大家好!
也许今天的出版物标题带有问号看起来会更好-很难说。 无论如何,今天我们想为您提供简短的导览,向您介绍
Dask库,该库旨在并行化Python中的任务。 我们希望将来能更彻底地回到这一主题。
 照片摄于
照片摄于毫无疑问,Dask是我遇到的最具革命性的数据处理工具。 如果您喜欢
Pandas和Numpy ,但有时您无法处理RAM中无法容纳的数据,那么Dask正是您所需要的。 Dask支持Pandas数据框架和Numpy数据结构(数组)。 Dask可以在本地计算机上运行或扩展,然后在群集中运行。 本质上,您只需编写一次代码,然后选择使用最通用的Python语法在本地计算机上使用它还是将其部署在许多节点的群集中。 该功能本身很棒,但是我决定写这篇文章只是为了强调:每个数据科学家(至少使用Python)都应该使用Dask。 从我的角度来看,Dask的神奇之处在于,通过最小化代码,您可以使用例如笔记本电脑上已经具备的计算能力来并行化它。 使用并行数据处理,程序运行速度更快,您需要等待的时间更少,因此,还有更多的时间用于分析。 特别是,在本文中,我们将讨论
dask.delayed对象及其如何适合数据科学任务流。
介绍Dask
作为对Dask的介绍,这里有几个示例,旨在让您大致了解其语法。 在这种情况下,我想建议的最重要的结论是,您已经拥有的知识将足以起作用。 您不必学习像Hadoop或Spark这样的新大数据工具。
Dask提供了3个并行集合,您可以在其中存储超出RAM大小的数据,即数据框,数据包和数组。 在每种类型的集合中,您可以通过在RAM和硬盘驱动器之间进行分段来存储数据,以及在群集中的多个节点之间分布数据。
Dask数据框由切细的数据框(例如Pandas中的数据框)组成,因此您可以使用Pandas查询语法中的部分功能。 下面是一个示例代码,该示例代码下载2018年的所有csv文件,解析带有时间戳的字段,并启动Pandas请求:
import dask.dataframe as dd df = dd.read_csv('logs/2018-*.*.csv', parse_dates=['timestamp']) df.groupby(df.timestamp.dt.hour).value.mean().compute()
Dask数据框示例在Dask Bag中,您可以存储和处理内存中不适合的Python对象的集合。 Dask Bag非常适合处理json格式的日志和文档集合。 在此代码示例中,将2018年的所有json文件加载到Dask Bag数据结构中,解析每个json记录,并使用lambda函数过滤用户数据:
import dask.bag as db import json records = db.read_text('data/2018-*-*.json').map(json.loads) records.filter(lambda d: d['username'] == 'Aneesha').pluck('id').frequencies()
达斯袋示例Dask Arrays数据结构支持Numpy样式切片。 在以下示例中,一组HDF5数据被划分为尺寸为(5000,5000)的块:
import h5py f = h5py.File('myhdf5file.hdf5') dset = f['/data/path'] import dask.array as da x = da.from_array(dset, chunks=(5000, 5000))
Dask数组示例Dask中的并行处理
本节的另一个同样准确的标题是“顺序循环的死亡”。 我时不时地遇到一个共同的模式:遍历元素列表,然后对每个元素执行Python方法,但是要使用不同的输入参数。 常见的数据处理方案包括为每个客户计算功能汇总或为每个学生从日志中汇总事件。 Dask Delayed对象可让您并行处理许多元素,而不是将函数应用于顺序循环中的每个自变量。 使用Dask Delayed时,所有函数调用都排队,放入执行图,然后计划对其进行处理。
我总是很懒惰编写自己的线程引擎或使用asyncio,所以我什至不会向您展示类似的示例进行比较。 使用Dask,您既不能更改语法也不可以更改编程风格! 您只需要注释或包装该方法,该方法将与
@dask.delayed并行执行,并在执行循环代码后调用计算方法。
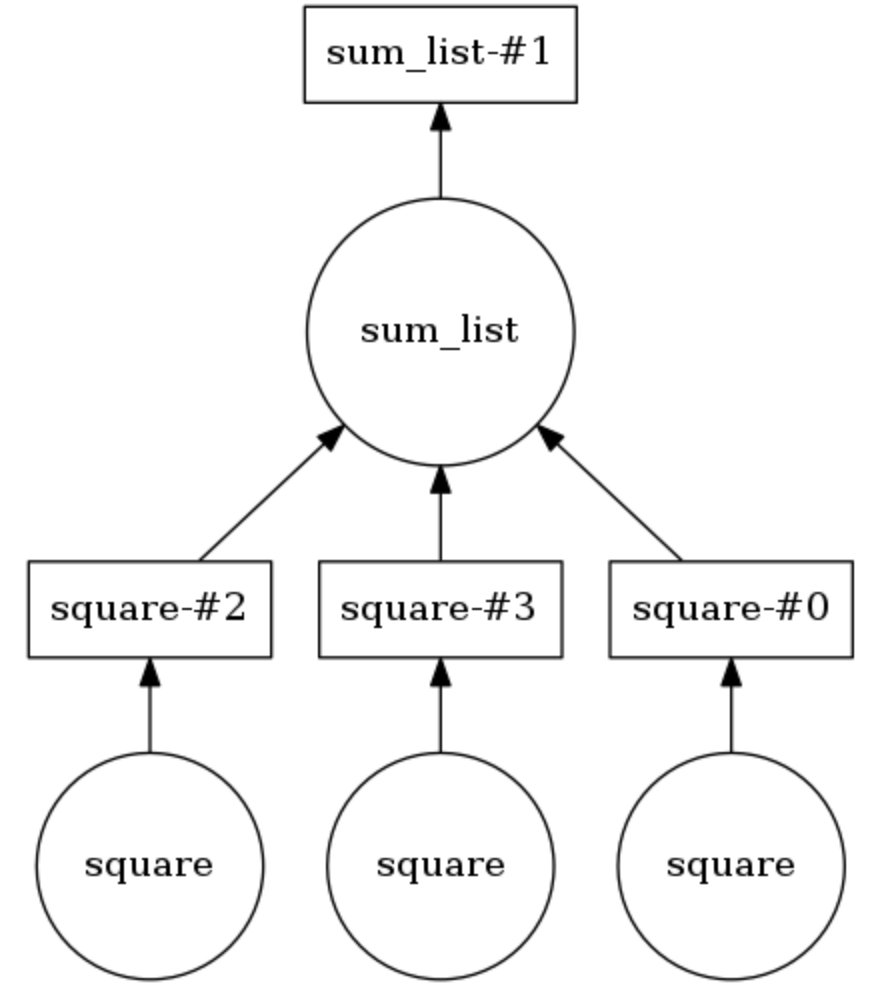
达斯克计算图示例
在下面的示例中,这两种方法都用
@dask.delayed注释。 三个数字存储在列表中,它们需要平方,然后求和。 Dask建立了一个计算图,该图提供了平方方法的并行执行,然后将此操作的结果传递给
sum_list方法。 可以通过
calling .visualize()来显示计算图。
Calling .compute()执行计算图。 从
结论可以明显看出,列表项不是按顺序处理的,而是并行处理的。
可以设置线程数(例如,
dask.set_options( pool=ThreadPool(10) ),也可以轻松地将它们交换以使用笔记本电脑或PC上的进程(例如
dask.config.set( scheduler='processes' ) 。
因此,我展示了使用Dask从数据科学领域向项目添加任务的并行处理是多么微不足道。 在撰写本文之前不久,我使用Dask将有关用户点击流(访问历史记录)的数据分为40分钟的会话,然后汇总每个用户的属性以进行进一步的聚类。 告诉我们你如何使用Dask!