
不久前,一个不愉快的故事发生在我身上,这触发了github上一个小项目,并引发了这篇文章。
典型的一天是定期发布:所有任务均由我们的质量检查工程师进行上下检查,因此,在这头圣牛的平静中,我们“滚动”到了舞台。 该应用程序在日志中表现良好-静音。 我们决定进行切换(阶段<->生产)。 我们切换,看看设备...
它需要几分钟,飞行稳定。 质量检查工程师进行了烟雾测试,发现该应用程序以某种不自然的方式减慢了速度。 我们注销以预热缓存。
几分钟后,第一行的第一个抱怨:从客户端下载数据的时间很长,应用程序运行缓慢,响应时间很长,等等。 我们开始担心……我们查看日志,寻找可能的原因。
几分钟后,DB管理员收到一封信。 他们写道,查询数据库(以下简称数据库)的执行时间已经突破了所有可能的界限,并且趋于无限。
我打开监视(我使用
JavaMelody ),发现了这些请求。 我重新启动PGAdmin。 真长。 我添加“解释”,然后查看执行计划……就是,我们忘记了索引。
为什么代码审查不够?
那件事使我受益匪浅。 是的,我“灭火”了一个小时,以某种方式直接在产品上创建了正确的索引(请不要忘记CONCURRENTLY选项):
CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_pets_name ON pets_table (name_column);
同意,这等同于停机。 对于我正在处理的应用程序,这是不可接受的。
我得出了结论,并在清单中添加了一个特殊的粗体以进行代码审查:如果我发现在开发过程中添加/更改了一个Repository类之一-我检查sql迁移中是否存在在其中创建和更改索引的脚本。 如果他不在那儿,我正在写给作者一个问题:他确定这里不需要索引吗?
如果数据很少,可能不需要索引,但是如果我们使用的表中的行数以百万为单位,则索引错误可能会致命,并导致出现本文开头的故事。
在这种情况下,我要求拉取请求(以下简称PR)的作者100%确保索引在他在HQL中编写的查询至少部分覆盖(使用索引扫描)。 为此,开发人员:
- 启动应用程序
- 在日志中寻找转换后的(HQL-> SQL)查询
- 打开PGAdmin或其他数据库管理工具
- 为了避免干扰实验,在本地数据库中生成了可以接受的测试数据量(至少10K-20K记录)
- 满足要求
- 要求执行计划
- 仔细研究并得出适当的结论
- 添加/修改索引,确保执行计划适合它
- 在PR中取消订阅请求覆盖范围已检查的订阅
- 通过专家评估请求的风险和严重性,我可以仔细检查其操作
很多例行行动和人为因素,但一段时间以来,我感到满意,并以此为生。
在回家的路上
他们说,至少有时候下班时不听音乐/播客非常有用。 这时候,只要思考生活,就可以得出有趣的结论和想法。
有一天,我回家,想着那天发生了什么。 有一些评论,我用清单核对了每个评论,并进行了上述一系列操作。 那个时候我太累了,我想,这到底是什么? 是否可以自动执行此操作?..我采取了一个快速步骤,希望快速“切开”这个想法。
问题陈述
在执行计划中,对开发人员最重要的是什么?
当然,由于缺少索引,seq扫描了大量数据。
因此,有必要进行以下测试:
- 在具有类似于prod的配置的数据库上执行
- 拦截由JPA存储库(Hibernate)进行的数据库查询
- 获取执行计划
- 解析执行计划,将其布置在便于检查的数据结构中
- 使用一组方便的Assert方法,检查期望。 例如,不使用seq扫描。
有必要通过制作原型来快速检验该假设。
解决方案架构
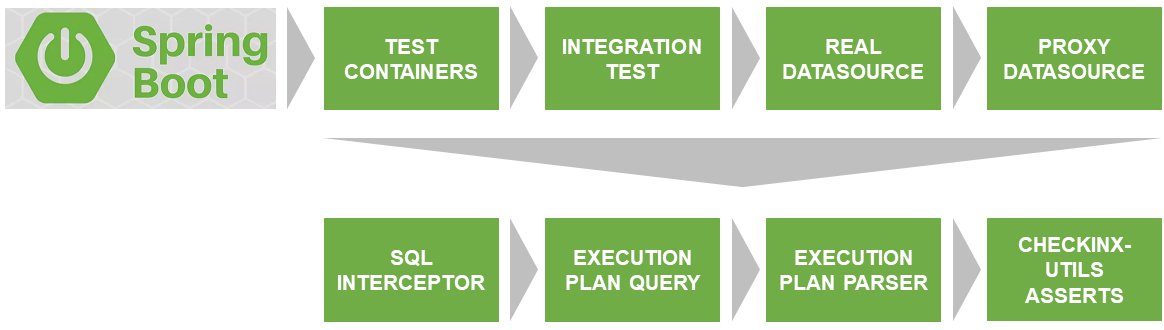
要解决的第一个问题是在与版本和设置与产品上使用的版本和设置相匹配的真实数据库上启动测试。
感谢
Docker和TestContainers ,他们解决了这个问题。
SqlInterceptor,ExecutionPlanQuery,ExecutionPlanParse和AssertService是我目前为Postgres实现的接口。 该计划将为其他数据库实施。 如果您想参加-欢迎。 该代码是用Kotlin编写的。
这一切我都在GitHub上发布,并称为
checkinx-utils 。 您无需重复此步骤,只需将依赖关系连接到maven / gradle中的checkinx并使用方便的断言即可。 如何执行此操作,我将在下面更详细地描述。
CheckInx组件交互的描述
ProxyDataSource
要解决的第一个问题是拦截准备执行的数据库查询。 已经建立了参数,没有问题等。
为此,您需要将实际的dataSource包装在某个Proxy中,这将使您可以集成到查询执行管道中并相应地对其进行拦截。
这样的ProxyDataSource已被许多人实现。 我使用了现成的
ttddyy解决方案,该解决方案使我可以安装侦听器来拦截所需的请求。
我使用DataSourceWrapper(BeanPostProcessor)类替换了源DataSource。
SqlInterceptor
实际上,其start()方法在proxyDataSource中设置其侦听器并开始拦截请求,并将其存储在内部语句列表中。 stop()方法分别删除已安装的侦听器。
执行计划查询
在这里,原始请求被转换为对执行计划的请求。 对于Postgres,这是对查询关键字“ EXPLAIN”的补充。
此外,此查询是从测试容器在同一数据库上执行的,并返回“原始”执行计划(行列表)。
ExecutionPlanParser
使用原始执行计划很不方便。 因此,我将其解析为一个由节点组成的树(PlanNode)。
让我们使用一个真实的ExecutionPlan的示例来分析PlanNode字段:
Index Scan using ix_pets_age on pets (cost=0.29..8.77 rows=1 width=36) Index Cond: (age < 10) Filter: ((name)::text = 'Jack'::text)
AssertService
解析器返回的数据结构已经可以正常工作。 CheckInxAssertService是上述PlanNode树的一组检查。 它允许您设置自己的支票lambda,或使用我认为最受欢迎的预定义lambda。 例如,以便您的查询没有Seq扫描,或者您要确保使用/不使用特定索引。
覆盖水平
非常重要的Enum,我将分别描述:
接下来,我们将看一些使用示例。
使用CheckInx的测试示例
我在GitHub
checkinx-demo上做了一个单独的项目,在这里我为pets表实现了一个JPA存储库,并为此存储库进行了测试以检查覆盖率,索引等。 以那里为起点将很有用。
您可能会进行如下测试:
@Test fun testFindByLocation() {
实施计划可以如下:
Index Scan using ix_pets_location on pets pet0_ (cost=0.29..4.30 rows=1 width=46) Index Cond: ((location)::text = 'Moscow'::text)
...或者像这样,如果我们忘记了索引(测试变成红色):
Seq Scan on pets pet0_ (cost=0.00..19.00 rows=4 width=84) Filter: ((location)::text = 'Moscow'::text)
在我的项目中,我主要使用最简单的断言,即执行计划中没有Seq扫描:
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])
这种测试的存在表明我至少研究了实施计划。
它还使项目管理更加明确,并且代码的可记录性和可预测性增加。
体验模式我建议使用CheckInxAssertService,但如有必要,您可以自己绕过解析的树(ExecutionPlanParser),或者通常解析原始执行计划(执行ExecutionPlanQuery的结果)。
@Test fun testFindByLocation() {
连接到项目
在我的项目中,我将此类测试分配给一个单独的组,称为密集集成测试。
连接和开始使用checkinx-utils很容易。 让我们从构建脚本开始。
首先连接存储库。 有一天,我会将checkinx上传到Maven,但是现在您只能通过jitpack从GitHub下载工件。
repositories { // ... maven { url 'https://jitpack.io' } }
接下来,添加依赖项:
dependencies { // ... implementation 'com.github.tinkoffcreditsystems:checkinx-utils:0.2.0' }
我们通过添加配置来完成连接。 当前仅支持Postgres。
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig
注意测试配置文件。 否则,您将在产品中找到ProxyDataSource。
PostgresConfig连接几个bean:
- 数据源包装器
- Postgres拦截器
- PostgresExecutionPlanParser
- PostgresExecutionPlanQuery
- CheckInxAssertServiceImpl
如果您需要当前API不提供的某种自定义功能,则可以始终用实现替换其中一个bean。
已知问题
有时,由于Spring CGLIB代理,DataSourceWrapper无法替换原始数据源。 在这种情况下,BeanPostProcessor不能使用数据源,而是ScopedProxyFactoryBean可以使用类型检查。
最简单的解决方案是手动创建HikariDataSource进行测试。 然后,您的配置将如下所示:
@Profile("test") @ImportAutoConfiguration(classes = [PostgresConfig::class]) @Configuration open class CheckInxConfig { @Primary @Bean @ConfigurationProperties("spring.datasource") open fun dataSource(): DataSource { return DataSourceBuilder.create() .type(HikariDataSource::class.<i>java</i>) .build() } @Bean @ConfigurationProperties("spring.datasource.configuration") open fun dataSource(properties: DataSourceProperties): HikariDataSource { return properties.initializeDataSourceBuilder() .type(HikariDataSource::class.<i>java</i>) .build() } }
发展计划
- 我想了解我以外是否需要此服务? 为此,创建一个调查。 我很乐意诚实回答。
- 查看您真正需要的内容,并扩展assert方法的标准列表。
- 编写其他数据库的实现。
- sqlInterceptor.statements [0]的构造看起来不是很明显,我想对其进行改进。
如果有人想加入Kotlin并从中获得一些荣誉,我将感到非常高兴。
结论
我敢肯定会有评论:
无法预测查询计划程序在产品上的表现,这完全取决于收集到的统计信息 。
的确是一个计划者。 使用先前收集的统计信息,它可以制定与所测试的计划不同的计划。 含义有所不同。
计划者的任务是改进而不是恶化请求。 因此,没有明显的原因,他不会突然使用Seq Scan,但是您可以在不知不觉中。
您需要CheckInx,以便在编写测试时不要忘记研究查询执行计划并考虑创建索引的可能性,反之亦然,通过测试清楚地表明此处不需要索引,并且您对Seq Scan感到满意。 这样可以避免您在代码审查中遇到不必要的问题。
参考文献
- https://github.com/TinkoffCreditSystems/checkinx-utils
- https://github.com/dsemyriazhko/checkinx-demo
- https://github.com/ttddyy/datasource-proxy
- https://mvnrepository.com/artifact/org.testcontainers/postgresql
- https://github.com/javamelody/javamelody/wiki