R是一种面向对象的语言。 在其中,绝对所有的东西都是对象,从函数开始并以表结尾。
反过来,R中的每个对象都属于一个类。 实际上,在我们周围的世界中,情况大致相同。 我们被对象包围,并且每个对象都可以归于一个类。 一个类确定可以用此对象执行的一组属性和操作。

例如,在任何厨房中都有桌子和炉子。 厨房的桌子和炉子可以称为厨房设备。 通常,表格的属性受其尺寸,颜色和制成表格的材料的限制。 炉具的性能范围更广,至少必须具有功率,燃烧器数量和炉具类型(电或燃气)。
可以对对象执行的操作称为其方法。 分别对于桌子和盘子,这套方法也将有所不同。 您可以在桌子上吃晚餐,可以在上面做饭,但是不可能对通常使用火炉的食物进行热处理。
目录内容
类属性
在R中,每个对象也属于一个类。 根据类的不同,它具有一组特定的属性和方法。 就面向对象编程(OOP)而言,将一组属性和对象方法中的相似对象组合为组(类)的可能性称为封装 。
向量是R中最简单的对象类别;它具有长度的属性。 例如,我们将使用内置的矢量字母 。
length(letters)
[1] 26
使用length函数,我们得到字母向量的长度。 现在,让我们尝试将相同的功能应用于虹膜内置日期框架。
length(iris)
[1] 5
用于表的length函数返回列数。
表还具有另一个属性,即维。
dim(iris)
[1] 150 5
上面示例中的dim功能显示信息, 虹膜表中有150行和5列。
反过来,向量没有维。
dim(letters)
NULL
因此,我们确保不同类的对象具有不同的属性集。
广义函数
R具有许多通用功能: print , plot , summary等。 这些功能对不同类的对象的作用不同。
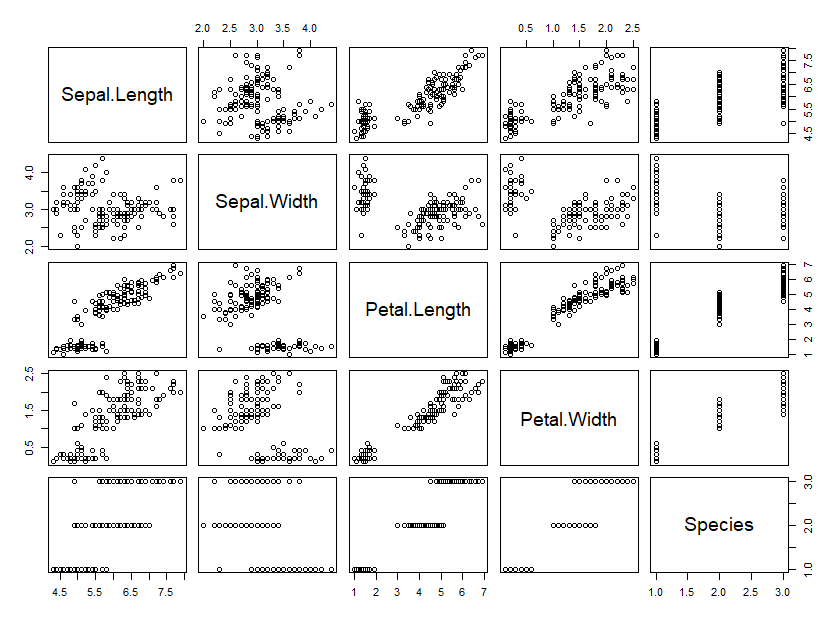
以plot函数为例。 让我们通过传递虹膜表作为其主要参数来运行它。
plot(iris)
结果:
现在,我们尝试将具有正态分布的100个随机数的向量传递给plot函数。
plot(rnorm(100, 50, 30))
结果:
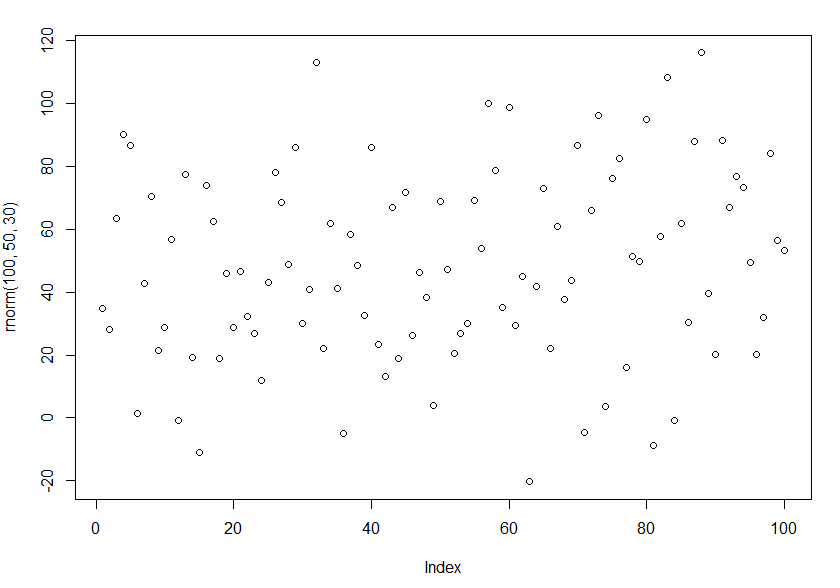
我们得到了不同的图,第一种情况是相关矩阵,第二种情况是散点图,在该图上沿x轴显示观察指标,沿y轴显示观察值。
因此, plot功能可以适应不同类别的工作。 如果我们回到OOP术语,那么确定传入对象的类并对不同类的对象执行各种操作的能力称为多态 。 这是由于以下事实:此函数只是用于为处理不同类而编写的各种方法的包装。 您可以使用以下命令对此进行验证:
body(plot)
UseMethod("plot")
body命令将功能主体打印到R控制台。 如您所见,body函数的主体仅包含一个UseMethod("plot")命令。
即 plot函数只是根据传递给它的对象的类来启动写入它的众多方法之一。 如下查看其所有方法的列表。
methods(plot)
[1] plot.acf* plot.data.frame* plot.decomposed.ts* [4] plot.default plot.dendrogram* plot.density* [7] plot.ecdf plot.factor* plot.formula* [10] plot.function plot.hclust* plot.histogram* [13] plot.HoltWinters* plot.isoreg* plot.lm* [16] plot.medpolish* plot.mlm* plot.ppr* [19] plot.prcomp* plot.princomp* plot.profile.nls* [22] plot.raster* plot.spec* plot.stepfun [25] plot.stl* plot.table* plot.ts [28] plot.tskernel* plot.TukeyHSD*
结果表明plot函数有29种方法,其中有plot.default ,如果该函数在输入中接收到一个未知类的对象,则默认情况下该函数起作用。
使用methods函数,您还可以获得一组具有针对任何类编写的方法的所有通用函数。
methods(, "data.frame")
[1] $<- [ [[ [[<- [5] [<- aggregate anyDuplicated as.data.frame [9] as.list as.matrix by cbind [13] coerce dim dimnames dimnames<- [17] droplevels duplicated edit format [21] formula head initialize is.na [25] Math merge na.exclude na.omit [29] Ops plot print prompt [33] rbind row.names row.names<- rowsum [37] show slotsFromS3 split split<- [41] stack str subset summary [45] Summary t tail transform [49] type.convert unique unstack within
什么是S3类以及如何创建自己的类
您可以创建R中的许多类。 最受欢迎的之一是S3。
此类是一个列表,其中存储了您创建的类的各种属性。 要创建自己的班级,只需创建一个列表并为其指定一个班级名称即可。
《 R语言编程的艺术 》一书给出了一个雇员类的示例,该类存储有关雇员的信息。 作为本文的示例,我还决定采用一个对象来存储有关员工的信息。 但是使它更加复杂和功能化。
# employee1 <- list(name = "Oleg", surname = "Petrov", salary = 1500, salary_datetime = Sys.Date(), previous_sallary = NULL, update = Sys.time()) # class(employee1) <- "emp"
因此,我们创建了自己的类,该类在其结构中存储以下数据:
- 员工姓名
- 员工姓
- 薪水
- 工资确定的时间
- 以前的薪水
- 最后更新信息的日期和时间
之后,使用class(employee1) <- "emp"命令class(employee1) <- "emp"将emp类分配给对象。
为了方便创建emp类的对象,您可以编写一个函数。
用于创建emp类对象的功能代码 # create_employee <- function(name, surname, salary, salary_datetime = Sys.Date(), update = Sys.time()) { out <- list(name = name, surname = surname, salary = salary, salary_datetime = salary_datetime, previous_sallary = NULL, update = update) class(out) <- "emp" return(out) } # emp create_employee employee1 <- create_employee("Oleg", "Petrov", 1500) # class(employee1)
[1] "emp"
自定义S3类的分配功能
因此,我们创建了自己的emp类,但是到目前为止,这还没有给我们任何好处。 让我们看看为什么我们创建自己的类以及可以使用它做什么。
首先,您可以为创建的类编写赋值函数。
[的分配功能 "[<-.emp" <- function(x, i, value) { if ( i == "salary" || i == 3 ) { cat(x$name, x$surname, "has changed salary from", x$salary, "to", value) x$previous_sallary <- x$salary x$salary <- value x$salary_datetime <- Sys.Date() x$update <- Sys.time() } else { cat( "You can`t change anything except salary" ) } return(x) }
[[ "[[<-.emp" <- function(x, i, value) { if ( i == "salary" || i == 3 ) { cat(x$name, x$surname, "has changed salary from", x$salary, "to", value) x$previous_sallary <- x$salary x$salary <- value x$salary_datetime <- Sys.Date() x$update <- Sys.time() } else { cat( "You can`t change anything except salary" ) } return(x) }
创建时的赋值函数总是用引号引起来,如下所示: "[<-. " / "[[<-. " 。 他们有3个必需的参数。
- x-将为其分配值的对象;
- i-对象元素的名称/索引(名称,姓氏,薪水,salary_datetime,previous_sallary,更新);
- value-分配的值。
在函数的主体中,您将编写如何更改类的元素。 在我的情况下,我希望用户只能更改薪水(薪水元素,其索引为3) 。 因此,在函数内部,我编写了一个if ( i == "salary" || i == 3 )检查if ( i == "salary" || i == 3 ) 。 如果用户尝试编辑其他属性, "You can't change anything except salary"收到消息"You can't change anything except salary" 。
更改工资元素后,将显示一条消息,其中包含员工的姓名和姓氏,其当前和新的工资水平。 当前薪水将传递到previous_sallary属性,并且为薪水分配新值。 salary_datetime和update属性的值也会更新。
现在,您可以尝试更改工资。
employee1["salary"] <- 1750
Oleg Petrov has changed salary from 1500 to 1750
为通用功能开发自定义方法
之前,您已经了解到R中存在一些通用函数,这些函数根据对象输入处接收的类来更改其行为。
您可以将方法添加到现有的通用函数中,甚至可以创建自己的通用函数。
print是最常用的通用函数之一。 每次您通过对象名称调用对象时都会触发此函数。 现在,我们创建的emp类对象的打印输出如下所示:
$name [1] "Oleg" $surname [1] "Petrov" $salary [1] 1750 $salary_datetime [1] "2019-05-29" $previous_sallary [1] 1500 $update [1] "2019-05-29 11:13:25 EEST"
让我们为打印功能编写方法。
print.emp <- function(x) { cat("Name:", x$name, x$surname, "\n", "Current salary:", x$salary, "\n", "Days from last udpate:", Sys.Date() - x$salary_datetime, "\n", "Previous salary:", x$previous_sallary) }
现在,print函数可以打印emp类的对象。 只需在控制台中输入对象的名称并获得以下输出。
employee1
Name: Oleg Petrov Current salary: 1750 Days from last udpate: 0 Previous salary: 1500
创建通用功能和方法
里面的大多数通用函数看起来都一样,只是使用UseMethod函数。
# get_salary <- function(x, ...) { UseMethod("get_salary") }
现在,我们将为其编写两种方法,一种方法用于处理emp类的对象,第二种方法将在默认情况下针对所有其他类的对象启动,而通用函数没有单独编写的方法。
# emp get_salary.emp <- function(x) x$salary # get_salary.default <- function(x) cat("Work only with emp class objects")
方法的名称由函数的名称和该方法将处理的对象的类组成。 如果您传递未写入该方法的类对象,则默认方法将在每次运行。
get_salary(employee1)
[1] 1750
get_salary(iris)
Work only with emp class objects
传承
学习面向对象的编程时会遇到另一个术语。
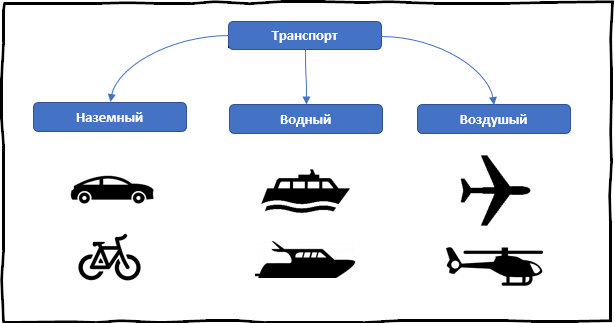
图片中显示的所有内容都可以归类为运输类别。 实际上,所有这些对象都有一个通用的方法-运动和通用属性,例如速度。 但是,所有6个对象可以分为三个子类:土地,水和空气。 在这种情况下,子类将继承父类的属性,但还将具有其他属性和方法。 面向对象编程框架中的类似属性称为继承 。
在我们的示例中,我们可以将远程工作程序分配给remote_emp的单独子类。 这些员工将拥有其他财产:居住城市。
# employee2 <- list(name = "Ivan", surname = "Ivanov", salary = 500, salary_datetime = Sys.Date(), previous_sallary = NULL, update = Sys.time(), city = "Moscow") # remote_emp class(employee2) <- c("remote_emp", "emp") # class(employee2)
[1] "remote_emp" "emp"
在分配一个类并创建一个子类时,我们使用一个向量,其中的第一个元素是子类的名称,然后是父类的名称。
在继承的情况下,为与父类一起使用而编写的所有通用函数和方法都将与其子类一起正确使用。
# remote_emp employee2
Name: Ivan Ivanov Current salary: 500 Days from last udpate: 0 Previous salary:
# salary remote_emp get_salary(employee2)
[1] 500
但是您可以为每个子类分别开发方法。
# salary remote_emp get_salary.remote_emp <- function(x) { cat(x$surname, "remote from", x$city, "\n") return(x$salary) }
# salary remote_emp get_salary(employee2)
Ivanov remote from Moscow [1] 500
它的工作原理如下。 首先,泛型函数会寻找为remote_emp子类编写的方法,如果找不到,它将走得更远并寻找为父类emp编写的方法。
什么时候可以使用自己的课程
对于刚刚开始精通R语言之旅的人来说,创建自己的S3类的功能不太可能会有用。
就个人而言,他们在开发rfacebookstat软件包时派上了用场。 事实是,在Facebook API中,存在action_breakdowns参数以加载事件并响应各个组中的广告发布。
使用此类分组时,您会以以下格式的JSON结构形式获得响应:
{ "action_name": "like", "action_type": "post_reaction", "value": 6 } { "action_type": "comment", "value": 4 }
不同action_breakdowns的元素数量和名称不同,因此对于每个元素,您都需要编写自己的解析器。 为了解决此问题,我使用了用于创建自定义S3类的功能以及带有一组方法的通用功能。
当请求具有分组的事件的统计信息时,根据参数的值,定义了一个类,该类分配给从API接收的响应。 响应被传递给泛型函数,并根据先前指定的类,确定了一种分析结果的方法。 谁愿意去研究实现细节,那么在这里您可以找到用于创建通用函数和方法的代码, 这就是它们的用途。
就我而言,我使用类和方法在包内专门处理它们。 如果通常需要为包的用户提供一个用于处理所创建的类的接口,则必须将所有方法作为S3method指令包括在S3method文件中,如下所示。
S3method(_,) S3method("[<-",emp) S3method("[[<-",emp) S3method("print",emp)
结论
从文章标题可以明显看出,这只是第一部分,因为 在R中,除了S3类外,还有其他类: S4 , R5 ( RC ), R6 。 将来,我将尝试写每个OOP实现。 尽管如此,任何具有英语水平的人都允许他们自由阅读书籍,然后Headley Wickham十分简洁,并举例说明了他在“ Advanced R”一书中涵盖的主题。
如果突然在一篇文章中我错过了有关S3类的一些重要信息,那么如果您在注释中写到这一点,将不胜感激。