 由DataArt解决方案架构师Lyudmila Dezhkina发布
由DataArt解决方案架构师Lyudmila Dezhkina发布大约六个月以来,我们的团队一直在使用Predictive Maintenance Platform,该系统应该可以预测可能的错误和设备故障。 该领域位于物联网和机器学习的交汇处,您必须在这里使用硬件,实际上是软件。 本文将讨论如何在AWS上使用Scikit-learn库构建无服务器ML。 我将谈论我们遇到的困难以及我用来节省时间的工具。
以防万一,关于你自己。我从事编程已经超过12年,在此期间,我参与了各种项目。 包括游戏,电子商务,高负载和大数据。 大约三年来,我一直参与与机器学习和深度学习相关的项目。
 看起来就像客户从一开始就提出的要求
看起来就像客户从一开始就提出的要求与客户的采访非常困难,主要是我们谈论了机器学习,我们被问到了很多算法和特定的个人经验。 但我不会谦虚-在这一部分中,我们最初非常了解。 第一个绊脚石是系统包含的硬件。 然而,我个人对铁的体验并没有那么多样化。
客户向我们解释:“看,我们有传送带。” 我立即在一家超市结帐处拿出一条传送带。 在那里可以教什么? 但是很快就很清楚,传送带一词隐藏了一个分拣中心,面积为300-400平方米。 米,实际上,那里有很多输送机。 也就是说,设备的许多元素需要连接在一起:传感器,机器人。 IoT和ML融合在一起的
“工业革命4.0”概念的经典插图。
预测性维护主题肯定会至少再增长两到三年。 每个输送机都分解为多个元素:从机器人或电动机将输送带移动到单独的轴承。 同时,如果这些部件中的任何一个发生故障,整个系统将停止运行,并且在某些情况下,一小时的空转输送机可能会花费一百万美元(这不是夸张!)。
我们的客户之一从事货物运输和物流:在此基础上,机器人在8分钟内卸下了40辆卡车。 这里没有延误,汽车必须按照非常严格的时间表来来去去,没有人在卸货过程中修理任何东西。 通常,在此基础上只有两三个人使用平板电脑。 但是,在另一个稍微不同的世界中,一切看起来都不那么时尚,戴着手套而没有计算机的机械师直接在物体上。
我们的第一个小型原型项目由大约90个传感器组成,一切正常,直到必须扩展该项目为止。 为了装备实际分拣中心的最小的独立部分,已经需要大约550个传感器。
PLC和传感器
可编程逻辑控制器-具有内置循环程序的小型计算机-最常用于使过程自动化。 实际上,在PLC的帮助下,我们从传感器获取了读数:例如,加速度和速度,电压水平,沿轴的振动,温度(在我们的示例中为17个指示器)。 传感器经常被误认为。 尽管我们的项目已经进行了8个月以上,但我们仍然拥有自己的实验室,我们在其中进行传感器实验,选择最合适的模型。 现在,例如,我们正在考虑使用超声波传感器。
就个人而言,我只有在访问客户的站点时才看到PLC。 作为开发人员,我以前从未遇到过它们,这非常令人不愉快:一旦我们在对话中深入研究了两相,三相和四相电机,我就开始失去线程。 大约80%的单词仍可理解,但一般含义固执地消失了。 通常,这是一个严重的问题,其根源在进入PLC编程时处于很高的门槛-微型计算机,您实际上可以做的事情至少花费200-300美元。 编程本身并不复杂,仅当传感器安装在实际的传送带或电机上时问题才会开始。
 37合1标准传感器组
37合1标准传感器组如您所知,传感器是不同的。 我们设法找到的最简单的商品起价为18美元。 主要特征-“带宽和分辨率”-传感器在一分钟内传输多少数据。 根据我自己的经验,我可以说,如果制造商声称每分钟有30个数据点,实际上它们的数量不可能超过15个。这也构成了一个严重的问题:这个话题很流行,有些公司正试图以此炒作赚钱。 我们测试了价值158美元的传感器,从理论上讲,其带宽可以简单地丢弃部分代码。 但实际上,它们竟然是这些相同设备(每台售价18美元)的绝对类似产品。
第一阶段:我们连接传感器,收集数据
实际上,该项目的第一阶段是硬件的安装,安装本身是一个漫长而乏味的过程。 这也是一门完整的科学-它收集的数据可能取决于将传感器连接到电动机或盒子的方式。 我们有一个案例,两个相同的传感器中的一个安装在盒子内部,另一个安装在外部。 逻辑建议内部温度应更高,但收集到的数据另有说明。 原来,系统出现了故障,但是当开发人员到达工厂时,他发现传感器不仅在盒子里,而且就在那里的风扇上。
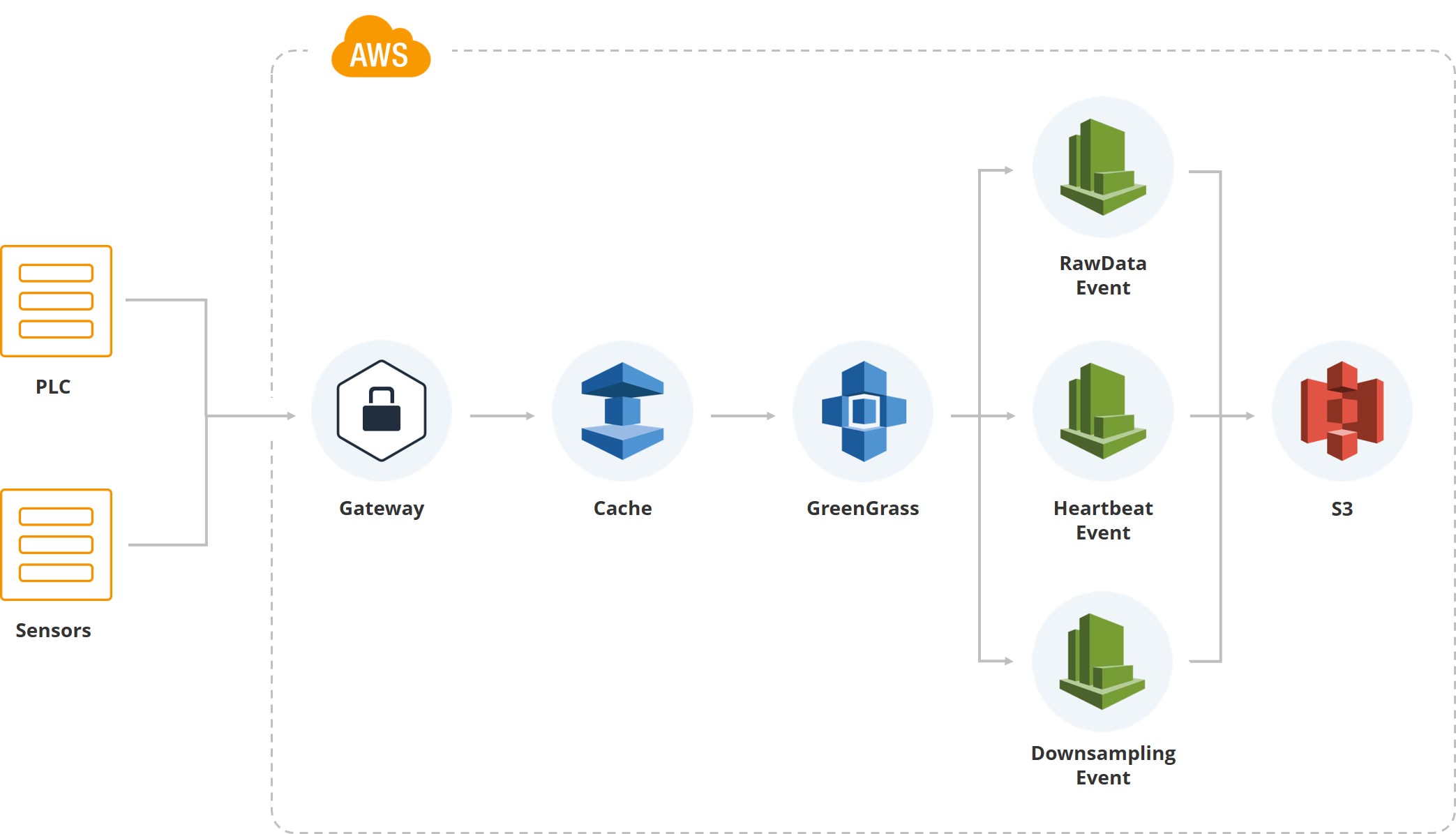
下图显示了第一个数据如何进入系统。 我们有一个网关,其中有PLC和传感器。 此外,当然,缓存-设备通常在移动卡上运行,并且所有数据都是通过移动Internet传输的。 由于客户的分拣中心之一位于经常发生飓风的区域,并且连接可能会中断,因此我们在网关上累积数据直到恢复数据。
接下来,我们使用来自Amazon的Greengrass服务,该服务在云系统(AWS)内发送数据。
一旦数据进入云内部,就会触发一系列事件。 例如,我们有一个原始数据事件,用于保存文件系统数据。 有一个“心跳”指示正常的系统性能。 有一个“下采样”,用于在UI上显示并用于处理(例如某个指标的每分钟平均值)。 也就是说,除了原始数据外,我们还对监视系统用户的屏幕上的数据进行了下采样。
原始数据以实木复合地板格式存储。 首先,我们选择了JSON,然后尝试了CSV,但最后得出的结论是,分析团队和开发团队都对“实木复合地板”感到满意。
实际上,该系统的第一个版本是基于DynamoDB构建的,我不想对此数据库说些不好的话。 只是,一旦我们获得了分析(应该由数学家来处理获得的数据),事实证明DynamoDB上的查询语言对他们来说太复杂了。 他们必须专门为ML和分析准备数据。 因此,我们选择了AWS中的查询编辑器Athena。 对我们来说,它的优点是它允许您读取Parquet数据,编写SQL并将结果收集到CSV文件中。 正是分析团队需要的。
第二阶段:我们要分析什么?
因此,我们从一个小对象中收集了大约3 GB的原始数据。 现在我们对温度,振动和轴向加速度了解很多。 因此,现在是时候让我们的数学家聚集起来,了解我们实际上是如何基于这些信息进行预测的。
目标是最大程度地减少设备停机时间。 人们只有在收到有关故障,漏油或地板上有水坑的信号时才进入可口可乐工厂。 一个机器人的成本从30,000美元开始,但几乎所有产品都基于它们
人们只有在收到有关故障,漏油或地板上有水坑的信号时才进入可口可乐工厂。 一个机器人的成本从30,000美元开始,但几乎所有产品都基于它们 大约有10,000人在特斯拉的六个工厂工作,而对于如此规模的生产来说,这是很少的。 有趣的是,梅赛德斯工厂的自动化程度更高。 显然,所有涉及的机器人都需要持续监控
大约有10,000人在特斯拉的六个工厂工作,而对于如此规模的生产来说,这是很少的。 有趣的是,梅赛德斯工厂的自动化程度更高。 显然,所有涉及的机器人都需要持续监控机器人越昂贵,其工作部件的振动就越少。 通过简单的动作,这可能不是决定性的,但是更细微的操作(例如在瓶子的颈部)要求将其最小化。 当然,必须不断监控昂贵汽车的振动水平。
节省时间的服务
我们在短短三个月内就启动了第一个安装,我认为它的速度很快。
 实际上,这些是可以节省开发工作的主要五点
实际上,这些是可以节省开发工作的主要五点我们减少时间表的第一件事是,大多数系统都是在AWS上构建的,可自行扩展。 一旦用户数量超过特定阈值,就会触发自动缩放,并且团队中的任何一个都不必花费时间。
我想提请注意两个细微差别。 首先,我们处理大量数据,在系统的第一个版本中,我们使用了流水线来进行备份。 一段时间后,数据变得太多了,为它们保留副本变得太昂贵了。 然后,我们仅将Raw数据保留在存储桶中为只读状态,禁止删除它们,并拒绝备份。
我们的系统涉及持续集成,以支持新站点,并且新安装不需要花费太多时间。
显然,实时是基于事件的。 当然,尽管由于某些事件发生两次或系统失去联系(例如由于天气条件)而引起困难,但这种情况仍然存在。
根据客户要求,数据加密在AWS中自动完成。 每个客户端都有自己的存储桶,我们根本不执行加密操作。
与分析师会面
我们收到了PDF格式的第一个代码,并要求实现一个或另一个模型。 直到我们开始接收.ipynb形式的代码之前,这令人震惊,但事实是分析人员是远离编程的数学家。 我们所有的操作都在云中进行,我们不允许下载数据。 所有这些观点共同促使我们尝试使用SageMaker平台。
SageMaker允许您开箱即用地使用大约80种算法;它包括以下框架:Caffe2,Mxnet,Gluon,TensorFlow,Pytorch,Microsoft认知工具套件。 目前,我们使用Keras + TensorFlow,但除Microsoft认知工具包之外的每个人都尝试了。 如此广泛的覆盖范围使我们不必限制自己的分析团队。

在最初的三到四个月中,人们在简单的数学帮助下完成了所有工作,实际上没有ML。 该系统的一部分是基于纯粹的数学定律,并且它是为统计数据而设计的。 也就是说,我们监视平均温度水平,如果发现温度超出刻度,则会触发警报。
然后进行模型训练。 一切看起来都很简单,因此似乎在实施开始之前。
建立,训练,部署...

我将简要描述我们如何摆脱困境。 查看第二列:我们收集数据,对其进行处理,对其进行清理,使用S3存储桶和Glue启动事件并创建“分区”。 我们将所有数据安排在雅典娜的分区中,这也是一个重要的细微差别,因为雅典娜是建立在S3之上的。 雅典娜本身很便宜。 但是,我们需要为读取数据并将其从S3中取出而付费,因为每个请求都可能非常昂贵。 因此,我们有一个很大的分区系统。
我们有一个停机时间。 还有Amazon EMR,可让您快速收集数据。 实际上,对于功能工程而言,在我们的云中,对于每个分析师,都提出了Jupyter Notebook-这是他们自己的实例。 他们直接在云本身中分析所有内容。
多亏了SageMaker,我们才能够跳过培训集群阶段。 如果我们不使用该平台,则必须在亚马逊上建立集群,而一名DevOps工程师将不得不遵循它们。 SageMaker允许使用该方法的参数,即Docker上的映像来引发集群,它仅用于指示您要使用的参数中的实例数。
此外,我们不必处理扩展。 如果我们要处理某种大型算法,或者迫切需要计算某些东西,可以启用自动缩放功能(这完全取决于您要使用CPU还是GPU)。
另外,我们所有的模型都是加密的:这也是SageMaker中的开箱即用-S3中的二进制文件。
模型部署
我们正在接近在环境中部署的第一个模型。 实际上,SageMaker允许您保存模型工件,但是就在这个阶段,我们有很多争议,因为SageMaker具有自己的模型格式。 我们想摆脱它,摆脱限制,所以我们的模型以pickle格式存储,以便我们甚至可以使用Keras,TensorFlow或其他东西(如果需要)。 尽管我们通过本地API使用了SageMaker的第一个模型。
SageMaker可让您分三个阶段简化工作。 每次尝试进行预测时,都必须启动某个过程,提供数据并获取预测值。 在需要自定义算法之前,一切都进行得很好。

分析人员知道他们有一个配置项和一个存储库。 CI存储库中有一个文件夹,其中应放置三个文件。 Serve.py是允许SageMaker提升Flask服务并与SageMaker本身通信的文件。 Train.py是带有train方法的类,他们必须将模型所需的所有内容放入其中。 最后,predict.py-在其帮助下,他们引发了此类,其中提供了一个方法。 有了访问权限,他们就可以从S3那里筹集各种资源-在SageMaker内部,我们有一个映像,可让您从界面上以编程方式运行任何内容(我们不限制它们)。
通过SageMaker,我们可以访问predict.py-内部图像只是一个Flask应用程序,它允许您使用特定参数调用预测或训练。 所有这些都与S3相关联,此外,它们还能够从Jupyter Notebook中保存模型。 也就是说,在Jupyter Notebook中,分析人员可以访问所有数据,并且可以进行某种试验。
在生产中,所有这些如下。 我们有用户,端点有预测值。 数据位于S3上并到达Athena。 每两个小时启动一次算法,该算法计算接下来两个小时的预测。 该时间步长是由于以下事实:在我们的案例中,大约6个小时的分析足以说明电机出了点问题。 即使在接通电源时,电机也会在5-10分钟内加热,并且不会出现急剧的跳动。
例如,在关键系统中,法航检查飞机涡轮时,预测速度为10分钟。 在这种情况下,准确性为96.5%。
如果我们发现出了点问题,则通知系统会打开。 然后,手表或其他设备上的许多用户之一接收到有关特定电动机行为异常的通知。 他去检查自己的状况。
管理笔记本实例
实际上,一切都很简单。 分析师开始工作,在Jupyter Notebook上启动了一个实例。 他获得了角色和会话,因此两个人无法编辑同一文件。 实际上,我们现在为每个分析师都有一个实例。
创建培训工作
SageMaker对培训工作有一定的了解。 其结果是,如果仅使用API(存储在S3上的二进制文件),则从提供的参数中获取模型。
sagemaker = boto3.client('sagemaker') sagemaker.create_training_job(**create_training_params) status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print(status) try: sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) finally: status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print("Training job ended with status: " + status) if status == 'Failed': message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Training job failed')
训练参数示例
{ "AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" }, "RoleArn": role, "OutputDataConfig": { "S3OutputPath": output_location }, "ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.8xlarge", "VolumeSizeInGB": 50 }, "TrainingJobName": job_name, "HyperParameters": { "k": "10", "feature_dim": "784", "mini_batch_size": "500", "force_dense": "True" }, "StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": data_location, "S3DataDistributionType": "FullyReplicated" } }, "CompressionType": "None", "RecordWrapperType": "None" } ] }
参量 首先是角色:您必须指出您的SageMaker实例有权访问的内容。 也就是说,在我们的案例中,如果分析师使用两种不同的作品,那么他应该看到一个存储桶,而不看到另一个。 输出配置是保存所有模型元数据的位置。
我们跳过自动缩放,可以简单地指定要在其上运行此训练作业的实例数。 最初,我们通常使用没有TensorFlow或Keras的中间实例,这就足够了。
超参数 您指定要在其中启动的Docker映像。 通常,Amazon提供了算法及其图像的列表,也就是说,您必须指定超参数-算法本身的参数。
建立模型
%%time import boto3 from time import gmtime, strftime job_name = 'kmeans-lowlevel-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print("Training job", job_name) from sagemaker.amazon.amazon_estimator import get_image_uri image = get_image_uri(boto3.Session().region_name, 'kmeans') output_location = 's3://{}/kmeans_example/output'.format(bucket) print('training artifacts will be uploaded to: {}'.format(output_location)) create_training_params = \ { "AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" }, "RoleArn": role, "OutputDataConfig": { "S3OutputPath": output_location }, "ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.8xlarge", "VolumeSizeInGB": 50 }, "TrainingJobName": job_name, "HyperParameters": { "k": "10", "feature_dim": "784", "mini_batch_size": "500", "force_dense": "True" }, "StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": data_location, "S3DataDistributionType": "FullyReplicated" } }, "CompressionType": "None", "RecordWrapperType": "None" } ] } sagemaker = boto3.client('sagemaker') sagemaker.create_training_job(**create_training_params) status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print(status) try: sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name) finally: status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus'] print("Training job ended with status: " + status) if status == 'Failed': message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Training job failed') %%time import boto3 from time import gmtime, strftime model_name=job_name print(model_name) info = sagemaker.describe_training_job(TrainingJobName=job_name) model_data = info['ModelArtifacts']['S3ModelArtifacts'] print(info['ModelArtifacts']) primary_container = { 'Image': image, 'ModelDataUrl': model_data } create_model_response = sagemaker.create_model( ModelName = model_name, ExecutionRoleArn = role, PrimaryContainer = primary_container) print(create_model_response['ModelArn'])
创建模型是培训工作的结果。 后者完成后,并在对其进行监视后,将其保存在S3上并可以使用。

从分析师的角度来看,这就是它的样子。 我们的分析师对模型进行了说:在此图像中,我要启动此模型。 他们只需指向S3文件夹Image,然后将参数输入图形界面即可。 但是有细微差别和困难,因此我们继续使用自定义算法。
创建端点
%%time import time endpoint_name = 'KMeansEndpoint-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime()) print(endpoint_name) create_endpoint_response = sagemaker.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name) print(create_endpoint_response['EndpointArn']) resp = sagemaker.describe_endpoint(EndpointName=endpoint_name) status = resp['EndpointStatus'] print("Status: " + status) try: sagemaker.get_waiter('endpoint_in_service').wait(EndpointName=endpoint_name) finally: resp = sagemaker.describe_endpoint(EndpointName=endpoint_name) status = resp['EndpointStatus'] print("Arn: " + resp['EndpointArn']) print("Create endpoint ended with status: " + status) if status != 'InService': message = sagemaker.describe_endpoint(EndpointName=endpoint_name)['FailureReason'] print('Training failed with the following error: {}'.format(message)) raise Exception('Endpoint creation did not succeed')
创建一个可以从任何lambda或从外部抽搐的端点需要大量代码。 每隔两个小时就会触发一个事件,该事件会拉动Endpoint。
端点视图

分析师就是这样看的。 他们只是简单地指出算法,时间,然后用手将其从界面中拉出。
调用端点
import json payload = np2csv(train_set[0][30:31]) response = runtime.invoke_endpoint(EndpointName=endpoint_name, ContentType='text/csv', Body=payload) result = json.loads(response['Body'].read().decode()) print(result)
这就是通过lambda来完成的。 也就是说,我们内部有一个端点,并且每两个小时发送一次有效载荷以进行预测。
有用的SageMaker链接:github链接
这些是非常重要的链接。 老实说,在我们开始使用常规的Sagemaker GUI之后,每个人都知道我们迟早会使用自定义算法,而所有这些都是手工组装的。 使用这些链接,您不仅可以找到算法的使用,还可以找到自定义图像的集合:
github.com/awslabs/amazon-sagemaker-examplesgithub.com/aws-samples/aws-ml-vision-end2endgithub.com/juliensimongithub.com/aws/sagemaker-spark接下来是什么?
我们已经接近第四次生产,现在,除了分析之外,我们还有两条发展道路。 首先,我们正在尝试从机械师那里获取日志,即我们正在尝试在支持下进行培训。 我们收到的第一批Mantainence日志如下所示:星期一发生故障,我在星期三到达那里,并在星期五开始修复它。 我们现在正在尝试为客户提供CMS-内容管理系统,该系统将允许记录故障事件。
怎么做? 通常,一旦发生故障,机械师会很快到达并更换零件,但是他可以在一周内填写各种纸质表格。 到这个时候,这个人只是忘记了零件到底发生了什么。 CMS当然将我们带入了与机械师互动的新高度。
其次,我们将在读取声音并进行频谱分析的电动机上安装超声波传感器。
我们可能会放弃Athena,因为在大数据上,使用S3昂贵。 同时,Microsoft最近宣布了自己的服务,我们的一位客户希望尝试在Azure上做同样的事情。 实际上,我们系统的优点之一是可以在另一个地方拆解和组装,例如从多维数据集上进行组装。