可以在
此链接上找到完整的俄语课程。
此链接提供原始英语课程。
 每2-3天安排一次新的讲座。
每2-3天安排一次新的讲座。Udacity首席执行官Sebastian Trun访谈
“您好,我是Paige,您今天是我的客人,Sebastian。”
-嗨,我是塞巴斯蒂安!
-...一个拥有令人难以置信的职业的男人,成功地做了很多令人惊奇的事情! 您是Udacity的联合创始人,创建了Google X,还是斯坦福大学的教授。 在您的整个职业生涯中,您一直在进行不可思议的研究和深度学习。 是什么使您最满意,以及您在哪个领域获得的最高成就回报?
-坦白说,我真的很喜欢在硅谷! 我喜欢和比我聪明得多的人在一起,而且我一直认为技术是一种以各种方式改变游戏规则的工具-从教育到物流,医疗保健等。 所有这些变化是如此之快,人们非常渴望成为这些变化的参与者,并加以观察。 您环顾四周,并了解到周围的大多数事物都无法正常工作-您可以随时发明新事物!
-嗯,这是非常乐观的技术观点! 您职业生涯中最大的尤里卡是什么?
-主啊,有很多! 我记得有一天,拉里·佩奇(Larry Page)打电话给我,建议创建可以在加利福尼亚所有街道上行驶的自动驾驶汽车。 当时我被认为是专家,在我当中我是排名很高的人,我就是那个说“不,这不可能做到”的人。 之后,拉里说服了我,从原则上讲,有可能做到这一点,您只需开始尝试即可。 而我们做到了! 在这一刻,我意识到甚至专家都错了,说“不”,我们是100%悲观的。 我认为我们应该对新事物更加开放。
-举例来说,如果拉里·佩奇(Larry Page)打电话给您,并说:“嘿,做一些很棒的事情,例如Google X”,您会得到一些很棒的事情!
-是的,这是肯定的,无需抱怨! 我的意思是,所有这些都是在实现方式上经过大量讨论的过程。 我真的很幸运能在Google X和其他项目上工作,并为此感到自豪。
-太棒了! 因此,本课程全部关于使用TensorFlow。 您是否有使用TensorFlow的经验,或者对它熟悉(听说过)?
-是的! 我真的很喜欢TensorFlow! 在我自己的实验室中,我们经常使用它很多,基于TensorFlow的最重要的作品之一是大约两年前发布的。 我们了解到,iPhone和Android可以比世界上最好的皮肤科医生更有效地检测皮肤癌。 我们在《自然》杂志上发表了研究成果,这在医学界引起了轰动。
-听起来很棒! 所以您知道并喜欢TensorFlow,这本身就是很棒的! 您已经使用过TensorFlow 2.0吗?
-不,很遗憾,我还没有时间。
-他会很棒! 本课程的所有学生都将使用此版本。
-我好羡慕他们! 我一定会尝试的!
-太好了! 在我们的课程中,有很多学生一生中从未使用过“完全”一词从事过机器学习。 对于他们来说,这个领域可能是新的,也许对于编程本身的人来说将是新的。 您对他们有什么建议?
-我希望他们保持开放-对新想法,新技术,新解决方案,新职位。 机器学习实际上比编程容易。 在编程过程中,您需要考虑源数据中的每种情况,并为其调整程序逻辑和规则。 此时,使用TensorFlow和机器学习,您实际上是使用示例训练计算机,让计算机自己找到规则。
-这真是有趣! 我迫不及待地想告诉这门课程的学生更多有关机器学习的知识! 塞巴斯蒂安(Sebastian),谢谢您今天抽出宝贵时间来找我们!
-谢谢! 保持联系!
什么是机器学习?
因此,让我们从以下任务开始-给定输入和输出值。

输入值为0时,输出值为32;输入值为8时,输出值为46.4。 当输入值为15时,输出值为59,依此类推。
请仔细看一下这些值,然后让我问一个问题。 如果我们输入38,您能确定输出是什么吗?

如果您回答100.4,那么您是对的!

那么,我们如何解决这个问题呢? 如果仔细看一下这些值,可以发现它们与表达式相关:

其中C-摄氏度(输入值),F-华氏度(输出值)。
您的大脑刚刚完成的工作-比较输入值和输出值,并发现它们之间的通用模型(连接,依赖性)-这就是机器学习所做的。
基于输入和输出值,机器学习算法将找到合适的算法将输入值转换为输出值。 可以表示如下:

让我们来看一个例子。 想象一下,我们想开发一个程序,使用公式
F = C * 1.8 + 32将摄氏温度转换为华氏温度。

从传统软件开发的角度来看,该解决方案可以使用以下功能以任何编程语言实现:

那我们有什么呢? 该函数采用C的输入值,然后使用显式算法计算F的输出值,然后返回计算出的值。

另一方面,在机器学习方法中,我们只有输入和输出值,而没有算法本身:
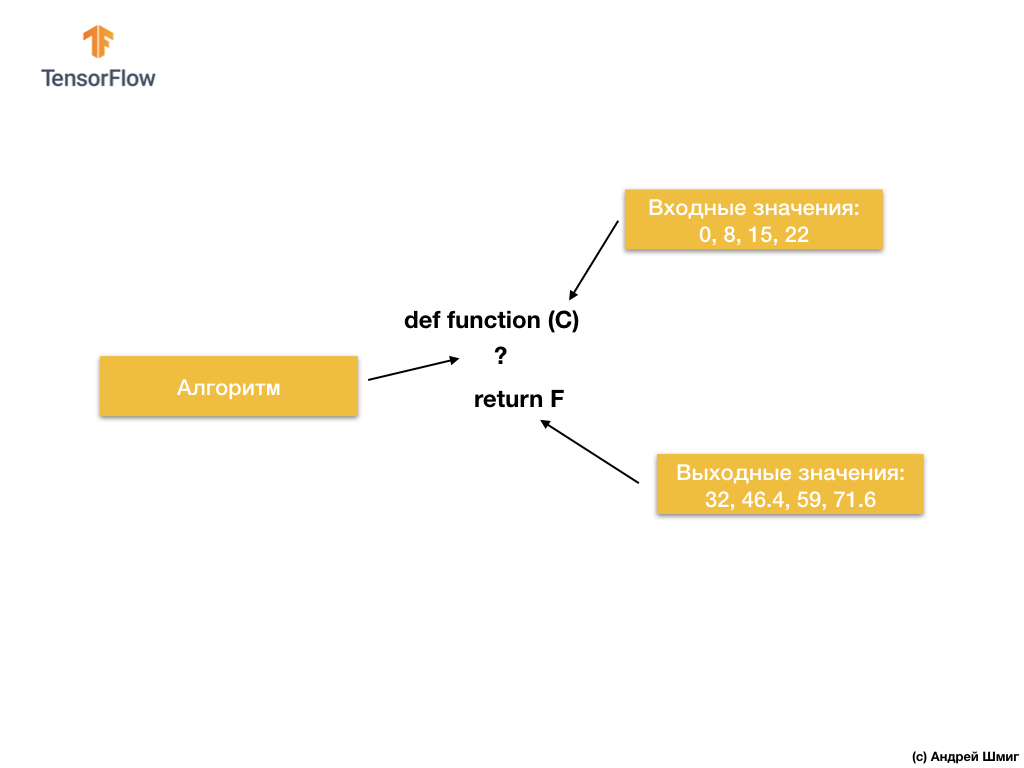
机器学习方法依赖于使用神经网络来查找输入和输出值之间的关系。

您可以将神经网络视为一堆层,每个层都由先前已知的数学(公式)和内部变量组成。 输入值进入神经网络并经过神经元层的堆栈。 在通过图层时,输入值会根据数学(给定的公式)和图层内部变量的值进行转换,从而产生输出值。
为了使神经网络能够学习并确定输入和输出值之间的正确关系,我们需要对其进行训练-进行训练。
我们通过反复尝试将输入值与输出值进行匹配来训练神经网络。

在训练过程中,将内部变量的值“拟合”(选择)在神经网络的各层中,直到网络学习生成对应的输入值的对应输出值为止。
稍后我们将看到,为了训练神经网络并允许其选择内部变量的最合适值,执行了数千或数万次迭代(训练)。

作为了解机器学习的简化版本,您可以将机器学习算法想象为选择内部变量值的函数,以便正确的输入值对应于正确的输出值。
神经网络架构的类型很多。 但是,无论您选择哪种架构,培训期间内部的数学(将执行哪些计算和以什么顺序进行)都将保持不变。 在训练期间,内部变量(权重和偏移量)会发生变化,而不是改变数学。
例如,在从摄氏度转换为华氏度的任务中,该模型通过将输入值乘以某个数字(权重)并加上另一个值(偏移量)来开始。 模型训练在于为这些变量找到合适的值,而无需更改已执行的乘法和加法运算。
但是要考虑的一件很酷的事情! 如果您解决了将摄氏温度转换为华氏温度的问题(如视频和下面的文字所示),则您可能已经解决了这一问题,因为您已经具有有关如何将摄氏温度转换为华氏温度的经验或知识。 例如,您可能只知道0摄氏度对应于32华氏度。 另一方面,基于机器学习的系统没有先前的支持知识即可解决问题。 他们学会了不基于先前的知识并且完全没有解决这些问题。
足够的谈话-继续讲课的实际部分!
CoLab:将摄氏度转换为华氏度
俄语版的CoLab源代码和
英文版的CoLab源代码 。
基础知识:学习第一个模型
欢迎来到CoLab,我们将在这里训练我们的第一个机器学习模型!
我们将尝试保持所介绍材料的简洁性,并仅介绍工作所需的基本概念。 随后的CoLabs将包含更多高级技术。
我们要解决的任务是将摄氏度转换为华氏度。 转换公式如下:
当然,使用Python或任何其他可以直接计算的编程语言编写转换函数会更容易,但是在这种情况下,这不是机器学习的方法:)
相反,我们将可用的输入摄氏度(0、8、15、22、38)和它们对应的华氏度(32、46、59、72、100)馈入TensorFlow输入。 然后,我们将以与上述公式大致相对应的方式训练模型。
导入依赖
我们导入的第一件事是
TensorFlow 。 在这里和下面,我们将其简称为
tf 。 我们还配置了日志记录级别-仅错误。
接下来,将
NumPy导入为
np 。
Numpy帮助我们将数据显示为高性能列表。
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf tf.logging.set_verbosity(tf.logging.ERROR) import numpy as np
培训数据准备
正如我们前面所看到的,与老师一起使用的机器学习技术是基于寻找一种将输入数据转换为输出的算法的。 由于此CoLab的任务是创建一个可以产生将摄氏度转换为华氏度的结果的模型,因此我们将创建两个列表
celsius_q和
celsius_q ,我们在训练模型时会使用它们。
celsius_q = np.array([-40, -10, 0, 8, 15, 22, 38], dtype=float) fahrenheit_a = np.array([-40, 14, 32, 46, 59, 72, 100], dtype=float) for i,c in enumerate(celsius_q): print("{} = {} ".format(c, fahrenheit_a[i]))
-40.0 = -40.0
-10.0 = 14.0
0.0 = 32.0
8.0 = 46.0
15.0 = 59.0
22.0 = 72.0
38.0 = 100.0
一些机器学习术语:
- 属性是模型的输入值。 在这种情况下,单位值为摄氏度。
- 标签是我们的模型预测的输出值。 在这种情况下,单位值为华氏度。
- 一个示例是一对用于训练的输入输出值。 在这种情况下,这是在一定索引下来自
celsius_q和celsius_q的一对值,例如(22,72)。
建立模型
接下来,我们创建一个模型。 我们将使用最简化的模型-全连接网络(
Dense网络)的模型。 由于任务非常琐碎,因此网络也将由具有单个神经元的单层组成。
建立网络
我们将命名层
l0 (层和零),并通过使用以下参数初始化
tf.keras.layers.Dense创建它:
input_shape=[1] -此参数确定输入参数的尺寸-单个值。 具有单个值的1×1矩阵。 由于这是第一(也是唯一)层,因此输入数据的维度对应于整个模型的维度。 唯一的值是代表摄氏度的浮点值。units=1此参数确定层中神经元的数量。 神经元的数量决定了将使用多少内部层变量来训练以找到问题的解决方案。 由于这是最后一层,因此它的尺寸等于结果的尺寸-模型的输出值-代表华氏度的单个浮点数。 (在多层网络中, input_shape层的大小和形状必须与下一层的大小和形状匹配)。
l0 = tf.keras.layers.Dense(units=1, input_shape=[1])
将图层转换为模型
一旦定义了图层,就需要将其转换为模型。
Sequential模型将图层列表按其应用顺序(从输入值到输出值)作为参数。
我们的模型只有一层
l0 。
model = tf.keras.Sequential([l0])
注意事项通常,您会在模型函数中直接遇到层的定义,而不是它们的初步描述和后续使用:
model = tf.keras.Sequential([ tf.keras.layers.Dense(units=1, input_shape=[1]) ])
我们编译具有损失和优化功能的模型
在训练之前,必须编译(组装)模型。 进行培训时,您需要:
- 损失函数 -一种测量预测值与期望输出值的距离的方法(可测量的差异称为“损失”)。
- 优化功能 -一种调整内部变量以减少损失的方法。
model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1))
在模型训练过程中使用损失函数和优化函数(
model.fit(...) )在每个点执行初始计算,然后优化值。
在模型中,计算电流损耗以及随后改善这些值的操作正是训练(一次迭代)。
在训练期间,优化功能用于计算对内部变量值的调整。 目的是在模型中以这种方式调整内部变量的值(实际上,这是一个数学函数),以便它们尽可能接近地反映将摄氏度转换为华氏度的现有表达式。
TensorFlow使用数值分析来执行这些类型的优化操作,而所有这些复杂性都不在我们的视线之内,因此在本课程中我们将不再赘述。
了解这些选项的有用之处:
此示例中使用的损失函数(标准误差)和优化函数(Adam)是此类简单模型的标准,但除此之外,还有许多其他可用的模型。 在此阶段,我们不在乎这些功能如何工作。
您应该注意的是优化函数,参数是
learning rate系数,在我们的示例中为
0.1 。 这是调整变量内部值时使用的步长。 如果值太小,将需要太多的训练迭代来训练模型。 太多-准确性下降。 为学习率系数找到一个好的值需要一些反复试验;通常在
0.01 (默认)到
0.1的范围内。
我们训练模型
通过
fit方法进行模型训练。
在训练期间,模型在输入处接收摄氏度,使用内部变量的值(称为“权重”)执行转换,并返回必须与华氏度相对应的值。 由于权重的初始值是任意设置的,因此结果值将与正确值相差甚远。 使用损失函数计算期望结果与实际值之间的差异,优化函数确定应如何调整权重。
计算,比较和调整的此循环在
fit方法中控制。 第一个参数是输入值,第二个参数是所需的输出值。
epochs参数确定此训练周期应完成多少次。
verbose参数控制日志记录的级别。
history = model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False) print(" ")
在下面的视频中,我们将深入探讨这一切的工作原理以及“引擎盖下”的完全连接的层(
Dense层)的精确度。
显示培训统计数据
fit方法返回一个对象,该对象包含有关每次后续迭代的损耗变化信息。 我们可以使用该对象来构建适当的损失时间表。 高损耗意味着模型预测的
fahrenheit_a与
fahrenheit_a数组中的真实值相去甚远。
为了可视化,我们将使用
Matplotlib 。 如您所见,我们的模型从一开始就非常迅速地改进,然后稳定而缓慢地改进,直到结果在训练结束时变得“接近”-完美。
import matplotlib.pyplot as plt plt.xlabel('Epoch') plt.ylabel('Loss') plt.plot(history.history['loss'])

我们使用该模型进行预测。
现在我们有了一个模型,该模型已经根据输入值
celsius_q和输出值
celsius_q进行训练,以确定它们之间的关系。 我们可以使用预测方法来计算华氏度,而以前我们不知道该华氏度。
例如,摄氏100.0度是多少? 在运行下面的代码之前,请尝试猜测。
print(model.predict([100.0]))
结论:
[[211.29639]]
正确答案是100×1.8 + 32 = 212,因此我们的模型做得很好!
复习- 我们使用
Dense层创建了一个模型。 - 我们用3500个示例(7个值对,500个训练迭代)训练了她
我们的模型调整了
Dense层中内部变量(权重)的值,以使正确的华氏度值返回到任意摄氏度输入值。
我们看一下重量
让我们显示
Dense层的内部变量的值。
print(" : {}".format(l0.get_weights()))
结论:
: [array([[1.8261501]], dtype=float32), array([28.681389], dtype=float32)]
第一个变量的值接近〜1.8,第二个变量的值接近〜32。 这些值(1.8和32)是将摄氏度转换为华氏度的公式中的直接值。
这确实非常接近公式中的实际值! 我们将在随后的视频中更详细地考虑这一点,在该视频中我们展示了
Dense层的工作原理,但是现在您只需要知道具有单个输入和输出的一个神经元包含简单的数学
y = mx + b (作为等式直接),这不过是我们将摄氏度转换为华氏度的公式,
f = 1.8c + 32 。
由于表示形式相同,因此模型的内部变量的值应收敛到实际公式中显示的值,该值最终发生。
由于存在附加的神经元,附加的输入值和输出值,公式变得稍微复杂一些,但本质保持不变。
一点实验
好玩! 如果我们用更多的神经元创建更多的
Dense层,又将包含更多的内部变量,会发生什么?
l0 = tf.keras.layers.Dense(units=4, input_shape=[1]) l1 = tf.keras.layers.Dense(units=4) l2 = tf.keras.layers.Dense(units=1) model = tf.keras.Sequential([l0, l1, l2]) model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1)) model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False) print(" ") print(model.predict([100.0])) print(" , 100 {} ".format(model.predict([100.0]))) print(" l0: {}".format(l0.get_weights())) print(" l1: {}".format(l1.get_weights())) print(" l2: {}".format(l2.get_weights()))
结论:
[[211.74748]] , 100 [[211.74748]] l0: [array([[-0.5972079 , -0.05531882, -0.00833384, -0.10636603]], dtype=float32), array([-3.0981746, -1.8776944, 2.4708805, -2.9092448], dtype=float32)] l1: [array([[ 0.09127654, 1.1659832 , -0.61909443, 0.3422218 ], [-0.7377194 , 0.20082018, -0.47870865, 0.30302727], [-0.1370897 , -0.0667181 , -0.39285263, -1.1399261 ], [-0.1576551 , 1.1161333 , -0.15552482, 0.39256814]], dtype=float32), array([-0.94946504, -2.9903848 , 2.9848468 , -2.9061244 ], dtype=float32)] l2: [array([[-0.13567649], [-1.4634581 ], [ 0.68370366], [-1.2069695 ]], dtype=float32), array([2.9170544], dtype=float32)]
您可能已经注意到,当前模型还能够很好地预测华氏度的相应程度。 但是,如果我们逐层查看神经元的内部变量(权重)的值,则将看不到任何类似于1.8和32的值。 该模型增加的复杂性掩盖了将摄氏度转换为华氏度的“简单”形式。
保持联系,在下一部分中,我们将研究“引擎盖”下密集层的工作方式。
简要总结
恭喜你! 您刚刚训练了您的第一个模型。 在实践中,我们看到了该模型如何通过输入和输出值来学习如何将输入值乘以1.8,然后将其加32以得到正确的结果。

考虑到我们需要编写多少行代码,这确实令人印象深刻:
l0 = tf.keras.layers.Dense(units=1, input_shape=[1]) model = tf.keras.Sequential([l0]) model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1)) history = model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False) model.predict([100.0])
上面的示例是所有机器学习程序的总体计划。 您将使用类似的构造来创建和训练神经网络并解决后续问题。
培训过程
(
model.fit(...) ) , . , ,
, .
, , . , - : -, «» , . « » ( ) , . , « », «» ( ) — .
训练过程从“直接分布”模块开始,在该模块中,输入参数进入神经网络的输入,跟随隐藏的神经元,然后进入周末。然后,模型对输入值和内部变量应用内部转换以预测响应。在我们的示例中,输入值是摄氏温度,模型预测了相应的值,以华氏度为单位。 一旦预测了该值,就会计算出预测值与正确值之间的差。这种差异称为“损失”,是衡量模型运行情况的一种形式。损失值由损失函数计算,损失函数由调用方法时的参数之一确定
一旦预测了该值,就会计算出预测值与正确值之间的差。这种差异称为“损失”,是衡量模型运行情况的一种形式。损失值由损失函数计算,损失函数由调用方法时的参数之一确定model.compile(...)。在计算了损失值之后,调整神经网络所有层的内部变量(权重和位移)以最小化损失值,以便将输出值近似为正确的初始参考值。 这种优化过程称为梯度下降。调用该方法时,将使用特定的优化算法为每个内部变量计算一个新值
这种优化过程称为梯度下降。调用该方法时,将使用特定的优化算法为每个内部变量计算一个新值model.compile(...)。在上面的示例中,我们使用了优化算法Adam。本课程不需要了解培训过程的原理,但是,如果您好奇的话,可以在Google Crash课程中找到更多信息。(整个课程的翻译和实践部分在作者的出版计划中作了规定)。至此,您应该已经熟悉以下术语:- 属性:模型输入值;
- 示例:输入+输出对;
- 标签:模型输出值;
- 层:神经网络内连接在一起的节点的集合;
- 模型:您的神经网络的表示;
- 密集且完全连接:一层中的每个节点都连接到上一层中的每个节点。
- 权重和偏移:模型内部变量;
- 损失:模型的期望输出值与实际输出值之差;
- MSE : , , , .
- : , - ;
- : ;
- : «» ;
- : ;
- : ;
- : ;
- : , .
Dense-
, , .
. ? 3 , .
 回想一下,神经网络可以想象成一组层,每个层由称为神经元的节点组成。每个级别的神经元都可以连接到每个后续层的神经元。一层的每个神经元与下一层的每个其他神经元连接的层的类型称为完全连接(完全连接)或密集层(-
回想一下,神经网络可以想象成一组层,每个层由称为神经元的节点组成。每个级别的神经元都可以连接到每个后续层的神经元。一层的每个神经元与下一层的每个其他神经元连接的层的类型称为完全连接(完全连接)或密集层(- Dense层)。 因此,当我们在中使用完全连接的层时
因此,当我们在中使用完全连接的层时keras,我们会告知该层的神经元应连接到上一层的所有神经元。要创建上述神经网络,以下表达式对我们来说足够了: hidden = tf.keras.layers.Dense(units=2, input_shape=[3]) output = tf.keras.layers.Dense(units=1) model = tf.keras.Sequential([hidden, output])
因此,我们弄清楚了什么是神经元以及它们之间的关系。但是,完全连接的层实际上如何工作?为了了解那里实际发生的情况以及它们在做什么,我们需要“深入研究”并分解神经元的内部数学。 想象一下,我们的模型收到三个参数-
想象一下,我们的模型收到三个参数- 1, 2, 3和1, 2 3-网络的神经元。还记得我们说过神经元具有内部变量吗?因此,w *和b *是神经元的相同内部变量,也称为权重和位移。这些变量的值在学习过程中进行了调整,以获得将输入值与输出进行比较的最准确结果。 您绝对应该记住的是,神经元的内部数学保持不变。换句话说,在训练过程中,只有重量和位移发生变化。当您开始学习机器学习时,可能看起来很奇怪-它确实有效,但这就是机器学习的原理!让我们回到将摄氏温度转换为华氏温度的示例。
您绝对应该记住的是,神经元的内部数学保持不变。换句话说,在训练过程中,只有重量和位移发生变化。当您开始学习机器学习时,可能看起来很奇怪-它确实有效,但这就是机器学习的原理!让我们回到将摄氏温度转换为华氏温度的示例。 对于单个神经元,我们只有一个重量和一个位移。你知道吗这正是将摄氏度转换为华氏度的公式。如果用
对于单个神经元,我们只有一个重量和一个位移。你知道吗这正是将摄氏度转换为华氏度的公式。如果用w11value 1.8代替b1- 32,则得到最终的转换模型!如果我们从实际部分返回模型的结果,请注意以下事实:“重量”和“位移”指标的“校准”方式近似等于公式中的值。, . , , . ? , !
— , . .
, !
总结
在本课程中,我们学习了机器学习的基本方法,并学习了完全连接的层(Dense-layers)如何工作。您训练了第一个模型来将摄氏度转换为华氏度。您还学习了机器学习中使用的基本术语,例如属性,示例,标签。您除其他外,用Python编写了代码的主要行,这是任何机器学习算法的基础。您看到了几行代码,您可以使用TensorFlow和创建,训练和请求来自神经网络的预测Keras。...和标准号召性用语-注册,加号并分享:)
YouTube:https://youtube.com/channel/ashmig电报:https : //t.me/ashmigVK:https : //vk.com/ashmig