我们都知道哈希看起来像什么,但是您是否想知道某个特定字符在哈希中出现的频率如何? 我想知道 我决定检查一下。 绘制了一个Python脚本以进行计数,这就是它的结果。
首先,我生成了一个随机字符串(长度从0到1000)。
def random_string(from_int, to_int): return str(''.join(random.SystemRandom().choice(string.ascii_letters + string.digits + string.punctuation) for _ in range(random.randint(from_int, to_int))))
接下来,我从字符串中获取了MD5哈希。
def md5_from_string(string): return hashlib.md5(string.encode('utf-8')).hexdigest()
之后-我计算了哈希中有0到9之间的数字。 在1000个散列的样本中,我收到了以下数据:
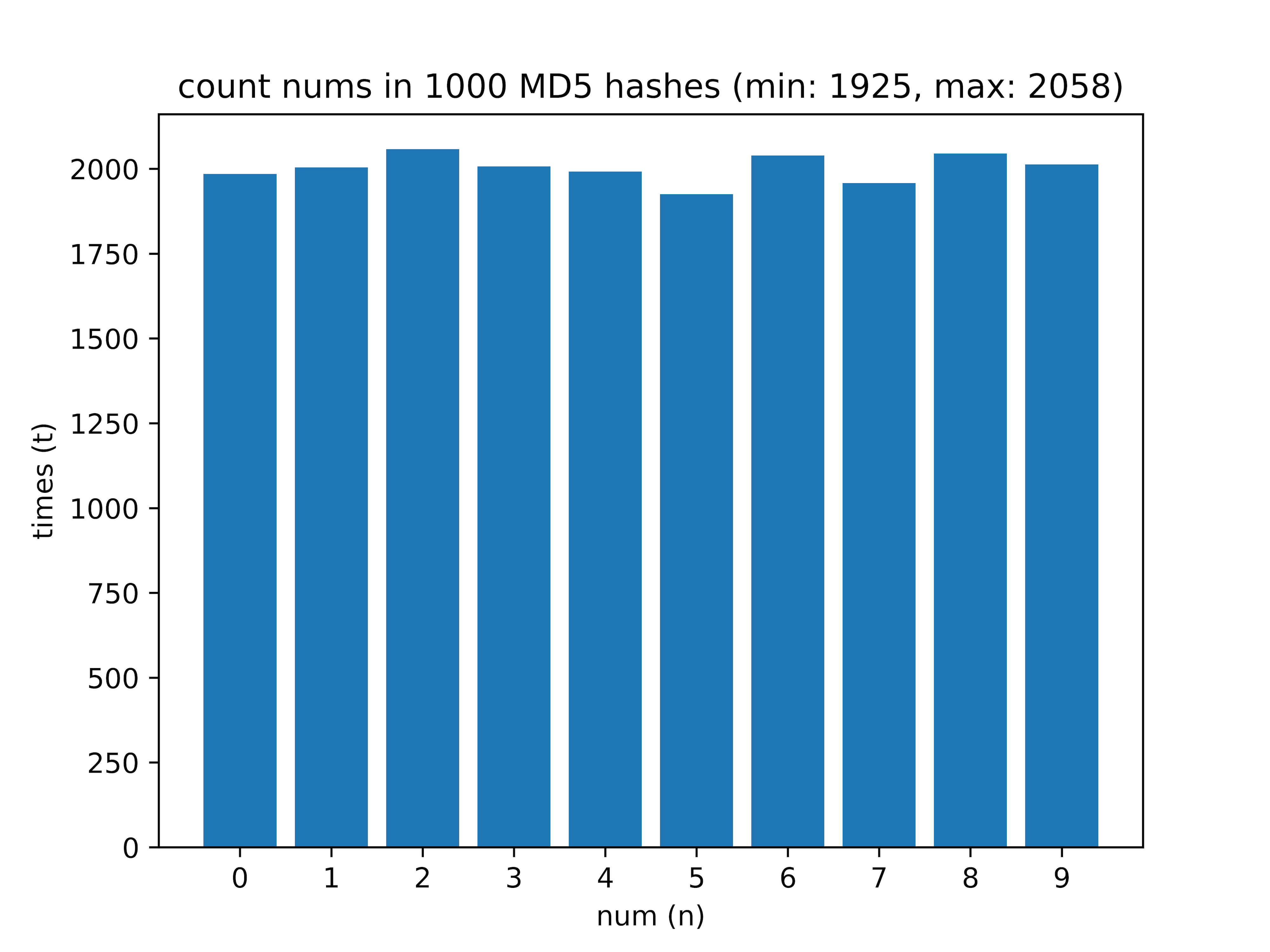
在这里,最常遇到的数字和最稀有的数字(增量值)之间的差异很有趣。

此外,为了跟踪增量值的变化,他制作了10,000、100,000、1,000,000、10,000,000哈希值的样本。

以下是具有不同数量的MD5哈希值的样本的最小和最大数值以及增量值的列表:
- 100-最小值:179,最大值:230,增量: 22.17%
- 1000-最小值:1925,最大值:2058,增量: 6.46%
- 10000-最小值:19769,最大值:20251,增量: 2.38%
- 100000-最小值:199297,最大值:200846,增量: 0.77%
- 1,000,000-最小值:1997650,最大值:2001690,增量: 0.20%
- 10000000-最小值:19991830,最大值:20004818,增量: 0.06%
我们所拥有的:随着数组中哈希数的增加,增量值将减小,并且具有几乎相同概率的任何数字都将落入数组中。 因此,样本越大,经常遇到和很少见到的数字之间的差异就越小。 因此,在散列中获得特定数字的可能性趋于均匀。
这些信息构成了我们在
bepeam.com竞争
平台上实现的算法的基础