引言
注意,这不是关于“如何使LED闪烁或如何进入STM32上的第一个中断”的另一篇“ Hello world”文章。 但是,我试图对提出的所有问题进行全面的解释,因此本文不仅对许多专业人士和梦想成为此类开发人员的人(如我希望的那样)有用,而且对新手微控制器程序员也很有用,因为该主题由于某种原因而在无数网站上流传/博客“ MK编程老师”。
我为什么决定写这个?
尽管我之前曾夸张地说过,Cortex-M系列的硬件位带并没有在专门的资源中描述,但仍然有一些地方涵盖了此功能(甚至在这里只见过一篇文章),但是显然这个话题需要补充和现代化。 我注意到这也适用于英语资源。 在下一节中,我将解释为什么此内核功能可能非常重要。
理论
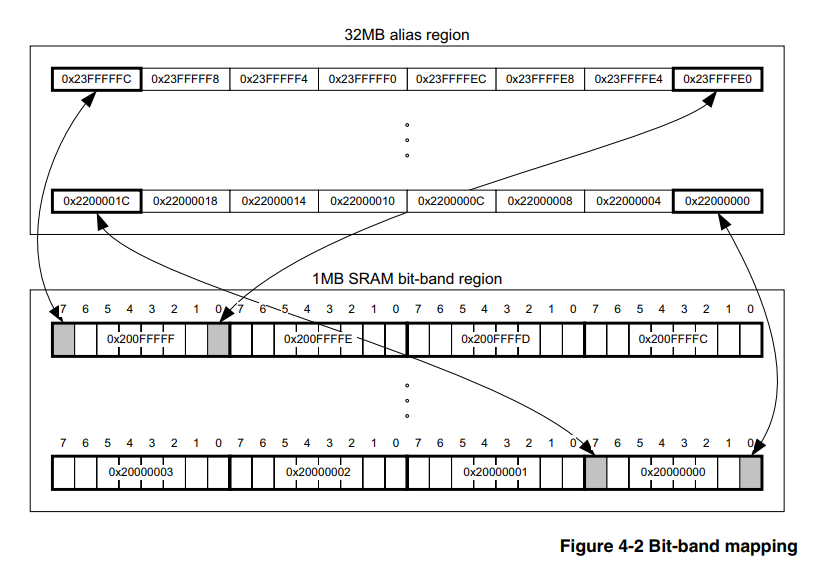
(那些认识她的人可以立即开始练习)硬件位绑定是内核本身的功能,因此不依赖于微控制器制造商的家族和公司,主要是内核是合适的。 在我们的案例中,将其设为Cortex-M3。 因此,有关此问题的信息应在核心本身的正式文档中寻求,并且有这样一个文档,
这里的第4.2节详细介绍了如何使用此工具。
在这里,我想对那些不熟悉汇编器的程序员做些技术上的改动,而现在大多数程序员是这样,这是由于诸如STM32,LPC等“严重”的32位微控制器的汇编器的复杂性和无用性引起的。此外,人们经常会遇到尝试即使在Habr上,也禁止在此区域使用汇编程序。 在本节中,我想简要描述写入MK存储器的机制,这应该阐明位带的优点。
我将为大多数STM32解释一个特定的简单示例。 假设我需要将PB0转换为通用输出。 一个典型的解决方案如下所示:
GPIOB->MODER |= GPIO_MODER_MODER0_0;
显然,我们使用按位“或”是为了不覆盖寄存器的其余位。
对于编译器,这将转换为以下4条指令集:
- 将GPIOB-> MODER下载到通用寄存器(RON)
- 将值从p1上载到RON指示的地址处的另一个RON。
- 使用GPIO_MODER_MODER0_0对该值进行按位“或”运算。
- 将结果下载回GPIOB-> MODER。
同样,不要忘记该内核使用thumb2指令集,这意味着它们的体积可以不同。 我还注意到,我们到处都在谈论O3的优化级别。
用汇编语言,它看起来像这样:

可以看出,第一条指令不过是带有偏移量的伪指令,我们在PC地址(给定传送带)+ 0x58处找到寄存器的地址。
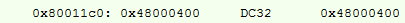
事实证明,每个操作有4个步骤(以及更多的时钟周期)和14个字节的占用内存。
如果您想进一步了解这一点,那么我推荐这本书[2],其中还有俄语。
我们传递给bit_banding方法。
据农民说,其实质是处理器具有专门分配的存储区,可将我们不更改外设寄存器或RAM其他位的值写入其中。 也就是说,我们不需要满足上述2)和3)的要求,为此,仅根据[1]中的公式重新计算地址就足够了。

我们正在尝试执行类似的操作,即其汇编程序:

重新计算的地址:

在这里,我们在RON中添加了一条写指令#1,但是无论如何,结果是10个字节,而不是14个字节,并且时钟周期减少了几个。
但是,如果区别太可笑了怎么办?
一方面,节省的幅度并不大,尤其是在已经习惯将控制器超频到168 MHz的周期中。 在一个普通的项目中,可以使用此方法的时间分别为40-80,如果地址不同,则节省的字节数可以达到250个字节。 而且,如果我们现在认为直接在寄存器上编程MK被认为是“ zashkvar”,并且使用各种骰子立方体“很酷”,那么节省的钱可能更多。
同样,由于社区积极使用高级库,固件膨胀到不雅大小,导致250字节的数字失真。 当进行低级编程时,具有熟练的体系结构和O3优化功能,这至少是一个普通项目的软件量的2-5%。
再说一遍,我不想说这是每个自重的MK程序员都应该使用的一种超级双端超酷工具。 但是,即使我可以削减成本这么少,那为什么不呢?实作
所有选项仅用于配置外围设备,因为我没有遇到需要RAM的情况。 严格来说,对于RAM,公式是相似的,只需更改基址即可进行计算。 那么如何实现呢?
组装工
让我们从我心爱的汇编程序的底部开始。
在汇编器项目中,我通常在整个项目的#0和#1下分配几个2字节的RON(根据与它们一起使用的指令),并在宏中也使用它们,这会不断减少我另外2个字节。 注意,我没有在STM的Assembler中找到CMSIS,因为我立即在宏中输入了位数,而不是其寄存器值。
GNU汇编器的实现 @ . MOVW R0, 0x0000 MOVW R1, 0x0001 @ .macro PeriphBitSet PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+(((\PerReg) - BIT_BAND_REGION) * 32) + ((\BitNum) * 4)) STR R1, [R3] .endm @ .macro PeriphBitReset PerReg, BitNum LDR R3, =(BIT_BAND_ALIAS+((\PerReg - BIT_BAND_REGION) * 32) + (\BitNum * 4)) STR R0, [R3] .endm
范例:
汇编程序示例 PeriphSet TIM2_CCR2, 0 PeriphBitReset USART1_SR, 5
该选项的优势无疑是我们拥有完全控制权,这不能说是其他选项。 正如文章的最后一部分将显示的那样,这一点
非常重要。
但是,从零开始大约没有人需要在Assembler中进行MK的项目,这意味着您需要切换到SI。
普通c
老实说,我在路径的开头,在广阔的网络中的某个地方找到了一个简单的Sishny选项。 那时,我已经在Assembler中实现了位组合,并且偶然发现了C文件,它立即起作用了,我决定不发明任何东西。
普通C的实现 #define MASK_TO_BIT31(A) (A==0x80000000)? 31 : 0 #define MASK_TO_BIT30(A) (A==0x40000000)? 30 : MASK_TO_BIT31(A) #define MASK_TO_BIT29(A) (A==0x20000000)? 29 : MASK_TO_BIT30(A) #define MASK_TO_BIT28(A) (A==0x10000000)? 28 : MASK_TO_BIT29(A) #define MASK_TO_BIT27(A) (A==0x08000000)? 27 : MASK_TO_BIT28(A) #define MASK_TO_BIT26(A) (A==0x04000000)? 26 : MASK_TO_BIT27(A) #define MASK_TO_BIT25(A) (A==0x02000000)? 25 : MASK_TO_BIT26(A) #define MASK_TO_BIT24(A) (A==0x01000000)? 24 : MASK_TO_BIT25(A) #define MASK_TO_BIT23(A) (A==0x00800000)? 23 : MASK_TO_BIT24(A) #define MASK_TO_BIT22(A) (A==0x00400000)? 22 : MASK_TO_BIT23(A) #define MASK_TO_BIT21(A) (A==0x00200000)? 21 : MASK_TO_BIT22(A) #define MASK_TO_BIT20(A) (A==0x00100000)? 20 : MASK_TO_BIT21(A) #define MASK_TO_BIT19(A) (A==0x00080000)? 19 : MASK_TO_BIT20(A) #define MASK_TO_BIT18(A) (A==0x00040000)? 18 : MASK_TO_BIT19(A) #define MASK_TO_BIT17(A) (A==0x00020000)? 17 : MASK_TO_BIT18(A) #define MASK_TO_BIT16(A) (A==0x00010000)? 16 : MASK_TO_BIT17(A) #define MASK_TO_BIT15(A) (A==0x00008000)? 15 : MASK_TO_BIT16(A) #define MASK_TO_BIT14(A) (A==0x00004000)? 14 : MASK_TO_BIT15(A) #define MASK_TO_BIT13(A) (A==0x00002000)? 13 : MASK_TO_BIT14(A) #define MASK_TO_BIT12(A) (A==0x00001000)? 12 : MASK_TO_BIT13(A) #define MASK_TO_BIT11(A) (A==0x00000800)? 11 : MASK_TO_BIT12(A) #define MASK_TO_BIT10(A) (A==0x00000400)? 10 : MASK_TO_BIT11(A) #define MASK_TO_BIT09(A) (A==0x00000200)? 9 : MASK_TO_BIT10(A) #define MASK_TO_BIT08(A) (A==0x00000100)? 8 : MASK_TO_BIT09(A) #define MASK_TO_BIT07(A) (A==0x00000080)? 7 : MASK_TO_BIT08(A) #define MASK_TO_BIT06(A) (A==0x00000040)? 6 : MASK_TO_BIT07(A) #define MASK_TO_BIT05(A) (A==0x00000020)? 5 : MASK_TO_BIT06(A) #define MASK_TO_BIT04(A) (A==0x00000010)? 4 : MASK_TO_BIT05(A) #define MASK_TO_BIT03(A) (A==0x00000008)? 3 : MASK_TO_BIT04(A) #define MASK_TO_BIT02(A) (A==0x00000004)? 2 : MASK_TO_BIT03(A) #define MASK_TO_BIT01(A) (A==0x00000002)? 1 : MASK_TO_BIT02(A) #define MASK_TO_BIT(A) (A==0x00000001)? 0 : MASK_TO_BIT01(A) #define BIT_BAND_PER(reg, reg_val) (*(volatile uint32_t*)(PERIPH_BB_BASE+32*((uint32_t)(&(reg))-PERIPH_BASE)+4*((uint32_t)(MASK_TO_BIT(reg_val)))))
如您所见,这是一段用处理器语言编写的非常简单明了的代码。 此处的主要工作是将CMSIS值转换为位数,因为不需要汇编程序版本。
哦,是的,像这样使用此选项:
普通C的示例 BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = 0;
但是,现代的趋势(据我的观察,大约是从2015年开始的)是趋势,甚至对于MK都赞成用C ++代替C。 而且宏不是最可靠的工具,因此下一个版本注定要诞生。
Cpp03
在这里,一个非常有趣且经过讨论的工具,但鉴于其复杂性而很少使用,并出现了一个经典的阶乘示例,该工具是元编程。
毕竟,将变量的值转换为位数的任务是理想的(CMSIS中已经有值),在这种情况下,这对于编译时是可行的。
我使用模板实现了以下步骤:
C ++ 03的实现 template<uint32_t val, uint32_t comp_val, uint32_t cur_bit_num> struct bit_num_from_value { enum { bit_num = (val == comp_val) ? cur_bit_num : bit_num_from_value<val, 2 * comp_val, cur_bit_num + 1>::bit_num }; }; template<uint32_t val> struct bit_num_from_value<val, static_cast<uint32_t>(0x80000000), static_cast<uint32_t>(31)> { enum { bit_num = 31 }; }; #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value<static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)>::bit_num)))
您可以使用相同的方式使用它:
C ++ 03的示例 BIT_BAND_PER(GPIOB->MODER, GPIO_MODER_MODER0_0) = false;
为何还剩下宏? 事实是,我不知道有什么其他方法可以确保在不进入程序代码其他区域的情况下插入此操作。 如果他们在评论中提示我,我将非常高兴。 模板和内联函数均未提供此类保证。 是的,这里的宏可以很好地处理其任务,仅因为
遵从者就认为这是“不安全的”,所以更改宏是没有意义的。
令人惊讶的是,时间还没有停滞不前,编译器越来越支持C ++ 14 / C ++ 17,为什么不利用这些创新,使代码更易于理解。
cpp14 / cpp17
C ++ 14的实现 constexpr uint32_t bit_num_from_value_cpp14(uint32_t val, uint32_t comp_val, uint32_t bit_num) { return bit_num = (val == comp_val) ? bit_num : bit_num_from_value_cpp14(val, 2 * comp_val, bit_num + 1); } #define BIT_BAND_PER(reg, reg_val) *(reinterpret_cast<volatile uint32_t *>(PERIPH_BB_BASE + 32 * (reinterpret_cast<uint32_t>(&(reg)) - PERIPH_BASE) + 4 * (bit_num_from_value_cpp14(static_cast<uint32_t>(reg_val), static_cast<uint32_t>(0x01), static_cast<uint32_t>(0)))))
如您所见,我只是用递归constexpr函数替换了模板,在我看来,这对于人眼来说更清晰。
使用相同的方法。 顺便说一下,在C ++ 17中,原则上可以使用递归lambda constexpr函数,但是我不确定这至少会导致一些简化,并且也不会使汇编程序的顺序复杂化。
总之,根据“理论”部分,所有三种C / Cpp实现都给出了同样正确的指令集。 很长时间以来,我一直在使用IAR ARM 8.30和gcc 7.2.0的所有实现。实践是a子
看来这就是全部。 计算内存节省量,选择实现方案,以准备提高性能。 不是在这里,这只是理论和实践存在分歧的情况。 什么时候不同?
如果不进行测试,我永远不会发布它,但是实际上减少了项目上的占用量。 我专门在几个老项目中用没有掩码的常规实现替换了此宏,并研究了两者之间的区别。 结果令人惊讶。
事实证明,音量实际上保持不变。 我专门选择了恰好使用了40-50个此类说明的项目。 根据理论,我必须保存至少100个字节,最多保存200个字节。实际上,差异为24-32个字节。 但是为什么呢?
通常,设置外围设备时,几乎会连续设置5-10个寄存器。 在高度优化的情况下,编译器不会按照寄存器的顺序准确地排列指令,而是按照看起来正确的方式排列指令,有时会在似乎不可分割的地方干扰它们。
我看到两个选择(这是我的推测):
- 还是编译器非常聪明,以至于您会知道如何优化指令集
- 还是编译器还不比一个人聪明,当他遇到这样的结构时会感到困惑
也就是说,事实证明,只有在没有一个类似的操作存在类似操作的情况下,这种以“高级”语言进行高度优化的方法才可以正确地工作。
顺便说一下,在O0级别上,理论和实践在任何情况下都会融合,但是我对这种优化级别不感兴趣。
我总结
否定结果也是结果。 我认为每个人都会为自己得出结论。 就我个人而言,我将继续使用此技术,从中可以肯定不会更糟。
我希望这很有趣,并且我要对那些读到最后的人表示极大的敬意。
文献清单
- “ Cortex-M3技术参考手册”,ARM 2005,第4.2节。
- 有关ARM Cortex-M3的权威指南,Joseph Yiu。
附言:我的书包里几乎涵盖了与嵌入式电子产品开发相关的主题。 让我知道,如果有兴趣的话,我会慢慢得到的。
PPS插入代码段不知何故弯曲,如果可能,请告诉我如何进行改进。 通常,您可以将一段感兴趣的代码复制到记事本中,从而避免在分析中产生不愉快的情绪。
UPD:
应读者的要求,我指出位绑定操作本身是原子的,这在使用寄存器时为我们提供了一些安全性。 这是此方法最重要的功能之一。