
最近,有几篇文章批评ImageNet,这可能是最著名的用于训练神经网络的图像集。
在第一篇文章中, 使用Imagebag-of-local特征模型逼近CNN在ImageNet上的效果出乎意料,作者采用了类似于word-of-words的模型,并将图像中的片段用作“ words”。 这些片段最多可以为9x9像素。 同时,在这样的模型上,完全没有关于这些碎片的空间排列的任何信息,作者的准确度为70%至86%(例如,常规ResNet-50的准确度为〜93%)。
在接受ImageNet训练的CNN偏向于纹理的第二篇文章中,作者得出的结论是ImageNet数据集本身以及人和神经网络感知图像的方式均对此有罪,并建议使用新的数据集-Stylized-ImageNet。
更详细地了解人们在图片中看到的内容以及哪些神经网络
影像网
ImageNet数据集是在李飞飞教授的努力下于2006年创建的,并一直发展到今天。 目前,它包含约1400万张图像,分别属于2万多个不同类别。
自2010年以来,在ImageNet大规模视觉识别挑战赛(ILSVRC)中使用了该数据集的一个子集,称为ImageNet 1K,具有约100万张图像和数千个类别。 在这项竞赛中,2012年,卷积神经网络AlexNet的top-1准确性为60%,top-5准确性为80%。
当他们提供新的网络体系结构时,正是在数据集的这个子集上,来自学术环境的人们衡量了他们的SOTA 。
关于此数据集的学习过程的一些知识。 我们将讨论学术环境中ImageNet上的培训协议。 也就是说,当本文显示某些SE块,ResNeXt或DenseNet网络的结果时,该过程看起来像这样:作为优化程序,网络学习90年代,学习速度每30倍和30年代降低10倍。选择权重衰减较小的普通SGD,在增强中仅使用RandomCrop和HorizontalFlip,通常将图片调整为224x224像素。
这是在ImageNet上进行训练的pytorch脚本示例。
袋网
让我们回到前面提到的文章。 首先,作者想要一个比普通的深度网络更易于解释的模型。 受功能包模型概念的启发,他们创建了自己的模型系列-BagNets。 以常用的ResNet-50网络为基础。
他们用ResNet-50中的1x1替换了一些3x3卷积,它们确保了最后一个卷积层上神经元的接受场显着减小,最多达到9x9像素。 因此,它们将可用于单个神经元的信息限制为整个图像的很小片段-几个像素的补丁。 应当注意,对于原始的ResNet-50,接收场的大小超过400像素,完全覆盖了图片,通常将其大小调整为224x224像素。
该补丁是模型可以从中提取空间数据的图像的最大片段。 在模型的最后,仅对所有数据进行了汇总,该模型完全无法知道每个补丁相对于其他补丁的位置。
总共测试了具有9x9、17x17和33x33感受野的三种网络变体。 而且,尽管完全缺乏空间信息,但此类模型在ImageNet上的分类中仍能够实现良好的准确性。 9x9补丁的前5个准确性为70%,17x17-80%,33x33-86%。 为了进行比较,ResNet-50 top-5的准确度约为93%。

该模型的结构如上图所示。 网络将每个从图像切出的qxqx3像素斑块转换为2048向量,然后将该向量馈送到线性分类器的输入,该线性分类器会为1000个分类中的每一个生成分数。 通过在2d数组中收集每个补丁的分数,您可以获得原始图像的每个类和每个像素的热图。 图像的最终分数是通过将每个类别的热图相加得出的。
某些类的热图示例:

如您所见,特定类的好处最大的贡献就是位于对象边缘的补丁。 来自后台的补丁几乎被忽略。 到目前为止,一切都很好。
让我们看一下最有用的补丁:

例如,作者参加了四节课。 对于它们中的每一个,选择2x7最重要的补丁(即,该类别的分数最高的补丁)。 7个色块的顶行仅取自相应类别的图像,底部则取自整个图像样本。
在这些图片中可以看到的是惊人的。 例如,对于ten类(ten,鱼),手指是特征。 是的,普通的人类手指在绿色背景上。 这是因为几乎所有此类摄影师的照片中都有一位渔夫,他实际上将这条鱼握在手中,炫耀着奖杯。
对于便携式计算机,其特征是字母键。 打字机键也计入此类。
书籍封面的一个特色是在彩色背景上的字母。 甚至可以将其刻在T恤或包包上。
看来这个问题不应该困扰我们。 由于它仅在接收领域非常有限的狭窄网络中是固有的。 但是,进一步,作者计算了分配给每个具有不同接收场的BagNet类的logit(最终softmax之前的网络输出)与具有较大接收场的VGG-16的logts之间的相关性。 他们发现她很高。
作者想知道BagNet是否包含有关其他网络如何做出决策的任何提示。
对于其中一项测试,他们使用了诸如图像加扰之类的技术。 其中包括使用基于gram矩阵的纹理生成器组成一张图片,其中保存了纹理,但是缺少空间信息。

VGG-16经过训练,可以处理普通的完整图片,可以很好地应对此类加扰的图片。 它的前五位准确性从90%下降到80%。 也就是说,即使具有较大接收场的网络仍然更喜欢记住纹理并忽略空间信息。 因此,它们的准确性在加扰图像上并没有严重下降。
作者进行了一系列实验,比较了图像的哪些部分对于BagNet和其他网络(VGG-16,ResNet-50,ResNet-152和DenseNet-169)最重要。 一切都暗示着其他网络,例如BagNet,都依赖于图像的小片段,并且在做出决策时也会犯同样的错误。 这对于不是很深的网络(例如VGG)尤其明显。
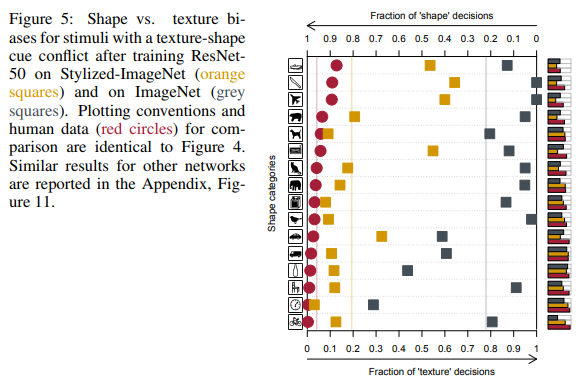
网络倾向于根据纹理进行决策的趋势与我们不同,喜欢形状的人(请参见下图)不同于我们,这促使第二篇文章的作者基于ImageNet创建了一个新的数据集。
程式化的ImageNet
首先,文章的作者使用样式转换创建了一组图像,其中一个图像中的形状(空间数据)和纹理相互矛盾。 然后,我们在16种类别的综合数据集上比较了不同架构的人员和深度卷积网络的结果。

在最右边的图中,人们看到了猫,网络-大象。

人与神经网络的结果比较。
如您所见,人们在将对象分配给特定类时依赖于对象的形状,纹理的神经网络。 在上图中,人们看到了猫,网络-大象。
是的,在这里您会发现网也有点正确的事实,例如,这可能是一头大象在近距离拍摄的,上面有一只心爱的猫的纹身。 但是事实是,网络在制定决策时的行为与人们的行为不同,因此作者考虑了这个问题并开始寻找解决问题的方法。
如上所述,仅依靠纹理,网络就可以以86%的top-5精度获得良好的结果。 这不是关于几个类(其中纹理有助于正确分类图像),而是关于大多数类。
问题出在ImageNet本身,因为稍后将证明网络能够学习表格,但不能做到这一点,因为纹理足以容纳这组数据,而负责纹理的神经元位于浅层,这更容易训练。
这次,作者使用了稍有不同的AdaIN快速样式转换机制,创建了一个新的数据集-Stylized ImageNet。 对象的形状取自ImageNet,而该比赛的一组纹理取自Kaggle 。 链接中提供了生成脚本。

此外,为简便起见,ImageNet将被称为IN ,风格化ImageNet将被称为SIN 。
作者采用ResNet-50和三个具有不同接收场的BagNet,并针对每个数据集在单独的模型上进行了训练。
这是他们所做的:
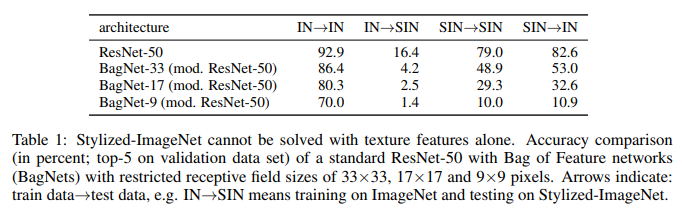
我们在这里看到的。 在IN上受过培训的ResNet-50在SIN上完全无能为力。 这部分确认了在进行IN训练时,网络会过分适应纹理并忽略对象的形状。 同时,经过SIN培训的ResNet-50可以完美应对SIN和IN。 也就是说,如果它被剥夺了一条简单的路径,那么网络将以一种困难的方式运转-它教导物体的形状。
BagNet终于开始表现出预期的效果,尤其是在小补丁上,因为它没有什么可依附的-SIN中只是缺少纹理信息。
在前面提到的16门课中,接受SIN培训的ResNet-50开始提供与人们给出的答案更相似的答案:
除了简单地在SIN上训练ResNet-50之外,作者还尝试在SIN和IN的混合集上训练网络,包括在纯IN上分别进行微调。

如您所见,使用SIN + IN进行训练时,结果不仅在主要任务(ImageNet上的图像分类)上得到了改善,而且在PASCAL VOC 2007数据集上检测对象的任务上也得到了改善。
此外,经过SIN训练的网络已变得更能抵抗数据中的各种噪声。
结论
即使在现在,2019年,在AlexNet成功使用七年之后,神经网络被广泛用于计算机视觉中,当ImageNet 1K实际上成为评估学术环境中模型性能的标准时,神经网络如何做出决策的机制仍不完全清楚。 以及训练这些网络的数据集如何影响这一点。
第一篇文章的作者试图阐明如何在具有易于接受的有限接收领域的功能包架构的网络中做出此类决策。 并且,通过比较BagNet和通常的深度神经网络的答案,我们得出的结论是,其中的决策过程非常相似。
第二篇文章的作者比较了人和神经网络如何感知形状和纹理相互矛盾的图片。 他们建议使用新的数据集Stylized ImageNet来减少感知差异。 作为奖励,提高了ImageNet上的分类准确性和第三方数据集检测的准确性。
可以得出以下主要结论:在图片中进行研究的网络能够记住对象的更高级别的空间属性,因此更喜欢一种更简单的方法来实现这一目标-过度拟合纹理。 如果他们训练的数据集允许这样做。
除了学术兴趣外,纹理过度拟合的问题对于我们所有人都非常重要,他们使用预训练的模型在任务中进行迁移学习。
所有这些对我们来说的重要结果是,您不应该相信通常在ImageNet上进行过预训练的模型的权重,因为对于大多数模型而言,它们使用的是相当简单的增强,绝不会有助于摆脱过度拟合。 如果可能的话,最好在嵌套中使用更严肃的增强或Stylized ImageNet + ImageNet训练模型。 为了始终能够比较哪一项最适合我们当前的任务。