对人进行生物特征识别是识别人的最古老的想法之一,他们通常试图在技术上实现这一点。 密码可能被盗,被监视,被遗忘,密钥可能被伪造。 但是,人本人的独特特征很难伪造和失去。 这可以是指纹,声音,视网膜血管的绘制,步态等等。

当然,生物识别系统正试图愚弄! 这就是我们今天要谈论的。 攻击者如何通过假冒他人来尝试绕过面部识别系统,以及如何检测到该问题。
您可以在此处观看此故事的视频版本,喜欢阅读而不是观看的人,我邀请您继续
根据好莱坞导演和科幻小说家的想法,欺骗生物特征识别非常容易。 只需单独或以其为人质,将真实用户的“所需部分”呈现给系统。 或者,您也可以“戴上面具”,例如,使用物理移植面具或通常显示出虚假遗传迹象的 面具
在现实生活中,攻击者还试图将自己介绍给其他人。 例如,如下图所示,戴着黑人面具抢劫银行。

人脸识别在移动领域似乎是一个非常有前途的领域。 如果每个人长期以来都习惯使用指纹,并且语音技术正在逐步且相当可预测地发展,那么通过直面识别情况,情况已经变得相当不寻常,值得对这个问题的历史稍作讨论。
这一切是如何开始的,或者是从小说到现实的
当今的识别系统展现出了极高的准确性。 随着大数据集和复杂体系结构的出现,可以实现高达0.000001(百万分之一的误差)的人脸识别精度,并且它们现在适合传输到移动平台。 瓶颈是他们的脆弱性。
为了在我们的技术现实世界中而不是在电影中模仿他人,最常使用口罩。 他们还试图通过摆弄别人而不是他们的面孔来愚弄计算机系统。 口罩的质量可能完全不同,从打印在打印机正面的人的照片打印到非常复杂的带有加热的三维口罩。 口罩可以片状或屏幕状分开显示,也可以戴在头上。
通过成功尝试欺骗iPhone X上的Face ID系统而获得了极大的关注,该系统采用相当复杂的石粉蒙版,在眼睛周围带有特殊的插入物,利用红外辐射模仿了活着的脸部的温暖感。
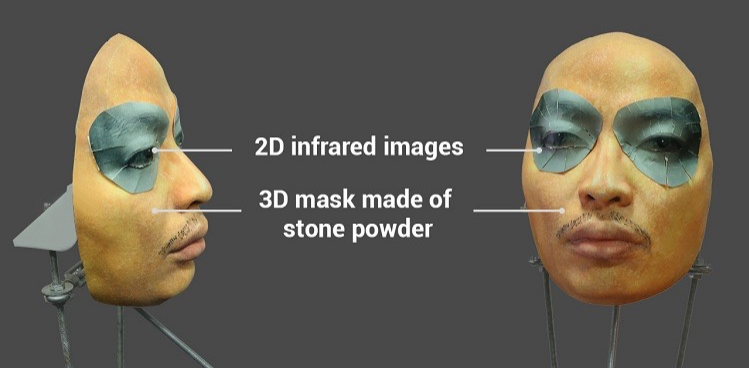
据称,使用这种口罩可以欺骗iPhone X上的人脸ID。可以在此处找到视频和一些文本
这种漏洞的存在对于银行或国家系统面对面认证用户非常危险,因为攻击者的渗透会带来重大损失。
术语学
面部防欺骗的研究领域是一个非常新的领域,即使是流行的术语也无法自夸。
让我们同意通过向其提供伪造的生物特征参数(在这种情况下为人) 欺骗攻击来进行欺骗,以欺骗识别系统。
因此,一套针对这种欺骗的保护措施将被称为反欺骗 。 可以采用多种技术和算法的形式来实现它,这些技术和算法内置在识别系统的传送带中。
ISO提供了一组稍微扩展的术语,包括表示攻击之类的术语-试图迫使系统错误地标识用户,或者通过演示图片,录制的视频等使用户避免标识。 正常(善意) -对应于系统的常用算法,即不是攻击的所有内容。 演示攻击工具是指一种攻击手段,例如,人为制造的身体一部分。 最后, Presentation攻击检测 -检测此类攻击的自动化方法。 但是,标准本身仍在开发中,因此无法谈论任何已建立的概念。 俄语中的术语几乎完全没有。
为了确定工作质量,系统通常使用HTER度量标准(半总错误率-总错误的一半),该度量标准是错误允许的识别系数(FAR-错误接受率)和错误禁止的识别系数(FRR-错误拒绝率)之和。一半。
HTER =(远+ FRR)/ 2
值得一提的是,在生物识别系统中,通常会给予FAR最多的关注,以尽一切可能阻止攻击者进入系统。 而且,他们在此方面取得了良好的进展(还记得从本文开始的一百万分之一吗?)另一方面,FRR不可避免地会增加-错误地将普通用户数量分类为恶意用户。 如果可以为国家,国防和其他类似系统而牺牲这一点,那么以其巨大规模,各种订户设备以及通常以用户角度为导向的设备工作的移动技术对任何可能导致用户拒绝服务的因素都非常敏感。 如果您想减少连续第十次拒绝身份验证后撞墙的电话数量,请注意FRR!
攻击类型。 欺诈系统

最后,让我们确切地了解攻击者如何欺骗识别系统,以及如何对付它。
最流行的作弊手段是口罩。 没有什么比戴上别人的面具并向识别系统展示您的脸(通常称为面具攻击)更明显的了。
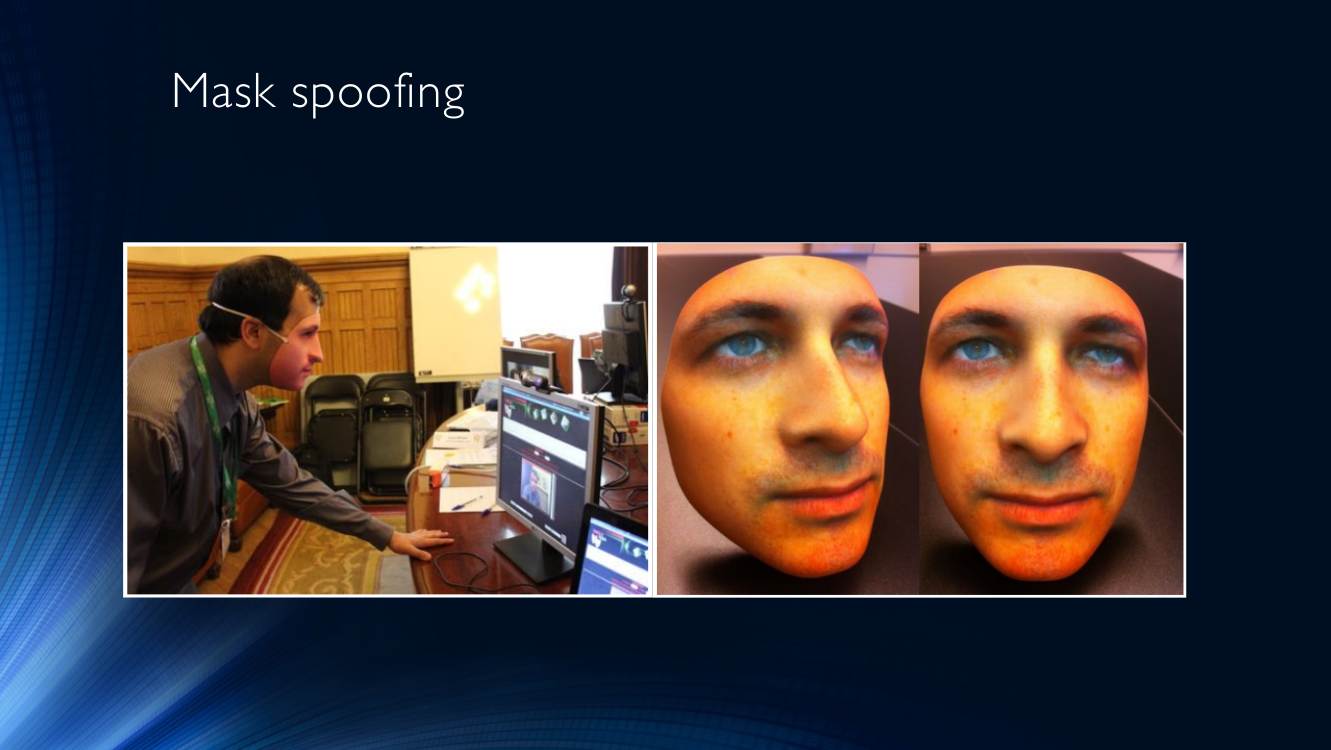
您还可以在一张纸上打印自己或其他人的照片,然后将其带到相机上(我们称这种类型的攻击为“打印过的攻击”)。

当系统出现在另一台设备的屏幕上,在该设备上播放之前与其他人录制的视频时,重放攻击会更加复杂。 由于控制系统经常使用基于时间序列分析的信号,例如跟踪眨眼,头部微动,面部表情,呼吸等,因此执行这种复杂的攻击可以补偿执行的复杂性。 所有这些都可以很容易地在视频上再现。

两种类型的攻击都具有许多特征,可以对其进行检测,从而将平板电脑屏幕或一张纸与真实的人区分开。
我们总结了一些特征,这些特征使我们可以在表中识别这两种类型的攻击:
攻击检测算法。 好老经典

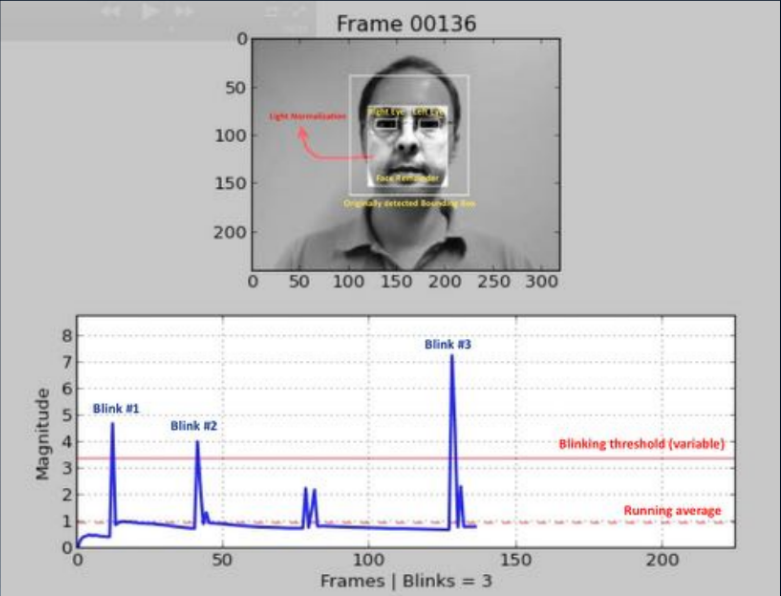
一种最古老的方法(2007年,2008年)是基于通过使用蒙版分析图像来检测人眨眼的方法。 关键是要构建某种二进制分类器,该分类器使您可以选择在一系列帧中睁着眼睛和闭着眼睛的图像。 这可以是使用面部识别(地标检测)或使用一些简单的神经网络对视频流进行分析。 今天,这种方法最常用。 系统会提示用户执行一系列操作:转头,眨眨眼,微笑等等。 如果序列是随机的,那么攻击者就很难预先为其准备。 不幸的是,对于一个诚实的用户,此任务也不总是可以克服的,参与度急剧下降。
您也可以在打印或在屏幕上播放时使用降低图像质量的功能。 最有可能在图像中甚至检测到一些局部模式,甚至是眼睛难以捉摸的模式。 例如,可以通过从帧( PDF )中选择脸部的不同区域来计算局部二进制模式(LBP,局部二进制模式)来完成此操作。 所描述的系统可以被认为是基于图像分析的面部反欺骗算法整个方向的奠基人。 简而言之,当计算LBP时,将依次获取图像中的每个像素,其八个相邻像素并比较它们的强度。 如果强度大于中心像素的强度,则分配一个,如果小于,则分配为零。 因此,对于每个像素,获得8位序列。 基于获得的序列,构造每个像素的直方图,该直方图被馈送到SVM分类器的输入。
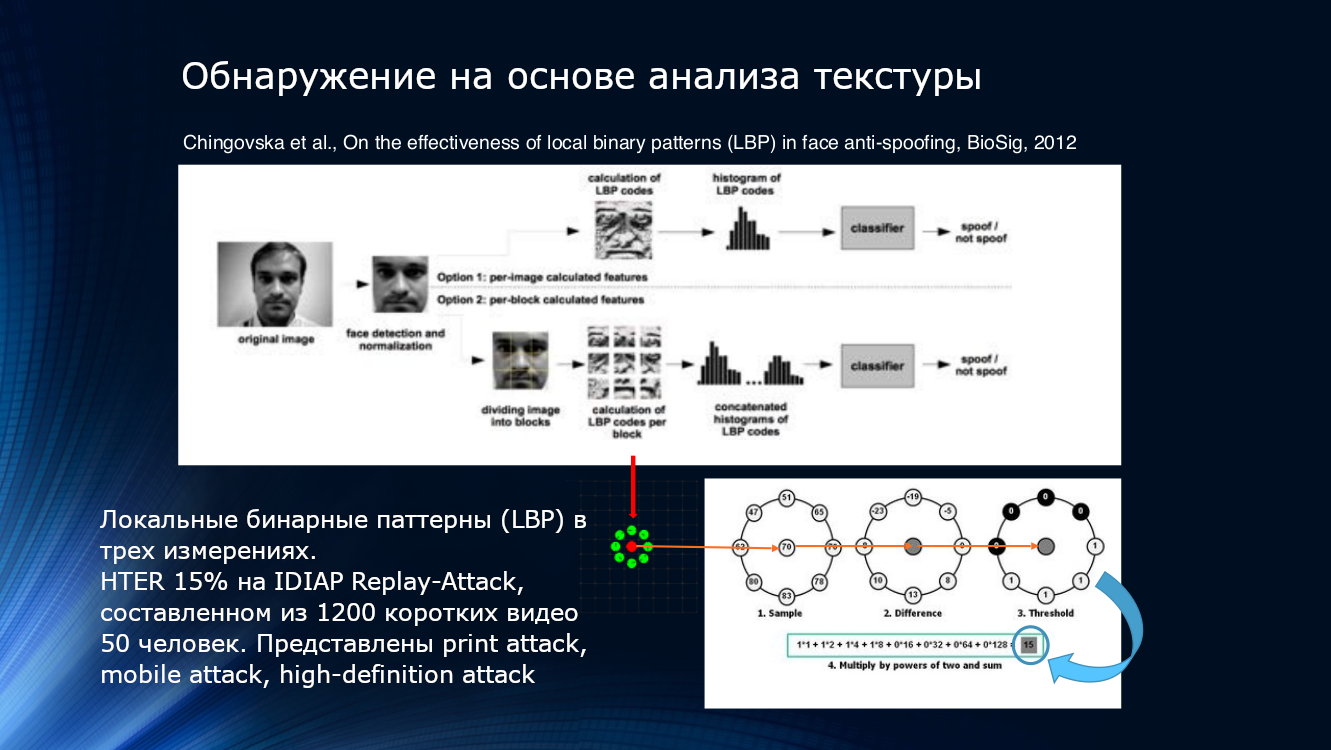
本地二进制模式,直方图和SVM。 您可以在这里加入永恒的经典
HTER效率指标“高达” 15%,这意味着相当一部分攻击者无需付出太多努力就能克服防御,尽管应该意识到,已经消除了很多东西。 该算法在IDIAP Replay-Attack数据集上进行了测试,该数据集由1200个包含50个受访者的短视频和三种类型的攻击组成:印刷攻击,移动攻击,高清攻击。
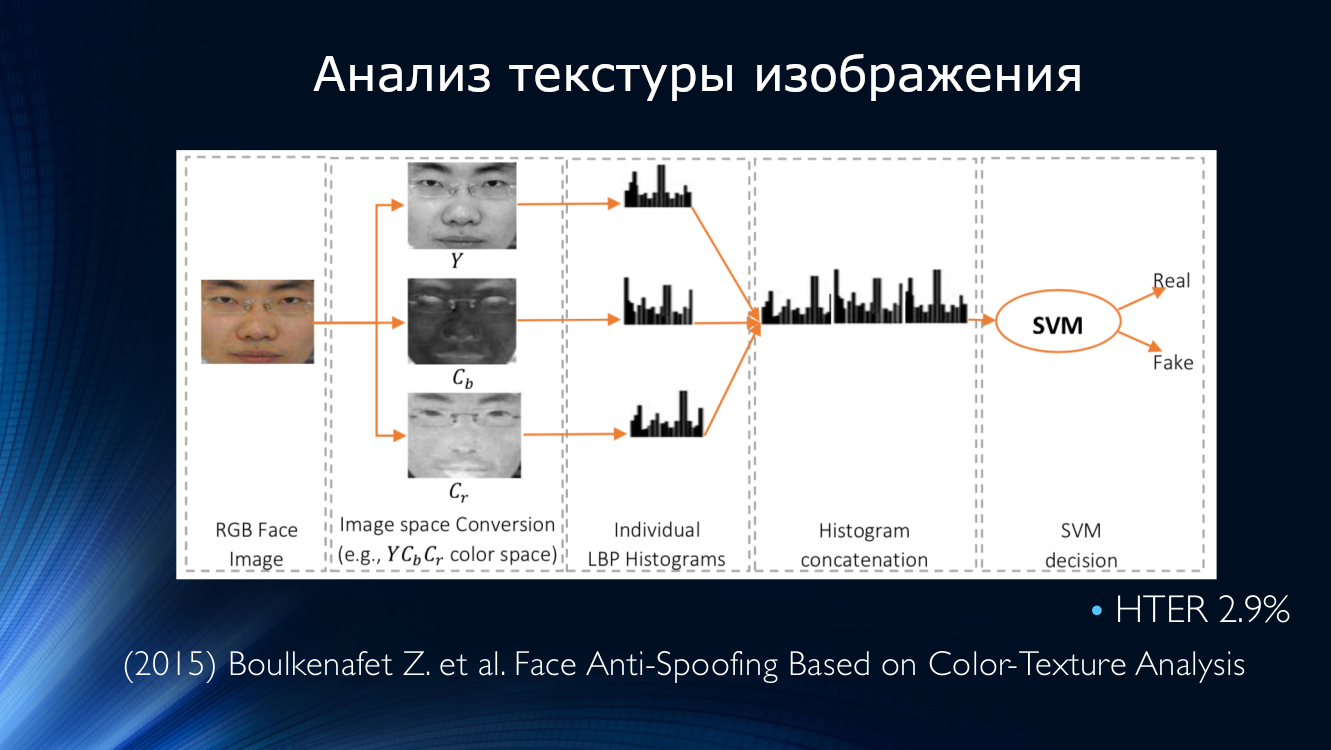
分析图像纹理的想法一直在继续。 在2015年,Bukinafit 开发了一种算法,除了传统的RGB之外,还可以将图像交替分成多个通道,其结果是再次计算出本地二进制模式,就像以前的方法一样,该模式被输入到SVN分类器的输入中。 当时,根据CASIA和Replay-Attack数据集计算出的HTER准确性令人印象深刻,达到3%。
同时,出现了探测云纹的工作。 帕特尔(Patel) 发表了一篇文章,他建议寻找由两次扫描重叠引起的周期性图案形式的图像伪像。 事实证明该方法是可行的,在IDIAP,CASIA和RAFS数据集上显示HTER约为6%。 这也是在不同数据集上比较算法性能的首次尝试。

重叠扫描导致的图像中的周期性图案
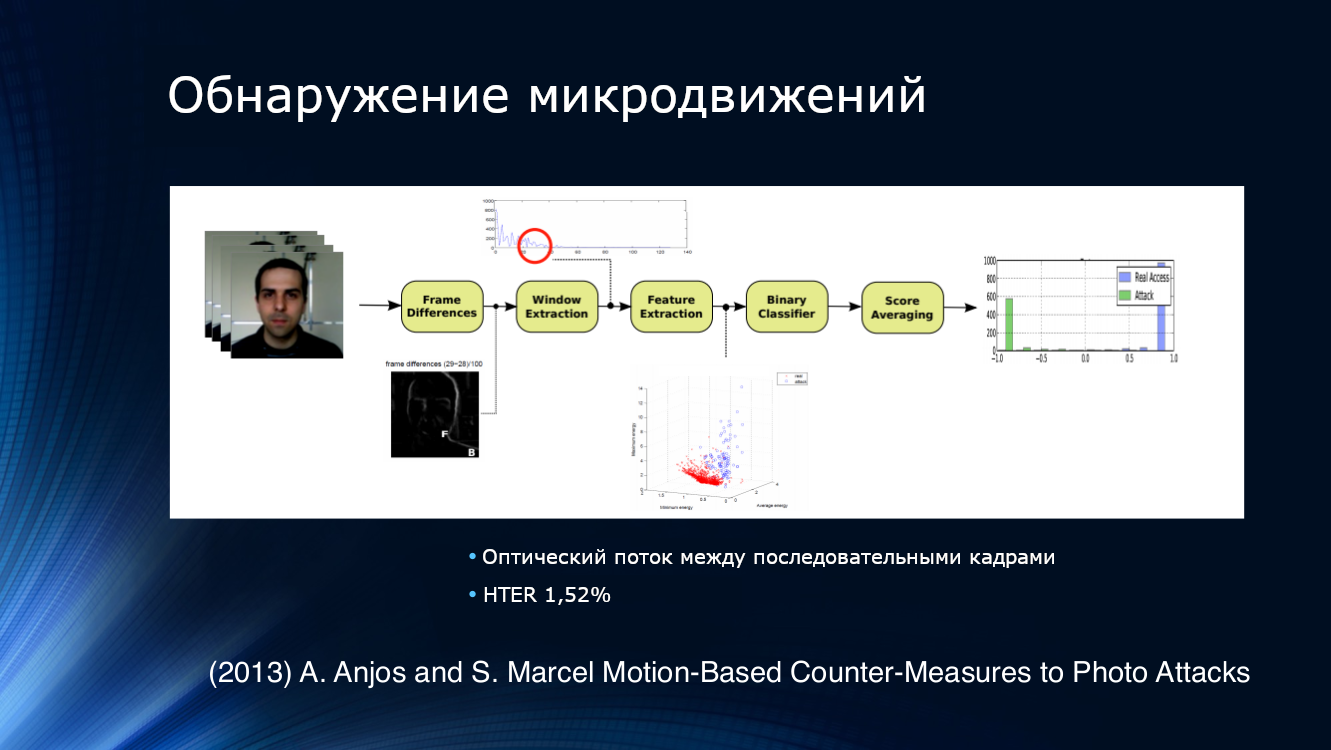
为了检测尝试呈现照片的尝试,逻辑解决方案是尝试分析一个图像,而不是分析从视频流中获取的图像序列。 例如,Anjos和同事建议从相邻帧对中的光流中分离特征,将二进制分类器输入到输入中,然后对结果求平均。 事实证明该方法非常有效,其自身数据集的HTER为1.52%。
一种有趣的跟踪运动的方法,与传统方法有些不同。 自2013年以来,“将原始图像应用于卷积网络的输入并调整网格层以获取结果”的原则在现代深度学习项目中并不常见,因此Bharadzha始终采用更复杂的初步转换。 特别是,他使用了麻省理工学院的科学家们众所周知的欧拉视频放大算法,该算法已成功地用于分析取决于脉冲的皮肤颜色变化。 我用HOOF(光流方向的直方图)替换了LBP,并正确地指出,由于我们要跟踪运动,因此需要适当的符号,而不仅仅是纹理分析。 当时传统的所有相同SVM都用作分类器。 该算法在Print Attack(0%)和Replay Attack(1.25%)数据集上显示了令人印象深刻的结果。

让我们已经学习了网格!

从某个角度来看,向深度学习的过渡已经很成熟了。 臭名昭著的“深度学习革命”取代了面部反欺骗技术。
“第一次吞咽”可视为分析图像各个部分(“斑块”)中深度图的方法。 显然,深度图对于确定图像所在的平面是一个很好的信号。 仅仅是因为纸张上的图像在定义上没有“深度”。 在2017年Ataum的工作中 ,从图像中提取了许多单独的小部分;为其计算了深度图,然后将其与主图像的深度图合并。 有人指出,十个随机的人脸图像补丁足以可靠地识别“印刷攻击”。 此外,作者将两个卷积神经网络的结果汇总在一起,第一个卷积神经网络计算了斑块的深度图,第二个卷积了整个图像。 在对数据集进行训练时,Printed Attack类与深度图为零,面部的三维模型以及一系列随机选择的部分相关联。 总的来说,深度图本身并不那么重要,仅使用了某个指标函数来表征“断面深度”。 该算法显示HTER值为3.78%。 训练使用了三个公共数据集-CASIA-MFSD,MSU-USSA和Replay-Attack。

不幸的是,大量用于深度学习的优秀框架的出现导致大量开发人员的出现,他们正试图以一种众所周知的组装神经网络的方式来“正面”解决面部反欺骗问题。 通常,它看起来像是在一些普遍的数据集上经过预训练的几个网络的输出上的特征图堆栈,这些数据集被馈送到二进制分类器。
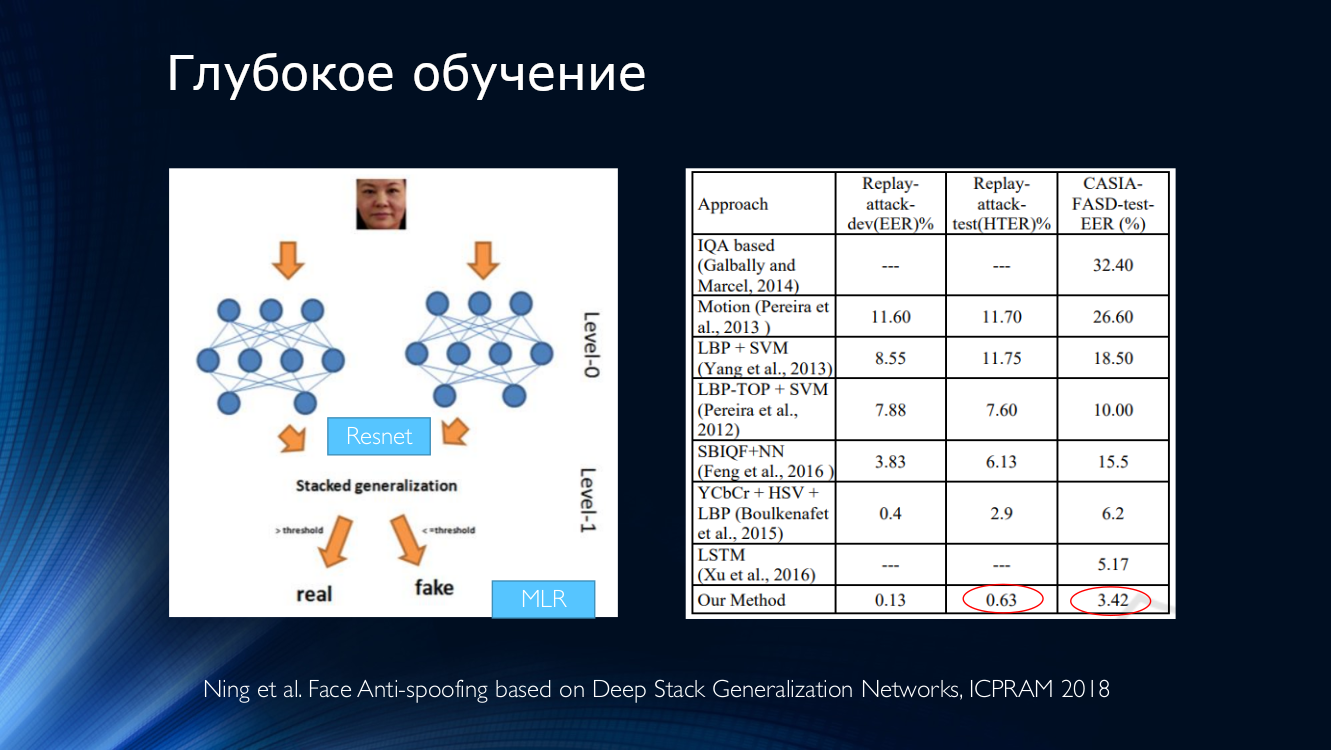
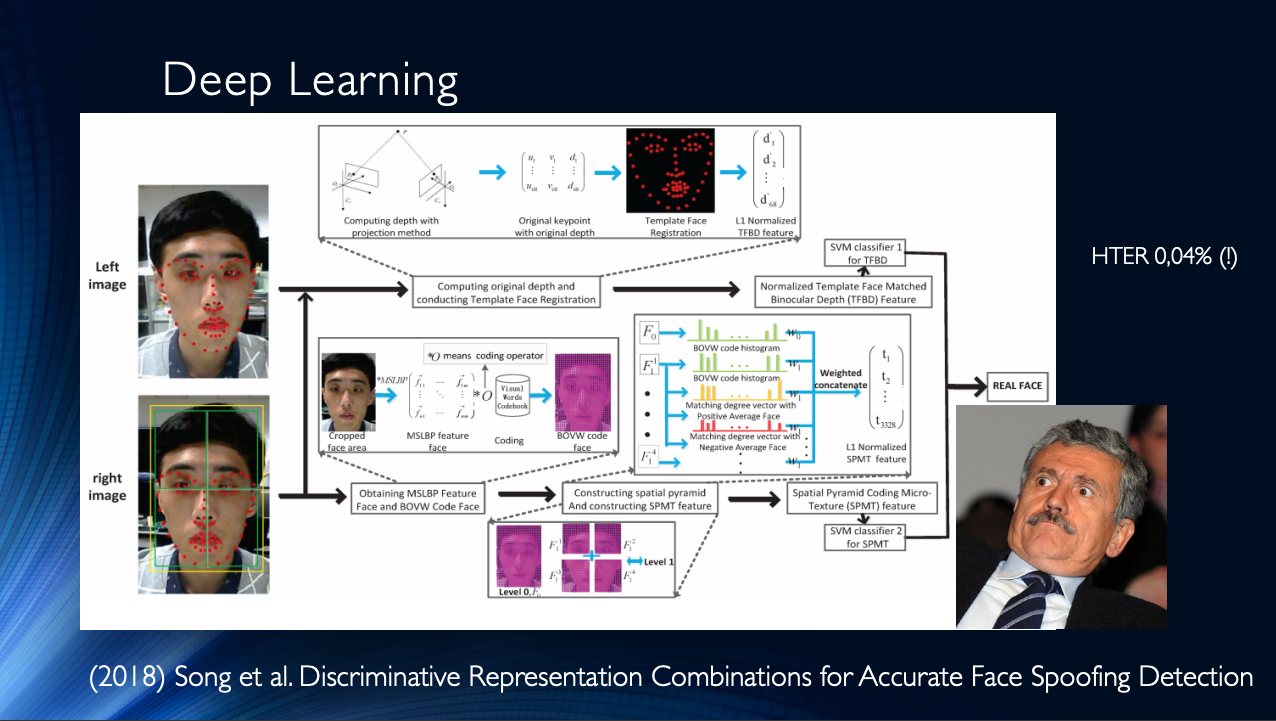
总的来说,值得总结的是,迄今为止,已经出版了许多作品,这些作品总体上显示出良好的效果,并且只结合了一个小的“但是”。 所有这些结果都显示在一个特定的数据集中! 数据集的可用性有限加剧了这种情况,例如,在臭名昭著的重放攻击中,HTER 0%也就不足为奇了。 所有这些都导致出现了非常复杂的架构,例如这些架构, 它们使用了各种巧妙的功能,在堆栈上组装的辅助算法,几个分类器,这些分类器的结果是平均的,依此类推...作者在输出中得到HTER = 0.04%!
这表明面部反欺骗问题已在特定数据集中解决。 让我们将各种基于神经网络的现代方法介绍到表中。 显而易见,“参考结果”是通过非常多样化的方法实现的,这些方法仅出现在开发人员的询问中。
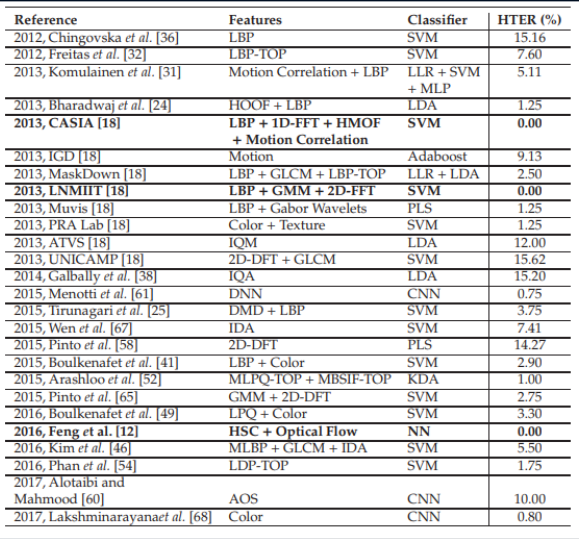
各种算法的比较结果。 桌子是从这里拿来的。
不幸的是,相同的“小”因素违反了为百分之一十分的努力而奋斗的良好画面。 如果您尝试在一个数据集上训练神经网络,然后在另一个数据集上应用它,结果将不会那么乐观。 更糟糕的是,在现实生活中应用分类器的尝试完全没有希望。
例如,我们取自 2015年的数据,其中使用其质量指标来确定所显示图像的真实性。 看一下自己:
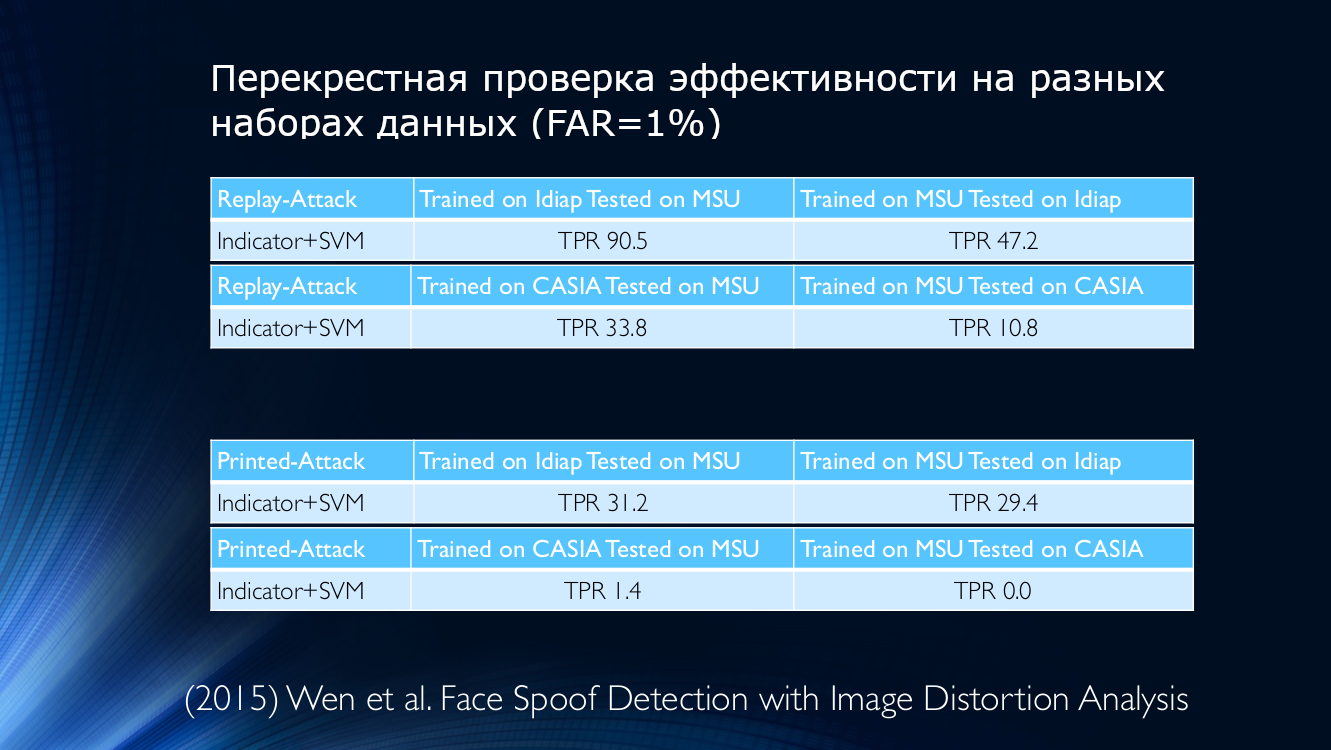
换句话说,使用Idiap数据训练但应用于MSU的算法将获得90.5%的真实阳性检测率,如果相反(对MSU进行训练并对Idiap进行测试),则只能正确确定47.2。 %(!)对于其他组合,情况甚至更糟,例如,如果在MSU上训练算法并在CASIA上对其进行检查,则TPR将为10.8%! 这意味着大量的诚实用户被错误地分配给攻击者,这不得不令人沮丧。 甚至跨数据库的培训也无法扭转这种局面,这似乎是一个完全合理的出路。
让我们看看更多。 Patel在2016年的文章中显示的结果表明,即使使用了足够复杂的处理管道以及选择了可靠的功能(例如闪烁和纹理),对不熟悉的数据集的结果也不能令人满意。 因此,在某些时候,很明显,所提出的方法远远不足以概括结果。
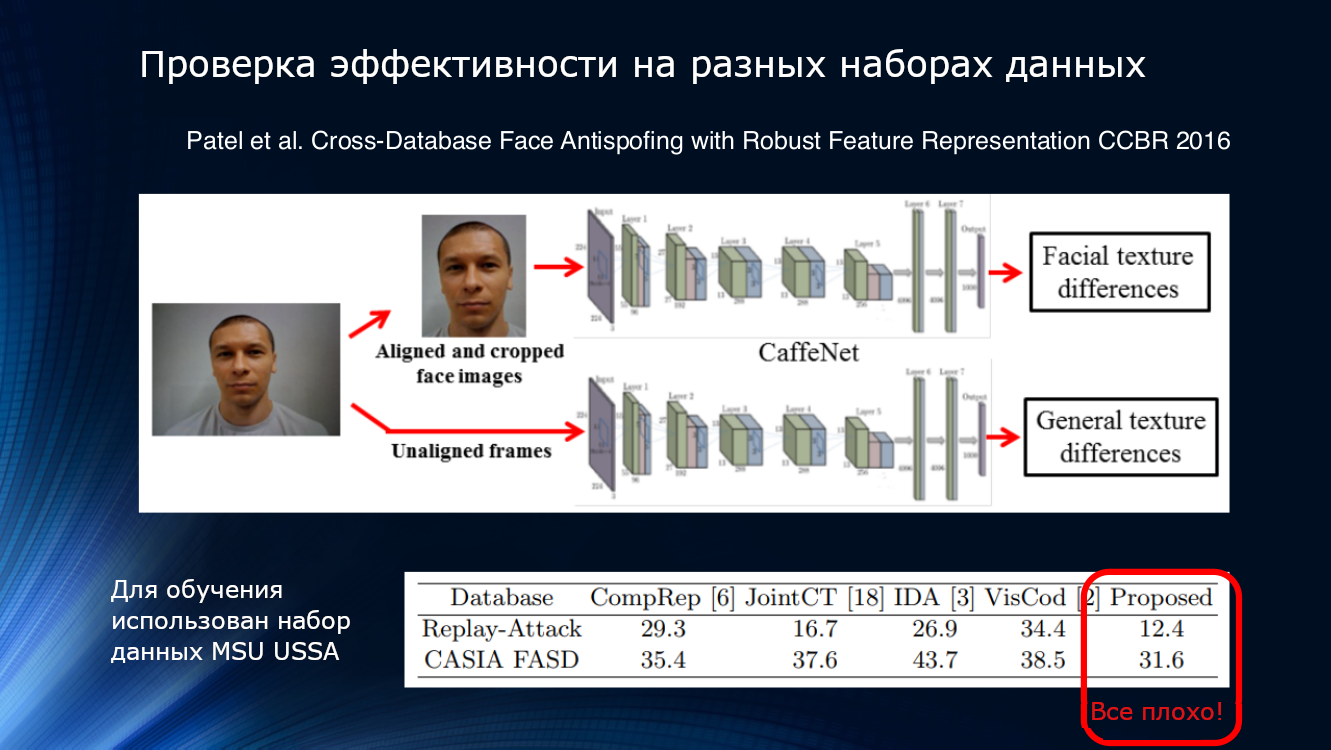
如果您安排比赛...
当然,在面部防护领域并非没有竞争。 2017年,在芬兰奥卢大学举行的竞赛中,竞赛采用了自己的新数据集,其中包含了非常有趣的协议,专门针对移动应用领域的使用。
-协议1:灯光和背景有所不同。 数据集记录在不同的位置,并且背景和光线不同。
-协议2:使用各种型号的打印机和屏幕进行攻击。 因此,在验证数据集中,使用了一种在训练集中找不到的技术
协议3:传感器的互换性。 真实的用户视频和攻击记录在五种不同的智能手机上,并用于训练数据集中。 , .
- 4: .
. , , , - . , , 10%. :
GRADIENT
- ( HSV YCbCr), .
- .
- HSV YCbCr, . ROI (region-of-interest) 160×160 ..
- ROI 3×3 5×5 , LBP , 6018.
- (Recursive Feature Elimination) 6018 1000.
- SVM .|
SZCVI
Recod
- SqueezeNet Imagenet
- Transfer learning : CASIA UVAD
- 224×224 pixels. , , , CNN.
- .
CPqD
- Inception-v3, ImageNet
- C
- , , 224×224 RGB |
, . LBP, , , .. GRADIANT , , , . .
. , . -, ( 15 NUAA 1140 MSU-USSA) , , , , . , , , , . -, . , CASIA , . , , , , … , , , .
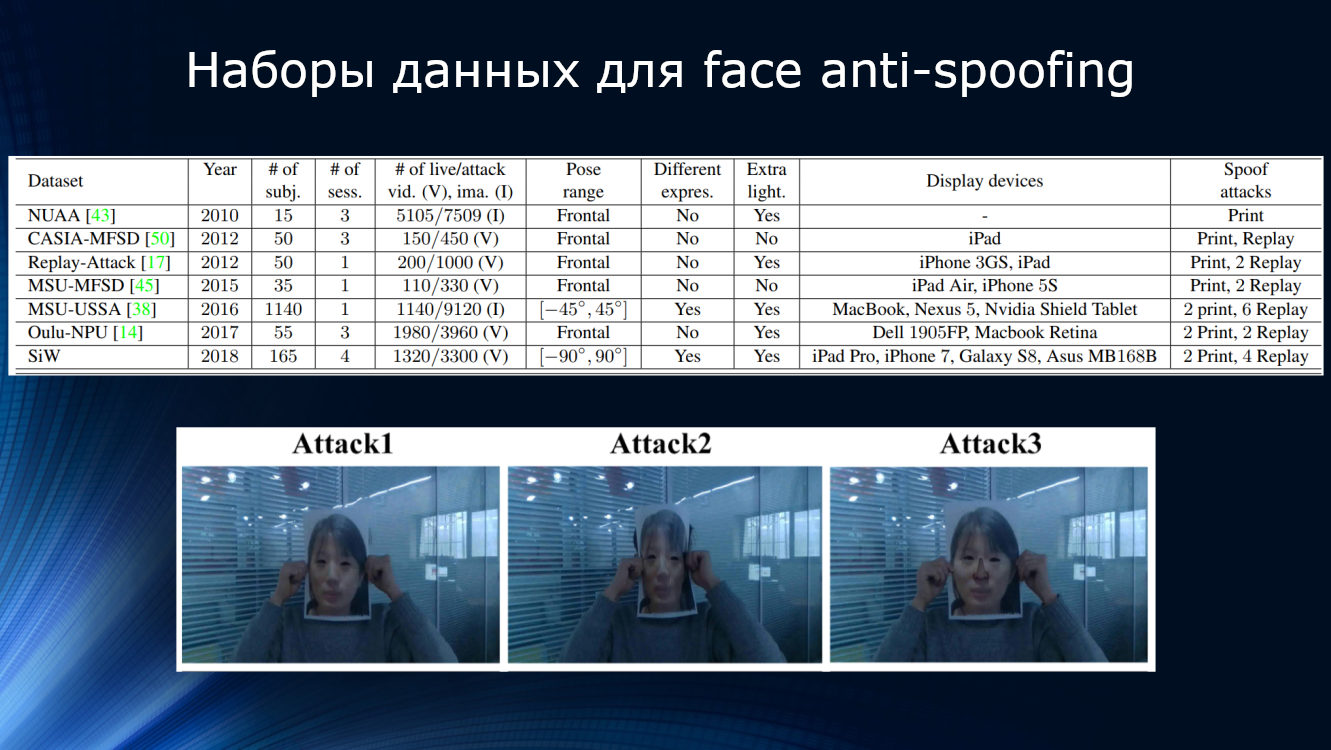
30 . , , . , .
, , « ». . , (rPPG – remote photoplethysmography), . , , -, – . . , , , . , , . , , , .


这项工作显示HTER值约为10%,证实了该方法的主要适用性。 有几项工作证实了这种方法的前景。
(CVPR 2018)JH-Ortega等 NIR中基于脉冲的人脸反欺骗的时间分析
(2016)X.李 等。 通过检测面部视频中的脉冲来进行全面的面部防欺骗
(2016)J.Chen等 Realsense =真实心率:视频中的照明不变心率估计
(2014)HE Tasli等。 使用自适应面部区域进行基于PPG的远程生命体征测量
2018年,密歇根大学的Liu及其同事提议放弃二进制分类 ,转而采用他们所谓的“二进制监督”方法,即使用基于深度图和远程光电容积描记法的更复杂的估计。 对于这些面部图像中的每一个,都使用神经网络重建了三维模型,并用深度图命名。 伪图像分配有一个由零组成的深度图,最后它只是一张纸或一个设备屏幕! 这些特征被视为“真相”;神经网络在其自己的SiW数据集上进行了训练。 然后,将三维面罩叠加在输入图像上,为其计算深度图和脉冲,然后将所有这些都捆绑在一个相当复杂的传送带中。 结果,该方法在OULU竞争数据集上显示出约10%的准确性。 有趣的是,奥卢大学组织的比赛的获胜者将算法建立在二进制分类模式,眨眼追踪和其他“手工设计”标志上,其解决方案的准确度也约为10%。 收益只有大约百分之五! 该算法在其自己的数据集上进行了训练,并在OULU上进行了测试,从而为新的组合技术提供了支持,从而提高了获胜者的成绩。 这表明结果从数据集到数据集具有一定的可移植性,到底是不是在开玩笑,现实生活还是有可能的。 但是,当尝试在其他数据集(CASIA和ReplayAttack)上进行训练时,结果还是大约28%。 当然,当对各种数据集进行训练时,这超出了其他算法的性能,但是具有这样的精度值,就谈不上任何工业用途!
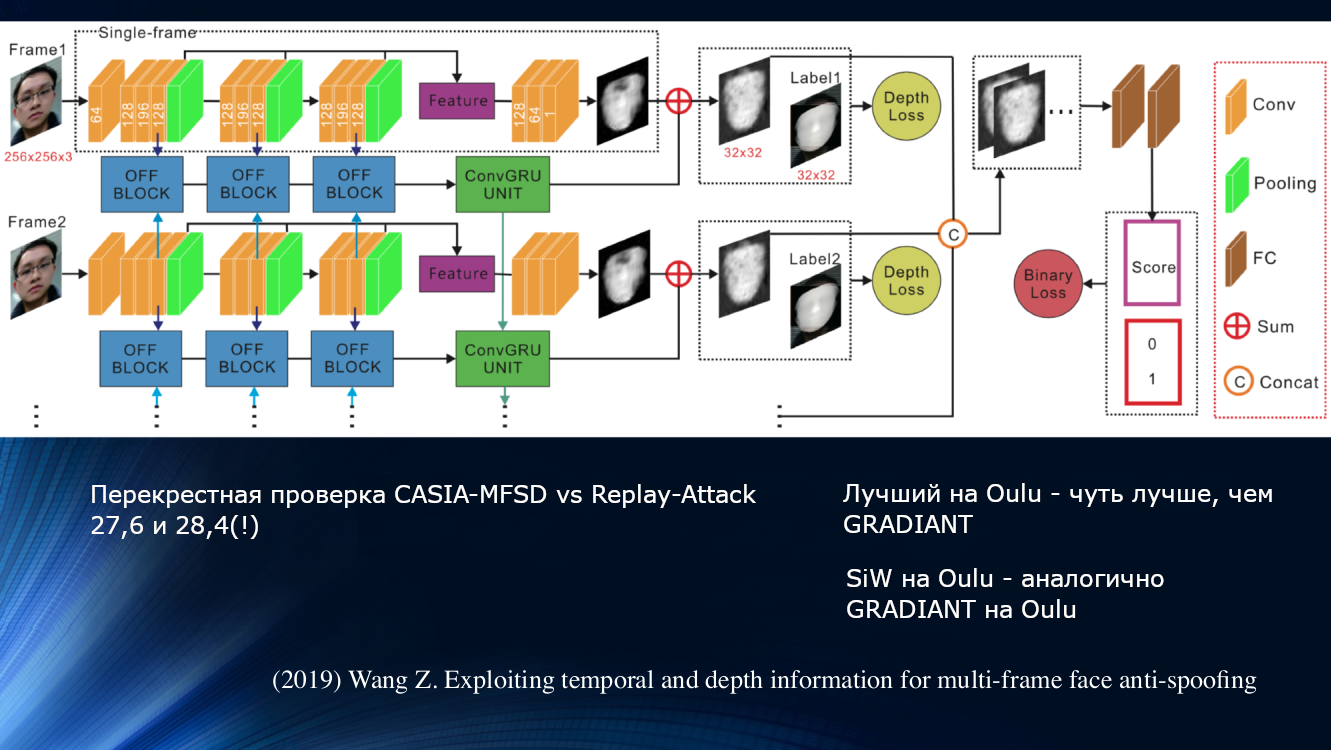
Wang和同事在2019年的最新工作中提出了另一种方法。 注意到在分析面部的微动时,头部的旋转和位移是明显的,从而导致面部上的符号之间的角度和相对距离的特征变化。 因此,当脸部水平移动时,鼻子和耳朵之间的角度会增加。 但是,如果以同样的方式移动一张带有图片的纸,角度将减小! 为了说明起见,值得引用作品中的图纸。
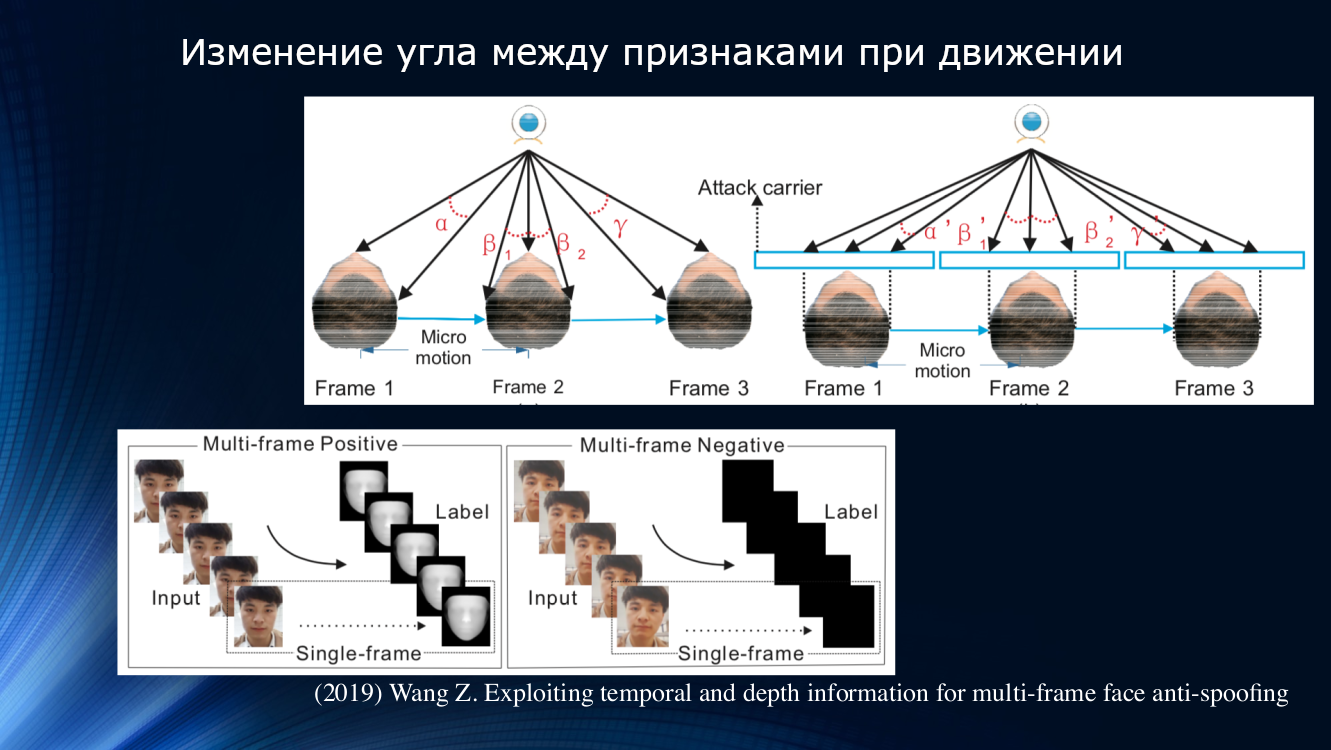
基于这一原理,作者建立了一个完整的学习单元,用于在神经网络各层之间传输数据。 它考虑了两个帧序列中每个帧的“不正确偏移量”,这使结果可用于基于GRU 门控循环单元的长期依赖关系分析的下一个块。 然后将所有符号连接起来,计算损失函数,并进行最终分类。 这使我们可以稍微改善OULU数据集上的结果,但是仍然存在依赖训练数据的问题,因为对于CASIA-MFSD和Replay-Attack对,指标分别为17.5%和24%。
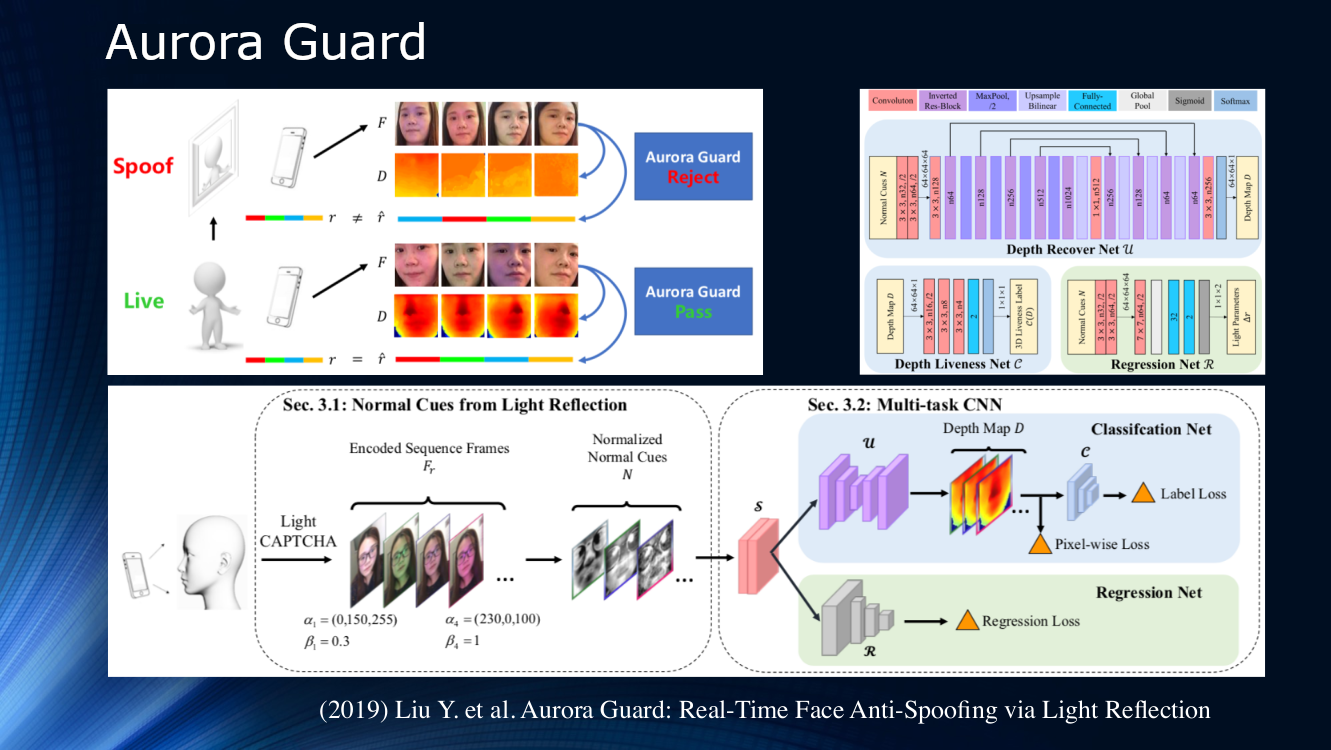
即将结束时,值得一提的是腾讯专家的工作 ,他们提议更改源视频图像的接收方式。 他们建议不要被动观察场景,而是建议动态照亮面部并读取反射。 主动照射物体的原理已长期应用于各种定位系统中,因此,将其用于研究人脸看起来非常合乎逻辑。 显然,为了在图像本身中进行可靠的识别,没有足够的信号,并且使用一系列的浅色符号(根据作者的术语为CAPTCHA来点亮)照亮手机或平板电脑的屏幕可能会很有帮助。 接下来,确定在一对帧上散射和反射的差异,并将结果馈送到多任务神经网络,以在深度图上进行进一步处理并计算各种损失函数。 最后,执行归一化光帧的回归。 作者没有分析其算法在其他数据集上的泛化能力,也没有在自己的私有数据集上对其进行训练。 结果大约是1%,据报道该模型已经被部署为实际使用。
直到2017年,面部防欺骗区域还不太活跃。 但是2019年已经展示了一系列作品,这与主要由苹果公司积极推广的移动面部识别技术有关。 此外,银行对面部识别技术也很感兴趣。 这个行业有很多新人,这使我们充满希望取得进展。 但是到目前为止,尽管出版物有漂亮的标题,但是算法的泛化能力仍然很弱,并且不允许我们谈论任何实际应用的适用性。
结论 最后,我要说的是...
- 本地二进制模式,跟踪眨眼,呼吸,动作和其他手动设计的标志根本没有失去其意义。 这主要是由于在面部防欺骗领域进行深入培训仍然非常幼稚的事实。
- 显然,在“相同”解决方案中,将合并几种方法。 反射,散射,深度图分析应一起使用。 最有可能的是,添加额外的数据通道将有帮助,例如,语音记录和某种系统方法,这些方法可让您将多种技术收集到一个系统中
- 几乎所有用于面部识别的技术都可以在面部反欺骗中找到应用(cap!)。为面部识别而开发的所有内容(一种或另一种形式)都可以用于攻击分析。
- 现有数据集已达到饱和。 在五分之十的基本数据集中,实现了零误差。 例如,这已经谈到了基于深度图的方法的效率,但不允许提高泛化能力。 我们需要新的数据和新的实验
- 人脸识别的发展程度与人脸反欺骗之间存在明显的不平衡。 识别技术明显领先于保护系统。 此外,缺乏可靠的保护系统阻碍了面部识别系统的实际使用。 碰巧的是,主要注意力集中在人脸识别上,并且攻击检测系统仍然显得微不足道
- 在面部反欺骗领域中非常需要一种系统的方法。 奥卢大学过去的竞争表明,使用非代表性的数据集时,只需对现有解决方案进行简单有效的调整即可消除失败,而无需开发新解决方案。 也许新的竞争可以扭转潮流
- 随着人们对该主题的兴趣日益增加,以及大型玩家引入了面部识别技术,新的雄心勃勃的团队出现了“机遇之窗”,因为在架构级别上迫切需要一种新的解决方案