每年在莫斯科举行
对话会议,语言学家和数据分析专家参加。 他们讨论什么是自然语言,如何教机器理解和处理它。 该会议传统上举行比赛(赛道)
对话评估 。 可以在自然语言处理领域(Natural Language Processing,NLP)创建解决方案的大公司的代表以及个别研究人员可以参加。 看来,如果您是一个简单的学生,那么您是否会与大型公司的大型专家多年来创建的系统竞争。 对话评估-最终排名中,一个简单的学生可能比一家知名公司高的情况就是这样。
今年将是对话评鉴活动连续第9年举行。 每年的比赛次数都不一样。 NLP任务(例如情感分析,词义归纳,自动拼写校正,命名实体识别等)已经成为曲目的主题。

今年,四组组织者准备了这样的曲目:
- 生成新闻报道的头条新闻。
- 回指和共指的解决。
- 低资源语言材料的形态分析。
- 自动分析其中一种省略号(空白)。
今天,我们将讨论其中的最后一个:什么是椭圆形,以及为什么要教汽车如何在文本中还原它,我们如何创建一个新的建筑物来解决这个问题,如何举行比赛以及参赛者能够取得什么成果。
AGRR-2019(俄语的自动间隔分辨率)
在2018年秋天,我们面临与椭圆相关的研究任务-故意遗漏可以从上下文中恢复的文本中的一系列单词。 如何自动在文本中找到这样的空白并正确填写? 以母语为母语的人很容易,但是教这辆车并不容易。 很快就知道这是竞争的好材料,我们开始做生意。
新主题竞赛的组织有其自身的特征,对我们来说,这似乎是件好事。 主要的事情之一是语料库的创建(许多带有标记的文本,您可以在上面学习)。 它看起来像什么,应该是多少? 对于许多任务,有一些标准可用于显示要建立的数据。 例如,对于
标识命名实体的
任务,已经开发了IO / BIO / IOBES标记方案,对于传统上使用CONLL格式进行语法和形态分析的任务,不需要发明任何东西,但是必须严格遵循准则。
在我们的情况下,由我们来组建部队并制定任务。
这是一个任务...
在这里,我们不可避免地不得不对省略号进行一般性的语言介绍,而省略号是其中的一种。
无论您对语言有什么想法,都很难说表面表达(文本或语音)不是唯一的表达。 所说的那句话是冰山一角。 冰山本身包括实用的评估,句法结构的构建,词汇材料的选择等。 椭圆现象是一种将水平面与深层完美地联系在一起的现象。 这是重复语法元素的省略。 如果我们以树的形式呈现句子的句法结构,并且可以在该树中选择相同的子树,那么为了使句子自然,经常(但并非总是)会删除重复的元素。 这样的删除称为省略号(示例1)。
(1)
他们没有给我回电话,我也不明白为什么他们没有给我回电话 。可以从语言上下文中明确地消除由省略号获得的差距。 将第一个示例与第二个示例(2)进行比较,这里有一个传递,但是尚不清楚确切缺少什么。 这种情况不是省略号。
(2)
间隙是省略号的频率类型之一。 考虑示例(3)并了解其工作原理。
(3)
我误以为她是意大利人,他是瑞典人。在所有示例中,都有两个以上的句子(子句),它们是由彼此组成的。 在第一个子句中有一个动词(语言学家更可能说“谓语”),并且它的参与者
接受了它:
我 ,
她和
意大利语 。 在第二子句中,没有表达的动词,只有“残体”(和残体)
与瑞典人在语法上没有关联,但是我们知道通行证是如何恢复的。
为了恢复通过,我们转到第一个子句并从中复制整个结构(示例4)。 我们仅替换不完整子句中存在“平行”残差的那些部分。 我们复制了谓词,将其替换
为意大利语 ,
对于意大利语,我们将其替换
为瑞典人的剩余谓词。 对
我而言,没有并行的残余,这意味着我们无需替换即可复制它。
(4)
我误以为她是意大利人, 误以为是瑞典人。看来,为了恢复间隔,我们足以确定此句子中是否存在间隔,找到不完整子句和与之相关联的整个子句(从中获取恢复的材料),然后了解不完整子句中的“残余”(残余)和它们完全对应什么。 这些条件似乎足以有效填补空白。 因此,我们尝试模仿一个人在阅读或听到可能有遗漏的文本时所经历的过程。
那么,为什么需要这样做呢?
显然,对于一个首先听到省略号及其相关处理困难的人,可能会出现一个合理的问题,“为什么?” 怀疑论者希望
邀请语言科学之父阅读以解释说,如果所解决问题的解决方案提供了可用于理论研究的材料,那么这已经足以回答有关此类活动目的的问题。
理论家一直在研究不同语言的省略号已有50年之久,描述了局限性,强调了不同语言的一般模式。 同时,我们还不知道存在一个用数百个例子说明任何类型的省略号的语料库。 部分原因是该现象的稀有性(例如,在我们的数据中,在1万个句子中,只有不到5个句子被发现存在这种问题)。 因此,创建这样的军团已经是重要的结果。
在使用文本数据的应用程序系统中,这种现象的稀有性使您可以简单地忽略它。 语法分析器无法恢复丢失的间隙并不会带来很多错误。 但是从罕见的事件中,形成了广泛而杂色的语言边缘。 对于那些想要创建不仅可以在具有常见词汇的简单,简短,整洁的文本上工作的系统的人来说,解决此类问题本身的经验似乎应该引起人们的兴趣,也就是说,他们可以在自然界中几乎没有的真空环境中处理球形文本。
很少有解析器拥有用于检测和解决省略号的有效系统。 但是在内部解析器ABBYY中,有一个模块负责还原通行证,它基于手动编写的规则。 借助解析器的这种功能,我们能够为比赛创建一个大型实体。 原始解析器的潜在好处是可以替换运行缓慢的模块。 另外,在处理该案例时,我们对当前系统的错误进行了详细分析。
我们如何创造身体
我们的建筑物主要用于自动化系统的培训,这意味着庞大而多样的建筑至关重要。 在此指导下,我们构建了如下数据收集工作。 对于军团,我们选择了各种类型的文本:从技术文档和专利到社交媒体的新闻和帖子。 所有这些都由ABBYY解析器标记。 在一个月内,我们在语言学家和书写者之间分发了数据。 邀请了标记,但不更改标记,对其进行了规模评估:
0-句子中没有映射,标记不相关。
1-有一个映射,并且其标记正确。
2-差距很大,但是标记出问题了。
3-一个棘手的情况,这是一个映射吗?
结果,每个小组都派上了用场。 第1类的示例属于我们数据集的肯定类。 为了节省时间,我们基本上不想手动对第2类和第3类中的示例进行重新抽样,但是这些示例对我们以后评估结果案例很有用。 从他们那里可以判断系统在哪些情况下始终错误地标记,这意味着它们不会落入我们的部队。 最后,在被标记归类为类别0的示例中,我们为系统提供了“从他人的错误中吸取教训”的机会,也就是说,不仅要模拟原始系统的行为,而且要比原始系统做得更好。
每个示例均由两个标记进行评估。 之后,略多于一半的提案从源数据进入了团队。 整个正面的例子类别和部分负面的例子由它们组成。 我们决定使否定类的积极性提高两倍,以便一方面使类的数量具有可比性,另一方面,保留该语言中存在的否定类的优势。
为了达到这个比例,除了描述的类别0的示例外,我们还必须在该案例中添加更多负面示例。让我们给出类别0的示例(5),它不仅会混淆汽车,还会混淆人。
(5)
但是到那时杰克已经爱上了辛迪·佩奇(Cindy Page),现在是杰克·斯威特克夫人。在第二个子句中,她并没有恢复
恋爱 ,因为我的意思是,现在辛迪·佩奇(Cindy Page)成为杰克·斯维特(Jack Svaytek)太太,因为她嫁给了他。
通常,对于诸如间隔这样的相对罕见的语法现象,否定示例几乎是该语言的任何随机句子,因为随机句子中存在很小的间隔的可能性。 但是,使用此类否定示例可能会导致对标点符号的重新训练。 在我们的案例中,否定类的示例是根据简单的标准获得的:动词的存在,逗号或破折号的存在,最小句子长度不少于6个记号。
对于竞赛,我们从培训建筑开发部分(以1:5的比例)中选择了一个,邀请参与者用来配置他们的系统。 系统的最终版本在培训和开发部分的组合中进行了培训。 我们自己手动标记了测试用例(测试),就数量而言,这是train + dev的第十部分。 这是类示例的确切数目:
除了手动验证的训练数据外,我们还添加了从源系统接收的原始标记文件。 其中有超过10万个示例,参与者可以选择使用这些数据来补充训练样本。 展望未来,我们说只有一名参与者想出了如何在不损失质量的情况下使用脏数据来显着增加培训体系的方法。
标记格式
我们故意拒绝使用第三方解析器,并开发了一种标记,其中在文本行中线性标记了我们感兴趣的所有元素。 我们使用了两种类型的标记。 第一个是人类可读的,旨在与标记一起使用,并且可以方便地分析所得系统的错误。 使用此方法,所有间隔元素都在句子内部用方括号标记。 每对方括号均标有相应元素的名称。 我们使用以下符号:

我们举例说明带有括号的句子。
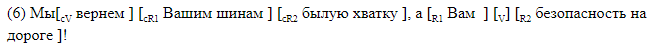
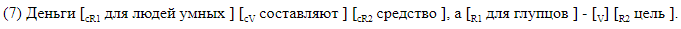

支架标记适用于材料分析。 在这种情况下,数据以不同的格式存储,如果需要,可以将其轻松转换为括号。 一行对应一个句子。 列指示句子中存在间隔,并且针对其列中的每个可能标签,给出与元素相对应的段的开头和结尾的符号偏移。 这就是偏移标记的外观,与()中的括号标记相对应。
参加者的任务
AGRR-2019参与者可以解决以下三个问题中的任何一个:
- 二进制分类 有必要确定句子中是否有空格。
- 差距许可。 有必要恢复过程的位置(V)和动词控制器的位置(cV)。
- 完整标记。 您需要为间隙的所有元素定义偏移量。
下一个任务必须以某种方式解决上一个任务。 显然,只有在二进制分类显示肯定的类别(存在映射)的句子中,任何标记都是可能的,并且完整的标记还包括查找缺失谓词和控制谓词的边界。
指标
对于二元分类问题,我们使用标准度量标准:准确性和完整性,并且参与者的结果通过f度量进行排名。
对于解决缺口和完整标记的任务,我们决定使用符号性f度量,因为源文本未进行标记化,并且我们不希望参与者使用的标记化器中的差异影响结果。 真负示例对符号f测度没有帮助,因为考虑了每个标记元素自己的f测度,最终结果是通过对整个身体进行宏平均获得的。 由于对度量标准进行了这种计算,对假阳性案例进行了明显的罚款,当真实数据中的阳性示例比阴性数据少很多倍时,这一点很重要。
比赛课程
在组装建筑物的同时,我们接受了参加比赛的申请。 结果,我们注册了40多名参与者。 然后,我们布置了培训大楼并启动了比赛。 参与者有4周的时间建立模型。
评估结果的阶段如下:参与者收到2万个没有加价的报价,其中涉及一个测试用例。 团队必须在其系统上标记该数据,然后我们评估测试建筑物上标记的结果。 将测试与大量数据混合在一起,保证了我们的全部意愿,无法在运行指定的几天内手动标记出案例(自动标记)。
比赛结果
共有9个团队进入决赛,其中包括两家IT公司的代表,莫斯科国立大学,莫斯科物理与技术学院,HSE和IPPI RAS的研究人员。
除一支队伍外,所有队伍都参加了所有三场比赛。 根据AGRR-2019的条款,所有团队均发布了自己的决策代码。
我们的存储库中提供了包含结果的摘要表,您还可以在其中找到带有简短说明的团队规划解决方案的链接。
几乎所有结果都很好。 以下是获胜团队决策的评估:
很快,您可以在Dialogue系列的参与者文章中找到有关最佳解决方案的详细说明。
因此,在本文中,我们讨论了如何以一种罕见的语言现象为基础来制定任务,准备一支队伍并进行比赛。 NLP社区也可以从此类工作中受益,因为竞争有助于在特定材料上相互比较不同的体系结构和方法,并且语言学家发现了一种罕见现象,有可能对其进行补充(使用获胜者的决定)。 组合后的军团比当前现有军团的规模大好几倍(此外,为了缩小差距,不仅对于俄语,而且对于所有语言,该军团的数量都比军团的数量大一个数量级)。 所有数据和参与者决定的链接都可以在我们的github中找到。
5月30日,在致力于自动分析差距竞赛的
对话特别会议上,将总结AGRR-2019的结果。 我们将讨论比赛的组织方式,并详细讨论新建建筑物的内容,参赛者将介绍他们用来解决问题的所选建筑。
NLP高级研究小组