我厌倦了过去。 有许多指南可以重现历史文物的外观,但是我们经常忘记这是一种创造性行为。 也许我们对屏幕过于关注,对外观过于重视。 相反,让我们尝试
听听过去的事情。
关于考古声学和声音景观的丰富文献有助于重现
它所在的地方的声音(例如,参见
圣保罗的虚拟大教堂或
杰夫·维奇关于古代奥斯蒂亚的作品 )。 但我有兴趣对数据本身“发出声音”。 我想定义以声音形式表示数据的语法,以便这些算法可以在历史科学中使用。 德鲁克说过一个
著名的短语 ,即“数据”并不是真正给出的,而是被捕获,转化的东西,即“ capta”。 讲数据时,我从字面上
重现了现在
的过去。 因此,此数据的假设和转换成为重要问题。 产生的声音是一种“变形的演奏”,使您以新的方式聆听现代的历史层次。
我想听听过去的含义,但是我知道这是不可能的。 但是,当我听到乐器时,就可以想象音乐家。 通过回声和共振,我可以区分物理空间。 我感觉到低音,我可以有节奏地运动。 音乐覆盖了我的身体,充满了我的想象力。 与以前听到的声音,音乐和音调的关联创造了深厚的时间体验,这是我与过去之间体现的关系系统。 视觉? 我们过去的视觉表现很久了,以至于这些语法几乎失去了艺术表现力和表现力。
在本课程中,您将学习如何从历史数据中产生一些噪音。 这种噪音
的重要性 ……完全取决于您。 部分原因是使您的数据再次变得陌生。 通过翻译,重新编码,
还原它们,我们开始看到在视觉检查期间仍不可见的数据元素。 这种变形与马克·桑普(Mark Sample)关于
社会变形或贝瑟尼·努维斯基(Bethany Nouwiski)关于
“材料抵抗”的论点是一致的。 计分将我们从数据带到“字幕”,从社会科学到艺术,
从小故障到美学 。 让我们看看它是什么样子。
目录内容
目的和目的
在本教程中,我将讨论从您的数据生成声音或音乐的三种方法。
首先,我们将使用由乔纳森·米德尔顿(Jonathan Middleton)开发的免费开放音乐算法系统。 在其中,我们将了解关键问题和术语。 然后,我们将使用一个小的Python库将数据“翻译”到88键键盘上,并为工作带来一些创造力。 最后,将数据上传到Sonic Pi实时声音和音乐处理程序,为此已发布了许多教程和参考资源。
您将看到使用声音的方式如何将我们从简单的可视化转变为真正有效的环境。
工具
数据样本
配音简介
声处理是一种将数据的某些方面转换为音频信号的方法。 通常,如果满足某些条件的方法可以称为“评分”。 这些包括可再现性(其他研究人员可以以相同的方式处理相同的数据并获得相同的结果),以及所谓的“可理解性”或“可理解性”,即原始数据的重要元素被系统地反映在结果声音中(请参见
Hermann,2008年 )。
Mark Last和Anna Usyskina(2015)的工作描述了一系列实验,以确定在对数据评分时可以执行哪些分析任务。 他们的
实验结果表明,即使是未经培训的学生(未经正规音乐培训)也可以区分听觉数据并得出有用的结论。 他们发现,听众能够听见声音,执行数据挖掘的一般任务,例如分类和聚类(在他们的实验中,他们以西方音乐规模播放基本的科学数据)。
Last和Usyskina专注于时间序列。 根据他们的发现,时间序列数据特别适合评分,因为这里有自然的相似之处。 音乐是一致的,具有持续时间,并且随着时间而发展。 还包含时间序列数据(
Last,Usyskina 2015:p.424 )。 仍然需要将数据与相应的音频输出进行比较。 在许多应用中,参数映射方法用于组合各种听觉测量的数据方面,例如高度,变异形式和间隔(发作)。 这种方法的问题在于,如果源数据点之间没有临时连接(或非线性连接),则结果声音可能被“混淆”(
2015:422 )。
填补空白
聆听声音,一个人用他的期望填补了沉默的时刻。 考虑一个视频,其中mp3转换为MIDI,然后又转换回mp3; 音乐被“拉平”,因此所有音频信息都可以用一种乐器进行再现(效果类似于将网页另存为.txt,在Word中将其打开,然后再次以.html格式保存)。 所有声音(包括人声)都将转换为相应的音符值,然后返回mp3。
这是噪音,但您可以明白这一点:
这是怎么回事 如果您知道这首歌,那么您可能理解了真正的“单词”。 但是这首歌无话可说! 如果您以前从未听过,那么听起来像是毫无意义的刺耳的声音(有关
Andy Bayo网站)。 这种效应有时称为听觉幻觉。 该示例说明了在任何数据表示形式中,我们如何能听到/看到严格来讲不是的声音。 我们用自己的期望填补了空白。
这对故事意味着什么? 如果我们说出自己的数据并开始听到声音或奇怪的爆发声,那么我们对音乐的文化期望(在某些情况下听到的类似音乐片段的记忆)将使我们的解释变色。 我要说的是,所有关于过去的想法都是如此,但是评分与标准方法大不相同,因此这种自我意识有助于识别或表达过去(有关数据)中的某些关键模式。
我们将考虑三种用于对数据评分的工具,并注意工具的选择如何影响结果,以及如何通过重新思考另一工具中的数据来解决此问题。 最终,评分并不比可视化更客观,因此研究人员应该准备证明自己的选择合理,并使该选择透明且可重复。 (因此,没有人会认为评分和算法生成的音乐是新事物,我将感兴趣的读者引向
Hedges,1978 )。
每个部分均包含概念性介绍,然后是使用考古或历史数据的演练。
音乐算法
有多种为数据发声的工具。 例如,流行的
R统计环境(例如
playitbyR和
AudiolyzR)的软件包 。 但是R的当前版本(最近的更新是在几年前)不支持第一个,并且为了使第二个正常工作,需要认真配置其他软件。
相比之下,
Musicalalgorithms网站非常易于使用;已经运行了十多年。 尽管源代码尚未发布,但它是乔纳森·米德尔顿(Jonathan Middleton)从事的一项关于计算音乐的长期研究项目。 它当前处于第三主要版本中(Internet上提供以前的版本)。 让我们从Musicalalgorithms开始,因为它允许我们快速下载和配置数据以将演示文稿发布为MIDI文件。 开始之前,请确保选择
第三个版本 。
 截至2016年2月2日的Musicalgorithms网站
截至2016年2月2日的Musicalgorithms网站音乐算法执行一系列数据转换。 在下面的示例中(该站点默认情况下),尽管看起来像几行,但只有一行数据。 此模式由用逗号分隔的字段组成,这些字段在内部由空格分隔。
声音数量,文本区域名称,文本区域数据
1,morphBox,
,areaPitch1,2 7 1 8 2 8 1 8 2 8 4 5 9 0 4 5 2 3 5 3 6 0 2 8
,dAreaMap1,2 7 1 8 2 8 1 8 2 8 4 5 9 0 4 5 2 3 5 3 6 0 2 8
,mapArea1.20 69 11 78 20 78 11 78 20 78 40 49 88 1 40 49 20 30 49 30 59 1 20 78
,dMapArea1.1 5 1 5 1 5 1 5 1 5 3 3 6 0 3 3 1 2 3 2 4 0 1 5
,so_text_area1.20 69 11 78 20 78 11 78 20 78 40 49 88 1 40 49 20 30 49 30 59 1 20 78
这些数字代表源数据及其转换。 共享文件使另一位研究人员可以重复工作或继续使用其他工具进行处理。 如果从头开始,则仅需要以下源数据(数据点列表):
声音数量,文本区域名称,文本区域数据
1,morphBox,
,区域间距1.24 72 12 84 21 81 14 81 24 81 44 51 94 01 44 51 24 31 5 43 61 04 21 81
对于我们来说,关键是带有输入数据的字段“ areaPitch1”,该字段用空格分隔。 在工作期间,其他字段将使用各种“音乐算法”设置进行填充。 在上述数据中(例如24 72 12 84等),这些值是对罗马沿途英国城市铭文数量的初步计算(以后我们将使用其他数据进行练习)。
 将数据加载到顶部菜单栏中后,您可以选择各种操作。 在屏幕快照中,将鼠标悬停在信息上会显示有关选择除法运算将数据缩放到选定音符范围时发生的情况的说明
将数据加载到顶部菜单栏中后,您可以选择各种操作。 在屏幕快照中,将鼠标悬停在信息上会显示有关选择除法运算将数据缩放到选定音符范围时发生的情况的说明现在,在界面中查看各种选项卡(持续时间,高度转换,持续时间转换,比例选项)时,可以使用各种转换。 在音高映射中,有许多数学选项可用于将数据转换为完整的88键钢琴键盘(在线性转换中,
平均值转换为平均值C,即40)。 您还可以选择比例类型:次要或主要,依此类推。 此时,选择各种转换后,必须保存文本文件。 在文件→播放选项卡上,您可以下载midi文件。 您的默认音频程序应该能够播放midi(默认情况下通常会使用钢琴音符)。 在调音台程序(如GarageBand(Mac)或
LMMS (Windows,Mac,Linux))中分配了更复杂的Midi工具。 但是,GarageBand和LMMS的使用不在本指南的范围之内:
此处提供LMMS视频教程,并且GarageBand教程在Internet上完整。 例如,Lynda.com上的
出色指南 。
碰巧的是,对于同一点,有几列数据。 假设在英国的例子中,我们也想表达对相同城市的陶瓷类型的计算。 然后,您可以重新加载下一行数据,执行转换和比较-并创建另一个MIDI文件。 由于GarageBand和LMMS允许您叠加声音,因此可以创建复杂的音乐序列。
GarageBand的屏幕截图,其中Midi文件是John Adams日记中的有声主题。 在GarageBand(和LMMS)界面中,每个midi文件都用鼠标拖动到适当的位置。 在GarageBand菜单中选择了每个midi文件(即音轨)的工具包。 曲目标签已更改,以反映每个主题中的关键字。 右侧的绿色区域是每个音轨上音符的可视化。 您可以在操作中观看此界面并在此处听音乐使用什么转换? 如果您有两列数据,那么这是两票。 也许,在我们的假设数据中,大声再现第一个声音作为主要声音是有道理的:最后,铭文以某种方式对我们说话(罗马铭文字面指的是路人:``哦,您路过...'')。 陶瓷也许是一种较为温和的文物,可以与音阶的低端进行比较,或者增加音符的持续时间,反映出其在该地区不同阶级代表中的普遍性。
目前还没有一种将数据转换为声音的“正确”方法 ,至少现在还没有。 但是即使在这个简单的示例中,我们也会看到含义和解释的阴影如何出现在数据及其感知中。
但是时间呢? 历史数据通常具有一定的日期约束力。 因此,必须考虑两个数据点之间的时间跨度。 如果数据点在时间空间上相互关联,这就是我们的下一个工具有用的地方。 我们开始从得分(数据点)转移到音乐(点之间的关系)。
练习
数据集的第一列
中是罗马硬币的数量和同一城市的其他材料的数量。 信息取自大英博物馆的便携式古物计划。 处理这些数据可能会揭示沃特林街(穿过罗马英国的主要路线)经济状况的某些方面。 数据点的地理位置从西北到东南。 因此,随着声音的再现,我们听到了空间中的运动。 每个音符代表前进途中的每个停靠点。
- 在电子表格中打开thesonification-roman-data.csv 。 将第一列复制到文本编辑器中。 删除行尾,使所有数据都在同一行上。
- 添加以下信息:
声音数量,文本区域名称,文本区域数据
1,morphBox,
,areaPitch1,
...因此您的数据紧跟在最后一个逗号之后(例如pltcm )。 使用有意义的名称保存文件,例如, coinsounds1.csv 。
- 转到Musicalgorithms网站(第三版),然后单击“加载”按钮。 在弹出窗口中,单击蓝色的“加载”按钮,然后选择上一步中保存的文件。 该站点将上载您的资料,如果成功,将显示一个绿色的选中标记。 如果不是这种情况,请确保这些值之间用空格隔开,并立即跟随代码块中的最后一个逗号。 您可以尝试从本指南下载演示文件 。

单击“加载”后,此对话框出现在主屏幕上。 然后点击“加载CSV文件”。 选择您的文件,它将显示在字段中。 然后点击底部的“加载”按钮。
- 单击“音高输入”,您将看到数据值。 请勿在此页面上选择其他选项(因此,将应用默认值)。
- 单击“持续时间输入”。 不要在这里选择任何选项 。 这些选项将随着每个音符持续时间的变化对数据进行各种转换。 除非您担心这些选项,否则请继续。
- 点击“音高映射”。 这是最重要的选择,因为它将原始数据转换(即缩放)为键盘键。 将
mapping保留为“除法”值(其他参数为模数转换或对数)。 Range参数(从1到88)使用88个键的整个键盘长度。 因此,最低值对应于钢琴上的最深音符,最高值对应于最高的音符。 相反,您可以将音乐限制在中间C的范围内,然后输入25到60的范围。输出将更改为: 31,34,34,34,25,28,30,60,28,25,26,26,25,25,60,25,25,38,33,26,25,25,25 。 这些不是您的电话号码,而是键盘上的注释。

单击“范围”字段,然后输入25。下面的值将自动更改。 在“至”字段中,设置为60。如果转到另一个字段,则值将被更新。
- 点击“持续时间映射”。 与高度转换一样,此处程序采用指定的时间范围,并使用各种数学参数将此范围转换为音符。 如果将鼠标悬停在
i ,您将看到哪些数字对应于整个音符,四分之一,八分之一等等。 现在保留默认值。
- 点击“缩放选项”。 在这里,我们开始处理某种意义上与“情感”方面相对应的内容。 通常,大尺度被认为是“快乐的”,小尺度被认为是“悲伤的”; 有关此主题的详细讨论,请参见此处 。 现在,保留“ scale by:major”。 将“比例”保留为C。
因此,我们宣布了一列数据! 点击“保存”,然后点击“保存CSV”。
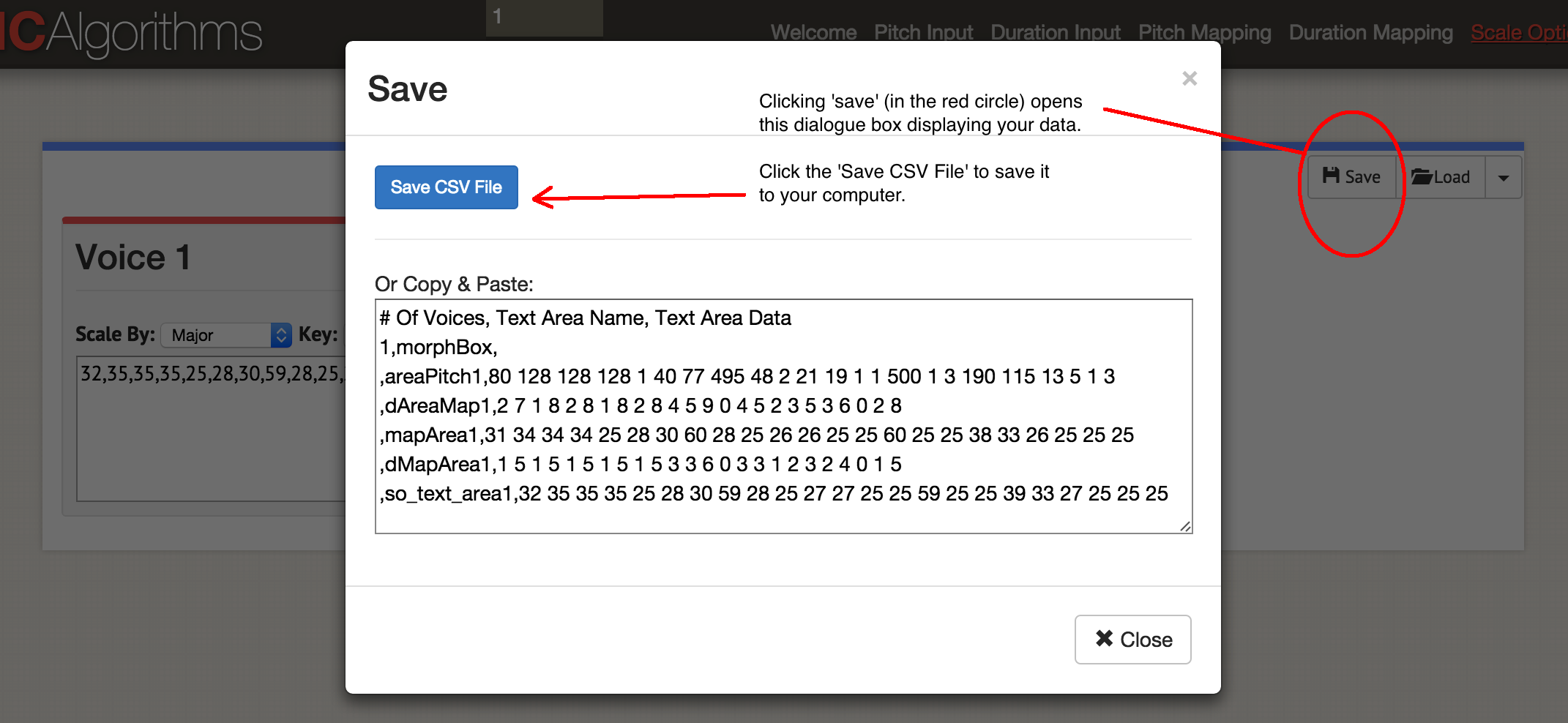 “保存”对话框
“保存”对话框您将获得类似此文件的内容:
声音数量,文本区域名称,文本区域数据
1,morphBox,
,区域间距1.80 128 128 128 1 40 77 495 48 2 21 19 1 1 1 500 1 3 190 115 13 5 1 3
,dAreaMap1,2 7 1 8 2 8 1 8 2 8 4 5 9 0 4 5 2 3 5 3 6 0 2
,mapArea1.31 34 34 34 25 28 30 60 28 25 26 26 25 25 60 25 25 38 33 26 25 25 25
,dMapArea1.1 5 1 5 1 5 1 5 1 5 3 3 6 0 3 3 1 2 3 2 4 0 1
,so_text_area1.32 35 35 35 25 28 30 59 28 25 27 27 25 25 59 25 25 39 33 27 25 25 25
原始数据保留在“ areaPitch1”字段中,然后创建的映射会更进一步。 该站点允许您一次在一个MIDI文件中最多生成四个声音。 根据以后要使用的乐器,您可以选择一次生成一个MIDI文件。 让我们开始音乐:单击“播放”。 在这里,您可以选择节奏和乐器。 您可以在浏览器中收听数据,也可以使用蓝色的“保存MIDI文件”按钮另存为MIDI文件。
让我们回到开头,将两个数据列都加载到此模板中:
声音数量,文本区域名称,文本区域数据
2,morphBox
,areaPitch1,
,areaPitch2,
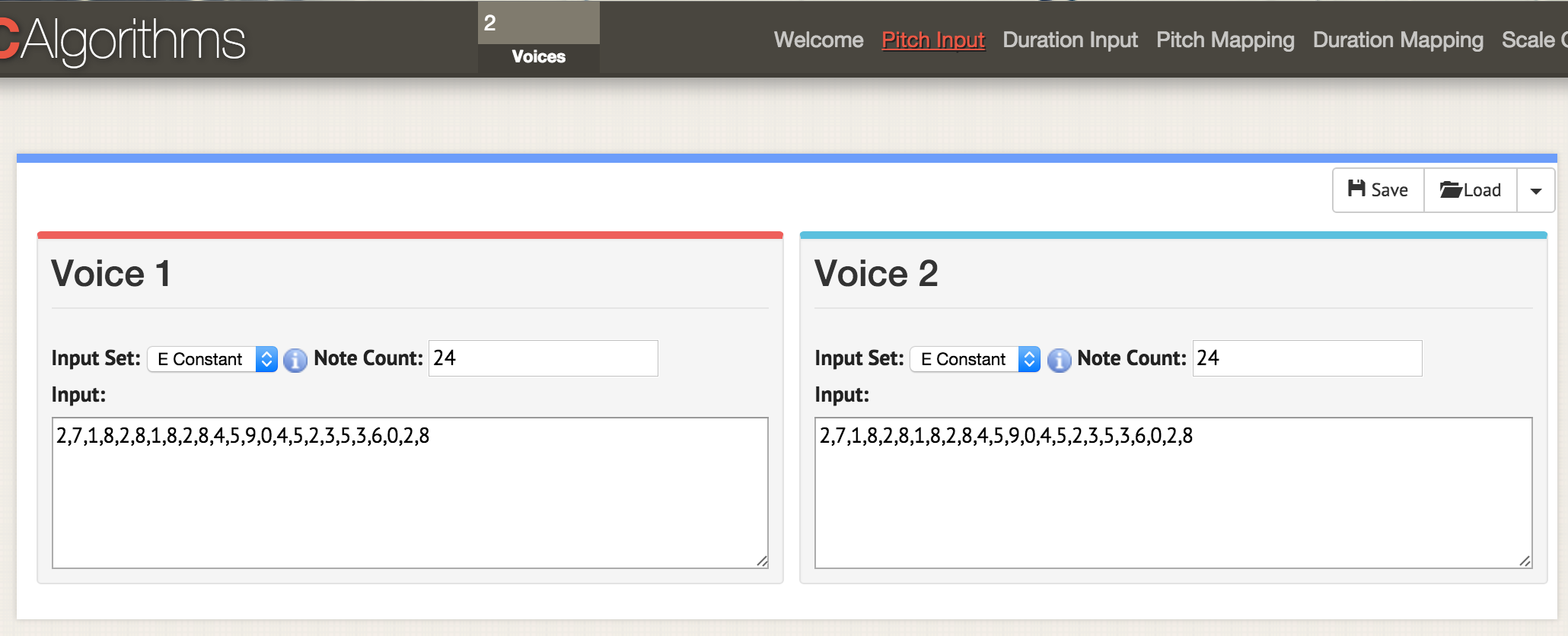 这是我们在页面上带有参数“音高输入”的页面。 在窗口顶部,指定两个投票,现在在任何具有两个投票两个窗口的参数的页面上。 和以前一样,我们以CSV格式加载数据,但是必须对文件进行格式化,以便在其中指示值“ areaPitch1”和“ areaPitch2”。 第一个语音的数据将显示在左侧,第二个-数据将显示在右侧
这是我们在页面上带有参数“音高输入”的页面。 在窗口顶部,指定两个投票,现在在任何具有两个投票两个窗口的参数的页面上。 和以前一样,我们以CSV格式加载数据,但是必须对文件进行格式化,以便在其中指示值“ areaPitch1”和“ areaPitch2”。 第一个语音的数据将显示在左侧,第二个-数据将显示在右侧如果我们有几票,那该怎么办呢? 请注意,采用这种方法时,我们的发声方式并未考虑到现实世界中两点之间的距离。 如果考虑的话,将大大影响结果。 当然,距离不必与地理联系在一起-它可以与时间联系在一起。 以下工具将在评分时明确指出该因素。
简要介绍Python
本手册的这一部分将需要Python。 如果您还没有尝试过这种语言,那么您将不得不花费一些时间来
了解命令行 。 另请参见
模块快速安装指南 。
Mac上已经安装了Python。 您可以检查:按COMMAND键和一个空格,在搜索框中输入
terminal ,然后单击终端应用程序。
$ type python —version将显示您已安装的Python版本。 在本文中,我们正在使用Python 2.7,该代码尚未在Python 3中进行测试。
Windows用户需要自己安装Python:从此
页面开始,尽管比说的要复杂一些。 首先,您需要下载
.msi文件(Python 2.7)。 运行安装程序,它将安装在新目录中,例如
C:\Python27\ 。 然后,您需要在路径中注册该目录,即告诉Windows运行Python程序时在哪里寻找Python。 有几种方法可以做到这一点。 查找
Powershell的最简单方法可能
Powershell在计算机上(在Windows搜索栏中输入“ powershell”)。 打开Powershell并在命令提示符下粘贴以下内容:
[Environment] :: SetEnvironmentVariable(“ Path”,“ $ env:Path; C:\ Python27 \; C:\ Python27 \ Scripts \”,“ User”)
如果按Enter键没有任何反应,则该命令已起作用。 要进行检查,请打开命令提示符(执行此操作的
十种方法 ),然后输入
python --version 。 您应该看到一个指示
Python 2.7.10或类似版本的响应。
最后一个难题是一个名为
Pip的程序。 Mac用户可以在
sudo easy_install pip终端中使用命令安装它。 Windows用户将更加复杂。 首先,右键单击并通过
此链接保存文件(如果您仅单击链接,则将在浏览器中打开
get-pip.py代码)。 将其放在手边。 在保存
get-pip.py的目录中打开命令提示符。 然后在
python get-pip.py命令提示符下键入
python get-pip.py 。
当您拥有要运行的Python代码时,请将其粘贴到文本编辑器中,并以扩展名
.py保存文件。 这是一个文本文件,但是文件扩展名告诉计算机使用Python对其进行解释。 它从命令行启动,首先指示解释器的名称,然后指示文件名:
python my-cool-script.py 。
MIDI时间
MIDITime是由
Reveal News (以前称为新闻研究中心)开发的Python软件包。
Github上的存储库。 MIDITime是专门设计来处理时间序列的(即随时间收集的一系列观察结果)。
虽然音乐算法具有或多或少直观的界面,但此处的优势是开源。 更重要的是,先前的工具无法将考虑历史时间的数据考虑在内。 MIDITime允许您在此因素上聚集信息。
假设我们有一本应用
主题模型的历史日记。 结果输出可能包含行形式的日记条目,并且在各列中每个主题的贡献百分比。 在这种情况下,
倾听价值观将有助于从日记中理解这样的思维模式,即不可能以图表的形式传达。 立即听到可识别的爆发或重复图表上不可见的音乐模式。
设定MIDITime
使用一个
pip命令进行安装:
$ pip install miditime
对于罂粟;
$ sudo pip install miditime
在Linux下;
> python pip install miditime
在Windows下(如果该说明不起作用,则可以尝试使用
该实用程序安装Pip)。
练习
考虑一个示例脚本。 打开文本编辑器,复制并粘贴以下代码:
将脚本另存为
music1.py 。 在终端或命令行中,运行它:
$ python music1.py
将在
myfile.mid创建一个新的
myfile.mid文件。 您可以使用Quicktime或Windows Media Player打开它进行收听(并在GarageBand或
LMMS中添加工具)。
Music1.py导入miditime(请记住在运行脚本之前安装它:
pip install miditime )。 然后设定速度。 所有音符都单独列出,其中第一个数字是播放的开始时间,高度(即音符本身!),音符的演奏力度或节奏(攻击)及其持续时间。 然后,将笔记记录在轨道上,并将轨道本身记录在
myfile.mid文件中。
播放脚本,添加更多注释。 以下是歌曲“ Baa Baa Black Sheep”的音符:
D,D,A,A,B,B,B,B,A
a,Ba,黑色,绵羊,有,羊毛吗?
您能为计算机写出演奏旋律的说明(这里有帮助的
图表 )吗?
顺便问一下 。 有一种用于描述音乐的特殊文本文件格式,称为
ABC符号 。 这超出了本文的讨论范围,但是您可以编写一个脚本来进行评分,例如在电子表格中,以ABC表示法比较注释的值(如果您曾经在Excel中使用过IF-THEN构造,则知道如何执行此操作),然后通过这样的站点
,将 ABC表示法转换为.mid文件。
上载您自己的数据
该文件包含
Macroscope网站的John Adams日记主题模型的样本。 这里只剩下最强的信号,将列中的值四舍五入到小数点后两位。 要将这些数据插入Python脚本中,您需要以特殊方式对其进行格式化。 最困难的是日期字段。
在本教程中,让变量名称和其余名称与示例脚本保持不变。 设计了一个示例来处理地震数据。 因此,这里的“幅度”可以表示为我们的“主题贡献”。 my_data = [
{'event_date':<datetime对象>,'magnitude':3.4},
{'event_date':<datetime对象>,'magnitude':3.2},
{'event_date':<datetime对象>,'magnitude':3.6},
{'event_date':<datetime对象>,'magnitude':3.0},
{'event_date':<datetime对象>,'magnitude':5.6},
{'event_date':<datetime对象>,'magnitude':4.0}
] 正则表达式可用于格式化数据,甚至更容易-电子表格。 将具有主题贡献值的元素复制到新的工作表中,并在左右各保留几列。 在下面的示例中,我将其放在D列中,然后填充其余部分:
然后复制并粘贴不可变元素,填充整个列。 带日期的项目必须采用格式(年,月,日)。 填写表格后,您可以将其复制并粘贴到文本编辑器中,使其成为
my_data数组的一部分,例如:
my_data = [
{'event_date':日期时间(1753,6,8),'magnitude':0.0024499630},
{'event_date':日期时间(1753,6,9),'magnitude':0.0035766320},
{'event_date':日期时间(1753,6,10),'magnitude':0.0022171550},
{'event_date':日期时间(1753,6,11),'magnitude':0.0033220150},
{'event_date':日期时间(1753,6,12),'magnitude':0.0046445900},
{'event_date':日期时间(1753,6,13),'magnitude':0.0035766320},
{'event_date':日期时间(1753,6,14),'magnitude':0.0042241550}
] 请注意,最后一行的末尾没有逗号。
如果您使用Miditime本身页面上的示例,则最终脚本将类似于以下内容(以下代码段被注释打断,但应将它们作为一个文件插入文本编辑器中):
from miditime.MIDITime import MIDITime from datetime import datetime import random mymidi = MIDITime(108, 'johnadams1.mid', 3, 4, 1)
MIDITime之后的值设置为
MIDITime(108, 'johnadams1.mid', 3, 4, 1) ,在这里:
- 每分钟的拍数(108),
- 输出文件(“ johnadams1.mid”),
- 代表历史的一年的音乐秒数(每个日历年3秒,因此50年的日记条目被缩放为50×3秒的旋律,即两分半钟),
- 音乐的基本八度(平均C通常表示为C5,因此此处4对应于比参考低一个八度),
- 以及用于比较高度的八度音阶数。
现在,我们通过将数据加载到
my_data数组中来将数据传递给脚本:
my_data = [ {'event_date': datetime(1753,6,8), 'magnitude':0.0024499630}, {'event_date': datetime(1753,6,9), 'magnitude':0.0035766320},
...在这里,我们插入了所有数据,并且不要忘记在
event_date的最后一行的
event_date以及在数据的最后括号放在另一行之后
删除逗号 :
{'event_date': datetime(1753,6,14), 'magnitude':0.0042241550} ]
然后插入时间:
my_data_epoched = [{'days_since_epoch': mymidi.days_since_epoch(d['event_date']), 'magnitude': d['magnitude']} for d in my_data] my_data_timed = [{'beat': mymidi.beat(d['days_since_epoch']), 'magnitude': d['magnitude']} for d in my_data_epoched] start_time = my_data_timed[0]['beat']
该代码设置不同日记条目之间的时间安排; 如果日记条目在时间上彼此接近,则相应的注释也将更接近。 最后,我们确定数据与高度的比较。 初始值以百分比表示,范围为0.01(即1%)至0.99(99%),因此我们将
scale_pct设置为0到1。如果没有百分比,则使用最低和最高价值观。 因此,我们插入以下代码:
def mag_to_pitch_tuned(magnitude): scale_pct = mymidi.linear_scale_pct(0, 1, magnitude)
以及将数据保存到文件的最后一个片段:
使用新名称和
.py扩展名保存该文件。
对于源数据中的每一列,我们制作一个唯一的脚本,并且不要忘记
更改输出文件的名称 ! 然后,您可以将单个Midi文件上载到GarageBand或LMMS进行检测。 这是
约翰·亚当斯的完整
日记 。
声波
在GarageBand或其他音乐编辑器中处理独特的Midi,意味着从简单的配音过渡到音乐艺术。 本文的最后部分不是使用
Sonic Pi的完整指南,而是对一种环境的介绍,该环境允许以音乐形式进行数据的实时编码和回放(请参见
视频以获取具有实时
回放的编码示例)。 该程序中内置的教程将展示如何将计算机用作乐器(您将Ruby代码输入到内置编辑器中,然后解释器立即播放结果)。
为什么需要这个? 从本指南可以理解,在读取数据时,您将开始决定如何将数据转换为声音。 这些决策反映了有关哪些数据重要的隐式或显式决策。 如果您愿意,还有一个连续的“客观性”。 一方面,带语音的历史数据,另一方面,对过去的构想,与任何精心制作的公开演讲一样,令人兴奋且具有个性。 探测可以使您真正听到存储在文档中的数据:这是一种公共历史。 我们数据的音乐表现……想象一下!
在这里,我提出了一个用于导入数据的代码片段,它只是存储为csv的值的列表。 感谢乔治华盛顿大学图书馆员劳拉·弗鲁贝尔(Laura Vrubel),她在
gist.github.com上发布了她对测深库操作的实验。
此示例中有两个主题(从
“耶稣会关系”生成的主题模型)。 在第一行中,标题为“ topic1”和“ topic2”。
练习
遵循内置的Sonic Pi教程,直到您熟悉界面和功能(所有这些教程均
在此处编译;您还可以收听Sonic Pi的创建者Sam Aaron
的访谈 )。 然后将以下代码复制到新缓冲区(编辑器窗口)中(同样,应在一个脚本中收集单独的片段):
require 'csv' data = CSV.parse(File.read("/path/to/your/directory/data.csv"), {:headers => true, :header_converters => :symbol}) use_bpm 100
请记住,
path/to/your/directory/是您的数据在计算机上的实际位置。 确保该文件的名称为
data.csv ,或在代码中编辑此行。
现在将这些数据加载到音乐作品中:
前几行加载数据列; 然后,我们指示要使用的声音样本(钢琴),然后根据指定的标准指示播放第一个主题(topic1):对于音符的强度(攻击),选择一个小于0.5的随机值; 衰减-小于1的随机值; 对于振幅,小于0.25的随机值。
看到一行乘以一百(
*100 )吗? 它采用我们的数据值(十进制)并将其转换为整数。 在此片段中,数字直接等于音符。 如果最低音符是88,最高音符是1,则此方法有点问题:实际上,我们在此不显示任何音高! 在这种情况下,您可以使用Musicalgorithms显示高度,然后将这些值传递回Sonic Pi。 另外,由于此代码或多或少是标准Ruby,因此您可以使用标准化数据的常用方法,然后对值进行1-88的线性比较。 对于初学者来说,很高兴看看
Steve Lloyd使用Sonic Pi发出声音数据
的工作 。
最后要注意的是:“ rand”(随机)的值使您可以在动态方面为音乐添加一些“人性化”。 我们对“ topic2”执行相同的操作。
您还可以指定Sonic Pi支持的节奏(每分钟节拍),循环,采样和其他效果。代码的位置会影响播放:例如,如果放在上述数据块的前面,它将首先播放。例如,如果在行后use_bpm 100插入以下内容:
...您会得到一些音乐上的介绍。该程序等待2秒钟,播放示例“ ambi_choir”,然后再等待6秒钟,然后开始播放我们的数据。如果您想在整个旋律中添加一些不祥的鼓,请如下所示(在您自己的数据之前):
代码非常简单:循环样本“ bd_boom”具有一定速度的混响音效。循环之间的暂停为2秒。对于“实时编码”,这意味着您可以在重放这些更改的同时对代码进行更改。不喜欢您听到的声音吗?立即更改代码!探索Sonic Pi可以从这个工作坊开始。另请参阅劳拉·弗鲁贝尔(Laura Vrubel)关于参加研讨会的报告,该报告还讲述了她在这一领域的工作以及她的同事的工作。阳光下没有新事物
: , . 1978
« » 18 , .
Sonic Pi . , Markdown+Pandoc, —
Lilypond .
The Programming Historian !
结论
在发声时,我们发现我们的数据反映的并不是故事本身,而是其表现的解释。这部分是由于将数据转换为声音所需的新颖性和艺术性。但这极大地将声音解释与传统的可视化区别开来。也许所产生的声音永远不会达到“音乐”的水平。但是如果他们帮助改变了我们对过去的理解并影响了他人,那么付出的努力是值得的。正如特雷弗·欧文斯(Trevor Owens)所说,“听起来是对新事物的发现,而不是对已知事物的辩护 ”。条款
- MIDI : . , ( ). . MIDI- , .
- MP3 : , .
- : ( C . .)
- :
- : ( , , . .)
- :
- : ,