如您所知,代码的读取次数比编写的次数要多。 这样至少除作者以外的其他人都可以阅读它,并且有样式指南。 对于R,这可能是例如Hadley手册。
样式指南不仅是开发人员之间的默认协议-许多规则都有很好的背景。 为什么箭头
<-比等号
= ,为什么R的旧时人不喜欢下划线,推荐的行长与打孔卡之间的关系,等等。
免责声明:R样式指南与Python不同,R没有统一的标准。 因此,没有单一的指南。 除了
Hadley指南 (或其
tidyverse的扩展版本)之外,还有其他一些指南,例如
Google或
Bioconductor 。
但是,可以将Hadley指南视为最常见的指南(例如
内置的 RStudio
检查 ),而Hadley自己创建的库(dplyr,ggplot,tidyr以及tidyverse集合中的其他库)的普及极大地简化了该指南。
1.赋值运算符: <- vs =
所有可用指南都建议使用非标准运算符
<- ,但不要使用等号
= ,这在其他现代语言中很常见。 甚至没有提到其他三个运算符(
<<- ,
-> ,
->> )(就像早期版本中的运算符
:= )。 看来,为什么我们需要这个非标准箭头?
历史向我们揭示了卡片:在R中,箭头来自S,而箭头又从APL继承而来。 在APL中,它使我们能够将分配与平等区分开。 在R中,相等运算符是标准的,因此差异是不同的。 如果箭头最初是赋值运算符,则等号
仅将值分配
给命名参数。 在2001年,等号成为了赋值运算符,但从未成为箭头的同义词。
是什么让我们考虑
=完全替代箭头? 首先,
=赋值运算符仅在顶层工作。 例如,在函数内部,一切将像以前一样工作:
mean(x = 1:5)
这里
=仅设置函数参数,而
<-还将值分配给变量x。 我们可以通过将赋值操作放在括号中来达到相同的效果
(不,这仍然不是Lisp) :
mean ((x = 1:5))
...或大括号:
mean ({x = 1:5})
此外,箭头优先于等号:
x <- y <- 1
最后一个表达式失败,因为它等于
(x <- y) = 4 ,并且解析器将其解释为
`<-<-`(x, y = 4, value = 4)
换句话说,我们试图执行不正确的操作:首先我们将x分配给y,然后尝试将x和y分配给4。仅当您使用括号更改操作的优先级时,该表达式才会被正确处理:
x <- (y = 4) 。
2.间距
该指南建议在运算符之间(当然,方括号,:,::和:::除外)以及左括号之间放置空格。 显然,这是GNU编码标准的一部分。 但是,此子句与
<-作为赋值运算符的使用密切相关。 举个例子
x <-1
这是什么 X小于-1? 或将x设为1?
但是,多余的空间并不比缺少的空间好,例如:
x <- 0 ifelse(x <-1, T, F)
在第一种情况下,
<和
-之间没有空格,这将创建一个赋值运算符。
3.函数和变量的名称
样式指南在名称问题上存在分歧:Hadley指南建议在所有名称下划线。 Google指南-以点分隔变量和驼峰样式,函数首小写; Bioconductor建议针对功能和变量使用lowerCamel。 R社区在这个问题上没有统一性,可以找到所有可能的样式:
lowerCamel period.separation lower_case_with_underscores allowercase UpperCamel
即使对于基本R名称也没有统一的样式(例如,行名和row.name是不同的功能!)。 如果您不考虑不允许使用的大写字母(只有Matlab用户会喜欢),则有三种最受欢迎的样式:lowerCamel,带_的小写字母和带点分隔的小写字母。
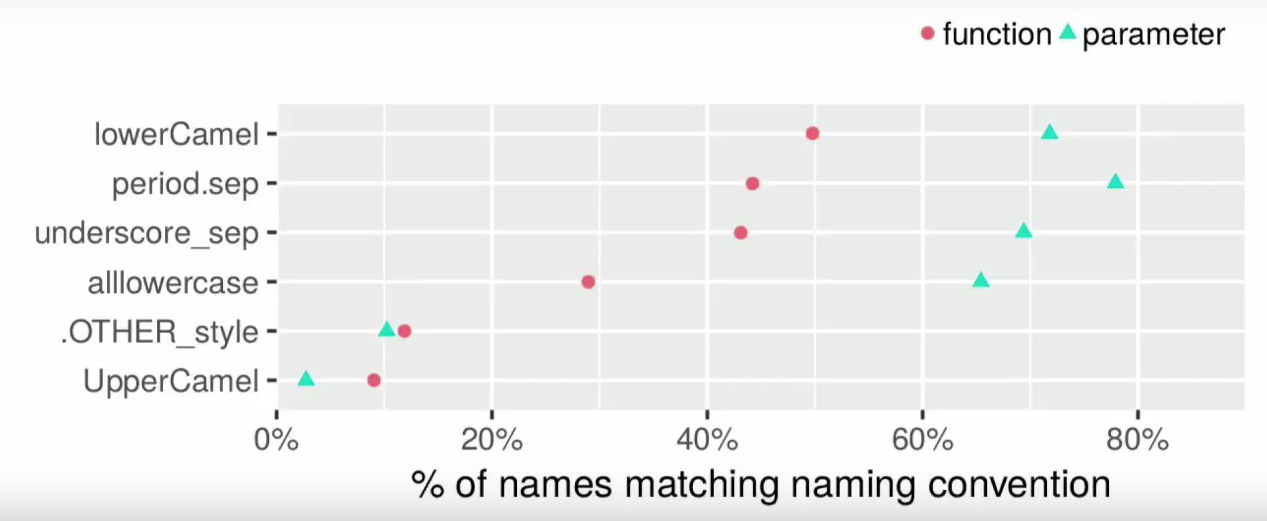
函数名称和参数使用不同样式(一种名称可以对应不同样式)。 资料来源:RasmusBååth在useR!2017上的
表现 。
2012年也是如此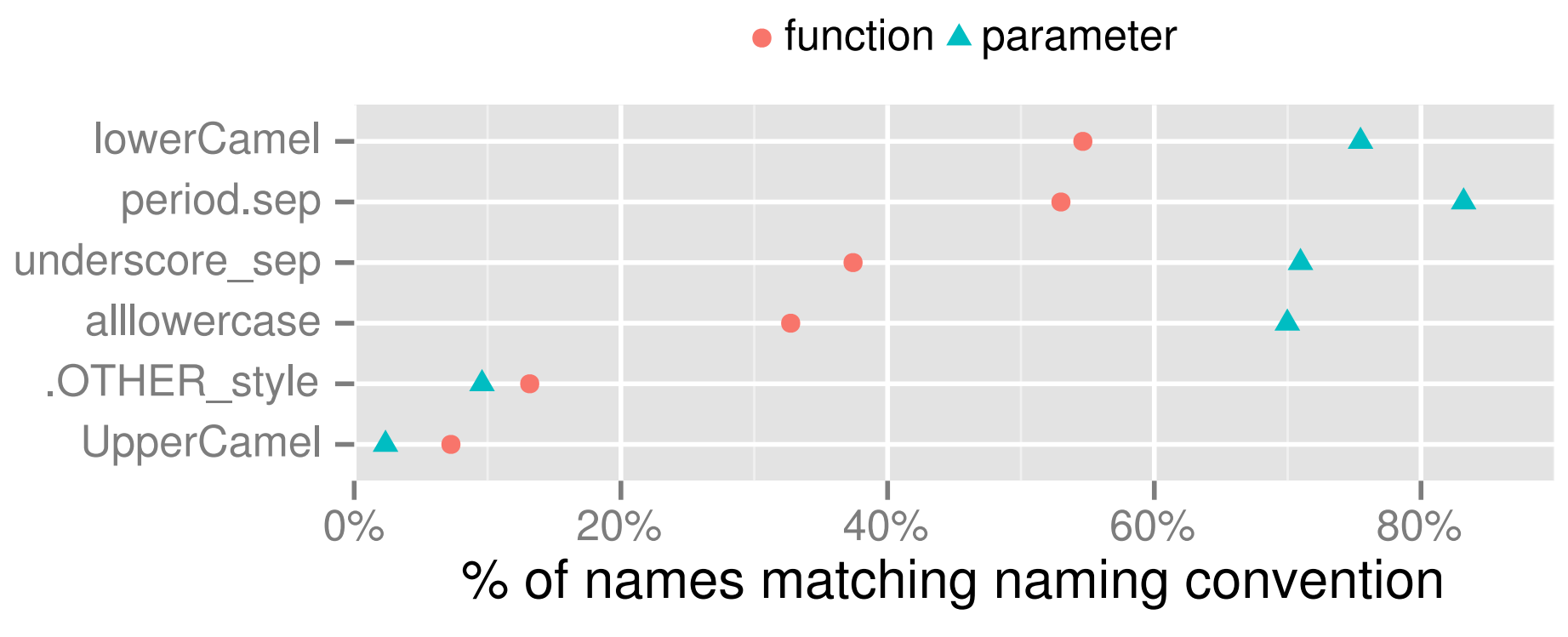
资料来源:Baath(2012)。 “
R中的命名约定状态 ”。 R杂志第一卷 4/2,第74-75页。
点对点分离让人不禁联想到面向对象编程中方法的使用,但在历史上是很普遍的。 这种特殊的样式非常普遍,可以被视为真正的R'vsky。 例如,大多数基本功能都专门使用它(并且每个刚遇到data.table和as.factor的人)。
但是分隔符_是最不流行的样式之一(在这里,哈德利与大多数人背道而驰)。 对于许多R用户而言,下划线会很烦人:在流行的Emacs Speaks Statistics扩展中,默认情况下将其替换为赋值运算符
<- 。 当然,默认设置
几乎没有任何变化。
但是,Emacs ESS的影响仍然是“尾巴摇狗”类别的一种解释。 还有一个更古老的原因:在R的早期版本中,下划线是箭头
<-同义词。 例如,在2000年,您可能会
遇到以下情况:
在这里,R不是创建变量
c_mean ,而是
c_mean值3分配给变量mean,然后分配给变量c。 在现代R中,这种变形当然不会发生。
由于不受欢迎,因此基本的_函数几乎找不到:
最后,使用长名称时,lowerCamel样式的可读性很差:
因此,就名称而言,指南建议不能被认为是明确的。 毕竟,这是一个品味问题(只要保持一致性)。
4.花括号
根据指南,在大括号开头应加上新行,而在大括号后面应另行(除非跟随在其他行上)。 即 像这样的东西:
if (x >= 0) { log(x) } else { message("Not applicable!") }
这里的一切都不是很有趣:这是K&R的标准缩进样式,可以追溯到C语言以及Kernigan和Ritchie着名的著作“ The C Programming Language”(或K&R的作者名字)。
这种样式的起源也很明显:它可以让您节省线条,同时保持可读性。 对于早期的计算机,垂直空间实在是太奢侈了。 例如,C是在PDP-11上开发的,其终端只有24条线。 在打印K&R书籍时,这种样式节省了纸张!
5. 80个字符串
根据指南,建议的行长为80个字符。 神奇数字80不仅可以在R中找到,还可以在许多其他语言(Java,Perl,PHP等)中找到。 不仅是语言:Windows命令行也包含80个字符。
第一次在编程中,这个数字出现在1928年,而不是标准的IBM打孔卡,那里有80列数据。 一个更有趣的问题是为什么选择了这样的标准? 毕竟,以前使用过不同长度的打孔卡(适用于24或45列)。

最受欢迎的答案是打孔卡的长度与打字机的行长有关。 第一台机器是为8½x 11英寸的美国标准纸设计的,根据页边距的大小,可以打印72至90个字符。 因此,每行80个字符的版本看起来很合理,尽管在最后一招中并非如此。 就人体工程学而言,80个字符可能只是中间地带。
6.行缩进:空格与制表符
指南建议的样式是两个空格,而不是制表符。 拒绝制表是可以理解的:TAB的长度在不同的文本编辑器中有所不同(可以是2到8个空格)。 拒绝它们,我们立即获得两个好处:首先,代码看起来与我们键入的代码完全相同; 其次,不会意外违反建议的字符串长度。 当然,在这种情况下,我们会增加文件大小(谁想要在2k19中处理此类微优化?)
争议空间与标签之间的历史悠久,可以等同于宗教领域(例如Win与Linux,Android与iOS等)。 但是,我们已经知道是谁赢了:根据Stack Overflow
研究 ,使用空格的开发人员比使用制表符的开发人员收入更高。 比样式指南的规则更有说服力吧?
而不是得出结论:样式指南
的规则似乎很奇怪且不合逻辑。 确实,为什么箭头
<-如果存在标准运算符
= ? 但是,如果您深入研究,那么每条规则背后都有一些逻辑,通常已经被人们遗忘了。