可以在
此链接上找到完整的俄语课程。
此链接提供原始英语课程。
 每2-3天安排一次新的讲座。
每2-3天安排一次新的讲座。Udacity首席执行官Sebastian Trun访谈
“因此,我们仍然像塞巴斯蒂安一样与您和我们在一起。” 我们只想讨论完全连接的层,即那些相同的密集层。 在此之前,我想问一个问题。 深度学习的界限是什么?在接下来的10年中将有哪些最大障碍? 一切都变的如此之快! 您认为接下来的“大事”是什么?
-我要说两件事。 首先是用于多个任务的通用AI。 太好了! 人们可以解决多个问题,并且永远不要做同样的事情。 第二是将技术推向市场。 对我来说,机器学习的独特之处在于它为计算机提供了观察和发现数据模式的能力,从而帮助人们成为专家级的业内最佳人才! 机器学习可用于法律,医学,自动驾驶汽车。 开发这样的应用程序是因为它们可以带来很多钱,但是最重要的是,您有机会让世界变得更加美好。
-我真的很喜欢您将所有内容都表达在深度学习及其应用中的方式-这只是一个可以帮助您解决特定问题的工具。
-是的! 难以置信的工具,对不对?
-是的,我完全同意您的意见!
“几乎像人的大脑!”
-您在视频课程的第一部分中的第一次采访中提到了医疗应用。 您认为深度学习在哪些应用程序中会带来最大的乐趣和惊喜?
-好多! 很好! 医学是积极使用深度学习的领域的短名单。 几个月前我失去了姐姐,她患了癌症,这非常令人难过。 我认为,许多疾病可以及早发现-在早期阶段,可以治愈或减慢其发展进程。 实际上,其想法是将一些工具转移到房屋(智能家居)中,以便有可能在人们本人看到它们之前就检测出这种健康状况的偏差。 我还要补充一点-重复一切,完成任何办公室工作,在其中您一次又一次地执行相同类型的操作,例如簿记。 甚至我作为首席执行官,也做了很多重复的动作。 使它们自动化甚至与邮件通信一起工作都很棒!
-我不能不同意你! 在本课程中,我们将向学生介绍带有称为稠密层的神经网络层的课程。 您能否详细介绍一下您对全连接层的看法?
-因此,让我们从一个事实开始,即每个网络可以通过不同的方式连接。 它们中的一些可能具有非常紧密的连接性,这使您可以在扩展和与大型网络“竞争”时获得一些好处。 有时您不知道所需的连接数,因此将所有内容都连接起来-这称为完全连接层。 我补充说,这种方法比更有条理的方法具有更大的力量和潜力。
-我完全同意你的看法! 感谢您帮助我们了解有关完全连接层的更多信息。 我期待我们终于开始实现它们并编写代码的时刻。
-玩得开心! 真的很有趣!
引言
-欢迎回来! 在上一课中,您了解了如何使用TensorFlow和Keras构建第一个神经网络,神经网络如何工作以及训练(培训)过程如何工作。 特别是,我们看到了如何训练模型以将摄氏温度转换为华氏温度。

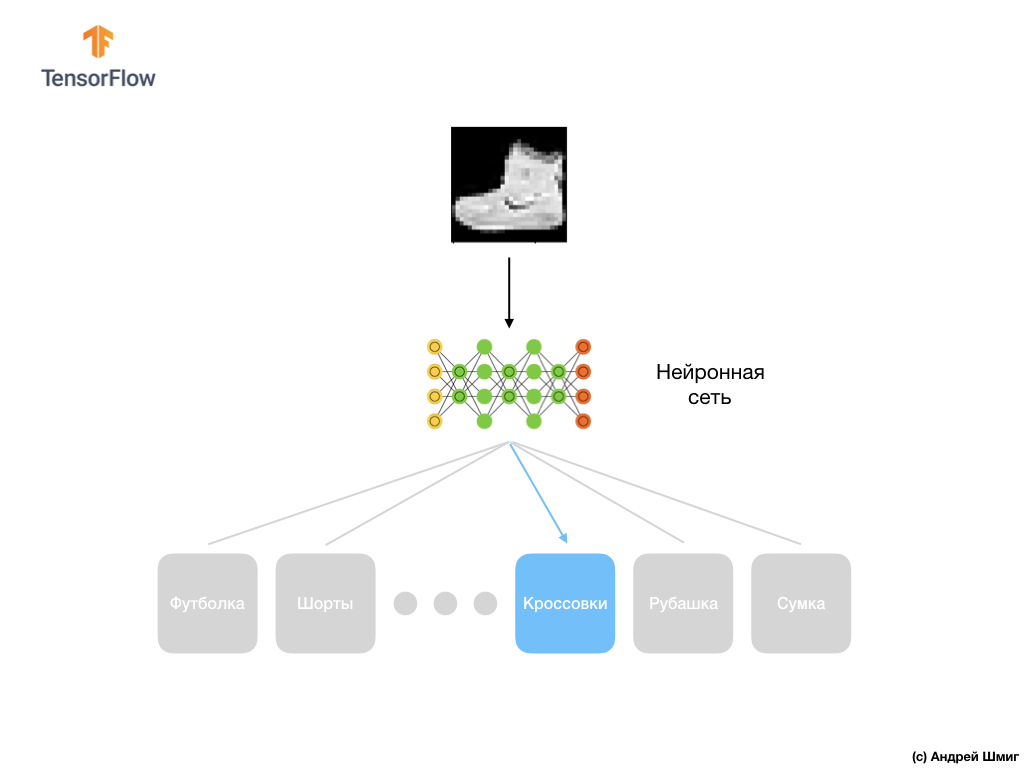
-我们还熟悉了全连接层(密集层)的概念,这是神经网络中最重要的层。 但是在本课中,我们将做很多更酷的事情! 在本课程中,我们将开发一个可以识别服装元素和图像的神经网络。 正如我们前面提到的,机器学习使用称为“功能”的输入和称为“标签”的输出,模型通过该输入学习并找到转换算法。 因此,首先,我们将需要许多示例来训练神经网络以识别服装的各种元素。 让我提醒您,训练的示例是一对值-输入要素和输出标签,它们被馈送到神经网络的输入。 在我们的新示例中,图像将用作输入,输出标签应为图片中所示服装项目所属的服装类别。 幸运的是,这样的数据集已经存在。 它被称为时尚MNIST。 在下一部分中,我们将仔细研究该数据集。
时尚MNIST数据集
欢迎来到MNIST数据集的世界! 因此,我们的图像集由28x28张图像组成,每个像素代表一个灰色阴影。

数据集包含T恤,上衣,凉鞋甚至靴子的图像。 这是我们的MNIST数据集包含的完整列表:
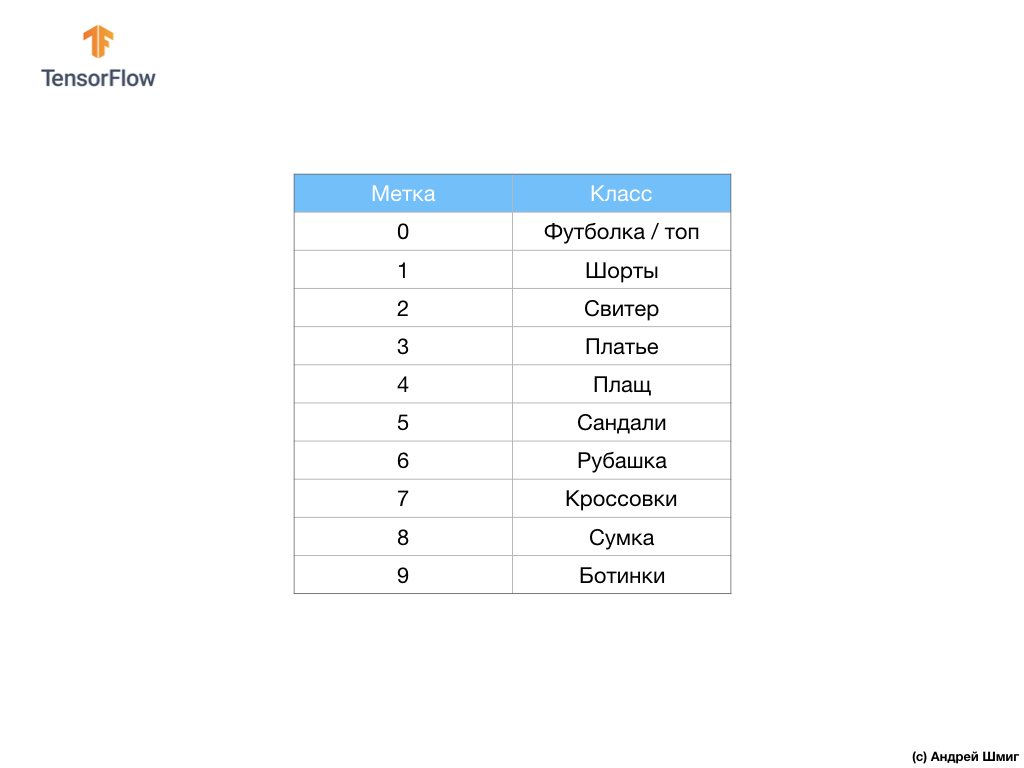
每个输入图像对应于上述标签之一。 Fashion MNIST数据集包含70,000张图像,因此我们有一个开始和工作的地方。 在这70,000人中,我们将使用60,000人来训练神经网络。
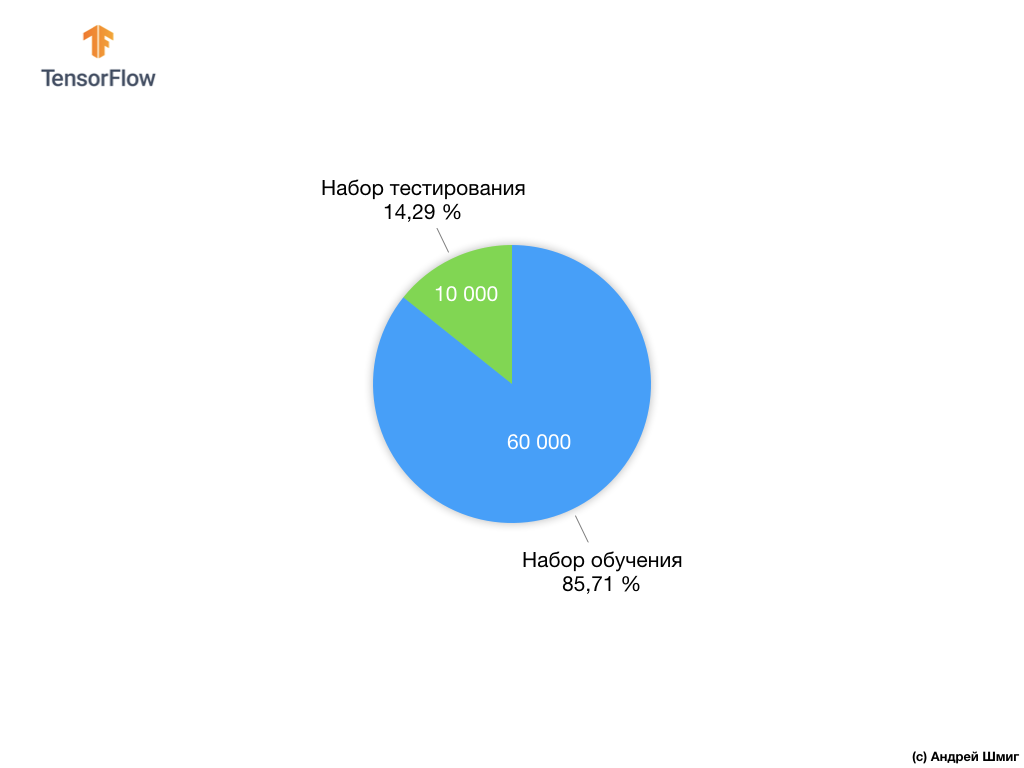
我们将使用剩余的10,000个元素来检查我们的神经网络对识别服装元素的了解程度。 稍后,我们将解释为什么将数据集分为训练集和测试集。
这是我们的Fashion MNIST数据集。
请记住,数据集中的每个图像都是一个灰度级为28x28的图像,这表示每个图像的大小均为784字节。 我们的任务是创建一个神经网络,该神经网络在输入处接收这784个字节,然后在输出处返回在10种可用的衣服类别中,输入处所应用的元素所属。
神经网络
在本课程中,我们将使用一个深度神经网络,该网络将学习从Fashion MNIST数据集中对图像进行分类。
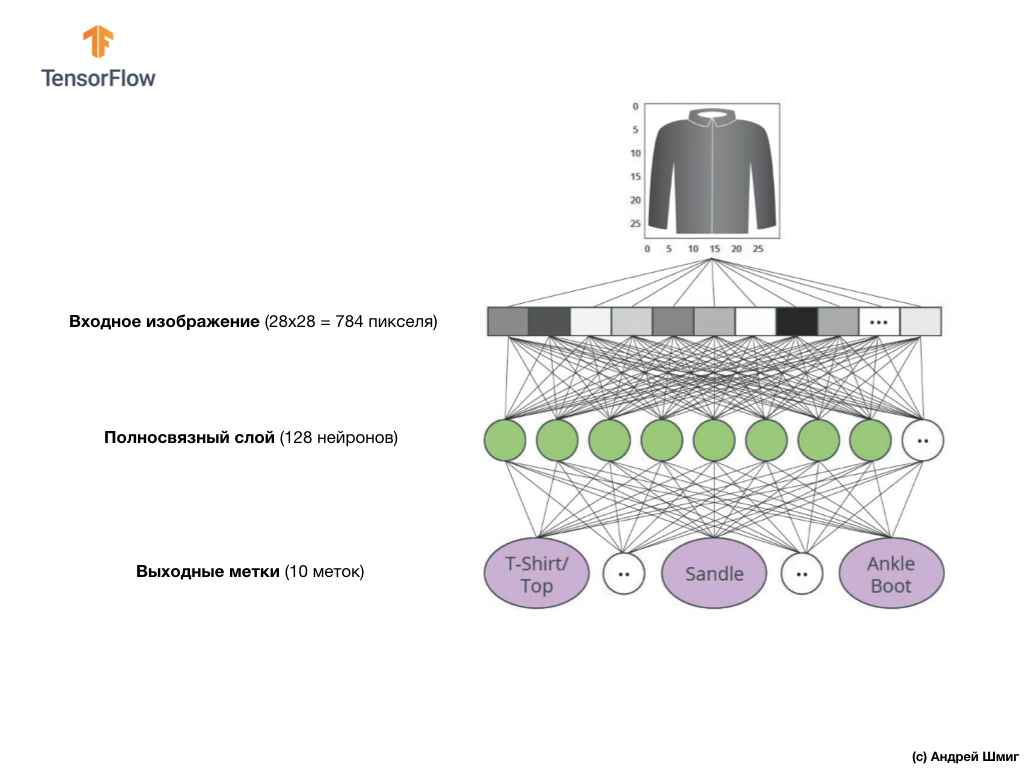
上图显示了我们的神经网络的外观。 让我们更详细地看一下。
我们神经网络的输入值是一个长度为784的一维数组,由于每个图像都是28x28像素(=图像中总共784像素)的原因,正是该长度的数组,我们将其转换为一维数组。 将2D图像转换为矢量的过程称为展平,并通过展平层(展平层)实现。
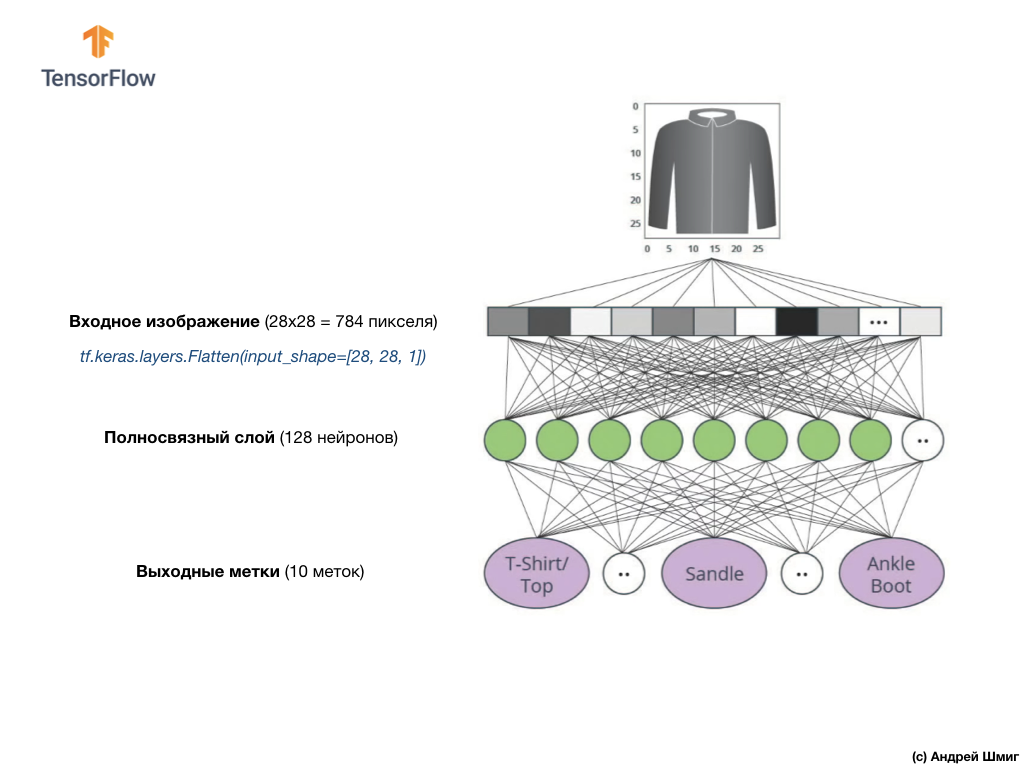
您可以通过创建适当的图层来进行平滑处理:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
该层将28x28像素的2D图像(每个像素1个字节用于灰度阴影)转换为784个像素的1D数组。
输入值将与我们的第一个
dense网络层完全相关,我们选择的大小等于128个神经元。
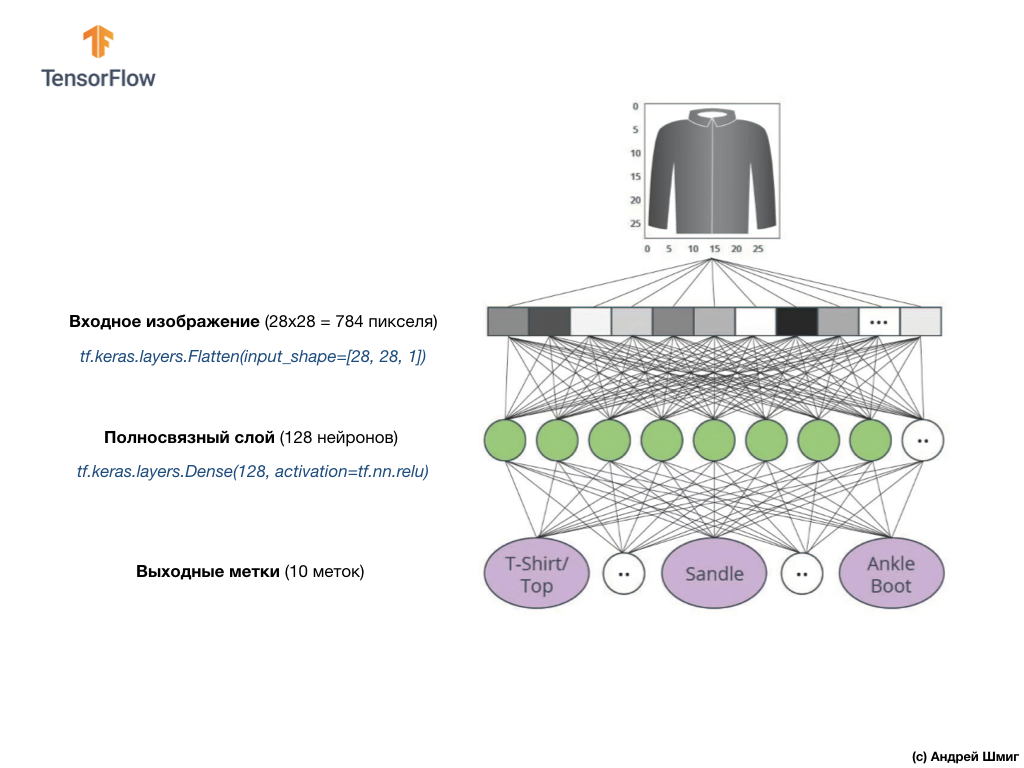
这是在代码中创建该层的样子:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
别说了 什么是
tf.nn.relu ? 在将摄氏度转换为华氏度时,我们在先前的神经网络示例中未使用此功能! 最重要的是,当前任务要比用作事实调查示例的任务复杂得多-将摄氏温度转换为华氏温度。
ReLU是一种数学函数,可添加到完全连接的层中,从而为网络提供更多功能。 实际上,这是对我们全连接层的一个小扩展,它使我们的神经网络能够解决更复杂的问题。 我们不会详细介绍,但是可以在下面找到一些更详细的信息。
最后,我们的最后一层,也称为输出层,由10个神经元组成。 它包含10个神经元,因为我们的Fashion MNIST数据集包含10个服装类别。 这10个输出值中的每一个将代表输入图像在此服装类别中的可能性。 换句话说,这些值反映了模型对输出图像中的10种服装类别中的特定类别的预测和相关性的正确性的模型“信心”。 例如,图像显示衣服,运动鞋,鞋子等的可能性是多少?
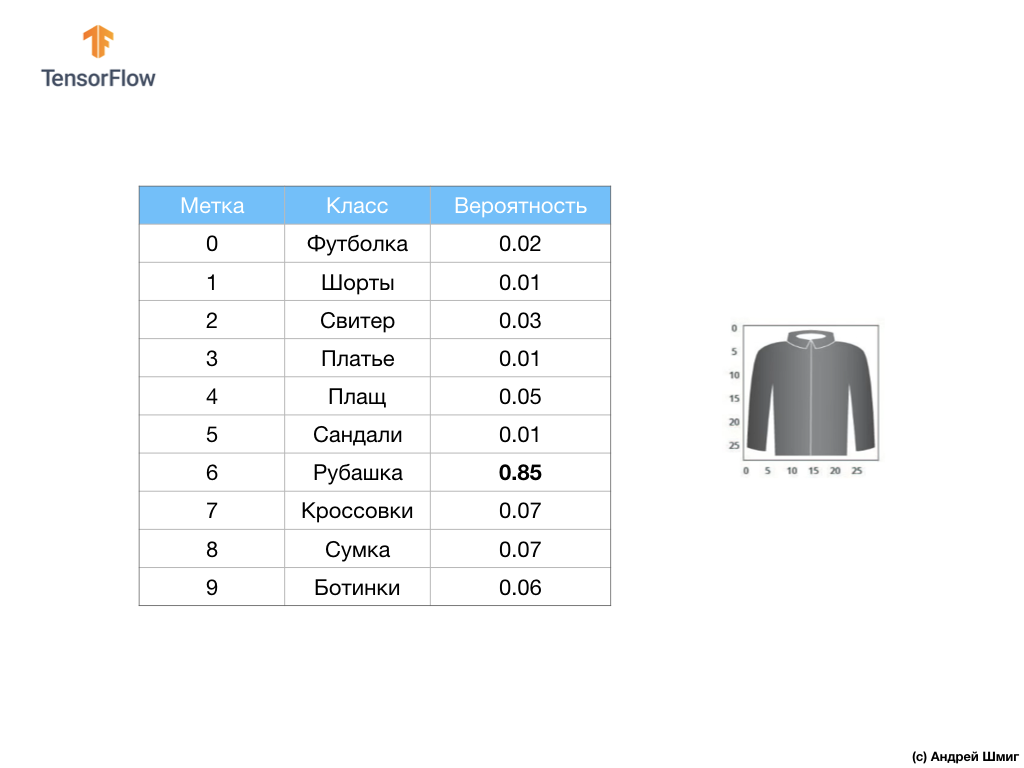
例如,如果将衬衫图像输入到我们的神经网络的输入中,则该模型可以为我们提供类似于您在上图中看到的结果-输入图像与输出标签匹配的概率。
如果您注意的话,您会发现最大的可能性-0.85表示标签6,它对应于衬衫。 该模特是85%确保衬衫上的图像。 通常,看起来像衬衫的事物也将具有较高的概率等级,而最不相似的事物将具有较低的概率等级。
由于所有10个输出值都对应于概率,因此在将所有这些值求和时,我们得到1。这10个值也称为概率分布。
现在,我们需要一个输出层来计算每个标签的概率。

我们将使用以下命令执行此操作:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
实际上,无论何时创建解决分类问题的神经网络,我们都始终使用完全连接的层作为神经网络的最后一层。 神经网络的最后一层应包含等于类数的神经元,我们确定其
softmax并使用softmax激活函数。
ReLU神经元激活功能
在本课程中,我们将
ReLU视为可以扩展神经网络功能并为其提供附加功能的东西。
ReLU是一个数学函数,如下所示:
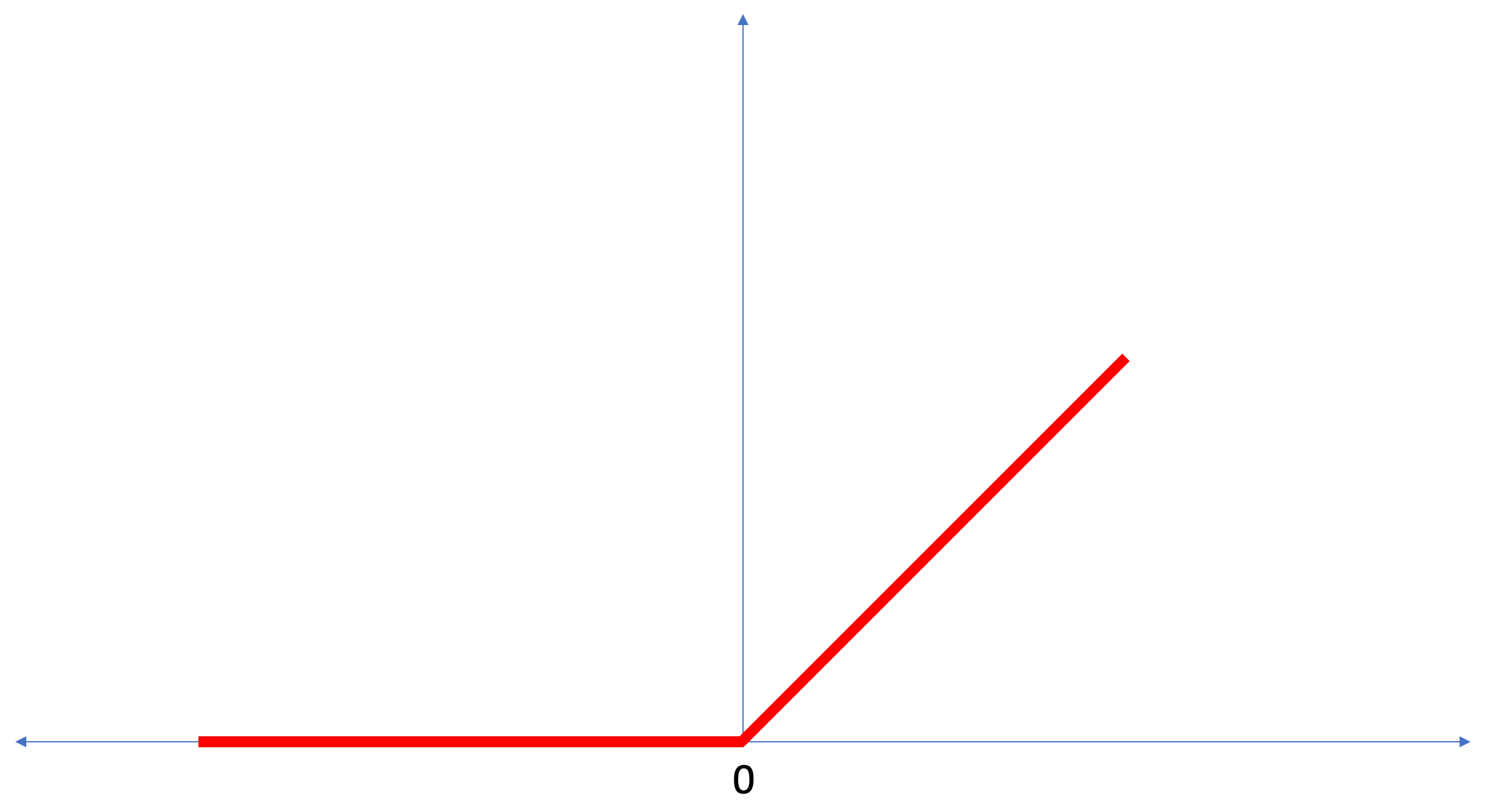
如果输入值为负值,则
ReLU函数返回0或为零,在所有其他情况下,该函数将返回原始输入值。
ReLU使解决非线性问题成为可能。
将摄氏度转换为华氏度是一项线性任务,因为表达式
f = 1.8*c + 32是线的方程
y = m*x + b 。 但是,我们要解决的大多数任务都是非线性的。 在这种情况下,将ReLU激活功能添加到我们的全连接层可以帮助完成此类任务。
ReLU只是激活功能的一种。 有诸如S形,ReLU,ELU,tanh的激活函数,但是,
ReLU最常被用作默认激活函数。 要构建和使用包含ReLU的模型,您无需了解它在内部如何工作。 如果您仍然想更好地理解,那么我们建议您阅读
本文 。
让我们回顾一下本课中介绍的新术语:
- 平滑 -将2D图像转换为1D矢量的过程;
- ReLU是一个激活函数,可以使模型解决非线性问题。
- Softmax-计算每种可能的输出类别的概率的函数;
- 分类 -一类机器学习任务,用于确定两个或多个类别(类)之间的差异。
培训与测试
训练模型(机器学习中的任何模型)时,始终有必要将数据集至少分为两个不同的集-用于训练的数据集和用于测试的数据集。 在这一部分中,我们将理解为什么值得这样做。
让我们记住如何分发来自Fashion MNIST的数据集,该数据集由70,000个副本组成。
我们建议将70,000分为两部分-在第一部分中,保留60,000进行培训,在第二部分中保留10,000进行测试。 这种方法的必要性是由以下事实引起的:在对模型进行了60,000份训练之后,有必要检查尚未在训练模型的数据集中得到的示例的结果和工作有效性。
就其自身而言,它类似于在学校通过考试。 在通过考试之前,您要努力解决特定班级的问题。 然后,在考试中,您会遇到同一类问题,但输入数据却不同。 提交与培训期间相同的数据是没有意义的,否则,任务将减少为记住决策,而不是找到解决方案模型。 这就是为什么在考试中您会面临课程中以前没有的任务。 只有这样,我们才能验证模型是否已经学习了通用解。
机器学习也会发生同样的事情。 您将显示一些数据,这些数据代表您要学习如何解决的特定类别的任务。 在我们的案例中,使用来自Fashion MNIST的数据集,我们希望神经网络能够确定图像中服装元素所属的类别。 这就是为什么我们在60,000个包含所有类别服装的示例上训练模型的原因。 训练后,我们要检查模型的有效性,因此我们提供模型尚未“看到”的剩余10,000件衣物。 如果我们决定不这样做,而不用10,000个示例进行测试,我们将无法确定地说我们的模型是否经过实际训练来确定服装的类别,或者她是否记住了所有输入和输出值对。
这就是为什么在机器学习中我们总是有一个训练数据集和一个测试数据集的原因。
TensorFlow是现成的培训数据的集合。
数据集通常分为几个块,每个块都用于训练和测试神经网络有效性的某个阶段。 在这一部分中,我们讨论:
- 训练数据集 :旨在训练神经网络的数据集;
- 测试数据集 :旨在验证神经网络效率的数据集;
考虑另一个数据集,我称之为验证数据集。 此数据集仅
在训练
期间不用于训练模型。 因此,在我们的模型经过几个训练周期后,我们将其提供给我们的测试数据集并查看结果。 例如,如果在训练过程中损失函数的值减小,并且测试数据集的准确性下降,则意味着我们的模型仅简单地记住成对的输入输出值。
验证数据集将在训练结束时重新使用,以测量模型预测的最终准确性。
有关
培训和测试数据集的更多
信息,请参阅Google Crash课程 。
CoLab的实践部分
链接到原始的英语CoLab和
链接到Russian CoLab 。
衣物图像分类
在本部分课程中,我们将构建和训练一个神经网络,以对服装元素的图像进行分类,例如衣服,运动鞋,衬衫,T恤等。
如果片刻不清楚,没关系。 本课程的目的是向您介绍TensorFlow,同时解释其工作算法,并使用TensorFlow形成对项目的共识,而不是深入研究实现细节。
在本部分中,我们使用
tf.keras ,这是一个用于在TensorFlow中构建和训练模型的高级API。
安装和导入依赖项
我们将需要
TensorFlow数据集 ,该API可以简化加载和访问由多种服务提供的数据集的过程。 我们还将需要一些辅助库。
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
导入Fashion MNIST数据集
此示例使用Fashion MNIST数据集,该数据集包含10个类别的灰度的70,000张服装项目图像。 图像包含低分辨率(28x28像素)的衣物,如下所示:

时尚MNIST被用来替代经典MNIST数据集-最常被用作“ Hello,World!” 在机器学习和计算机视觉方面。 MNIST数据集包含手写数字(0、1、2等)的图像,其格式与本例中的服装相同。
在我们的示例中,我们使用Fashion MNIST是因为其种类繁多,并且因为从实现的角度来看,此任务比解决MNIST数据集上的典型问题更为有趣。 这两个数据集都足够小,因此,它们用于检查算法的正确可操作性。 强大的数据集,可用于开始学习机器学习,测试和调试代码。
我们将使用60,000张图像来训练网络,并使用10,000张图像来测试训练和图像分类的准确性。 您可以使用API通过TensorFlow直接访问Fashion MNIST数据集:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True) train_dataset, test_dataset = dataset['train'], dataset['test']
通过加载数据集,我们可以获得元数据,训练数据集和测试数据集。
- 在来自“ train_dataset”的数据集上训练模型
- 在来自test_dataset的数据集上测试了模型
图片是二维
2828数组,其中每个单元格中的值可以在
[0, 255]区间内。 标签-一个整数数组,其中每个值都在
[0, 9]区间内。 这些标签对应于输出图像类,如下所示:
每个图像都属于一个标签。 由于类名称不包含在原始数据集中,因此在绘制图像时将其保存以备将来使用:
class_names = [' / ', "", "", "", "", "", "", "", "", ""]
我们研究数据
在训练模型之前,让我们研究训练集中呈现的数据的格式和结构。 以下代码将显示训练数据集中有60,000张图像,测试数据集中有10,000张图像:
num_train_examples = metadata.splits['train'].num_examples num_test_examples = metadata.splits['test'].num_examples print(' : {}'.format(num_train_examples)) print(' : {}'.format(num_test_examples))
数据预处理
图像中每个像素的值在
[0,255]范围内。 为了使模型正常工作,必须将这些值归一化-减小为
[0,1]间隔内的值。 因此,稍稍降低一点,我们声明并实现归一化功能,然后将其应用于训练和测试数据集中的每个图像。
def normalize(images, labels): images = tf.cast(images, tf.float32) images /= 255 return images, labels
我们研究处理后的数据
让我们画一个图像来看看它:
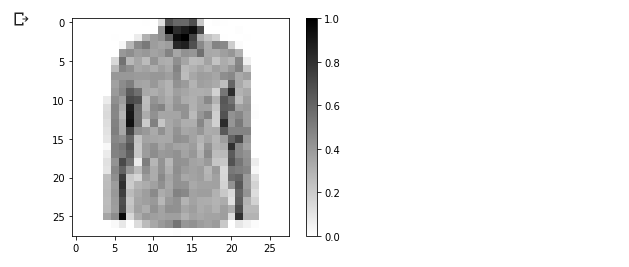
我们显示训练数据集中的前25个图像,并在每个图像下方指示其所属的类别。
确保数据格式正确,我们准备开始创建和训练网络。
plt.figure(figsize=(10,10)) i = 0 for (image, label) in test_dataset.take(25): image = image.numpy().reshape((28,28)) plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(image, cmap=plt.cm.binary) plt.xlabel(class_names[label]) i += 1 plt.show()

建立模型
建立神经网络需要调整图层,然后组装具有优化和损失函数的模型。
自定义图层
建立神经网络的基本元素是层。 该层从输入数据中提取视图。 通过多层连接的工作结果,我们得到了解决该问题的观点。
大多数时候,您在进行深度学习时都会在简单层之间创建链接。 例如,大多数图层,例如tf.keras.layers.Dense,都有一组可以在学习过程中“拟合”的参数。
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
网络由三层组成:
- 输入
tf.keras.layers.Flatten此层将尺寸为28x28像素的图像转换为尺寸为784(28 * 28)的一维数组。 在这一层上,我们没有用于训练的参数,因为该层仅处理输入数据的转换。 - 隐藏层
tf.keras.layers.Dense -128个神经元的紧密连接层。 每个神经元(节点)都将前一层的所有784个值作为输入,在训练过程中根据内部权重和位移来更改输入值,然后将单个值返回到下一层。 - 输出层
ts.keras.layers.Dense - softmax由10个神经元组成,每个神经元代表一类特定的服装元素。 与上一层一样,每个神经元都接收上一层所有128个神经元的输入值。 在训练过程中,该层上每个神经元的权重和位移都会发生变化,因此结果值的范围为[0,1] ,表示图像属于此类的概率。 10个神经元的所有输出值的总和为1。
编译模型
在我们开始训练模型之前,还需要进行一些设置。 这些设置是在模型组装期间通过调用compile方法进行的:
- 损失函数 -一种用于测量所需值与预测值之间距离的算法。
- 优化函数 -一种“拟合”模型内部参数(权重和偏移量)以最小化损失函数的算法;
- 指标 -用于监视培训过程和测试。 下面的示例使用诸如
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
我们训练模型
首先,我们根据训练数据集确定训练过程中的动作顺序:
- 使用
dataset.repeat()方法将输入数据集重复无数次dataset.repeat()以下描述的epochs参数确定要执行的所有训练迭代的次数) dataset.shuffle(60000)方法混合了所有图像,因此我们模型的训练不受输入数据输入顺序的影响。model.fit dataset.batch(32)方法告诉model.fit训练model.fit更新模型的内部变量时都使用32个图像的块和标签。
通过调用
model.fit方法进行培训:
- 将
train_dataset发送到模型输入。 - 该模型学习将输入图像与标签匹配。
- 参数
epochs=5将训练次数限制为对数据集进行5次完整训练迭代,最终使我们可以进行5 * 60,000 = 300,000个示例的训练。
(您可以忽略
steps_per_epoch参数,不久该参数将被从方法中排除)。
BATCH_SIZE = 32 train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE) test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
这是结论:
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
在模型训练期间,将为每次训练迭代显示损失函数的值和准确性度量。 该模型在训练数据上达到约0.88(88%)的精度。
检查准确性
让我们检查一下模型在测试数据上产生的精度。 我们将使用测试数据集中的所有示例来检查准确性。
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE)) print(" : ", test_accuracy)
结论:
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
: 0.8793
如您所见,结果证明测试数据集的准确性小于训练数据集的准确性。 这是很正常的,因为模型是在train_dataset数据上训练的。 当模型发现一个从未见过的图像时(来自train_dataset数据集),显然分类效率会降低。
预测和探索
我们可以使用经过训练的模型来获得一些图像的预测。
for test_images, test_labels in test_dataset.take(1): test_images = test_images.numpy() test_labels = test_labels.numpy() predictions = model.predict(test_images)
predictions.shape
结论:在上面的示例中,模型为每个测试输入图像预测了标签。让我们看一下第一个预测:(32, 10)
predictions[0]
结论: array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05, 6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09, 8.4999456e-06, 1.0296091e-09], dtype=float32)
回想一下,模型预测是10个值的数组。这些值描述了模型对输入图像属于特定类别(服装项目)的“信心”。我们可以看到最大值如下: np.argmax(predictions[0])
结论: 6
这意味着模型最有信心该图像属于标记为6的类(class_names [6])。我们可以检查并确保结果正确,并且正确无误: test_labels[0]
6
我们可以显示所有输入图像以及10类的相应模型预测: def plot_image(i, predictions_array, true_labels, images): predictions_array, true_label, img = predictions_array[i], true_label[i], images[i] plt.grid(False) plt.xticks([]) plt.yticks([]) plt.imshow(img[...,0], cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array) if predicted_label == true_label: color = 'blue' else: color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], 100 * np.max(predictions_array), class_names[true_label]), color=color) def plot_value_array(i, predictions_array, true_label): predictions_array, true_label = predictions_array[i], true_label[i] plt.grid(False) plt.xticks([]) plt.yticks([]) thisplot = plt.bar(range(10), predictions_array, color="#777777") plt.ylim([0, 1]) predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red') thisplot[true_label].set_color('blue')
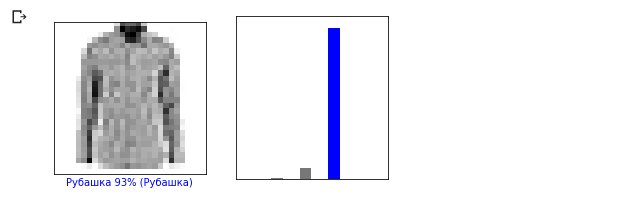
让我们看一下第0张图像,模型的预测结果和预测数组。 i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
i = 12 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels)
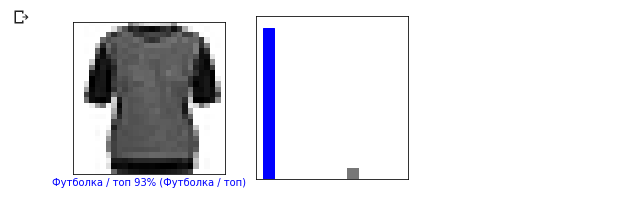 现在让我们显示一些带有各自预测的图像。正确的预测为蓝色,错误的预测为红色。图像下方的值反映输入图像对应于此类的置信度百分比。请注意,即使“ confidence”值很高,结果也可能不正确。
现在让我们显示一些带有各自预测的图像。正确的预测为蓝色,错误的预测为红色。图像下方的值反映输入图像对应于此类的置信度百分比。请注意,即使“ confidence”值很高,结果也可能不正确。 num_rows = 5 num_cols = 3 num_images = num_rows * num_cols plt.figure(figsize=(2*2*num_cols, 2*num_rows)) for i in range(num_images): plt.subplot(num_rows, 2*num_cols, 2*i + 1) plot_image(i, predictions, test_labels, test_images) plt.subplot(num_rows, 2*num_cols, 2*i + 2) plot_value_array(i, predictions, test_labels)
 使用训练有素的模型来预测单个图像的标签:
使用训练有素的模型来预测单个图像的标签: img = test_images[0] print(img.shape)
结论: (28, 28, 1)
中的模型tf.keras针对按块(集合)的预测进行了优化。因此,尽管事实是我们只使用一个元素,但仍需要将其添加到列表中: img = np.array([img]) print(img.shape)
结论:(1, 28, 28, 1)现在我们将预测结果: predictions_single = model.predict(img) print(predictions_single)
结论: [[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02 1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels) _ = plt.xticks(range(10), class_names, rotation=45)
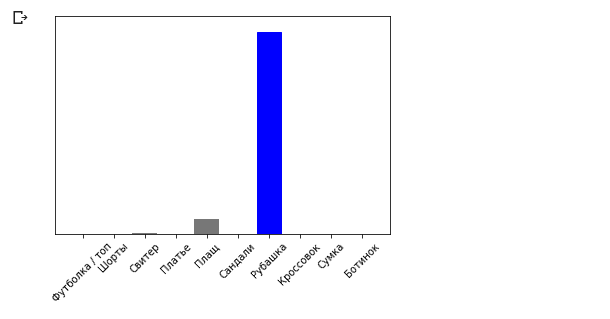 model.predict方法返回列表列表(数组的数组),每个列表用于输入块中的图像。对于单个输入图像,我们得到唯一的结果:
model.predict方法返回列表列表(数组的数组),每个列表用于输入块中的图像。对于单个输入图像,我们得到唯一的结果: np.argmax(predictions_single[0])
结论: 6
如前所述,该模型预测标签6(衬衫)。练习题
尝试不同的模型,看看准确性将如何变化。特别是,请尝试更改以下设置:- 将epochs参数设置为1;
- 例如,将隐藏层中的神经元数量从10的低值更改为512,并查看预测模型的准确性将如何变化;
- 在平坦层(平滑层)和最终的致密层之间添加其他层,并在该层上试验神经元的数量;
- 不要标准化像素值,看看会发生什么。
请记住激活GPU,以便所有计算都更快(Runtime -> Change runtime type -> Hardware accelertor -> GPU)。另外,如果在操作过程中遇到问题,请尝试重置全局环境设置:Edit -> Clear all outputsRuntime -> Reset all runtimes
摄氏度VS MNIST
-在这一阶段,我们已经遇到了两种类型的神经网络。我们的第一个神经网络学习了如何将摄氏温度转换为华氏温度,并返回可以在广泛数值范围内的单个值。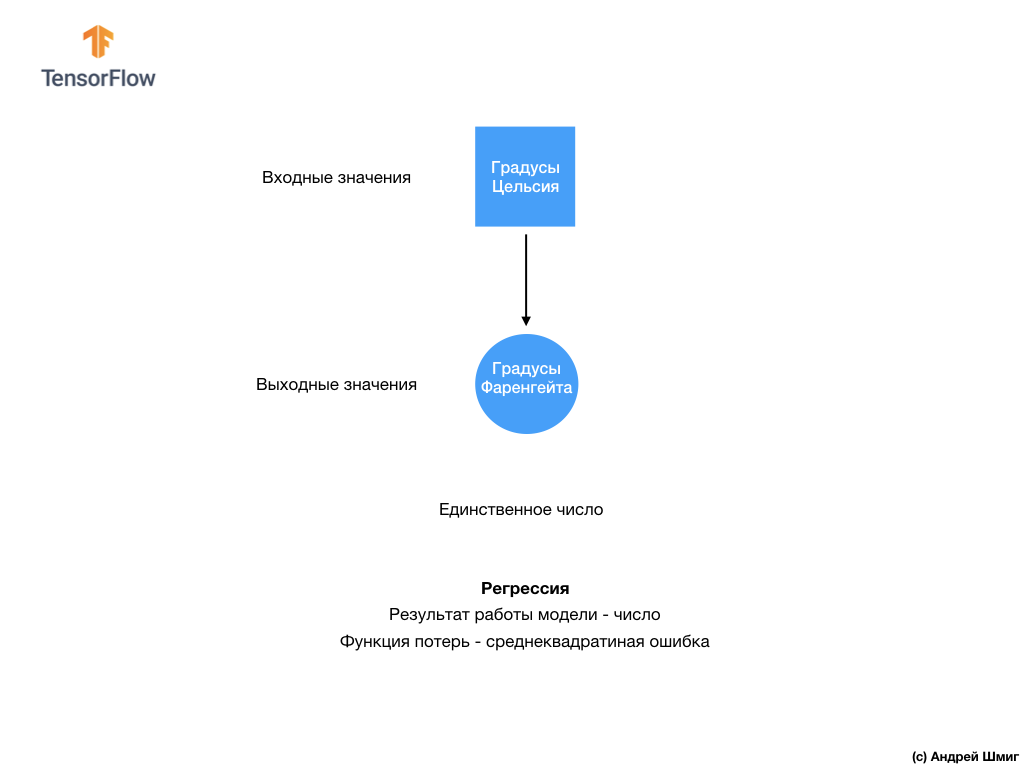 我们的第二个神经网络返回10个概率值,这些值反映了网络对输入图像对应于特定类别的信心。神经网络可用于解决各种问题。
我们的第二个神经网络返回10个概率值,这些值反映了网络对输入图像对应于特定类别的信心。神经网络可用于解决各种问题。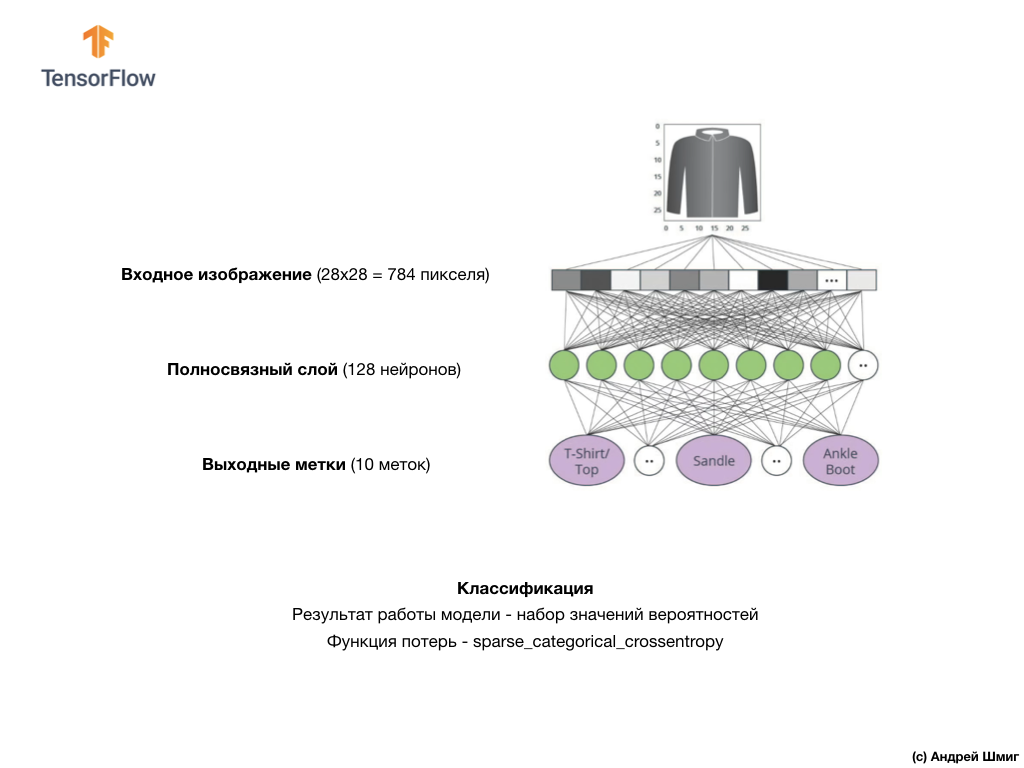 我们通过预测单个值解决的第一类问题称为回归
我们通过预测单个值解决的第一类问题称为回归 . . , , .
, ,
. («» , ). , 10 , , — , .
让我们总结并注意这两类问题之间的区别- 回归和分类。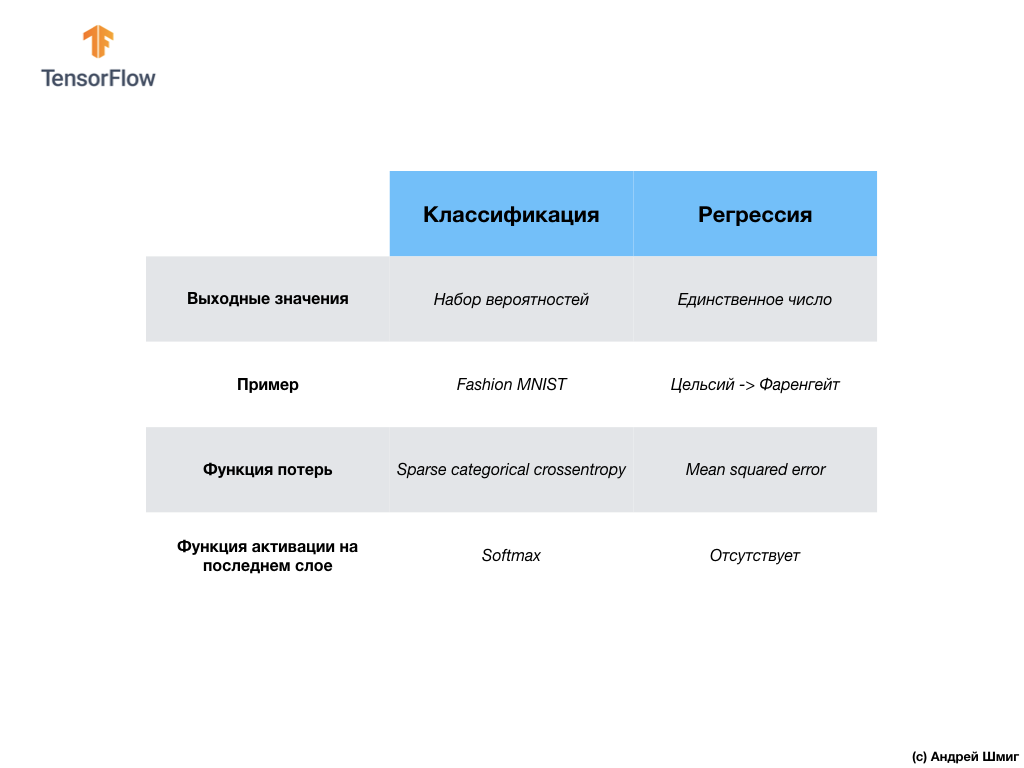 恭喜,您已经研究了两种类型的神经网络!为下一次演讲做准备,在那里我们将学习一种新型的神经网络-卷积神经网络(CNN)。
恭喜,您已经研究了两种类型的神经网络!为下一次演讲做准备,在那里我们将学习一种新型的神经网络-卷积神经网络(CNN)。总结
在本课程中,我们训练了神经网络对服装元素进行图像分类。为此,我们使用了Fashion MNIST数据集,其中包含70,000张服装图片。其中60,000个我们用来训练神经网络,其余的10,000个用来测试其工作的有效性。为了将这些图像提交到神经网络的输入,我们需要将它们从28x28 2D格式转换(平滑)为784个元素的1D格式。我们的网络由128个神经元的完全连接层和10个神经元的输出层组成,对应于标签的数量(类别,服装项目类别)。这10个输出值代表每个类别的概率分布。Softmax激活功能计算概率分布。我们还了解了回归和分类之间的区别。- 回归:返回单个值(例如房屋价值)的模型。
- 分类:返回几个类别之间的概率分布的模型。例如,在我们与Fashion MNIST的任务中,输出值为10个概率值,每个概率值都与特定类别(服装项目类别)相关联。我提醒您,我们使用softmax激活函数只是为了获得最后一层的概率分布。
文章的视频版本该视频在发布几天后发布,并已添加到文章中。
...和标准号召性用语-注册,加号并分享:)
YouTube的电报VKontakte