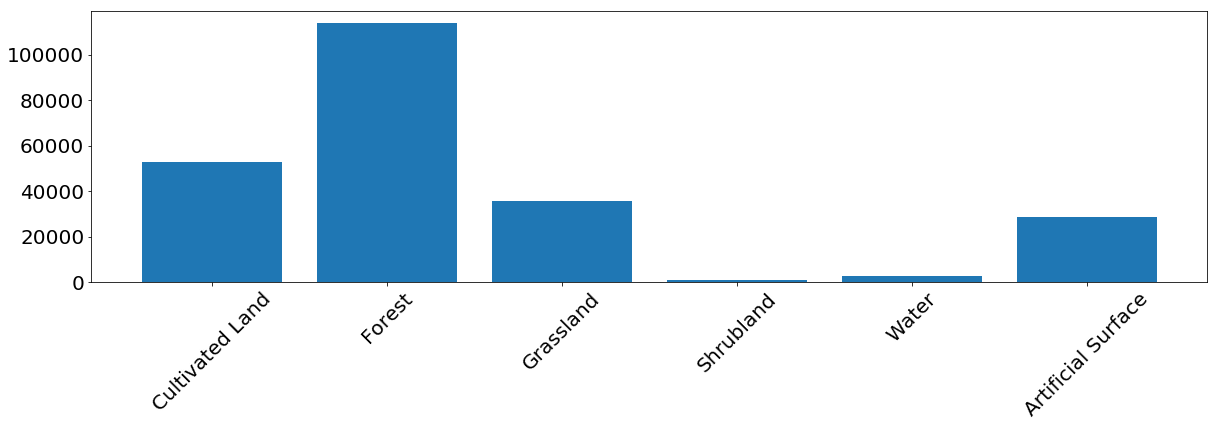
训练集中每个类别的像素出现的频率。
接收器工作特性-ROC曲线
分类器可以确定地预测标签,但是可以更改特定标签的阈值。 ROC曲线显示了更改灵敏度阈值时分类器做出正确预测的能力。 通常,该图用于二进制系统,但是如果我们为每个类计算特征“针对所有其他的标签”,则可以在我们的情况下使用该图。 x轴显示在不同阈值处的假阳性结果(我们需要减少其数量),y轴显示假阳性结果(我们需要增加其数量)。 好的分类器可以用曲线面积最大的曲线来描述。 该指标也称为曲线下面积AUC。 从ROC曲线图可以得出关于“灌木”类示例数量不足的相同结论,尽管水的曲线看起来要好得多-这是由于以下事实:即使数据中的示例数量不足,水在视觉上也与其他类别有很大不同。

分类器的ROC曲线,每个类别的形式为“一对一反对”。 括号中的数字是AUC值。
症状的重要性
如果您想更深入地研究分类器的复杂性,可以查看特征重要性图,它告诉我们哪些符号对最终结果的影响更大。 一些机器学习算法(例如我们在本文中使用的算法)返回这些值。 对于其他模型,此指标必须由我们自己考虑。

示例中分类器的特征重要性矩阵
尽管通常春季其他标志(NDVI)更为重要,但我们可以看到确切的日期是其中一个标志(B2-蓝色)最重要。 如果您查看这些图片,结果发现在此期间的AOI被雪覆盖了。 可以得出结论,积雪揭示了有关下层覆盖物的信息,这极大地帮助了分类器确定表面的类型。 值得记住的是,这种现象是所观察到的AOI所特有的,并且通常不能依靠它。

积雪的3x3 EOPatch AOI零件
预测结果
验证之后,我们会更好地了解我们模型的优缺点。 如果我们对当前的状态不满意,可以对管道进行更改,然后重试。 优化模型后,我们定义一个简单的EOTask,它接受EOPatch和分类器模型,进行预测并将其应用于片段。
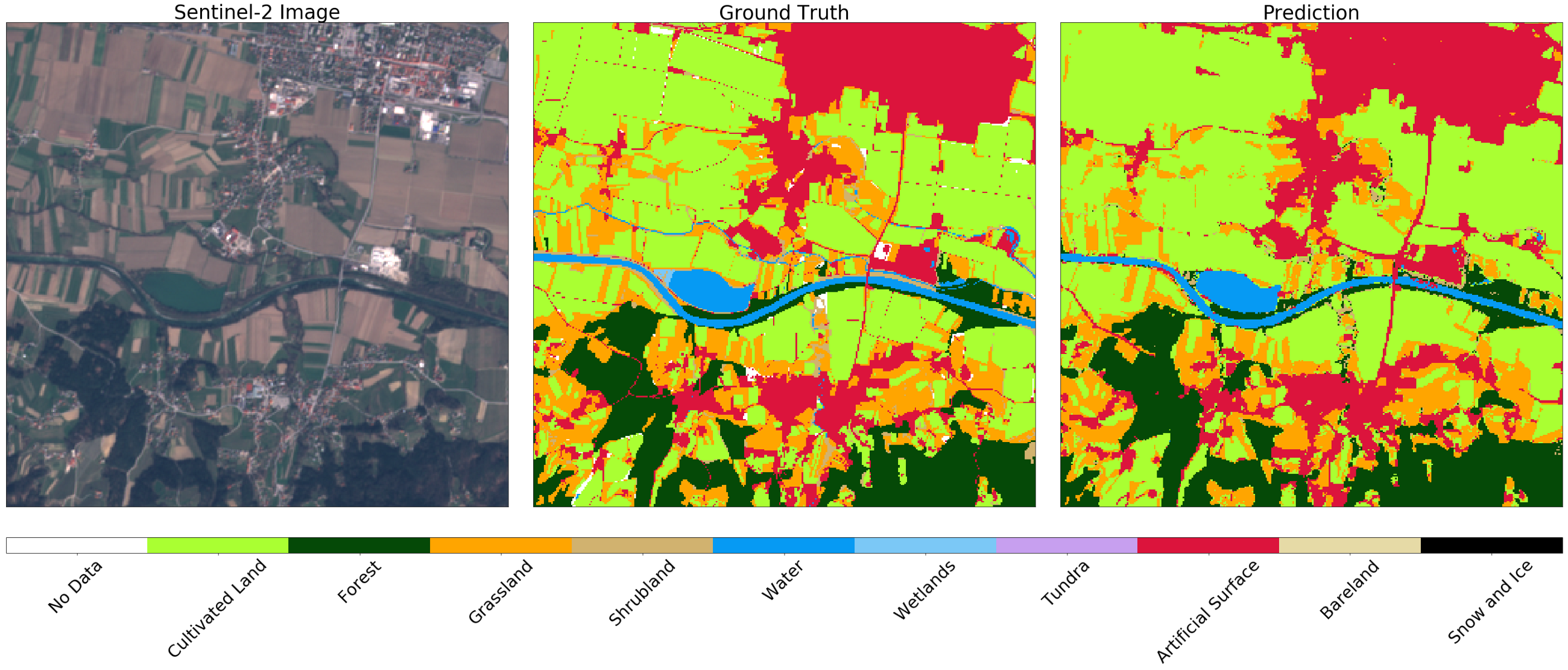
来自AOI的随机片段的Sentinel-2(左),真值(中心)和预测(右)图像。 您可能会注意到图像中的一些差异,这可以通过在原始地图上使用负缓冲来解释。 通常,该示例的结果令人满意。
进一步的道路是明确的。 必须对所有片段重复该过程。 您甚至可以将它们导出为GeoTIFF格式,并使用gdal_merge.py粘贴它们。
我们将粘合的GeoTIFF上传到我们的GeoPedia门户,您可以在此处查看详细信息
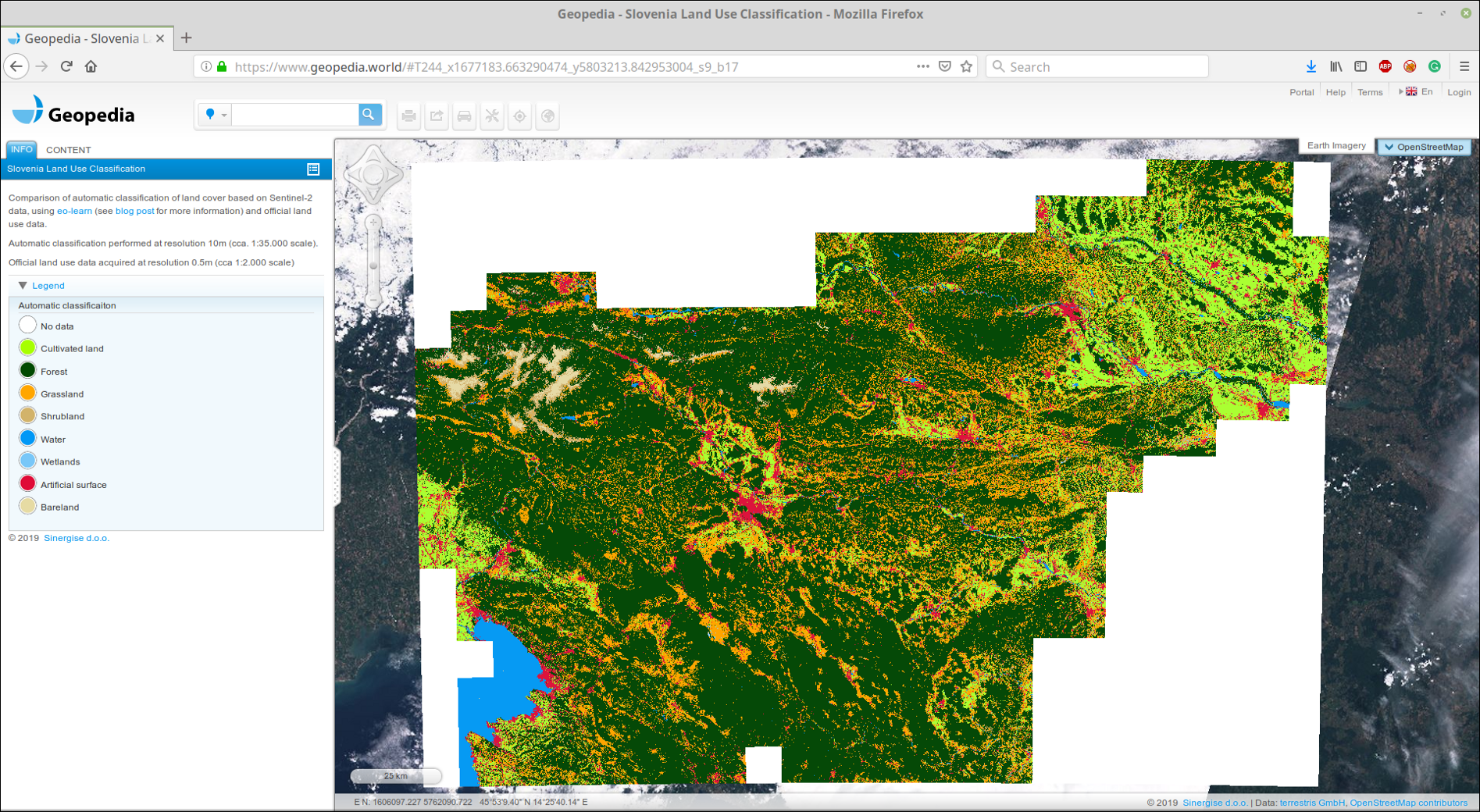
使用本文的方法,对2017年斯洛文尼亚的土地覆盖预测的屏幕截图。 在上面的链接中以互动格式提供
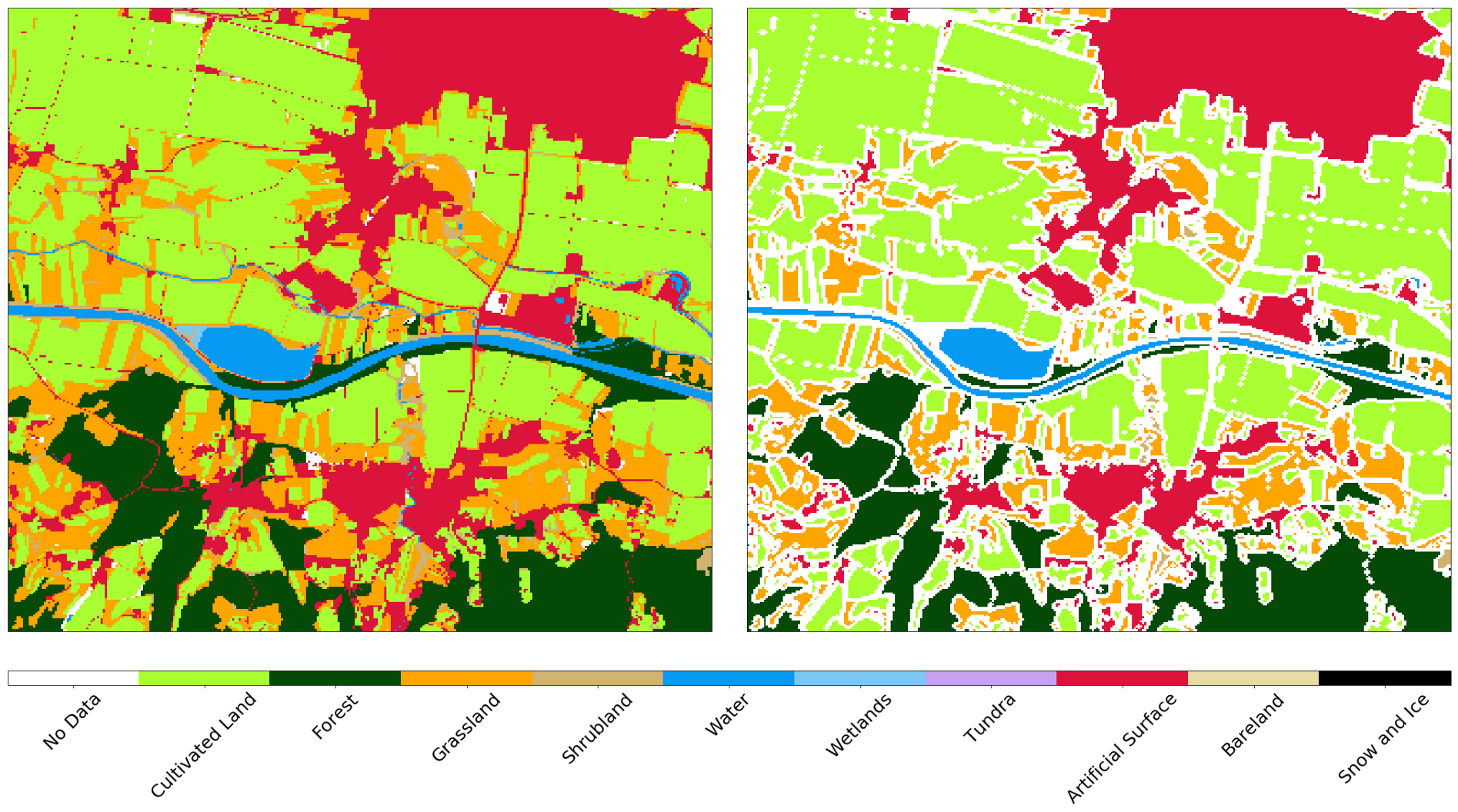
您还可以将官方数据与分类结果进行比较。 注意土地使用和土地覆盖的概念之间的区别,这通常在机器学习任务中发现-将数据从官方注册簿映射到自然界中的类并非总是容易的。 例如,我们显示了斯洛文尼亚的两个机场。 第一个是Levets,在Celje镇附近 。 这个机场很小,主要用于私人飞机,草皮覆盖。 正式地,该区域被标记为人造表面,尽管分类器能够正确地将该区域识别为草皮,请参见下文。

小型体育机场周围区域的Sentinel-2(左),真实(中)和预测(右)图像。 分类器将跑道定义为草地,尽管在当前数据中跑道被标记为人造表面。
另一方面, 在斯洛文尼亚卢布尔雅那最大的机场中,地图上标记为人工表面的区域是道路。 在这种情况下,分类器可以在结构之间进行区分,同时可以正确区分相邻区域中的草地和田野。
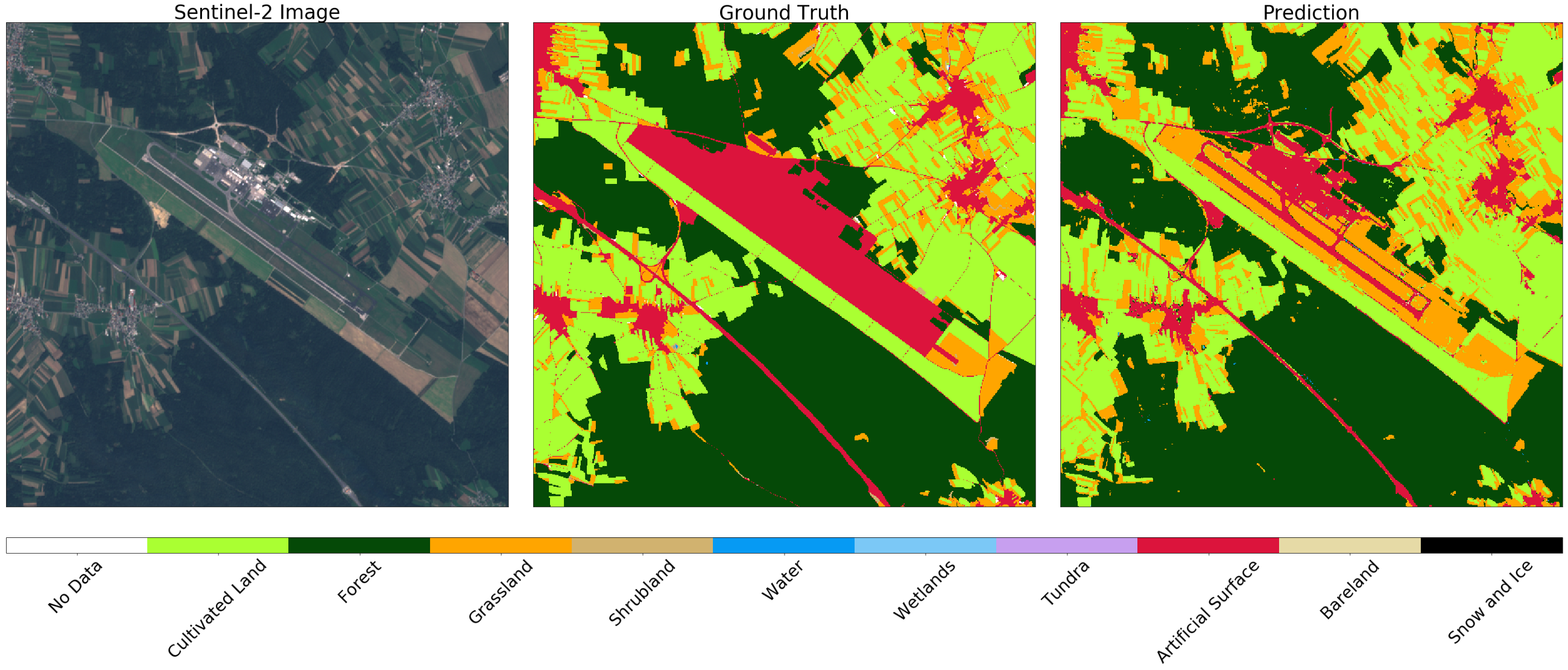
卢布尔雅那周边地区的Sentinel-2(左),真相(中)和预测(右)图像。 分类器确定跑道和道路,同时正确区分附近的草地和田野
瞧!
现在您知道了如何在全国范围内创建可靠的模型! 请记住将其添加到您的简历中。