另一个用户想将新的数据写入硬盘,但是他没有足够的可用空间。 我也不想删除任何内容,因为“所有内容都非常重要和必要。” 那我们该怎么办呢?
他没有这个问题。 数TB的信息保存在我们的硬盘驱动器上,并且这一数量不会减少。 但是它有多独特? 最后,所有文件毕竟只是具有一定长度的一组位,最有可能的是,新文件与已存储的文件没有太大区别。
显然,在硬盘驱动器上搜索已存储的信息是一项任务,即使不是失败,也至少不是有效的任务。 另一方面,因为如果差异很小,那么您可以稍微适应一下...

TL; DR-第二次尝试讨论使用JPEG文件优化数据的奇怪方法,现在以更易于理解的形式进行。
关于位和差异
如果我们获取两个完全随机的数据,则平均包含的一半比特在其中重合。 实际上,在每对可能的布局中('00,01、10、11'),恰好一半具有相同的值,这里的一切都很简单。
但是,当然,如果我们只取两个文件,将一个放在第二个文件下面,那么我们将丢失其中一个。 如果我们保留更改,我们将简单地重新发明delta编码 ,即使没有我们完美地存在,尽管通常不将其用于相同目的。 您可以尝试将较小的序列嵌入到较大的序列中,但是即使如此,当我们匆忙使用所有内容时,我们也可能会丢失关键数据段。
在什么和什么之间可以消除差异? 嗯,就是说,用户记录的一个新文件只是一系列的位,我们不能单独执行任何操作。 然后,您只需要在硬盘驱动器上找到这样的位,就可以在无需存储差异的情况下对其进行更改,以便您可以承受丢失而不会造成严重后果。 是的,不仅更改FS上的文件本身,而且更改其中的一些不太敏感的信息也很有意义。 但是,哪一个呢?
拟合方法
有损压缩文件可以解救。 尽管所有这些jpeg,mp3和其他文件都是有损压缩,但它们包含一堆可用于安全更改的位。 您可以使用高级技术,在不同的编码区域中谨慎地修改其组件。 等一下 先进的技术...不起眼的修改...其他一些...是的,这几乎是隐写术 !
的确,无论如何,将一种信息嵌入另一种信息都类似于其方法。 它还给人的感官变化留下了深刻的印象。 这就是路径分歧的地方-这是一个秘密:我们的任务是向用户的硬盘添加其他信息,这只会伤害他。 忘记更多。
因此,尽管我们可以使用它们,但是我们需要进行一些修改。 然后,我将以现有方法之一和通用文件格式的示例为例进行说明。
关于the狼
如果进行压缩,那么世界上压缩性最高。 我们当然是在谈论JPEG文件。 不仅有大量的工具和现有的方法将数据嵌入其中,它还是这个星球上最流行的图形格式。

但是,为了不进行狗的繁殖,您需要在这种格式的文件中限制活动范围。 没有人喜欢由于过度压缩而产生的单色正方形,因此您需要限制自己使用已经压缩的文件, 避免转码 。 更具体地说,由于整数系数在导致数据丢失的操作之后仍然存在-DCT和量化,因此可以完美地显示在编码方案中(感谢鲍曼国家图书馆的Wiki):

jpeg文件有很多可能的优化方法。 有无损优化(jpegtran),有无损优化,实际上它仍然起作用,但是它们不会打扰我们。 实际上,如果用户为了增加可用磁盘空间而准备将一个信息嵌入另一个信息中,那么他要么长时间优化了自己的映像,要么由于担心质量下降而根本不想这样做。
F5
在这种情况下,适合使用整个算法系列,可以在此很好的演示中找到。 其中最先进的是由Andreas Westfeld创作的F5算法,该算法使用亮度分量的系数,因为人眼对其变化最不敏感。 此外,他使用了一种基于矩阵编码的嵌入技术,该技术允许在嵌入相同数量的信息时使更改量减少,所用容器的尺寸也越大。
在某些条件下(即并非总是如此),这些变化本身可以降低每单位系数的绝对值,从而可以使用F5优化硬盘上的数据存储。 事实是,由于JPEG中值的统计分布,在进行此类更改后的系数在霍夫曼编码后可能会占用较少的位数,而使用RLE对它们进行编码将使新的零受益。
减少了必要的修改,以消除负责保密(密码置换)的部分,从而节省了资源和执行时间,并增加了一种用于处理多个文件的机制,而不是一次处理一个文件。 更详细地讲,更改读者的过程不太可能引起人们的兴趣,因此我们转向实现的描述。
高科技
为了演示这种方法的工作原理,我在纯C语言中实现了该方法,并在速度和内存方面进行了许多优化(即使在DCT之前,您也无法想象这些图片在不压缩的情况下会有多少重量)。 结合使用libjpeg , pcre和tinydir库可以实现跨平台性能 ,对此我深表感谢。 所有这些都将由make完成,因此Windows用户希望安装一些Cygwin进行评估,或者自己处理Visual Studio和库。
该实现以控制台实用程序和库的形式提供。 有关使用后者的更多信息,请参见github上存储库中的自述文件,我将在文章末尾附加到该链接。
使用方法
小心一点 通过在指定的根目录中进行正则表达式搜索来选择用于打包的图像。 在文件末尾,您可以根据需要在其中移动,重命名和复制文件,更改文件和操作系统等。但是,应格外小心,不要更改立即内容。 即使丢失一位的值,也可能导致无法恢复信息。
完成工作后,实用程序将留下一个特殊的存档文件,其中包含解压缩所需的所有信息,包括所用图像的数据。 它本身的重量只有几千字节,对占用的磁盘空间没有任何重大影响。
您可以使用'-a'标志来分析可能的容量:'./f5ar -a [搜索文件夹] [与Perl兼容的正则表达式]'。 使用命令'./f5ar -p [搜索文件夹] [Perl兼容的正则表达式] [打包的文件] [归档名称]'进行打包,并使用'./f5ar -u [归档文件] [已还原文件的名称]'进行打包。 。
工作示范
为了展示该方法的有效性,我从Unsplash服务下载了225张绝对免费的狗照片集,并在 Knut 编程艺术第二卷的文档中挖掘了一个长达45米的大型pdf文件。
序列非常简单:
$ du -sh knuth.pdf dogs/ 44M knuth.pdf 633M dogs/ $ ./f5ar -p dogs/ .*jpg knuth.pdf dogs.f5ar Reading compressing file... ok Initializing the archive... ok Analysing library capacity... done in 17.0s Detected somewhat guaranteed capacity of 48439359 bytes Detected possible capacity of upto 102618787 bytes Compressing... done in 39.4s Saving the archive... ok $ ./f5ar -u dogs/dogs.f5ar knuth_unpacked.pdf Initializing the archive... ok Reading the archive file... ok Filling the archive with files... done in 1.4s Decompressing... done in 21.0s Writing extracted data... ok $ sha1sum knuth.pdf knuth_unpacked.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth_unpacked.pdf $ du -sh dogs/ 551M dogs/
粉丝截图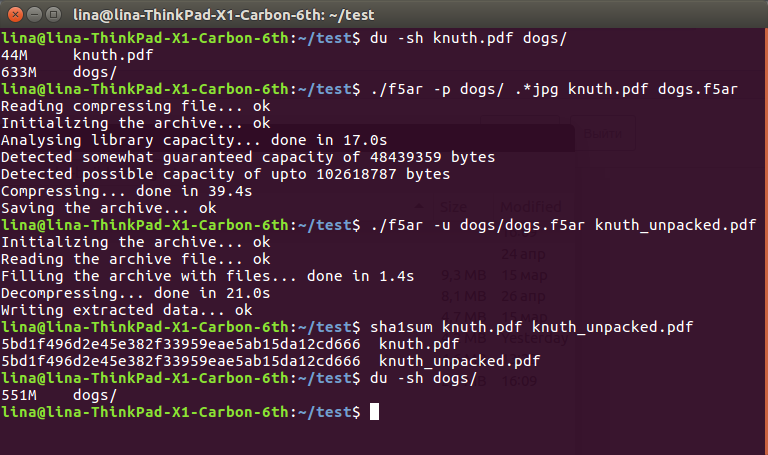
解压缩后的文件仍然可能,应阅读:

如您所见,从硬盘上原始的633 + 36 == 669兆字节数据来看,我们得到了一个更令人愉悦的551。系数值的减少解释了这种根本性的差异,系数值的降低会影响其后的压缩而不会造成损失:只有一个一个的减少就可以平静下来。从结果文件中剪切“几个字节。 但是,这仍然是必须忍受的数据丢失,尽管非常小。
幸运的是,它们不是完全可见的。 在扰流板下(因为habrastorage无法处理大文件),读者可以通过从原件中减去更改后的分量的值来通过肉眼和强度来评估差异: 原件 , 其中包含的信息是差异 (颜色越暗,块中的差异越小) )
而不是结论
考虑到所有这些困难,购买硬盘驱动器或将所有内容上传到云似乎是解决该问题的简单得多的方法。 但是,即使我们现在生活在如此美好的时光中,也无法保证明天仍然可以在线上载所有额外数据。 或者来商店购买自己的另一千TB硬盘。 但是您始终可以使用已经撒谎的房屋。
-> github