
哈利·波特的技术一直活到今天。 现在,要创建一个人的完整视频,只需一张他的照片即可。 来自Skolkovo和莫斯科三星AI中心的机器学习研究人员发布了他们在创建这样一个系统方面的工作,以及许多名人和艺术品的录像带,这些录像带重新焕发了生命。

可以在这里阅读科学著作的全文。 那里的一切都很有趣,有很多公式,但是含义很简单:它们的系统受“地标”,鼻子,两只眼睛,两条眉毛和下巴线等脸部视觉的引导。 因此,她立即了解一个人是什么。 然后,它可以将其他所有内容(颜色,面部纹理,胡须,胡茬等)传输到任何其他人的视频中。 使旧面孔适应新情况。
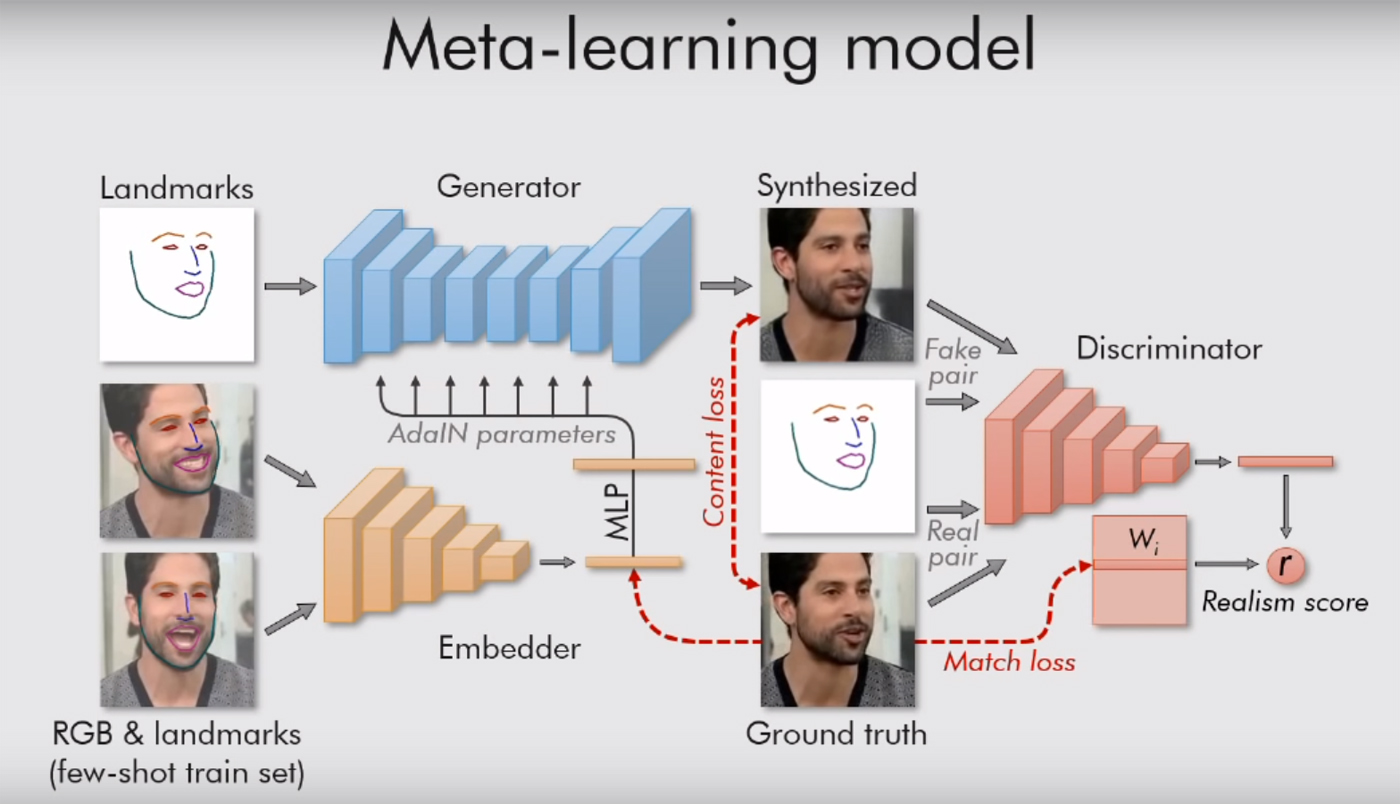
当然,这仅适用于肖像。 该模型仅需一个人,其脸部朝向我们,这样他至少可以看到两只眼睛。 然后,系统可以对其执行任何操作,向其传输任何面部表情。 给她一个合适的视频就足够了(另一个人的头大约在同一位置)。
早些时候,人工智能已经学会了如何制造声音,互联网用户通过将面孔插入色情内容并与尼古拉斯·凯奇(Nicholas Cage)进行模因来嘲笑名人。 但是为此,他们必须训练算法以兆字节(或更好的千兆字节)的数据为基础,以找到尽可能多的具有名人面孔的图像和视频,以产生或多或少的体面结果。 Deepfakes的创建者本人说,汇编一部短片需要8到12个小时。 新系统可立即生成结果,而在输入时只需要一张图片。
使用以前的系统,我们将永远无法看清生活中的蒙娜丽莎,因为我们只有一个角度。 现在,借助基准算法,这已成为可能。 理想没有实现,但是有些事情已经接近了。

莫斯科的研究人员还使用了生成对抗网络。 该算法的两个模型相互冲突。 每个人都试图欺骗对手,并向他证明她创建的视频是真实的。 这样,就可以达到一定程度的真实感:如果评论者模型对其真实性的把握不超过90%,则不会“露面”释放人脸。 正如作者在他们的工作中所说的那样,图像中调节着数千万个参数,但是由于这种系统,这项工作很快就沸腾了。

如果有几张图片,效果会得到改善。 同样,最简单的方法是与已经从各个角度入手的名人共事。 为了实现“理想的现实主义”,需要32张照片。 在这种情况下,生成的低分辨率AI照片将无法与真实的人类照片区分开。 在这一阶段未经训练的人不再能够识别假货-也许机会仍然存在于专家或与所有这些图像中的“实验性”近亲中。
如果只有一张照片或图片,则结果并不总是最好的。 头部运动时,您可以在视频上看到伪像,没有任何问题。 研究人员自己说,他们的最弱点是凝视。 基于脸部标志的模型尚不能始终了解人的外观和位置。
