你好
我的名字叫Marat Gayanov,我想与大家分享我在“
最佳反向器”竞赛中解决问题的方法,以展示如何为这种情况制作密钥发生器。
内容描述
在此竞赛中,将为参与者提供Sega Mega Drive的ROM游戏(
best_reverser_phd9_rom_v4.bin )。
任务:领取一个这样的密钥,该密钥连同参与者的电子邮件地址将被视为有效。
所以解决方案...
工具
检查密钥长度
该程序不接受每个键:您需要填写整个字段,它们是16个字符。 如果密钥较短,您将看到一条消息:“长度错误! 再试一次...”。
让我们尝试在程序中找到这一行,我们将使用二进制搜索(Alt-B)。 我们会发现什么?
我们不仅会发现这一点,还会发现附近的其他服务热线:“错误的密码! 再试一次...“和“您是最好的反向器!”。
为了方便起见,我设置了
WRONG_LENGTH_MSG ,
YOU_ARE_THE_BEST_MSG和
WRONG_KEY_MSG 。
中断读取地址
0x0000FDFA -找出谁处理消息“长度错误! 再试一次...”。 并运行调试器(在输入键之前它将停止几次,只需在每次停止时按F9键)。 输入您的电子邮件,输入
ABCD 。
调试器导致
0x00006FF0 tst.b (a1)+ :
块本身没有什么有趣的。 谁在这里转移控制权更有趣。 我们来看一下调用堆栈:
单击并获得此处-转到指令
0x00001D2A jsr (sub_6FC0).l :
我们看到所有可能的消息都被发现在一个地方。 但是,让我们在
WRONG_KEY_LEN_CASE_1D1C块中找出控制权转移到的
WRONG_KEY_LEN_CASE_1D1C 。 我们不会设置中断,只需将光标移到箭头上的箭头即可。 调用方位于
0x000017DE loc_17DE (我将其重命名为
CHECK_KEY_LEN ):
在地址
0x000017EC cmpi.b 0x20 (a0, d0.l)上
0x000017EC cmpi.b 0x20 (a0, d0.l)在此上下文中,该指令将查看键字符数组末尾是否有空字符),重新启动,重新输入邮件和
ABCD密钥。 调试器停止并显示输入的密钥位于地址
0x00FF01C7 (此时存储在寄存器
a0 ):
这是一个很好的发现,通过它我们将完全掌握所有内容。 但是首先,为了方便起见,标记密钥的字节:
从该位置向上滚动,我们看到邮件存储在键旁边:
我们深入研究,是时候找到密钥正确性的标准了。 而是密钥的前半部分。
密钥前半部分正确性的标准
初步计算
合理地假设,在检查了长度之后,将立即进行其他使用该键的操作。 检查后立即考虑该块:
该街区正在进行初步工作。
get_hash_2b函数(原来是
sub_1526 )被调用了两次。 首先,将密钥的第一个字节的地址发送给它(寄存器
a0包含地址
KEY_BYTE_0 ),第二次-第五个(
KEY_BYTE_4 )。
我之所以这样命名函数,是因为它考虑的是2字节哈希。 这是我最容易理解的名称。
我不会考虑函数本身,但是我会立即用python编写它。 她做一些简单的事情,但是她对屏幕截图的描述会占用很多空间。
最重要的事情是:输入地址被提供给输入,并且正在从该地址开始处理4个字节。 也就是说,他们将键的第一个字节发送到输入,并且该函数将与1,2,3,4th一起使用。 第五名,该函数与第5、6、7、8位一起使用。 换句话说,在此块中,对密钥的前半部分进行了计算。 结果写入
d0寄存器。
因此,
get_hash_2b函数:
立即编写哈希解码功能:
我没有想出更好的解码功能,而且并不完全正确。 因此,我将以这种方式进行检查(不是现在,而是以后):
key_4s == decode_hash_4s(get_hash_2b(key_4s))
检查
get_hash_2b的操作。 函数执行后,我们对寄存器
d0的状态感兴趣。 我们在输入
ABCDEFGHIJKLMNOP的密钥
0x000017FE和
0x00001808输入了中断。
值
0xABCD ,
0xEF01输入到寄存器
d0 。 而
get_hash_2b会给什么呢?
>>> first_hash = get_hash_2b("ABCD") >>> hex(first_hash) 0xabcd >>> second_hash = get_hash_2b("EFGH") >>> hex(second_hash) 0xef01
验证通过。
然后产生
xor eor.w d0, d5 ,结果输入
d5 :
>>> hex(0xabcd ^ 0xef01) 0x44cc
获得这样的哈希值是
0x44CC ,由初步计算组成。 此外,一切只会变得更加复杂。
哈希值去哪儿了
如果我们不知道该程序如何与哈希一起工作,我们将走得更远。 当然,它会从
d5移动到内存,因为 该寄存器在其他地方很方便。 我们可以通过跟踪(观看
d5 )找到这样的事件,但不是手动的,而是自动的。 以下脚本将帮助您:
#include <idc.idc> static main() { auto d5_val; auto i; for(;;) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); d5_val = GetRegValue("d5"); // d5 if (d5_val != 0xFFFF44CC){ break; } } }
让我提醒您,我们现在处于最后一个中断
0x00001808 eor.w d0, d5 。 粘贴脚本(
Shift-F2 ),单击
Run该脚本将在指令
0x00001C94 move.b (a0, a1.l), d5处停止,但是此时
d5已被清除。 但是,我们看到
d5中的值被指令
0x00001C56 move.w d5,a6 :它被写入地址
0x00FF0D46 (2个字节)的存储器中。
请记住:哈希存储在0x00FF0D46 。我们捕获了从
0x00FF0D46-0x00FF0D47读取的指令(我们设置了读取
0x00FF0D46-0x00FF0D47 )。 抓到4个方块:




如何选择正确的/正确的?
回到开头:
此块确定程序将进入
LOSER_CASE还是进入
WINNER_CASE :
我们看到寄存器
d1必须为零才能获胜。
置零在哪里? 向上滚动:
如果在
loc_1EEC块中满足
loc_1EEC :
*(a6 + 0x24) == *(a6 + 0x22)
那么我们在
d5得到零。
如果在指令
0x00001F16 beq.w loc_20EA上加一个中断,我们将看到
a6 + 0x24 = 0x00FF0D6A并在
0x4840存储了值
0x4840 。 并且在
a6 + 0x22 = 0x00FF0D68中存储了
a6 + 0x22 = 0x00FF0D68 。
如果我们输入不同的键,邮件,我们将看到
0xCB4C - 。
仅当在0x00FF0D6A也有0xCB4C才接受密钥的前半部分。 这是密钥前半部分正确性的标准。我们找出哪些块写在
0x00FF0D6A -中断记录,再次输入邮件和密钥。
我们将找到这个
loc_EAC块(实际上有3个,但是前两个只是
0x00FF0D6A零):
该块属于
sub_E3E函数。
通过调用堆栈,我们发现在块
loc_1F94 ,
loc_203E调用了
sub_E3E函数:
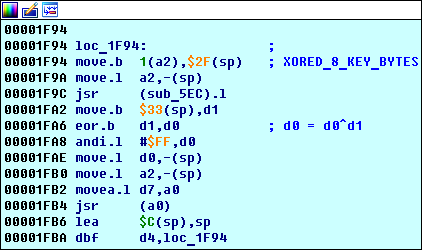

还记得我们早发现了4个街区吗?
loc_1F94我们在那里看到了-这是主密钥处理算法的开始。
第一个重要循环loc_1F94
从代码中可以看到
loc_1F94是一个循环的事实:它执行了
d4次(请参见指令
0x00001FBA d4,loc_1F94 ):
寻找什么:
- 有一个
sub_5EC函数。 - 指令0x00001FB4 jsr(a0)调用sub_E3E函数(可以通过简单的跟踪查看)。
这是怎么回事:
sub_5EC函数将其执行结果写入d0寄存器(这将在下面的单独部分中进行讨论)。- 地址
sp+0x33处的字节(调试器告诉我们0x00FFFF79 )存储在寄存器d1 ,它等于键哈希地址( 0x00FF0D47 )的第二个字节。 如果您在记录0x00FFFF79处放个中断,这很容易证明:它将对指令0x00001F94 move.b 1(a2), 0x2F(sp) 。 此时的寄存器a2存储地址0x00FF0D46哈希地址,即0x1(a2) = 0x00FF0D46 + 1哈希的第二个字节的地址。 - 寄存器
d0被写入d0^d1 。
- 所得的xor'a结果将提供给
sub_E3E函数,该函数的行为取决于其先前的计算(如下所示)。 - 再说一次
此循环运行多少次?
找出这个。 运行以下脚本:
#include <idc.idc> static main() { auto pc_val, d4_val, counter=0; while(pc_val != 0x00001F16) { StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); pc_val = GetRegValue("pc"); if (pc_val == 0x00001F92){ counter++; d4_val = GetRegValue("d4"); print(d4_val); } } print(counter); }
0x00001F92 subq.l 0x1,d4在这里确定在循环之前
d4会发生什么:
我们处理sub_5EC函数。
sub_5EC
重要的代码段:
其中
0x2c(a2)始终为
0x00FF1D74 。
这段代码可以用伪代码重写:
d0 = a2 + 0x2C *(a2+0x2C) = *(a2+0x2C) + 1 #*(0x00FF1D74) = *(0x00FF1D74) + 1 result = *(d0) & 0xFF
也就是说,从
0x00FF1D74 4个字节是地址,因为 他们像指针一样对待。
如何在python中重写
sub_5EC函数?
- 或进行内存转储并使用它。
- 或者只是写下所有返回的值。
我更喜欢第二种方法,但是如果使用不同的授权数据,返回的值不同怎么办? 检查一下。
该脚本将对此有所帮助:
#include <idc.idc> static main() { auto pc_val=0, d0_val; while(pc_val != 0x00001F16){ pc_val = GetRegValue("pc"); if (pc_val == 0x00001F9C) StepInto(); else StepOver(); GetDebuggerEvent(WFNE_SUSP, -1); if (pc_val == 0x00000674){ d0_val = GetRegValue("d0") & 0xFF; print(d0_val); } } }
我只是将输出与具有不同键,邮件的控制台进行了比较。
使用不同的键多次运行脚本,我们将看到
sub_5EC函数始终返回数组中的下一个值:
def sub_5EC_gen(): dump = [0x92, 0x8A, 0xDC, 0xDC, 0x94, 0x3B, 0xE4, 0xE4, 0xFC, 0xB3, 0xDC, 0xEE, 0xF4, 0xB4, 0xDC, 0xDE, 0xFE, 0x68, 0x4A, 0xBD, 0x91, 0xD5, 0x0A, 0x27, 0xED, 0xFF, 0xC2, 0xA5, 0xD6, 0xBF, 0xDE, 0xFA, 0xA6, 0x72, 0xBF, 0x1A, 0xF6, 0xFA, 0xE4, 0xE7, 0xFA, 0xF7, 0xF6, 0xD6, 0x91, 0xB4, 0xB4, 0xB5, 0xB4, 0xF4, 0xA4, 0xF4, 0xF4, 0xB7, 0xF6, 0x09, 0x20, 0xB7, 0x86, 0xF6, 0xE6, 0xF4, 0xE4, 0xC6, 0xFE, 0xF6, 0x9D, 0x11, 0xD4, 0xFF, 0xB5, 0x68, 0x4A, 0xB8, 0xD4, 0xF7, 0xAE, 0xFF, 0x1C, 0xB7, 0x4C, 0xBF, 0xAD, 0x72, 0x4B, 0xBF, 0xAA, 0x3D, 0xB5, 0x7D, 0xB5, 0x3D, 0xB9, 0x7D, 0xD9, 0x7D, 0xB1, 0x13, 0xE1, 0xE1, 0x02, 0x15, 0xB3, 0xA3, 0xB3, 0x88, 0x9E, 0x2C, 0xB0, 0x8F] l = len(dump) offset = 0 while offset < l: yield dump[offset] offset += 1
这样
sub_5EC可以准备
sub_5EC 。
sub_E3E是
sub_E3E 。
sub_E3E
重要的代码段:
解密:
, d2, . a2 0xFF0D46, a2 + 0x34 = 0xFF0D7A d0 = *(a2 + 0x34) *(a2 + 0x34) = *(a2 + 0x34) + 1 , a0 a0 = d0 *(a0) = d2 offset, d2. a2 0xFF0D46, a2 + 0x24 = 0xFF0D6A - , (. ) 0x00000000, d0 = *(a2 + 0x24) d2 = d0 ^ d2 d2 = d2 & 0xFF d2 = d2 + d2 - 2 0x00011FC0 + d2, ROM, 0x00011FC0 + d2 a0 = 0x00011FC0 d2 = *(a0 + d2) 8 d0 = d0 >> 8 d2 = d0 ^ d2 *(a2 + 0x24) = d2
sub_E3E函数可
sub_E3E为以下步骤:
- 将输入参数保存到数组。
- 计算偏移量。
- 在地址
0x00011FC0 + offset (ROM)中拉2个字节。 - 结果=
( >> 8) ^ (2 0x00011FC0 + offset) 。
想象一下这种形式的
sub_E3E函数:
def sub_E3E(prev_sub_E3E_result, d2, d2_storage): def calc_offset(): return 2 * ((prev_sub_E3E_result ^ d2) & 0xff) d2_storage.append(d2) offset = calc_offset() with open("dump_00011FC0", 'rb') as f: dump_00011FC0_4096b = f.read() some = dump_00011FC0_4096b[offset:offset + 2] some = int.from_bytes(some, byteorder="big") prev_sub_E3E_result = prev_sub_E3E_result >> 8 return prev_sub_E3E_result ^ some
dump_00011FC0只是一个文件,我从
[0x00011FC0:00011FC0+4096]保存了4096个字节。
1FC4附近的活动
我们还没有看到地址
0x00001FC4 ,但是很容易找到,因为该块几乎在第一个循环之后就进入了。
该块更改了地址
0x00FF0D46 (寄存器
a2 )中的内容,也就是密钥哈希的存储位置,因此我们现在在研究此块。 让我们看看这里发生了什么。
- 确定是选择左分支还是右分支的条件是:(
( ) & 0b1 != 0 。 即,检查哈希的第一位。 - 如果您查看两个分支,您将看到:
- 在这两种情况下,都会向右移一位。
- 在左分支中,执行哈希运算,
0x8000执行 0x8000 。 - 在这两种情况下,已处理的哈希值都被写入地址
0x00FF0D46 ,即,哈希值被替换为新值。 - 进一步的计算不是关键性的,因为,大致而言,
(a2)中没有写操作(a2)没有指令,第二个操作数将是(a2) )。
想象这样一个块:
def transform(hash_2b): new = hash_2b >> 1 if hash_2b & 0b1 != 0: new = new | 0x8000 return new
第二个重要的循环是loc_203E
loc_203E循环,因为
0x0000206C bne.s loc_203E 。
这个循环计算哈希值,这是它的主要特征:
jsr (a0)是对我们已经检查过的
sub_E3E函数的调用-它依赖于其自身工作的先前结果和某些输入参数(它是通过上面的寄存器
d2传递的,这里是通过
d0传递的) )
让我们找出通过
d0寄存器传递给她的东西。
我们已经遇到了构造
0x34(a2) sub_E3E函数将传递的参数保存在那里。 这意味着在此循环中使用了先前传递的参数。 但不是全部。
解密代码部分:
2 a2+0x1C move.w 0x1C(a2), d0 neg.l d0 a0 sub_E3E movea.l 0x34(a2), a0 , d0 2 a0-d0( d0 ) move.b (a0, d0.l), d0
底线很简单:在每次迭代中,从数组末尾获取
d0存储的参数。 也就是说,如果4存储在
d0 ,那么我们从末尾取第四个元素。
如果是这样,
d0究竟
d0什么? 在这里,我没有编写脚本,只是简单地将它们写了出来,在此代码块的开头放置了一个空格。 它们是:
0x04, 0x04, 0x04, 0x1C, 0x1A, 0x1A, 0x06, 0x42, 0x02 。
现在,我们拥有编写完整的键哈希计算功能的所有功能。
完整的哈希计算功能
def finish_hash(hash_2b):
健康检查
- 在调试器中,我们将中断设置为地址
0x0000180A move.l 0x1000,(sp) (在哈希计算之后立即)。 - 中断到地址
0x00001F16 beq.w loc_20EA (比较最终哈希与常量0xCB4C )。 - 在程序中,输入键
ABCDEFGHIJKLMNOP ,然后按Enter 。 - 调试器在
0x0000180A处0x0000180A ,我们看到将值0xFFFF44CC 0x44CC d5寄存器,其中0x44CC是第一个哈希。 - 我们进一步启动调试器。
- 我们在
0x00FF0D6A处停止,然后在0x00FF0D6A处看到0x4840最后的哈希
- 现在查看我们的finish_hash(hash_2b)函数:
>>> r = finish_hash(0x44CC) >>> print(hex(r)) 0x4840
我们正在寻找正确的钥匙1
正确的密钥是此密钥,其最终哈希为
0xCB4C (如上所示)。 因此,问题就来了:最终变成
0xCB4C的第一个哈希应该是什么?
现在很容易发现:
def find_CB4C(): result = [] for hash_2b in range(0xFFFF+1): final_hash = finish_hash(hash_2b) if final_hash == 0xCB4C: result.append(hash_2b) return result >>> r = find_CB4C() >>> print(r)
程序的输出表明只有一个选项:第一个哈希应该是
0xFEDC 。
我们需要什么字符,以便它们的第一个哈希为
0xFEDC ?
由于
0xFEDC = __4_ ^ __4_您只需要查找
__4_的
__4_ = __4_ ^ 0xFEDC ,因为
__4_的
__4_ = __4_ ^ 0xFEDC 。 然后解码两个哈希。
算法如下:
def get_first_half(): from collections import deque from random import randint def get_pairs(): pairs = [] for i in range(0xFFFF + 1): pair = (i, i ^ 0xFEDC) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) pairs = get_pairs() for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
一堆选项,任意选择。
我们正在寻找正确的钥匙2
密钥的前半部分已准备就绪,第二个部分呢?
这是最简单的部分。
负责的代码位于
0x00FF2012 ,我通过手动跟踪找到了它,从地址
0x00001F16 beg.w loc_20EA (验证密钥的前半部分)。 在寄存器
a0是邮件地址,
loc_FF2012是一个循环,因为
bne.s loc_FF2012 。 只要有
*(a0+d0) (邮件的下一个字节
*(a0+d0)它就会执行。
jsr (a3)指令调用了已经熟悉的
get_hash_2b函数,该函数现在可以与键的后半部分一起使用。
让我们使代码更清晰:
while(d1 != 0x20){ d2++ d1 = d1 & 0xFF d3 = d3 + d1 d0 = 0 d0 = d2 d1 = *(a0+d0) } d0 = get_hash_2b(key_byte_8) d3 = d0^d3 d0 = get_hash_2b(key_byte_12) d2 = d2 - 1 d2 = d2 << 8 d2 = d0^d2 if (d2 == d3) success_branch
在寄存器
d2 -
( -1) << 8 。 在
d3 ,邮件字符的字节总和。
正确性标准如下:
__ ^ d2 == ___2 ^ d3 。
我们编写键后半部分的选择功能:
def get_second_half(email): from collections import deque from random import randint def get_koeff(): k1 = sum([ord(c) for c in email]) k2 = (len(email) - 1) << 8 return k1, k2 def get_pairs(k1, k2): pairs = [] for a in range(0xFFFF + 1): pair = (a, (a ^ k1) ^ k2) pairs.append(pair) pairs = deque(pairs) pairs.rotate(randint(0, 0xFFFF)) return list(pairs) k1, k2 = get_koeff() pairs = get_pairs(k1, k2) for pair in pairs: key_4s_0 = decode_hash_4s(pair[0]) key_4s_1 = decode_hash_4s(pair[1]) hash_2b_0 = get_hash_2b(key_4s_0) hash_2b_1 = get_hash_2b(key_4s_1) if hash_2b_0 == pair[0] and hash_2b_1 == pair[1]: return key_4s_0, key_4s_1
Keygen
邮件必须是一个胶囊。
def keygen(email): first_half = get_first_half() second_half = get_second_half(email) return "".join(first_half) + "".join(second_half) >>> email = "M.GAYANOV@GMAIL.COM" >>> print(keygen(email)) 2A4FD493BA32AD75
感谢您的关注! 所有代码都
在这里 。