如果您曾经使用过C或C ++等低级语言,则可能听说过指针。 它们使您可以大大提高不同代码段的效率。 但是他们也会使新手,甚至是经验丰富的开发人员感到困惑,并导致内存管理错误。 Python中是否有指针,我可以以某种方式模拟它们吗?
指针广泛用于C和C ++。 实际上,这些变量包含其他变量所在的内存地址。 要重新
梳理指针,请阅读此
评论 。
通过本文,您将更好地理解Python中的对象模型,并找出为什么在这种语言中实际上并不存在指针。 万一您需要模拟指针的行为,您将学习如何在没有伴随内存管理噩梦的情况下模拟指针。
通过本文,您可以:
- 了解为什么Python没有指针。
- 了解Python中C变量和名称之间的区别。
- 学习在Python中模拟指针。
- 使用
ctypes尝试使用真实的指针。
注意 :此处,术语“ Python”适用于C语言中的Python实现,即CPython。 语言设备的所有讨论都对CPython 3.7有效,但可能不与后续迭代相对应。
为什么在Python中没有指针?
我不知道 指针可以原生存在于Python中吗? 可能但很显然,指针与
Python的
Zen的概念相矛盾,因为它们会引发隐式更改而不是显式更改。 指针通常非常复杂,特别是对于初学者。 而且,它们会促使您做出不成功的决定或执行某些真正危险的事情,例如从不应读取的存储区读取。
Python尝试从用户那里提取实现细节,例如内存地址。 通常用这种语言,重点是可用性,而不是速度。 因此,Python中的指针没有多大意义。 但请放心,默认语言为您提供了使用指针的一些好处。
为了理解Python中的指针,让我们简要介绍一下该语言实现的功能。 特别是,您需要了解:
- 什么是可变的和不变的对象。
- 如何在Python中排列变量/名称。
保留您的内存地址,开始吧!
Python中的对象
Python中的所有内容都是一个对象。 例如,打开REPL并查看
isinstance() :
>>> isinstance(1, object) True >>> isinstance(list(), object) True >>> isinstance(True, object) True >>> def foo(): ... pass ... >>> isinstance(foo, object) True
此代码说明Python中的所有内容实际上都是一个对象。 每个对象至少包含三种类型的数据:
参考计数器用于管理内存。 有关此管理的详细信息,请
参见Python的“内存管理” 。 在CPython级别使用该类型在运行时提供类型安全。 值是与对象关联的实际值。
但并非所有对象都是相同的。 有一个重要的区别:对象是可变的并且是不可变的。 了解对象类型之间的区别将帮助您更好地理解洋葱的第一层,即“ Python中的指针”。
可变和不可变的对象
Python中有两种类型的对象:
- 不可变的对象(无法更改);
- 可修改的对象(可能会更改)。
认识到这种差异是在Python中遍历指针世界的第一把钥匙。 这是一些流行类型的不变性特征:
如您所见,许多常用的基本类型都是不可变的。 您可以通过编写一些Python代码来验证这一点。 您将需要标准库中的两个工具:
id()返回对象的内存地址;
- 当且仅当两个对象具有相同的内存地址时,
is返回True 。
您可以在REPL环境中运行以下代码:
>>> x = 5 >>> id(x) 94529957049376
在这里,我们将变量
x设置为
5 。 如果尝试使用加法更改值,则将获得一个新对象:
>>> x += 1 >>> x 6 >>> id(x) 94529957049408
尽管此代码似乎只是更改
x的值,但实际上您正在获得一个
新对象作为答案。
str类型也是不可变的:
>>> s = "real_python" >>> id(s) 140637819584048 >>> s += "_rocks" >>> s 'real_python_rocks' >>> id(s) 140637819609424
在这种情况下,运算
+=之后的
s将获得
不同的内存地址。
奖励 :
+=运算符可转换为各种方法调用。
对于某些对象,例如列表,
+=转换为
__iadd__() (本地附加)。 它将更改自身并返回相同的ID。 但是,
str和
int没有这些方法,因此,将调用
__iadd__()而不是
__iadd__() 。
有关
更多详细信息,请参见Python
数据模型文档 。当我们尝试直接更改
s的字符串值时
s出现错误:
>>> s[0] = "R"
追溯(最近的呼叫显示在最后):
File "<stdin>", line 1, in <mdule> TypeError: 'str' object does not support item assignment
上面的代码崩溃,Python报告
str不支持此更改,该更改对应于
str类型的不可变性的定义。
与可变对象进行比较,例如,与列表进行比较:
>>> my_list = [1, 2, 3] >>> id(my_list) 140637819575368 >>> my_list.append(4) >>> my_list [1, 2, 3, 4] >>> id(my_list) 140637819575368
此代码演示了两种对象之间的主要区别。 最初,
my_list具有一个ID。 即使将
4加到列表中,
my_list仍具有
相同的 ID。 原因是类型
list是可变的。
这是使用赋值的列表可变性的另一个演示:
>>> my_list[0] = 0 >>> my_list [0, 2, 3, 4] >>> id(my_list) 140637819575368
在此代码中,我们更改了
my_list并将其设置为
0作为第一个元素。 但是,此操作后,列表保留了相同的ID。 我们
学习Python的下一步将是探索其生态系统。
我们处理变量
Python中的变量与C和C ++中的变量从根本上不同。 本质上,它们只是在Python中不存在。
除了变量,还有名称 。
它听起来可能很古怪,而且在大多数情况下是。 通常,您可以将Python中的名称作为变量,但是您需要了解它们之间的区别。 当您学习诸如指针之类的难题时,这一点尤其重要。
为了使您更容易理解,让我们看看变量如何在C中工作,它们代表什么,然后与Python中的名称工作进行比较。
C中的变量
使用定义变量
x的代码:
int x = 2337;
这条短线的执行经历了几个不同的阶段:
- 为一个数字分配足够的内存。
- 将
2337分配给该存储位置。
x表示此值的映射。
简化的内存可能看起来像这样:

此处,变量
x的伪地址为
0x7f1 ,其值为
2337 。 如果以后要更改
x的值,可以执行以下操作:
x = 2338;
此代码将变量
x新值
2338 ,从而覆盖
先前的值。 这意味着变量
x 可变的 。 为新值更新了内存方案:

请注意,
x的位置没有改变,只是值本身。 这很重要。 这告诉我们
x是
内存中的位置 ,而不仅仅是一个名称。
您也可以将此问题视为所有权概念的一部分。 一方面,
x在内存中占有一席之地。 首先,
x是一个只能包含一个整数的空框,其中可以存储整数值。
当给
x赋值时,将值放在一个属于
x的框中。 如果要引入新变量
y ,可以添加以下行:
int y = x;
这段代码创建了一个名为
y的新框,并将
x的值复制到其中。 现在,存储电路如下所示:

注意新位置
y -
0x7f5 。 尽管将值
x复制到
x ,变量
y在内存中拥有一个新地址。 因此,您可以覆盖
y的值而不会影响
x :
y = 2339;
现在,存储电路如下所示:

我重复一遍:您更改了
y的值,但未更改位置。 此外,您没有影响原始变量
x 。
使用Python中的名称,情况完全不同。
Python中的名称
Python中没有变量,而是名称。 您可以自行决定使用“变量”一词,但是了解变量和名称之间的区别很重要。
让我们从上面的C示例中获取等效的代码,然后用Python编写:
>>> x = 2337
与C语言一样,代码在执行过程中将经历几个单独的步骤:
- PyObject已创建。
- 为PyObject编号分配了类型代码。
2337分配一个PyObject值。
- 名称
x已创建。 x指向新的PyObject。- PyObject的引用计数增加1。
注意 :
PyObject与Python中的对象不同,该实体特定于CPython,并表示所有Python对象的基本结构。
PyObject被定义为C结构,因此如果您想知道为什么不能直接调用类型代码或引用计数器,那么原因是您无法直接访问该结构。
调用sys.getrefcount()之类的方法可以帮助获取某种内部信息。
如果我们谈论内存,那么它可能看起来像这样:

在此,存储电路与上述C中的电路非常不同。 不是让
x拥有一个存储值
2337的内存块,而是一个新创建的Python对象拥有
2337所在的内存。 Python名称
x不直接拥有内存中的
任何地址,就像C变量拥有静态单元格一样。
如果要给
x新值,请尝试以下代码:
>>> x = 2338
系统的行为将与C语言中的行为有所不同,但与Python中的原始绑定没有太大的不同。
在此代码中:
- 创建一个新的PyObject。
- 为PyObject编号分配了类型代码。
2为PyObject分配了一个值。
x指向新的PyObject。
- 新PyObject的引用计数增加1。
- 旧PyObject的引用计数减少1。
现在,存储电路如下所示:
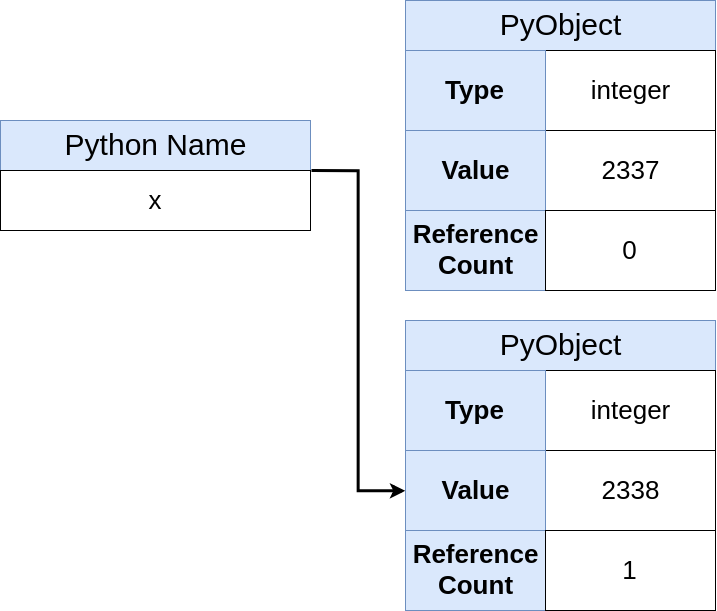
该图说明了
x指向对对象的引用,并且不像以前那样拥有存储区。 您还会看到命令
x = 2338不是分配,而是名称
x与链接的绑定。
另外,先前的对象(包含值
2337 )现在在内存中的引用计数为0,并将
由垃圾收集器删除。
您可以输入一个新名称
y ,如C示例中所示:
>>> y = x
新名称将出现在内存中,但不一定是新对象:
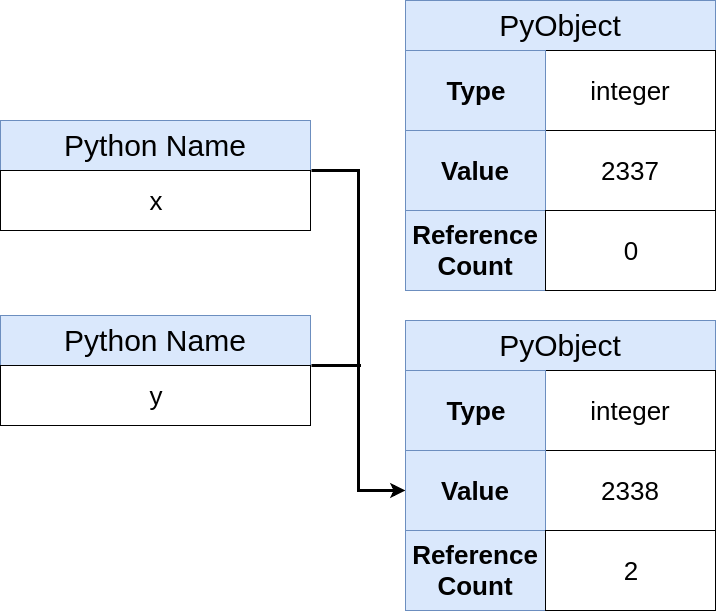
现在您看到
尚未创建新的Python对象,仅创建了指向同一对象的新名称。 此外,对象引用计数器增加了1。您可以检查对象标识的等效性以确认其标识:
>>> y is x True
此代码表明
x和
y是一个对象。 但是请不要误会:
y仍然是不变的。 例如,您可以使用
y执行加法运算:
>>> y += 1 >>> y is x False
调用添加后,您将返回一个新的Python对象。 现在内存看起来像这样:
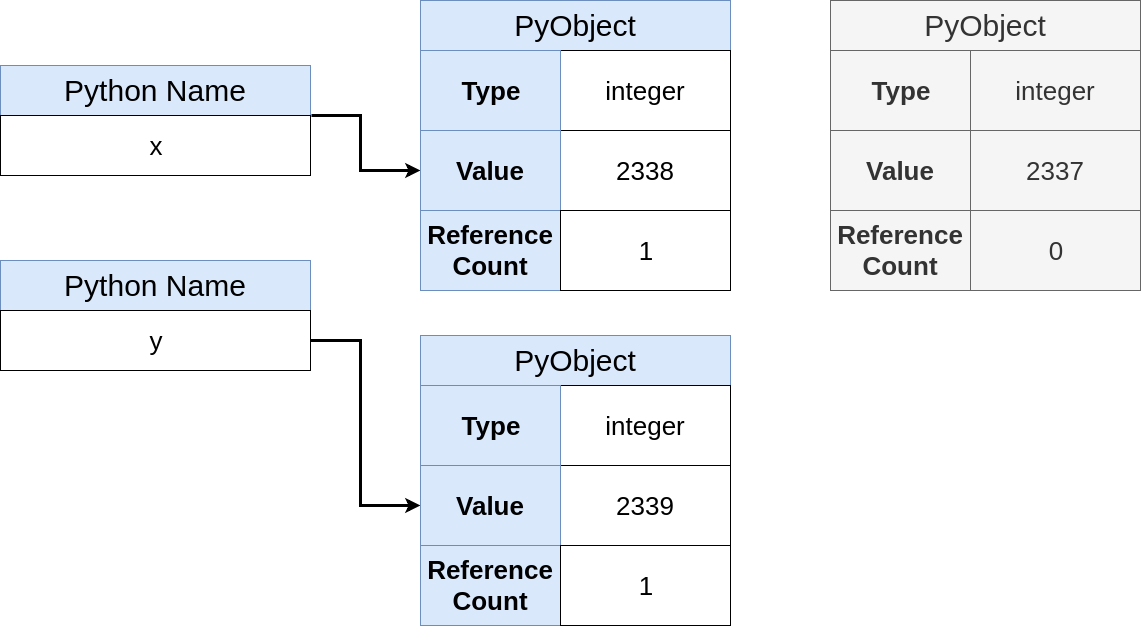
已经创建了一个新对象,
y现在指向它。 奇怪的是,如果直接将
y链接到
2339 ,我们将获得完全相同的最终状态:
>>> y = 2339
在此表达式之后,我们将获得加法运算中的最终存储状态。 让我提醒您,在Python中,您不分配变量,而是将名称绑定到链接。
关于Python实习生
现在您了解了如何在Python中创建新对象以及如何将名称附加到它们。 现在该谈论被拘留对象了。
我们有以下Python代码:
>>> x = 1000 >>> y = 1000 >>> x is y True
和以前一样,
x和
y是指向同一Python对象的名称。 但是,包含值
1000该对象不能始终具有相同的内存地址。 例如,如果您将两个数字相加得到1000,则将得到另一个地址:
>>> x = 1000 >>> y = 499 + 501 >>> x is y False
这次,字符串
x is y返回
False 。 如果您感到尴尬,请不要担心。 执行此代码后,将发生以下情况:
- 创建一个Python对象(
1000 )。
- 它被命名为
x 。
- 创建了Python对象(
499 )。
- 创建Python对象(
501 )。
- 这两个对象加起来。
- 创建一个新的Python对象(
1000 )。
- 他的名字叫
y 。
技术说明 :仅当在REPL内部执行此代码时,才会执行所描述的步骤。 如果采用以上示例,将其粘贴到文件中并运行它,则
x is y行将返回
True 。
原因在于CPython编译器的机智,它尝试执行
窥孔优化 ,以帮助尽可能节省代码执行步骤。 可以
在peyphole优化器CPython的
源代码中找到详细信息。
但这不是浪费吗? 好吧,是的,但是您要为此付出Python的所有巨大好处。 您无需考虑删除此类中间对象,甚至不需要了解它们的存在! 开玩笑的是,这些操作相对较快地执行,直到那一刻您才知道。
Python的创建者明智地注意到了这一开销,并决定进行一些优化。 他们的结果是可能令初学者惊讶的行为:
>>> x = 20 >>> y = 19 + 1 >>> x is y True
在此示例中,代码与上面几乎相同,除了我们得到
True 。 这都是关于被拘留对象的。 Python在内存中预先创建对象的特定子集,并将其存储在全局命名空间中以供日常使用。
哪些对象取决于Python实现? 在CPython 3.7中,被拘禁者是:
- 整数,范围从
-5到256 。
- 仅包含ASCII字母,数字或下划线的字符串。
这是因为这些变量在许多程序中经常使用。 通过实习,Python防止为持久对象分配内存。
小于20个字符且包含ASCII字母,数字或下划线的行将被插入,因为应该将其用作标识符:
>>> s1 = "realpython" >>> id(s1) 140696485006960 >>> s2 = "realpython" >>> id(s2) 140696485006960 >>> s1 is s2 True
此处
s1和
s2指向内存中的相同地址。 如果不插入ASCII字母,数字或下划线,则会得到不同的结果:
>>> s1 = "Real Python!" >>> s2 = "Real Python!" >>> s1 is s2 False
本示例使用感叹号,因此字符串不会被插入并且是内存中的不同对象。
奖励 :如果您希望这些对象引用相同的实习对象,则可以使用
sys.intern() 。 文档中介绍了使用此功能的一种方法:
字符串插入对于稍微提高字典搜索性能很有用:如果字典中的键和要搜索的键被插入,则可以通过比较指针而不是字符串来进行键比较(在散列之后)。 ( 来源 )
被拘禁者经常使程序员感到困惑。 只要记住,如果您开始怀疑,可以随时使用
id()来确定对象的等效性。
Python指针仿真
Python本身不存在指针的事实并不意味着您无法利用指针。 实际上,有几种方法可以在Python中模拟指针。 这里我们来看其中两个:
- 用作指向可变类型的指针。
- 使用专门准备的Python对象。
用作可变类型指针
您已经知道什么是可变类型。 由于它们的可变性,我们可以模拟指针的行为。 假设您需要复制以下代码:
void add_one(int *x) { *x += 1; }
该代码使用一个指向数字(
*x )的指针,并将该值加1。这是执行代码的主要功能:
在上面的片段中,我们将
y分配给
2337 ,显示当前值,将其增加1,然后显示一个新值。 屏幕上显示以下内容:
y = 2337 y = 2338
在Python中复制此行为的一种方法是使用可变类型。 例如,应用一个列表并更改第一个元素:
>>> def add_one(x): ... x[0] += 1 ... >>> y = [2337] >>> add_one(y) >>> y[0] 2338
这里的
add_one(x)指向第一个元素,并将其值加1。使用列表意味着结果是我们得到了更改后的值。 那么Python中有指针吗? 不行 由于列表是可变类型,因此描述的行为成为可能。 如果尝试使用元组,则会出现错误:
>>> z = (2337,) >>> add_one(z)
回溯(最近的通话走到最后):
File "<stdin>", line 1, in <module> File "<stdin>", line 2, in add_one TypeError: 'tuple' object does not support item assignment
此代码演示了元组的不变性,因此它不支持元素分配。
list不是唯一的可变类型;也使用
dict模拟了部分指针。
假设您有一个应跟踪有趣事件发生的应用程序。 这可以通过创建字典并将其元素之一用作计数器来完成:
>>> counters = {"func_calls": 0} >>> def bar(): ... counters["func_calls"] += 1 ... >>> def foo(): ... counters["func_calls"] += 1 ... bar() ... >>> foo() >>> counters["func_calls"] 2
在此示例中,词典使用计数器来跟踪函数调用的数量。 在调用
foo()计数器按预期增加了2。 还要感谢
dict 。
不要忘记,这只是指针行为的
模拟 ,它与C和C ++中的实际指针无关。 我们可以说这些操作比在C或C ++中执行的操作要昂贵得多。
使用Python对象
dict是在Python中模拟指针的好方法,但是记住您使用的键名有时很繁琐。 特别是如果您在应用程序的不同部分中使用字典。 自定义Python类可以在这里提供帮助。
假设您需要跟踪应用程序中的指标。 忽略烦人的细节的一种好方法是创建一个类:
class Metrics(object): def __init__(self): self._metrics = { "func_calls": 0, "cat_pictures_served": 0, }
这段代码定义了
Metrics类。 它仍然使用字典来存储
_metrics成员
_metrics中的最新数据。 这将为您提供所需的可变性。 现在,您只需要访问这些值。 您可以使用以下属性执行此操作:
class Metrics(object):
在这里,我们使用
@property 。 如果您不熟悉装饰器,请阅读《
Python Decorators入门》文章。 在这种情况下,
@property func_calls装饰器允许您访问
func_calls和
cat_pictures_served ,就好像它们是属性一样:
>>> metrics = Metrics() >>> metrics.func_calls 0 >>> metrics.cat_pictures_served 0
您可以将这些名称称为属性的事实意味着您从这些值存储在字典中这一事实中抽象出来。 此外,使属性名称更明确。 当然,您应该能够增加这些值:
class Metrics(object):
:
inc_func_calls()inc_cat_pics()
metrics . , , :
>>> metrics = Metrics() >>> metrics.inc_func_calls() >>> metrics.inc_func_calls() >>> metrics.func_calls 2
func_calls inc_func_calls() Python. , -
metrics , .
: ,
inc_func_calls() inc_cat_pics() @property.setter int , .
Metrics :
class Metrics(object): def __init__(self): self._metrics = { "func_calls": 0, "cat_pictures_served": 0, } @property def func_calls(self): return self._metrics["func_calls"] @property def cat_pictures_served(self): return self._metrics["cat_pictures_served"] def inc_func_calls(self): self._metrics["func_calls"] += 1 def inc_cat_pics(self): self._metrics["cat_pictures_served"] += 1
ctypes
, - Python, CPython? ctypes , C. ctypes,
Extending Python With C Libraries and the «ctypes» Module .
, , . -
add_one() :
void add_one(int *x) { *x += 1; }
,
x 1. , (shared) . ,
add.c , gcc:
$ gcc -c -Wall -Werror -fpic add.c $ gcc -shared -o libadd1.so add.o
C
add.o .
libadd1.so .
libadd1.so . ctypes Python:
>>> import ctypes >>> add_lib = ctypes.CDLL("./libadd1.so") >>> add_lib.add_one <_FuncPtr object at 0x7f9f3b8852a0>
ctypes.CDLL ,
libadd1 .
add_one() , , Python-. , . Python , .
, ctypes :
>>> add_one = add_lib.add_one >>> add_one.argtypes = [ctypes.POINTER(ctypes.c_int)]
, C. , , :
>>> add_one(1) Traceback (most recent call last): File "<stdin>", line 1, in <module> ctypes.ArgumentError: argument 1: <class 'TypeError'>: \ expected LP_c_int instance instead of int
Python ,
add_one() , . , ctypes . :
>>> x = ctypes.c_int() >>> x c_int(0)
x 0 . ctypes
byref() , .
:
.
, . , .
add_one() :
>>> add_one(ctypes.byref(x)) 998793640 >>> x c_int(1)
太好了! 1. , Python .
结论
Python . , Python.
Python:
Python .