您好,Habr亲爱的读者。 我叫Rustem,是哈萨克斯坦IT公司DAR的主要开发人员。 在本文中,我将告诉您使用Akka工具包进入事件源和CQRS模板之前需要了解的内容。
2015年左右,我们开始设计生态系统。 经过分析并基于对Scala和Akka的经验,我们决定停止使用Akka工具包。 我们已经成功地使用CQRS实现了事件来源模板的实现,而并非如此。 我想与读者分享这方面的专业知识。 我们将研究Akka如何实现这些模式,以及可用的工具,并讨论Akka的陷阱。 我希望阅读本文后,您将对使用Akka工具包的风险有更多的了解。
关于CQRS和事件采购的主题,撰写了许多有关Habré和其他资源的文章。 本文适用于已经了解CQRS和事件源的读者。 在本文中,我想重点介绍Akka。
域驱动设计
关于域驱动设计(DDD)的许多材料已经被撰写。 这种方法既有反对者,也有支持者。 我想补充一点,如果您决定切换到事件源和CQRS,那么学习DDD并不是多余的。 此外,所有Akka工具都具有DDD理念。
实际上,事件源和CQRS只是称为域驱动设计的全局图的一小部分。 在设计和开发时,您可能会遇到许多有关如何正确实现这些模板并将其集成到生态系统中的问题,并且了解DDD将使您的生活更轻松。
在本文中,实体(由DDD表示实体)一词将表示具有唯一标识符的Persistence Actor。
为什么选择Scala?
经常有人问我们为什么使用Scala,而不是Java。 原因之一是Akka。 用Scala语言编写的框架本身,并支持Java语言。 在这里我必须说, .NET上也有一个实现,但这是另一个主题。 为了不引起讨论,我不会写为什么Scala比Java更好或更差。 我只告诉您几个例子,我认为Scala在使用Akka时比Java具有优势:
- 不可变的对象。 在Java中,您需要自己编写不可变的对象。 相信我,不断编写最终参数并不容易,也不是很方便。 在Scala
case class ,内置copy功能已使case class不可变 - 编码样式。 当用Java实现时,您仍将以Scala风格(即功能上)进行编写。
这是Scala和Java中actor的示例实现:
Scala:
object DemoActor { def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber)) } class DemoActor(magicNumber: Int) extends Actor { def receive = { case x: Int => sender() ! (x + magicNumber) } } class SomeOtherActor extends Actor { context.actorOf(DemoActor.props(42), "demo")
Java:
static class DemoActor extends AbstractActor { static Props props(Integer magicNumber) { return Props.create(DemoActor.class, () -> new DemoActor(magicNumber)); } private final Integer magicNumber; public DemoActor(Integer magicNumber) { this.magicNumber = magicNumber; } @Override public Receive createReceive() { return receiveBuilder() .match( Integer.class, i -> { getSender().tell(i + magicNumber, getSelf()); }) .build(); } } static class SomeOtherActor extends AbstractActor { ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo");
(示例取自此处 )
请注意使用Java语言示例实现createReceive()方法。 在内部,通过ReceiveBuilder工厂实现了模式匹配。 receiveBuilder()是Akka提供的一种支持lambda表达式的方法,即Java中的模式匹配。 在Scala中,这是本地实现的。 同意,Scala中的代码更短,更易于阅读。
- 文档和示例。 尽管官方文档中有Java实例,但在Internet上,几乎所有实例都在Scala中。 同样,您可以更轻松地在Akka库的源代码中导航。
在性能方面,Scala和Java之间没有区别,因为一切都在JVM中进行。
贮藏
在使用Akka Persistence实现事件源之前,建议您预先选择一个用于永久数据存储的数据库。 基础的选择取决于系统的要求,您的需求和偏好。 数据既可以存储在NoSQL和RDBMS中,也可以存储在文件系统中,例如Google的 LevelDB。
请务必注意,Akka Persistence不负责从数据库中写入和读取数据,而是通过必须实现Akka Persistence API的插件来完成的。
选择用于存储数据的工具后,您需要从列表中选择一个插件 ,或者自己编写。 第二种选择,我不建议为什么重新发明轮子。
对于永久数据存储,我们决定留在Cassandra。 事实是我们需要一个可靠,快速且分布式的基础。 此外,Typesafe本身也随插件一起提供 ,该插件完全实现了Akka Persistence API 。 它会不断更新,与其他版本相比,Cassandra插件编写了更完整的文档。
值得一提的是,该插件还存在一些问题。 例如,仍然没有稳定的版本(在撰写本文时,最新版本为0.97)。 对于我们来说,使用此插件时遇到的最大麻烦是读取某些实体的持久查询时事件丢失。 要获得完整的图片,下面是CQRS图表:
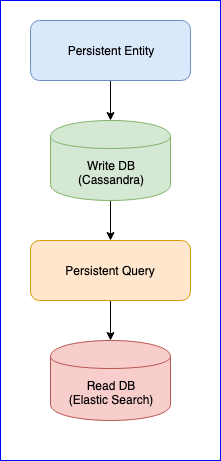
持久实体使用一致的哈希算法(例如10个分片)将实体事件分布到标签中:
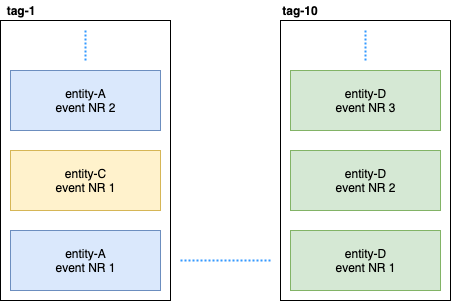
然后,Persistent Query订阅这些标签并启动将数据添加到Elastic Search的流。 由于Cassandra位于群集中,因此事件将分散在各个节点上。 一些节点可能会下垂,并且响应速度会比其他节点慢。 不能保证您会严格按照顺序接收事件。 为了解决此问题,实现了插件,以便如果它接收到无序事件(例如, entity-A event NR 2 ,则它会等待一段时间以等待初始事件,如果未接收到该事件,它将简单地忽略此实体的所有事件。 即使这样,也有关于Gitter的讨论。 如果有人感兴趣,您可以阅读@kotdv和插件开发人员之间的对应关系: Gitter
如何解决这种误解:
- 您需要将插件更新为最新版本。 在最新版本中,Typesafe开发人员解决了许多与最终一致性有关的问题。 但是,我们仍在等待稳定的版本
- 已为负责接收事件的组件添加了更精确的设置。 您可以尝试增加无序事件的超时时间,以使插件更可靠地运行:c
assandra-query-journal.events-by-tag.eventual-consistency.delay=10s - 按照DataStax的建议配置Cassandra。 放入垃圾收集器G1并为Cassandra分配尽可能多的内存。
最后,我们解决了事件丢失的问题,但是现在持久性查询方面存在稳定的数据延迟(从五秒到十秒)。 决定不再使用用于分析的数据的方法,在速度很重要的地方,我们手动在总线上发布事件。 最主要的是选择适当的机制来处理或发布数据:至少一次或最多一次。 在这里可以找到Akka的详尽描述。 对于我们来说,保持数据的一致性非常重要,因此,在将数据成功写入数据库之后,我们引入了一种过渡状态,该状态控制着数据在总线上的成功发布。 以下是示例代码:
object SomeEntity { sealed trait Event { def uuid: String } case class DidSomething(uuid: String) extends Event /** * , . */ case class LastEventPublished(uuid: String) extends Event /** * , . * @param unpublishedEvents – , . */ case class State(unpublishedEvents: Seq[Event]) object State { def updated(event: Event): State = event match { case evt: DidSomething => copy( unpublishedEvents = unpublishedEvents :+ evt ) case evt: LastEventPublished => copy( unpublishedEvents = unpublishedEvents.filter(_.uuid != evt.uuid) ) } } } class SomeEntity extends PersistentActor { … persist(newEvent) { evt => updateState(evt) publishToEventBus(evt) } … }
如果由于某种原因无法发布事件,则在SomeEntity的下一次启动时,它将知道DidSomething事件未到达总线,并将尝试重新发布数据。
序列化器
序列化是使用Akka时同样重要的一点。 他有一个内部模块-Akka序列化 。 在参与者之间交换消息以及通过Persistence API存储消息时,该模块用于序列化消息。 默认情况下,使用Java序列化程序,但建议使用另一个序列化程序。 问题是Java序列化程序速度很慢并且占用大量空间。 有两种流行的解决方案-JSON和Protobuf。 JSON虽然很慢,但是更易于实现和维护。 如果需要最小化序列化和数据存储的成本,可以在Protobuf停下来,但是开发过程会变慢。 除了域模型,您还必须编写另一个数据模型。 不要忘记数据版本控制。 准备好不断编写域模型和数据模型之间的映射。
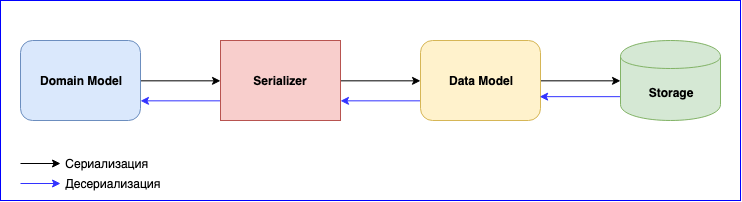
添加了一个新事件-写映射。 更改了数据结构-编写新版本的数据模型并更改映射功能。 不要忘了串行器的测试。 通常,会有很多工作要做,但是最终您将获得松耦合的组件。
结论
- 仔细研究并为自己选择合适的基础和插件。 我建议选择一个维护良好且不会停止开发的插件。 该领域是一个相对较新的领域,仍有许多缺陷尚待解决
- 如果选择分布式存储,则必须自己或最多忍受10秒的延迟来解决问题。
- 序列化的复杂性。 您可以牺牲速度并停止使用JSON,或者选择Protobuf并编写许多适配器并支持它们。
- 该模板有很多优点,它们是组成一个大型系统的松散耦合组件和独立开发团队。