
背景知识
碰巧服务器受到勒索软件病毒的攻击,该勒索软件病毒通过“福禄克”病毒部分地搁置了.ibd文件(innodb表的原始数据文件),但对.fpm文件(结构文件)进行了完全加密。 同时.idb可分为:
- 可以通过标准工具和指南进行恢复。 对于这种情况,有一篇很棒的文章 ;
- 部分加密的表。 大多数情况下,这些都是大表,据我所知,攻击者在这些表上没有足够的RAM来进行完全加密。
- 好吧,完全加密的表无法恢复。
可以通过以所需的编码(在我的情况下为UTF8)在任何文本编辑器中打开并简单地查看文件中是否存在文本字段来确定表所属的选项,例如:
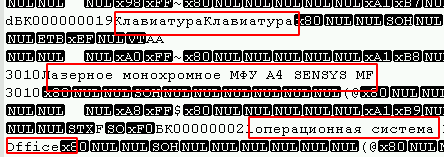
此外,在文件的开头,您可以观察到大量的0字节,并且使用块加密算法(最常见)的病毒通常会对其产生影响。

以我为例,每个加密文件末尾的攻击者都留下了4个字节的字符串(1、0、0、0),这简化了任务。 一个脚本足以搜索未感染的文件:
def opened(path): files = os.listdir(path) for f in files: if os.path.isfile(path + f): yield path + f for full_path in opened("C:\\some\\path"): file = open(full_path, "rb") last_string = "" for line in file: last_string = line file.close() if (last_string[len(last_string) -4:len(last_string)]) != (1, 0, 0, 0): print(full_path)
因此,事实证明是找到属于第一类的文件。 第二个意味着很长的手册,但是已经足够了。 一切都会好起来的,但是您需要知道绝对准确的结构,并且(当然)在这种情况下,我不得不使用频繁更改的表。 没有人记得字段的类型是否正在更改,或者是否添加了新列。
不幸的是,Debri City无法解决此问题,因此正在撰写本文。
切入点
3个月前的表结构与当前表结构不一致(也许是一个字段,但可能更多)。 表结构:
CREATE TABLE `table_1` ( `id` INT (11), `date` DATETIME , `description` TEXT , `id_point` INT (11), `id_user` INT (11), `date_start` DATETIME , `date_finish` DATETIME , `photo` INT (1), `id_client` INT (11), `status` INT (1), `lead__time` TIME , `sendstatus` TINYINT (4) );
在这种情况下,您需要提取:
id_point INT(11);id_user INT(11);date_start DATETIME;date_finish DATETIME。
为了恢复,使用了.ibd文件的字节分析,然后以更易读的形式进行了翻译。 由于找到了所需的内容,因此我们足以分析诸如int和datatime之类的数据类型,因此本文将仅对它们进行描述,但有时它们还将引用其他数据类型,这可以帮助解决其他类似事件。
问题1 :类型为DATETIME和TEXT的字段具有NULL值,并且只是在文件中跳过了它们,因此,在我的情况下无法确定恢复的结构。 在新列中,默认值为null,由于设置innodb_flush_log_at_trx_commit = 0,某些事务可能会丢失,因此必须花费额外的时间来确定结构。
问题2 :应该注意,通过DELETE删除的行将完全位于ibd文件中,但是它们的结构将不会使用ALTER TABLE进行更新。 结果,数据结构可能从文件的开头到结尾都不同。 如果您经常使用OPTIMIZE TABLE,则不太可能遇到类似的问题。
请注意 ,DBMS版本会影响数据的存储方式,此示例可能不适用于其他主要版本。 就我而言,使用的是Windows版本mariadb 10.1.24。 另外,尽管在mariadb中使用InnoDB表,但实际上它们是XtraDB ,这排除了该方法在InnoDB mysql中的适用性。
文件分析
在python中, bytes()数据类型以Unicode而不是通常的数字集显示数据。 尽管您可以考虑使用这种形式的文件,但是为了方便起见,可以通过将字节数组转换为常规数组(列表(example_byte_array))将字节转换为数字形式。 无论如何,两种方法都可用于分析。
查看几个ibd文件后,您可以找到以下内容:
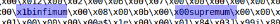
此外,如果将文件除以这些关键字,则将获得大部分平面数据块。 我们将使用infimum作为除数。
table = table.split("infimum".encode())
一个有趣的发现,对于数据量很少的表,在最小和最高之间,有一个指针指向该块中的行数。
 -第一行测试表
-第一行测试表
 -2行测试表
-2行测试表
行表[0]的数组可以跳过。 看了一下,我仍然找不到表的原始数据。 该块最有可能用于存储索引和键。
从表[1]开始并将其转换为数值数组,您已经注意到一些模式,即:

这些是存储在字符串中的int值。 第一个字节指示数字是正数还是负数。 就我而言,所有数字均为正。 从剩余的3个字节中,您可以使用以下功能确定数字。 剧本:
def find_int(val: str):
例如128,0,0,1 = 1或128,0,75,108 = 19308 。
该表有一个具有自动增量的主键,在这里您也可以找到它

比较测试表中的数据,发现DATETIME对象由5个字节组成,从153开始(最有可能表示年度间隔)。 由于DATTIME的范围是'1000-01-01'至'9999-12-31',我认为字节数可以变化,但就我而言,数据落在2016年至2019年这段时间内,因此我们假设5个字节就足够了。
为了确定没有秒的时间,编写了以下功能。 剧本:
day_ = lambda x: x % 64 // 2
一年零一个月,不可能编写出健康的工作函数,所以我不得不硬编码。 剧本:
ym_list = {'2016, 1': '153, 152, 64', '2016, 2': '153, 152, 128', '2016, 3': '153, 152, 192', '2016, 4': '153, 153, 0', '2016, 5': '153, 153, 64', '2016, 6': '153, 153, 128', '2016, 7': '153, 153, 192', '2016, 8': '153, 154, 0', '2016, 9': '153, 154, 64', '2016, 10': '153, 154, 128', '2016, 11': '153, 154, 192', '2016, 12': '153, 155, 0', '2017, 1': '153, 155, 128', '2017, 2': '153, 155, 192', '2017, 3': '153, 156, 0', '2017, 4': '153, 156, 64', '2017, 5': '153, 156, 128', '2017, 6': '153, 156, 192', '2017, 7': '153, 157, 0', '2017, 8': '153, 157, 64', '2017, 9': '153, 157, 128', '2017, 10': '153, 157, 192', '2017, 11': '153, 158, 0', '2017, 12': '153, 158, 64', '2018, 1': '153, 158, 192', '2018, 2': '153, 159, 0', '2018, 3': '153, 159, 64', '2018, 4': '153, 159, 128', '2018, 5': '153, 159, 192', '2018, 6': '153, 160, 0', '2018, 7': '153, 160, 64', '2018, 8': '153, 160, 128', '2018, 9': '153, 160, 192', '2018, 10': '153, 161, 0', '2018, 11': '153, 161, 64', '2018, 12': '153, 161, 128', '2019, 1': '153, 162, 0', '2019, 2': '153, 162, 64', '2019, 3': '153, 162, 128', '2019, 4': '153, 162, 192', '2019, 5': '153, 163, 0', '2019, 6': '153, 163, 64', '2019, 7': '153, 163, 128', '2019, 8': '153, 163, 192', '2019, 9': '153, 164, 0', '2019, 10': '153, 164, 64', '2019, 11': '153, 164, 128', '2019, 12': '153, 164, 192', '2020, 1': '153, 165, 64', '2020, 2': '153, 165, 128', '2020, 3': '153, 165, 192','2020, 4': '153, 166, 0', '2020, 5': '153, 166, 64', '2020, 6': '153, 1, 128', '2020, 7': '153, 166, 192', '2020, 8': '153, 167, 0', '2020, 9': '153, 167, 64','2020, 10': '153, 167, 128', '2020, 11': '153, 167, 192', '2020, 12': '153, 168, 0'} def year_month(x1, x2):
我敢肯定,如果您花费n倍的时间,那么这种误解可以得到纠正。
接下来,该函数从字符串返回日期时间对象。 剧本:
def find_data_time(val:str): val = [int(v) for v in val.split(", ")] day = day_(val[2]) hour = hour_(val[2], val[3]) minutes = min_(val[3], val[4]) year, month = year_month(val[1], val[2]) return datetime(year, month, day, hour, minutes)
可以从int,int,datetime,datetime中检测到频繁重复的值 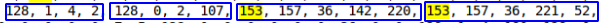 看来这就是您所需要的。 而且,这样的序列每行不重复两次。
看来这就是您所需要的。 而且,这样的序列每行不重复两次。
使用正则表达式,我们找到了必要的数据:
fined = re.findall(r'128, \d*, \d*, \d*, 128, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*, 153, 1[6,5,4,3]\d, \d*, \d*, \d*', int_array)
请注意,通过该表达式进行搜索时,将无法在必填字段中确定NULL值,但就我而言,这并不重要。 之后我们遍历发现。 剧本:
result = [] for val in fined: pre_result = [] bd_int = re.findall(r"128, \d*, \d*, \d*", val) bd_date= re.findall(r"(153, 1[6,5,4,3]\d, \d*, \d*, \d*)", val) for it in bd_int: pre_result.append(find_int(bd_int[it])) for bd in bd_date: pre_result.append(find_data_time(bd)) result.append(pre_result)
实际上,结果数组中的所有数据都是我们需要的数据。 ### PS。###
我知道这种方法并不适合所有人,但本文的主要目标是提示采取措施,而不是解决所有问题。 我认为最正确的解决方案是开始研究mariadb本身的源代码,但是由于时间有限,当前的方法似乎是最快的。
在某些情况下,在分析了文件之后,您可以确定近似的结构并从上面的链接恢复标准方法之一。 它将更加正确,并减少问题。