大家好 我叫Danila,我在一个致力于Avito开发分析基础架构的团队中工作。 此基础架构的核心是A / B测试。
A / B实验是Avito中的关键决策工具。 在我们的产品开发周期中,必须进行A / B测试。 我们检验每个假设,只推出积极的变化。
我们收集数百个指标,并能够将其深入到业务部门:垂直行业,区域,授权用户等。我们使用单个平台进行实验来自动执行此操作。 在本文中,我将详细介绍平台的布置方式,并深入探讨一些有趣的技术细节。

A / B平台的主要功能表述如下。
- 帮助您快速进行实验
- 控制不必要的实验路口
- 统计指标,统计信息。 测试,可视化结果
换句话说,该平台可帮助您快速做出无错误的决策。
如果我们忽略了开发要发送给测试的功能的过程,则整个实验周期如下所示:

- 客户(分析师或产品经理)通过管理面板配置实验参数。
- 拆分服务根据这些参数将必要的A / B组分配给客户端设备。
- 用户操作收集在原始日志中,这些日志经过汇总并变成度量标准。
- 指标通过统计测试运行。
- 启动后的第二天,结果就会在内部门户上显示。
一个周期中的所有数据传输需要一天的时间。 通常,实验会持续一周,但客户每天都会收到越来越多的结果。
现在让我们深入研究细节。
实验管理
管理面板使用YAML格式配置实验。

对于小型团队来说,这是一个方便的解决方案:最终确定配置功能确实没有先例。 使用文本配置可简化用户的工作:您只需用鼠标点击几次即可。 Airbnb A / B框架使用了类似的解决方案。
为了将流量分为几类,我们使用通用的盐哈希技术。
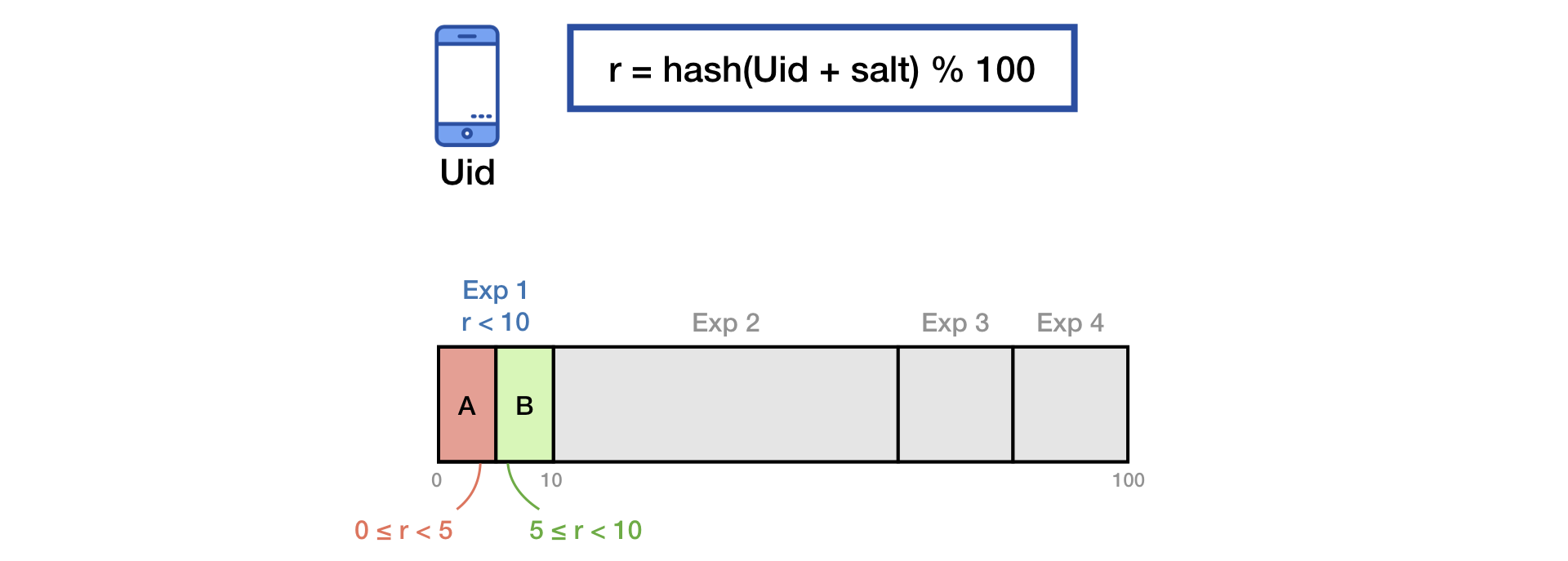
为了消除用户的“记忆”效应,在开始新实验时,我们会与第二种盐进行额外的混合:

Yandex的介绍中描述了相同的原理。
为了防止潜在的危险实验交叉,我们使用类似于Google中的“图层”的逻辑。
指标收集
我们将原始日志放入Vertica中,并将其汇总到结构如下的准备表中:

观察通常是简单的事件计数器。 观测值用作度量标准计算公式中的组成部分。
用于计算任何度量的公式是分数,以分子和分母表示的是观测值的总和:
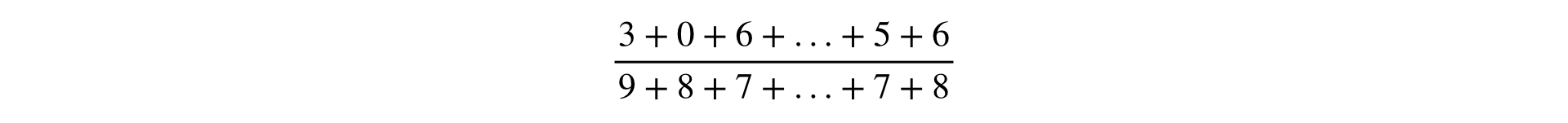
在Yandex的一份报告中,指标分为两种类型:按用户和比率。 这具有商业意义,但是在基础架构中,以与比率相同的方式考虑所有指标更为方便。 这种概括是有效的,因为“ posyuzerny”度量显然可以表示为分数:
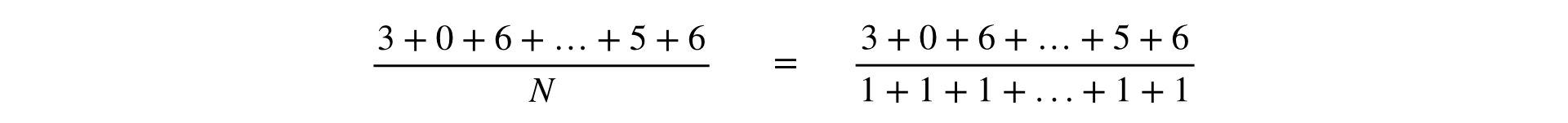
我们以两种方式总结度量的分子和分母中的观察结果。
简单:
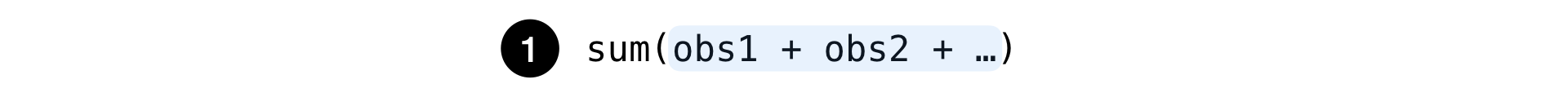
这是任何一组观察值的通常数量:搜索次数,广告点击次数等。
更复杂的是:

唯一的键数,在分组中,观察的总数大于给定的阈值。
可以使用YAML配置轻松设置此类公式:

groupby和threshold参数是可选的。 他们只是确定第二种求和方法。
所描述的标准允许您配置几乎所有可以想到的在线指标。 同时,保留了简单的逻辑,不会对基础结构造成过多的负担。
统计标准
我们使用传统方法( T检验 , Mann-Whitney U检验)通过量度度量偏差的重要性。 应用这些标准的主要必要条件是样品中的观测值不应相互依赖。 在几乎所有的实验中,我们都认为用户(Uid)满足此条件。

现在出现了一个问题:如何对比率指标进行T检验和MW检验? 对于T检验,您需要能够读取样本的方差,对于MW,样本应该是“用户定义的”。
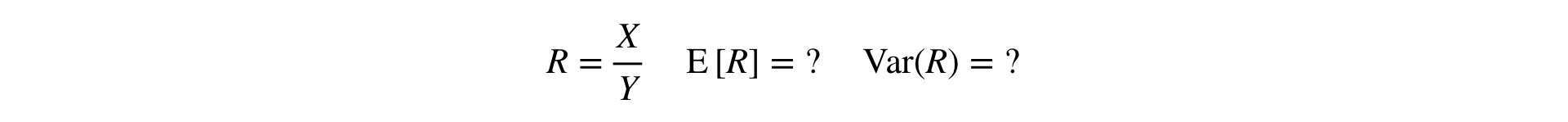
答:您需要将泰勒级数中的比率扩展到一点 (E\左[X\右],E\左[Y\右]) :
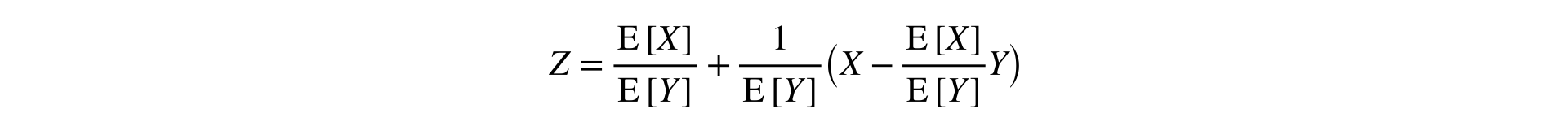
此公式将两个样本(分子和分母)转换为一个样本,保留均值和方差(渐近),这允许使用经典统计量。 测试。
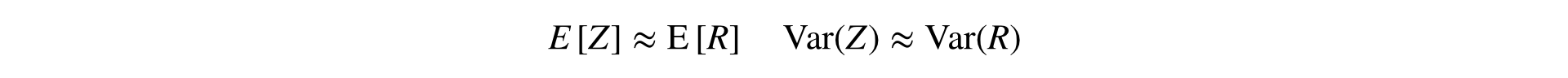
Yandex的同事将类似的想法称为比率线性化方法( 一次和两次出现)。
缩放性能
快速使用CPU统计信息。 标准使得在具有56个核的完全普通的服务器上,可以在几分钟内完成数百万次迭代(处理与控制比较)。 但是,在海量数据的情况下,性能首先取决于存储和从磁盘读取时间。
每天计算Uid指标会生成总值达数千亿的样本(由于大量同时进行的实验,数百个指标和累积积累)。 每天都无法从磁盘中挤出此类卷(尽管Vertica列基础的群集很大),这太麻烦了。 因此,我们被迫减少数据的基数。 但是我们使用称为“桶”的技术几乎不会丢失有关方差的信息。
这个想法很简单:我们拥有Uid,并根据除法的其余部分,将它们“分散”到多个存储桶中(用B表示它们的数字):
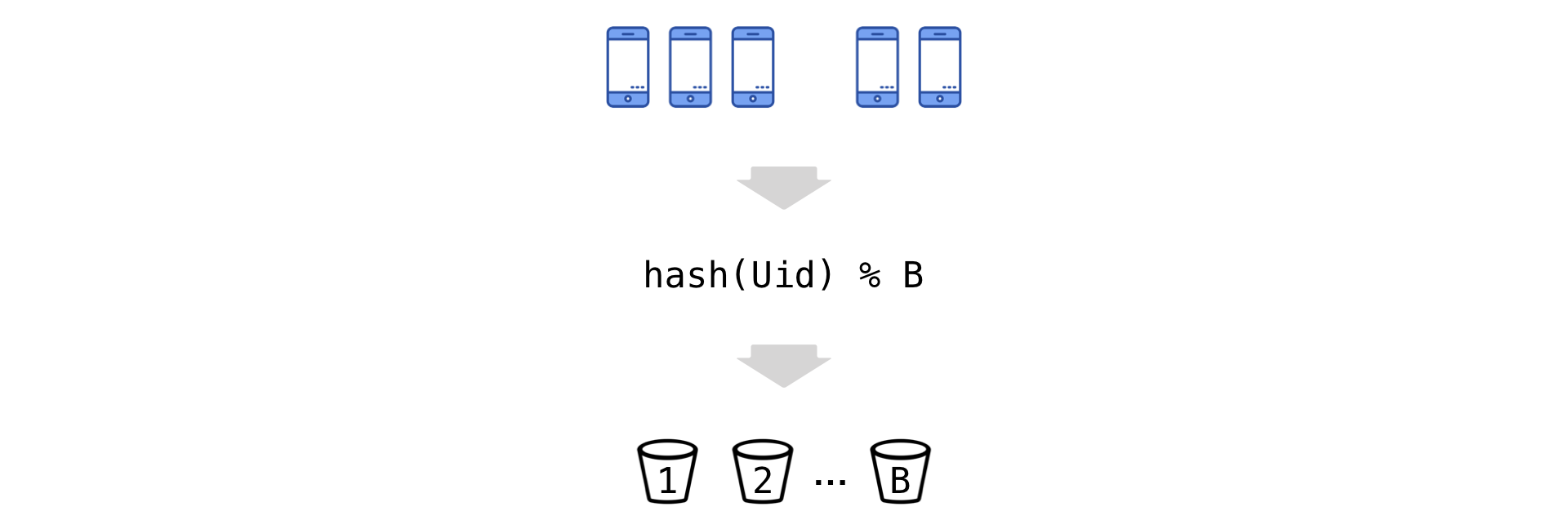
现在我们转到新的实验单元-铲斗。 我们总结一下桶中的观察结果(分子和分母是独立的):

通过这种转换,满足了观测独立性的条件,度量值不发生变化,并且很容易验证度量的方差(观测样本的平均值)是否得以保留:

存储桶越多,丢失的信息越少,相等性错误就越小。 在Avito中,我们取B = 200。
铲斗转换后的度量分布密度始终变得与正常相似。
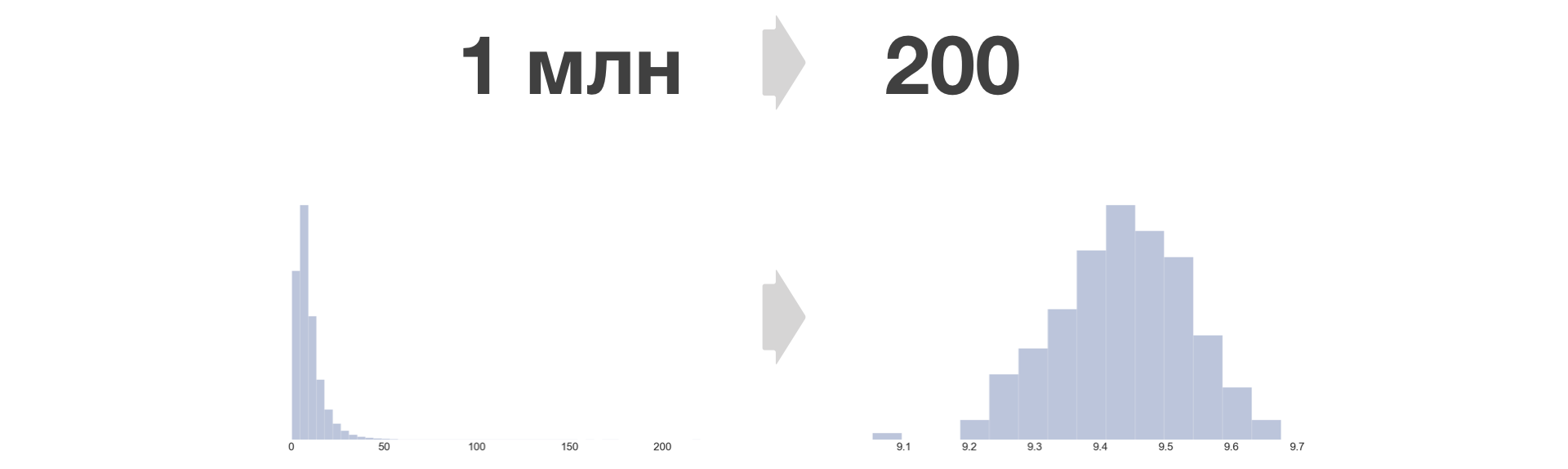
您可以将任意数量的大样本缩小为固定大小。 在这种情况下,存储数据量的增长仅线性地取决于实验和指标的数量。
结果可视化
作为可视化工具,我们在Tableau Server上使用Tableau和Webview。 每个Avito员工都可以在那里访问。 应该注意的是,Tableau做得很好。 要使用完整的后端/前端开发来实现类似的解决方案,将需要大量资源。
每个实验的结果都是几千个数字。 在执行第一类和第二类错误的情况下,可视化必须能够最大程度地减少错误的结论,并且同时不要“遗漏”重要指标和部分中的更改。
首先,我们监控实验的“健康”指标。 也就是说,我们回答以下问题:“是否确实将参与者“倾注”到每个组中?”,“是否等于授权用户或新用户?”
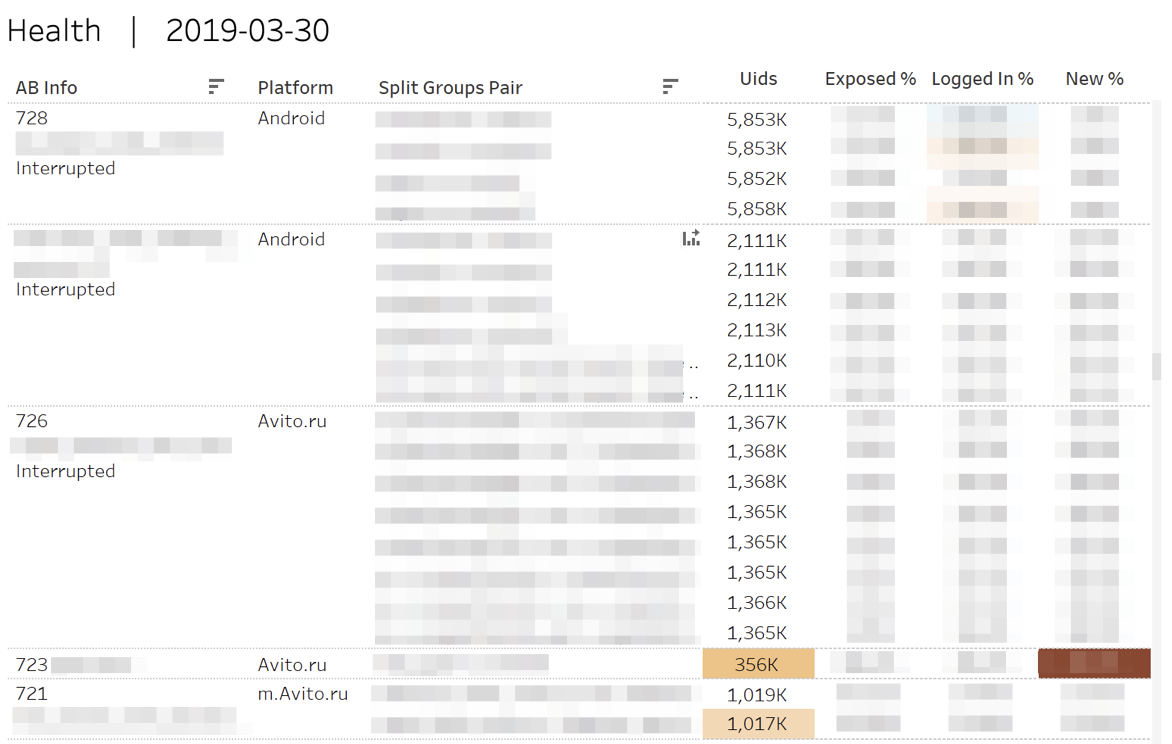
在统计上有重大偏差的情况下,突出显示相应的单元格。 当您将鼠标悬停在任意数字上时,将显示当天的累计动态。
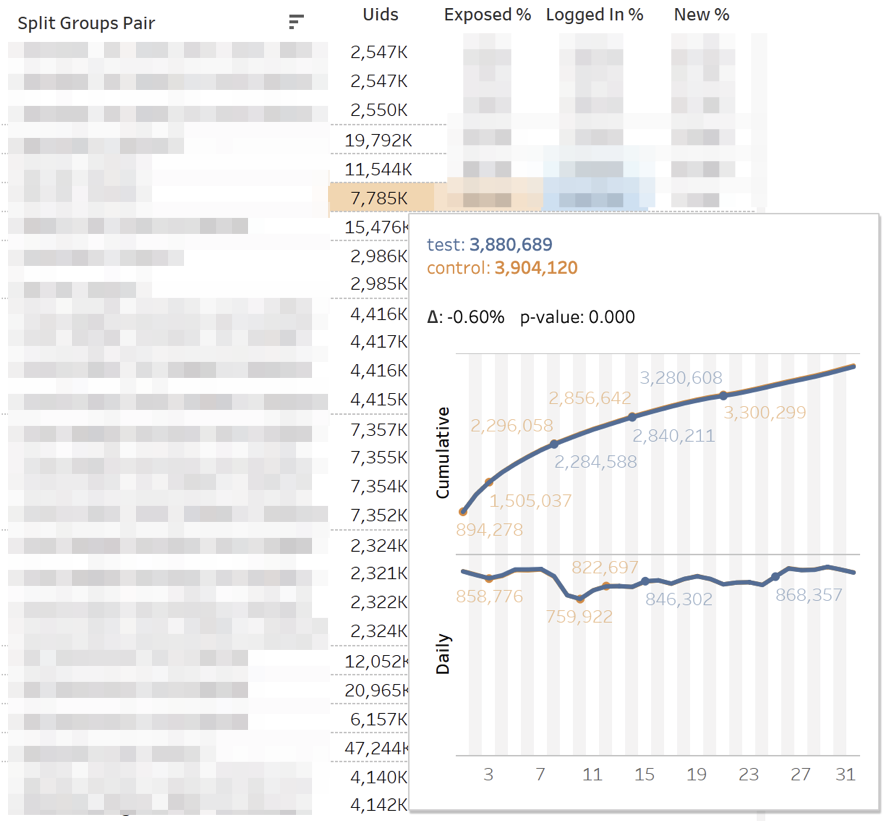
带有指标的主仪表板如下所示:
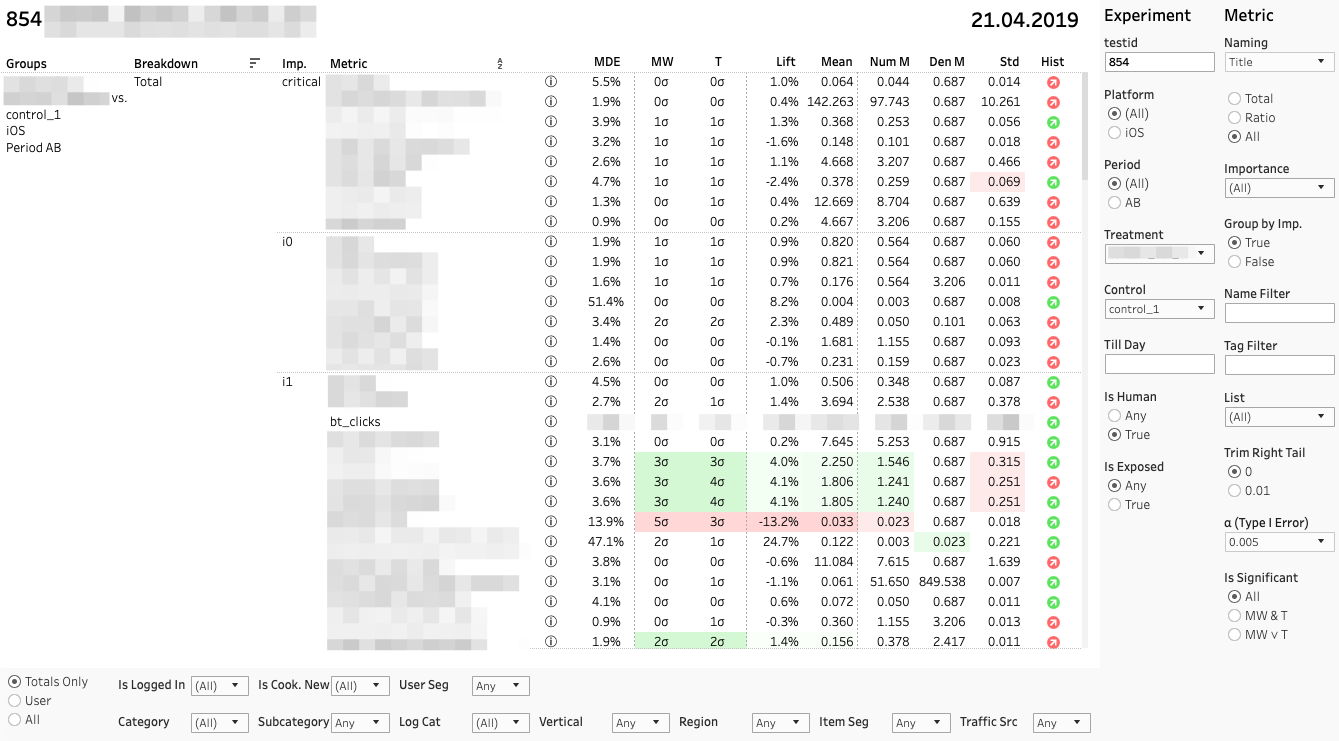
每行是特定部分中特定指标对组的比较。 右侧是带有用于实验和指标的过滤器的面板。 底部-部分过滤器面板。
每个指标比较均包含多个指标。 让我们从左到右分析它们的值:
1. MDE。 最小可检测效果

⍺和β是第一类和第二类的预选错误概率。 如果变化在统计上不显着,则MDE非常重要。 做出决定时,客户必须记住缺少统计信息。 意义并不等于没有效果。 足够可靠地,我们只能说可能的效果不超过MDE。
2.兆瓦| T.Mann-Whitney U和T检验结果
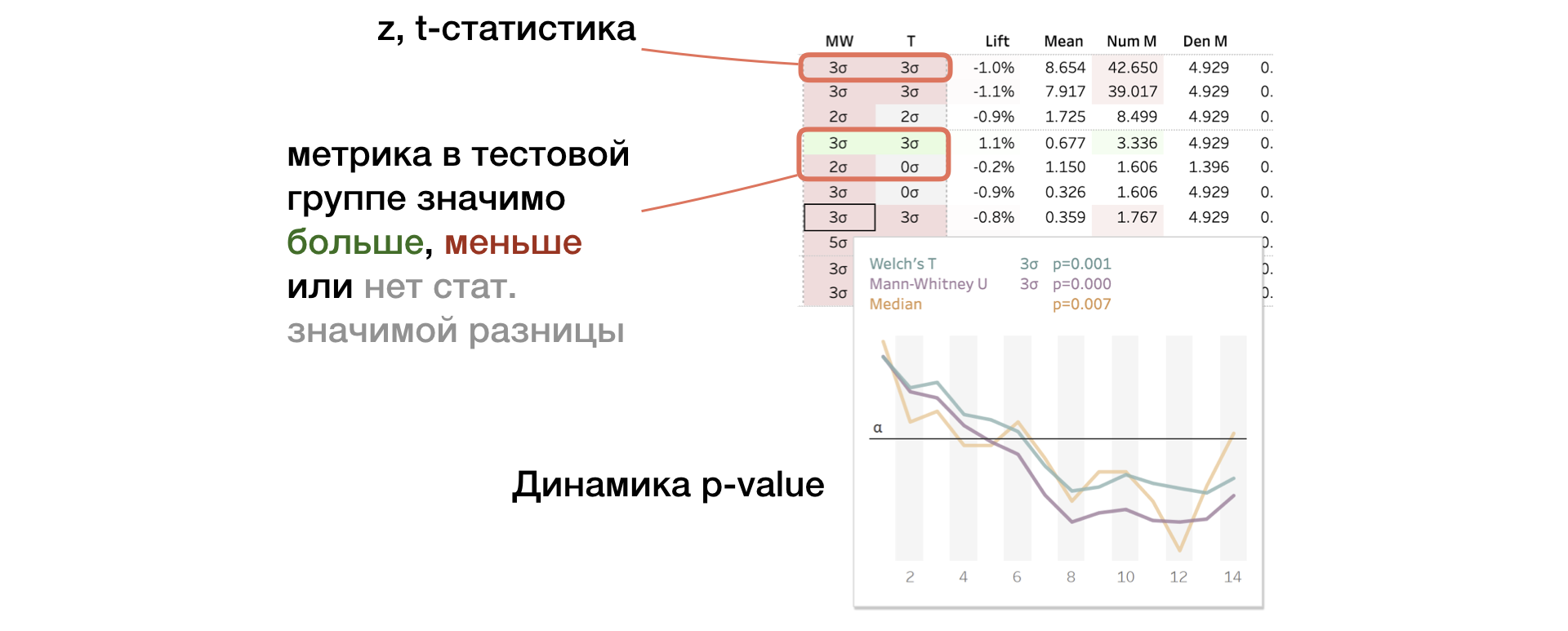
面板显示z统计量和t统计量的值(分别用于MW和T)。 在工具提示中-p值动态。 如果变化很大,则根据组之间差异的符号,单元格将以红色或绿色突出显示。 在这种情况下,我们说度量是“有色的”。
3.抬起。 组之间的百分比差异
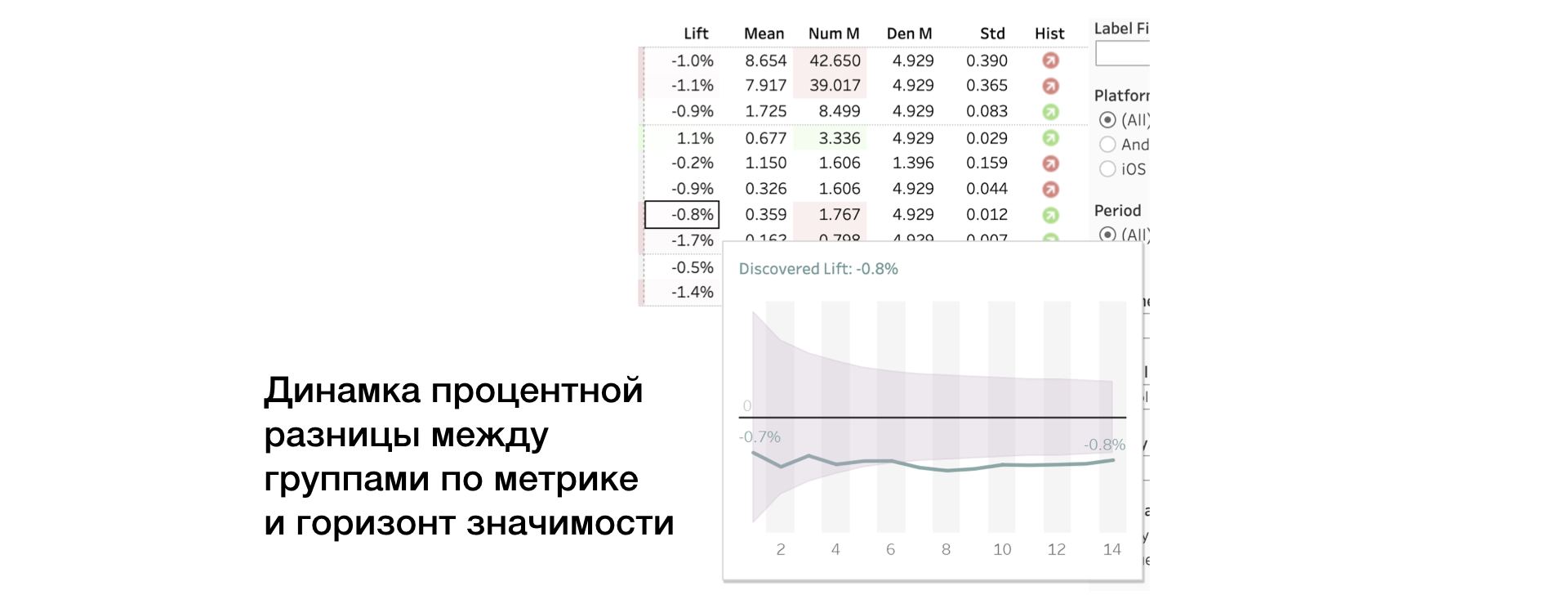
4.平均值| 编号 登 指标值,以及分子和分母
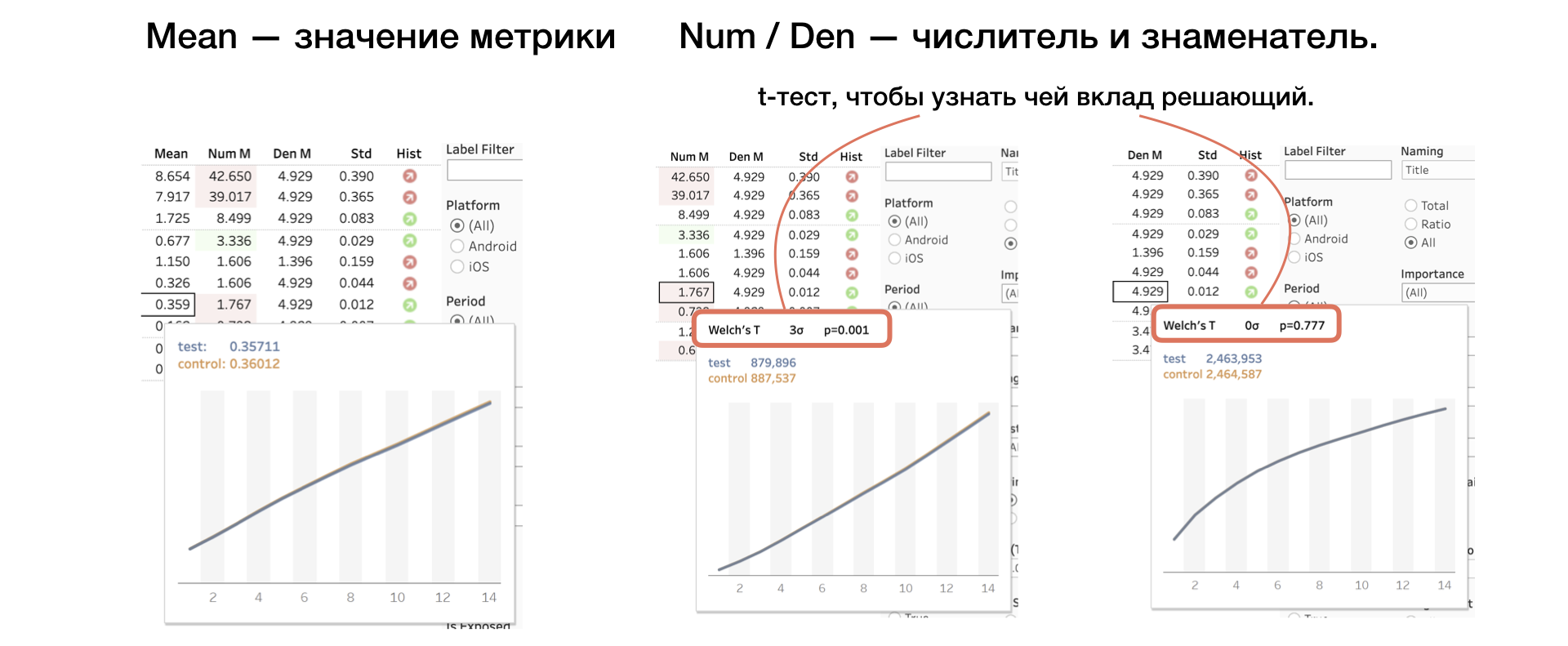
我们对分子和分母应用另一个T检验,这有助于了解谁的贡献是决定性的。
5.标准 选择性标准偏差
6.历史。 Shapiro-Wilk测试“桶”分布的正态性。
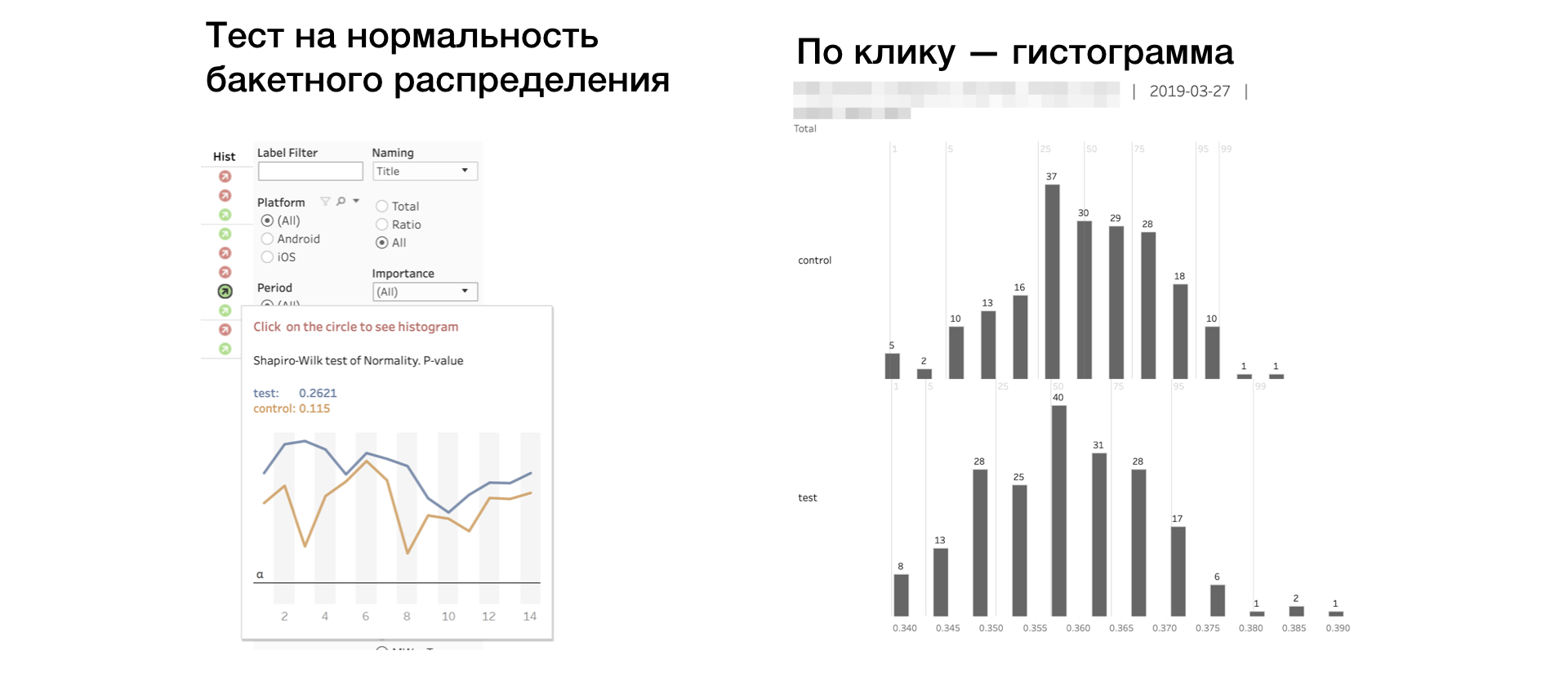
如果指示器为红色,则表明样品有异常值或异常长的尾巴。 在这种情况下,您需要根据此指标仔细或完全不考虑结果。 单击指标可按组打开指标的直方图。 直方图清楚地显示出异常-得出结论更容易。
结论
当我们的产品开始更快增长时,Avito中A / B平台的出现是一个分水岭。 每天,我们都会进行绿色实验,向团队负责; 和“红色”,可为您提供健康的思考。
我们设法建立了有效的A / B测试和指标体系。 我们经常用简单的方法解决复杂的问题。 由于这种简单性,基础结构具有良好的安全裕度。
我相信那些打算在他们的公司中构建A / B平台的人会在本文中找到一些有趣的见解。 我很高兴与您分享我们的经验。
写下问题和评论-我们将尽力回答。