在“黑镜”中,有一个系列(S2E1),他们使用社交网络上的通信历史来训练类似于死者的机器人。 我想告诉你我如何尝试做类似的事情以及它的结果。 没有理论,只有实践。

这个想法很简单-从Telegram获得他们的聊天记录,并在他们的基础上训练seq2seq网络,该网络能够在对话开始时预测其完成。 这样的网络可以三种模式运行:
- 根据对话历史预测用户短语的完成
- 在聊天机器人模式下工作
- 合成整个对话记录
那就是我得到的
Bot提供词组补全
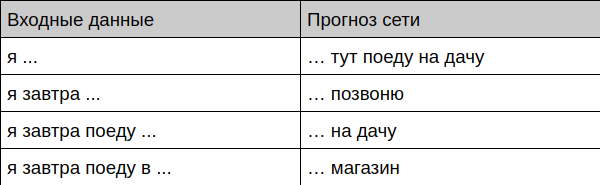
Bot提供对话的完成
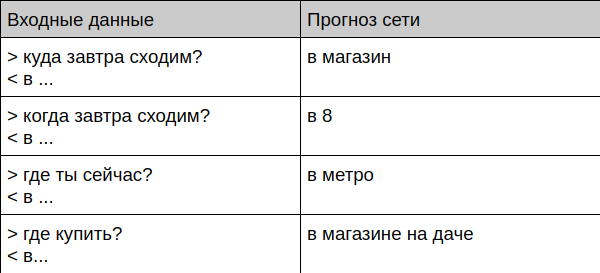
Bot与在世人士交流
User: Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot:
接下来,我将告诉您如何准备数据并亲自培训这样的机器人。
如何教自己
资料准备
首先,您需要在某个地方进行很多聊天。 我用Telegram收集了所有信件,因为桌面客户端允许下载JSON格式的完整档案。 然后,我丢弃了所有包含引号,链接和文件的消息,并将其余文本转换为小写字母,并从中删除了所有稀有字符,仅保留了一组简单的字母,数字和标点符号-便于学习网络。
然后,我将聊天内容转换为以下形式:
=== > < > < ! === > ? <
在这里,以符号“>”开头的消息对我来说是一个问题,符号“ <”相应地标记了我的答案,而行“ ===”用于分隔对话框。 我确定一个对话结束而另一个对话开始的事实是由时间决定的(如果消息之间传递的时间超过15分钟,那么我们认为这是一次新的对话。您可以在github上看到用于转换故事的脚本。
由于我长期以来一直在积极地使用电报,所以最后有很多消息-最终文件中有44.3万行。
选型
我保证今天不会有任何理论,因此我将尽我所能解释。
我选择了基于GRU的经典seq2seq。 这种输入模型逐个字母地接收文本,并且一次也输出一个字母。 学习过程基于以下事实:我们教网络预测文本的最后一个字母,例如,将“ lead”赋予输入,然后等待“ rivet”被输出。
为了生成长文本,使用了一个简单的技巧-将先前预测的结果发送回网络,依此类推,直到生成必要的文本长度为止。
GRU模块可以非常简化为“具有记忆力和注意力的狡猾的感知器”,例如,可以在此处找到有关它们的更多详细信息。
该模型基于生成莎士比亚文本的任务的著名示例 。
培训课程
曾经接触过神经网络的任何人都可能知道,在CPU上学习它们非常无聊。 幸运的是,谷歌通过其Colab服务为您提供了帮助 -您可以使用CPU,GPU甚至TPU在jupyter笔记本中免费运行代码。 以我为例,对视频卡的培训可以在30分钟内完成,尽管在10点后仍可获得合理的结果。主要要记住要切换硬件的类型(在“运行时”菜单->更改运行时类型中)。
测试中
训练后,您可以继续进行模型验证-我编写了一些示例,使您可以以不同的方式访问模型-从文本生成到实时聊天。 所有这些都在github上 。
生成文本的方法具有温度参数-温度参数越高,生成机器人的文本就越多样化(无意义)。 该参数对于配置特定任务的手很有意义。
进一步使用
为什么要使用这样的网络? 最明显的是开发一种机器人(或智能键盘),该机器人甚至可以在用户编写答案之前就为他们提供现成的答案。 Gmail和大多数键盘中早就存在类似的功能,但是它没有考虑到对话的上下文以及特定用户进行通信的方式。 说,G键盘稳定地为我提供了完全没有意义的选项,例如,在我想获得“我要从别墅中去”选项的地方,“我要尊重...”,我肯定使用了很多次。
聊天机器人有未来吗? 从纯粹的角度来看,它绝对不存在,它拥有太多的个人数据,没人知道它将在什么时候向对话者提供您曾经扔给朋友的信用卡号。 而且,这种机器人完全没有经过调整,很难执行任何特定任务或正确回答特定问题。 而是,这样的聊天机器人可以与其他类型的机器人一起工作,提供“几乎没有”的更紧密的对话-很好地解决了这一问题。 (不过,一位外部妻子的专家说,该机器人的通讯方式与我非常相似。他所关心的主题显然是相同的-错误,修复,提交以及开发人员的其他喜怒哀乐在文本中不断出现。)
如果您对此主题感兴趣,还有什么建议您尝试的?
- 转移学习(训练大量的其他人的对话,然后自己完成)
- 变更模型-增加,变更类型(例如,在LSTM上)。
- 尝试使用TPU。 以其纯粹形式,此模型将不起作用,但可以进行调整。 理论上的学习加速应该是十倍。
- 移植到移动平台,例如使用Tensorflow mobile。
PS 链接到github