
许多人习惯于在观看电影后在KinoPoisk或imdb上对电影进行评级,并且“在线购买”和“受欢迎的产品”部分都可以在任何在线商店中找到。 但是,建议的类型较少。 在本文中,我将讨论推荐系统推荐哪些任务,在哪里运行以及对谷歌搜索什么。
我们推荐什么?
如果我们想为用户推荐一条
舒适的
路线怎么办? 这次旅行的不同方面对不同的用户来说很重要:座位的可用性,旅行时间,交通,空调,从窗户欣赏美丽的景色。 这是一项不寻常的任务,但是很清楚如何构建这样的系统。
如果我们推荐
新闻怎么办? 新闻很快变得过时了-您需要向用户显示最新的文章,同时它们仍然是相关的。 有必要了解文章的内容。 已经更加困难了。
如果我们根据评论推荐
餐厅 ? 但是,我们不仅建议餐厅,还建议您尝试一些特定的菜肴。 您还可以向餐厅提供值得改进的建议。
如果我们
扩大任务范围并尝试回答以下问题:“最大的人群会感兴趣的产品是什么?”。 这变得非常不寻常,目前尚不清楚如何解决。
实际上,建议任务有多种变体,每种变体都有自己的细微差别。 您可以推荐完全出乎意料的事情。 我最喜欢的示例是推荐
Netflix上的预览 。

缩小任务
进行推荐音乐的熟悉和熟悉的任务。 我们到底要推荐什么?

在此拼贴上,您可以找到来自Spotify,Google和Yandex的各种建议的示例。
- 在“每日组合”中强调同类兴趣
- 个性化新闻发布雷达,推荐新发布,首映
- 自己选择喜欢的内容-每日播放列表
- 用户尚未听过的曲目的个人选择-Dejavu Discover Weekly
- 结合了前两点和新曲目的偏见-我感觉很幸运
- 位于库中,但尚未听到-缓存
- 您的热门歌曲2018
- 您在14岁时就听过并改变了您的口味的曲目-您的时间胶囊
- 您可能喜欢的曲目,但不同于用户通常听的曲目-口味破坏者
- 在您所在城市表演的艺术家的足迹
- 风格系列
- 活动和情绪选择
当然,您可以提出其他建议。 即使我们绝对有能力预测用户喜欢的曲目,但问题仍然在于应该以哪种形式和布局发布。
经典演出
在经典的问题陈述中,我们拥有的只是用户项目评分矩阵。 它非常稀疏,我们的任务是填写缺失的值。 通常,将预测等级的RMSE用作度量标准,但是,这并不完全正确,应该整体上考虑建议的特征,而不是预测特定数字的准确性。
如何评价质量?
在线评估
评估系统质量的最可取方法是在业务指标范围内对用户进行直接验证。 这可能是点击率,在系统上花费的时间或购买次数。 但是,针对用户的实验非常昂贵,而且我甚至不想对一小部分用户推出糟糕的算法,因此他们在进行在线测试之前会使用离线质量指标。
离线评估
排名指标(例如MAP @ k和nDCG @ k)通常用作质量指标。
在
MAP@k的上下文中的
Relevance是一个二进制值,在
nDCG@k的上下文中可以有一个评级量表。
但是,除了预测的准确性外,我们可能还对其他事情感兴趣:
- overage-推荐人发布的商品份额,
- 个性化-用户之间的推荐有何不同,
- 多样性-建议中产品的多样性。
总的来说,对指标有很好的审查,
您的推荐系统有多好? 推荐评估研究综述 。 可以在
推荐系统的新颖性和多样性指标的等级和相关性中找到形式化新颖性指标的示例。
资料
明确的反馈
等级矩阵是显式数据的示例。 喜欢,不喜欢,评分-用户本人已经清楚表达了他对商品的兴趣程度。 此类数据通常很少。 例如,在
Rekko Challenge的测试数据中,只有34%的用户至少拥有一个分数。
隐式反馈
有关隐式首选项的更多信息-视图,单击,添加书签,设置通知。 但是,如果用户观看了电影,这仅意味着在观看电影之前对他来说足够有趣。 我们不能直接得出关于这部电影是否受欢迎的结论。
学习损失函数
为了使用隐式反馈,我们提出了适当的教学方法。
贝叶斯个性化排名
原始文章 。
已知用户与哪些项目进行了交互。 我们假设这些是他喜欢的积极例子。 用户仍然没有与许多项目进行交互。 我们不知道其中哪个对用户感兴趣,而哪些对用户不感兴趣,但是我们当然知道并非所有这些示例都将是积极的。 我们进行了粗略的概括,并认为没有互动是一个负面的例子。
我们将对三元组{用户,正面项目,负面项目}进行抽样,如果负面示例的评分高于正面示例,则对模型进行罚款。
加权近似秩对
添加到以前的想法自适应学习率。 我们将基于寻找给定对{用户,正例}的负例时必须查看的样本数量来评估系统的培训,该系统对系统的评价高于正例。
如果我们是第一次发现这样的例子,那么罚款会很大。 如果您需要花费很长时间,那么该系统已经可以正常运行了,您不需要做太多的事情。
还有什么值得考虑的?
冷启动
一旦我们学会了对现有用户和产品做出预测,就会出现两个问题:-“如何推荐尚未见过的产品?” 和“我应该向尚未获得单一评分的用户推荐什么?”。 为了解决此问题,他们尝试从其他来源提取信息。 这可能是来自其他服务的有关用户的数据,注册期间的问卷调查,来自其内容的有关项目的信息。
在这种情况下,有些任务的冷启动状态是恒定的。 在基于会话的推荐中,您需要花时间了解用户在网站上的时间。 新商品不断出现在新闻或时尚产品的推荐者中,而旧商品很快就过时了。
长尾巴
如果我们以与之互动或给予正面评价的用户数量的形式来计算每个商品的受欢迎程度,那么我们经常会得到如下图所示的图表:
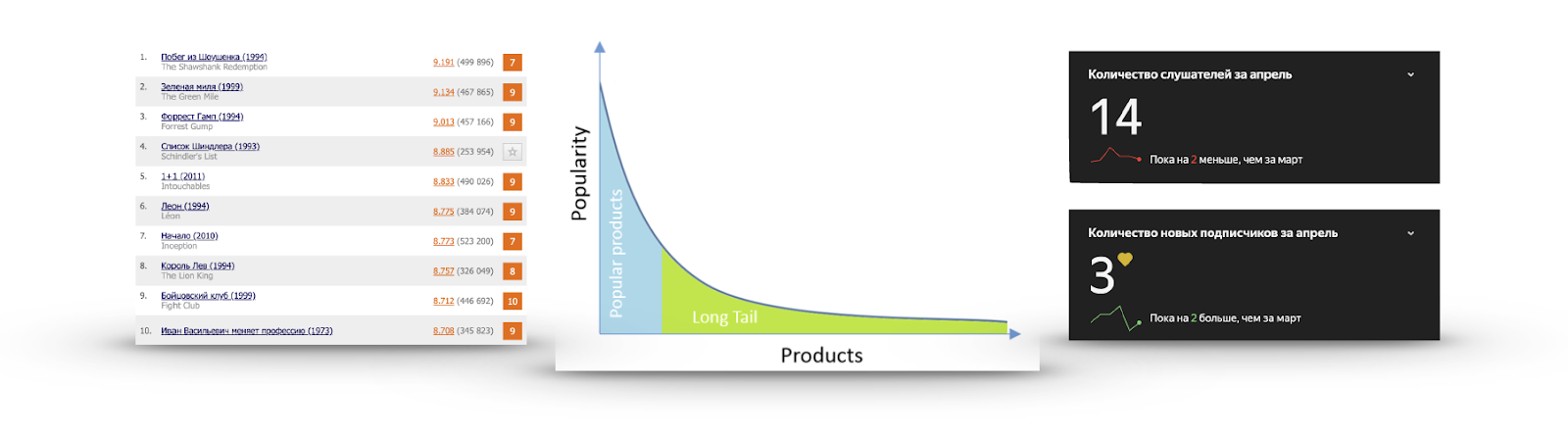
每个人都知道的东西很少。 推荐它们是没有意义的,因为用户很可能已经看过它们并且根本没有给出评分,或者知道它们并打算看到它们,或者已经坚决决定完全不观看。 我不止一次地观看了迅达列表的预告片,但我不会看到它。
另一方面,受欢迎程度正在迅速下降,几乎没有人看到过绝大多数商品。 从这一部分提出建议会更加有用:存在一些有趣的内容,用户不太可能发现自己。 例如,右边是Yandex.Music上我最喜欢的一个小组的收听统计数据。
探索与开发
假设我们确切知道用户喜欢什么。 这是否意味着我们应该推荐相同的东西? 感觉这样的建议很快就会变得无聊,有时值得展示一些新的东西。 当我们推荐的时候,剥削到底应该是什么。 如果我们尝试在建议中添加较不受欢迎的内容或以某种方式使其多样化-这就是探索。 我想平衡这些事情。
非个性化建议
最简单的选择是向所有人推荐相同的东西。
按人气排序
分数=(正面评分)-(负面评分)
您可以从喜欢中减去不喜欢的人并将其排序。 但是在这种情况下,我们不考虑它们的百分比比率。 感觉有50个不喜欢的200个喜好与1200个不喜欢和1050个不喜欢的不一样。
得分=(积极评分)/(总评分)
您可以将喜欢的次数除以不喜欢的次数,但是在这种情况下,我们不考虑评分的数量,并且评分为5分的产品将比平均评分为4.8的非常受欢迎的产品高。
如何
不按平均评分排序并考虑评分数量? 计算置信区间:“根据可用的估计,拥有95%的正面评级的真实份额的概率至少是什么?” 这个问题的答案是埃德温·威尔逊(Edwin Wilson)在1927年给出的。
-观察到的积极评价份额
-正态分布的1-alpha分位数
相容性
经常遇到的产品集的选择包括一整套模式挖掘任务:
定期模式挖掘 ,
顺序规则挖掘 ,
顺序模式挖掘 ,
高效工具集挖掘 ,
频繁项目集挖掘(篮子分析) 。 每个特定任务都有其自己的
方法 ,但是如果粗略地概括一下,用于查找频繁集的算法将执行简短的广度优先搜索,以尽量避免找出明显的错误选项。
稀有集合在给定的边界支持处被切除-集合在数据中出现的次数或频率。
突出显示频繁项集后,使用提升或置信度(a,b)/置信度(!A,b)指标评估其依赖关系的质量。 它们旨在消除错误的依赖关系。
例如,在杂货店的篮子里经常可以找到香蕉和罐头食品。 但这并不是特定的联系,而是香蕉本身很受欢迎,因此在寻找匹配项时应考虑到这一点。
个性化推荐
基于内容
基于内容的方法的思想是根据用户操作的历史记录为他创建一个对象空间中他的偏好向量,并推荐接近该向量的产品。
即,该项目应具有一些特征描述。 例如,这些可能是电影类型。 电影的喜好史形成了偏好的载体,
突出某些类型,避免其他类型。 通过比较用户向量和项目向量,可以进行排名并获得推荐。
协同过滤

协作过滤假定用户项评估矩阵。 这个想法是为每个用户找到最相似的“邻居”,并通过加权平均“邻居”的评分来填补特定用户的空白。
同样,您可以查看项目的相似性,相信相似的人会喜欢相似的项目。 从技术上讲,这只是考虑转置的估计矩阵。
用户对评分量表的使用方式有所不同-有人从未将其超过8,而有人使用了整个量表。 考虑到这一点很有用,因此可以不预测等级本身,而是预测平均等级的偏差。
或者,您可以预先归一化估计值。
矩阵分解
从数学上,
我们知道任何矩阵都可以分解为三个矩阵的乘积。 但是评级矩阵非常稀疏,99%是司空见惯的。 SVD不知道有什么差距。 用平均值填充它们不是很理想。 总的来说,我们对奇异值矩阵不太感兴趣-我们只想获取用户和对象的隐藏视图,当它们相乘时,将逼近真实评级。 您可以立即分解为两个矩阵。
如何处理通行证? 锤他们。 事实证明,您可以使用SGD或ALS通过RMSE指标训练近似的收视率,而完全忽略了遗漏。 第一个这样的算法是
Funk SVD ,它是在解决Netflix竞争的过程中于2006年发明的。
Netflix奖
Netflix奖 -这是一项重大事件,为推荐系统的发展提供了强大动力。 竞赛的目标是将现有的Cinematch RMSE推荐系统提高10%。 为此,当时提供了一个包含1亿个评分的大型数据集。 这项任务似乎并不那么困难,但是为了达到所需的质量,需要两次重新发现比赛-仅在比赛3年后才收到解决方案。 如果有必要获得15%的改善,那么可能无法通过所提供的数据来实现。
在比赛中,数据中发现了
一些有趣的特征。 该图显示了电影的平均评分,取决于它们在Netflix目录中出现的日期。 明显的差距与以下事实有关:Netflix目前从客观比例(一部坏电影,一部好电影)转换为主观电影(我不喜欢它,我真的很喜欢)。 人们在表达自己的评估而不是表征对象时没有那么严格。
此图显示了发行后平均电影收视率的变化。 可以看出,在2000天内,得分提高了0.2。 就是说,在这部电影不再是新电影之后,那些非常确信他会喜欢这部增加评分的电影的人开始观看它。
一等奖由AT&T的专家团队-Korbell获得。 经过2000个小时的工作并汇编了107种算法,他们设法提高了8.43%。
在这些模型中,有SVD和RBM的变体,它们本身提供了大部分输入。 其余的105种算法仅提高了指标的百分之一。 Netflix针对其数据量调整了这两种算法,但仍将其用作系统的一部分。
在比赛的第二年,两个团队合并,现在奖杯由Bellkor在BigChaos中获得。 他们总共攻击了207种算法,准确率又提高了百分之一百,达到0.8616。 所需的质量仍然没有达到,但是很明显,明年一切都应该解决。
第三年 与另一个团队结合,将Bellkor的Pragmatic Chaos重命名,并获得所需的质量,略逊于The Ensemble。 但这只是数据集的公共部分。
从隐藏的方面来看,事实证明这些团队的准确性恰好是小数点后第四位,因此获胜者是由20分钟的提交差异决定的。
Netflix向获奖者支付了承诺的百万美元,但从未
使用过最终的解决方案 。 事实证明,集成的实施成本太高,并且获益不多-毕竟,只有两种算法已经提供了大部分的准确性提高。 最重要的是-在2009年竞赛结束之时,除了租借DVD两年之外,Netflix已经开始从事流媒体服务。 他们还有许多其他任务和数据可以在系统中使用。 但是,他们的DVD邮件租赁服务仍然
为270万名满意的用户提供服务 。
神经网络
在现代推荐系统中,一个常见的问题是如何考虑各种显式和隐式信息源。 通常,会有有关用户或项目的其他数据,而您想使用它们。 神经网络是处理此类信息的好方法。
关于使用网络进行推荐的问题,您应该注意
基于深度学习的推荐系统的综述
:调查和新观点 。 它描述了将大量体系结构用于各种任务的示例。
有很多架构和方法。 重复的名称之一是
DSSM 。 我还想提到
专注协作过滤 。
ACF建议引入两个级别的衰减:
- 即使使用相同的评分,某些项目对您的偏好的贡献也会比其他项目更多。
- 项目不是原子的,而是由组件组成的。 有些对评估的影响大于其他。 由于存在喜欢的演员,这部电影才是有趣的。
多臂匪是近来最受欢迎的话题之一。 在
哈布雷(Habré)或《
媒介》(Medium)上的一篇文章中可以读到什么是多臂匪。
当应用于建议时,Contextual-Bandit任务将听起来像这样:“我们将用户和项目上下文向量提供给系统的输入,我们希望随着时间的流逝使所有用户进行交互(点击,购买)的可能性最大化,从而频繁地更新建议策略。” 这种表述自然解决了勘探与开发的难题,并允许您快速为所有用户推出最佳策略。
随着变压器体系结构的流行,也尝试在建议中使用它们。
具有自我注意的“下一项推荐”尝试结合长期和近期用户的偏好来改进推荐。
工具
建议不是CV或NLP这样受欢迎的主题,因此,要使用最新的网格体系结构,您要么必须自己实现它们,要么希望作者的实现非常方便且易于理解。 但是,一些基本工具仍然存在:
结论
推荐系统与关于填写评估矩阵的标准声明相去甚远,并且每个特定领域都会有自己的细微差别。 这带来了困难,但也增加了兴趣。 另外,可能很难将推荐系统与整个产品分开。 实际上,不仅项目列表很重要,而且提交的方法和上下文也很重要。 什么,如何,向谁以及何时推荐。 所有这些决定了与服务交互的印象。