自动审核系统在需要处理大量用户消息的Web服务和应用程序中实现。 这样的系统可以减少手动审核的成本,加快手动审核的速度并实时处理所有用户消息。 在本文中,我们将讨论构建使用机器学习算法处理英语的自动审核系统。 我们将讨论从研究任务和ML算法选择到正式投产的整个管道工作。 让我们看看在哪里寻找现成的数据集,以及如何自己为任务收集数据。
由Poteha Labs的数据科学家Ira Stepanyuk( id_step )编写任务说明
我们与多用户主动聊天一起工作,每分钟一次聊天中可以接收来自数十个用户的短信。 任务是在此类聊天的对话框中突出显示有毒消息和带有任何淫秽言论的消息。 从机器学习的角度来看,这是一个二进制分类任务,其中必须将每个消息分配给一个类。
为了解决这个问题,首先,必须了解什么是有毒信息,以及究竟是什么使它们有毒。 为此,我们查看了Internet上的大量典型用户消息。 以下是一些我们已经分为有毒和正常信息的示例。
可以看出,有毒信息通常包含淫秽单词,但这仍然不是前提条件。 该消息可能不包含不适当的单词,但会冒犯他人(示例(1))。 另外,有时有毒和正常的信息包含在不同上下文中使用的相同单词-是否令人反感(示例(2))。 这样的消息也需要能够区分。
在研究了各种消息之后,对于我们的审核系统,我们将那些包含淫秽,侮辱性表达或仇恨他人言论的消息称为
有毒 。
资料
打开数据
最著名的审核数据集之一是来自Kaggle
有毒评论分类挑战赛的数据集。 数据集中的部分标记不正确:例如,带有淫秽单词的邮件可以标记为正常。 因此,您不能只参加内核竞赛并获得运行良好的分类算法。 您需要更多地使用数据,查看哪些示例还不够,并使用此类示例添加其他数据。
除了竞赛外,还有一些科学出版物,它们具有指向适当数据集的链接(
例如 ),但并非所有出版物都能用于商业项目。 通常,这些数据集包含来自社交网络Twitter的消息,您可以在其中找到许多有毒的推文。 此外,数据是从Twitter收集的,因为某些主题标签可用于搜索和标记有毒的用户消息。
手动数据
在我们从开放源收集数据集并对其进行基本模型训练之后,很明显开放数据是不够的:模型的质量并不令人满意。 除了用于解决问题的开放数据之外,我们还提供了游戏信使中未分配的带有大量有毒消息的消息选择。

要将这些数据用于他们的任务,必须以某种方式标记它们。 当时,已经有训练有素的基线分类器,我们决定将其用于半自动标记。 通过模型运行所有消息后,我们获得了每条消息的毒性概率,并按降序排序。 在此列表的开头,收集了带有淫秽和令人反感的词语的邮件。 相反,最后有正常的用户消息。 因此,大多数数据(具有非常大和非常小的概率值)无法被标记出来,而是立即分配给特定类别。 它仍然可以标记落在列表中间的消息,这是手动完成的。
数据扩充
通常,在数据集中,您会看到分类器输入错误的更改消息,并且人员可以正确理解其含义。
这是因为用户可以调整并学习欺骗审核系统,以便算法在有毒消息上犯错误,并且对人而言含义仍然清楚。 用户现在正在做什么:
- 错别字产生: 你是个笨蛋,怕你 ,
- 用描述中类似的数字替换字母字符: n1gga,b0ll0cks ,
- 插入多余的空格: 白痴 ,
- 删除单词之间的空格: dieyoustupid 。
为了训练可抵抗此类替换的分类器,您需要执行用户的操作:在消息中生成相同的更改,并将其添加到主数据的训练集中。
通常,这种斗争是不可避免的:用户将始终尝试查找漏洞和黑客,主持人将实施新算法。
子任务的描述
我们面临着以两种不同模式分析消息的子任务:
- 在线模式-实时分析消息,并具有最快的响应速度;
- 脱机模式-分析消息日志并分配有毒对话框。
在联机模式下,我们处理每个用户消息并在模型中运行它。 如果消息有毒,则将其隐藏在聊天界面中,如果消息正常,则将其显示。 在这种模式下,所有消息都应得到非常迅速的处理:该模型应尽快做出响应,以免破坏用户之间对话的结构。
在离线模式下,工作没有时间限制,因此我想以最高质量实施该模型。
联机模式。 字典搜寻
无论接下来选择哪种模型,我们都必须查找并过滤带有淫秽文字的消息。 要解决此子问题,最简单的方法是编译一个字典,其中包含不能跳过的无效单词和表达式,并在每条消息中搜索此类单词。 搜索应该很快,因此该时间的幼稚子字符串搜索算法不适合。 用于查找字符串中
的一组单词的合适算法是
Aho-Korasik算法 。 由于这种方法,可以在将某些有毒的示例传输到主算法之前快速识别出一些有毒的示例并阻止消息。 使用ML算法将使您“了解消息的含义”并提高分类质量。
联机模式。 基本机器学习模型
对于基本模型,我们决定对文本分类使用标准方法:TF-IDF +经典分类算法。 再次出于速度和性能的原因。
TF-IDF是一种统计量度,它使您可以使用两个参数来确定正文中最重要的单词:每个文档中单词的出现频率和包含特定单词的文档数量(在
此处更详细地介绍)。 计算出TF-IDF消息中的每个单词后,我们得到了该消息的矢量表示。
可以为文本中的单词以及n-gram单词和字符计算TF-IDF。 这样的扩展将更好地工作,因为它将能够处理训练集中未出现的频繁出现的短语和单词(词汇以外)。
from sklearn.feature_extraction.text import TfidfVectorizer from scipy import sparse vect_word = TfidfVectorizer(max_features=10000, lowercase=True, analyzer='word', min_df=8, stop_words=stop_words, ngram_range=(1,3)) vect_char = TfidfVectorizer(max_features=30000, lowercase=True, analyzer='char', min_df=8, ngram_range=(3,6)) x_vec_word = vect_word.fit_transform(x_train) x_vec_char = vect_char.fit_transform(x_train) x_vec = sparse.hstack([x_vec_word, x_vec_char])
在n-gram的单词和字符上使用TF-IDF的示例将消息转换为向量后,您可以使用任何经典的分类方法:
逻辑回归,SVM ,
随机森林,boosting 。
我们决定在我们的任务中使用逻辑回归,因为与其他经典的ML分类器相比,该模型可提高速度并预测分类概率,从而使您可以灵活地选择生产中的分类阈值。
使用TF-IDF和逻辑回归获得的算法可以快速运行,并且可以很好地定义带有淫秽单词和表达式的消息,但并不总是理解含义。 例如,经常出现带有“
黑色 ”和“
女性粉刺 ”字样的消息属于有毒类别。 我想解决此问题,并学习使用下一版本的分类器更好地理解消息的含义。
离线模式
为了更好地理解消息的含义,可以使用神经网络算法:
- 嵌入(Word2Vec,FastText)
- 神经网络(CNN,RNN,LSTM)
- 新的预训练模型(ELMo,ULMFiT,BERT)
我们将讨论其中一些算法,以及如何更详细地使用它们。
Word2Vec和FastText
嵌入模型使您可以从文本中获取单词的矢量表示。
Word2Vec有
两种类型 :跳过语法表和CBOW(连续词袋)。 在Skip-gram中,上下文由单词预测,但在CBOW中,反之亦然:单词由上下文预测。
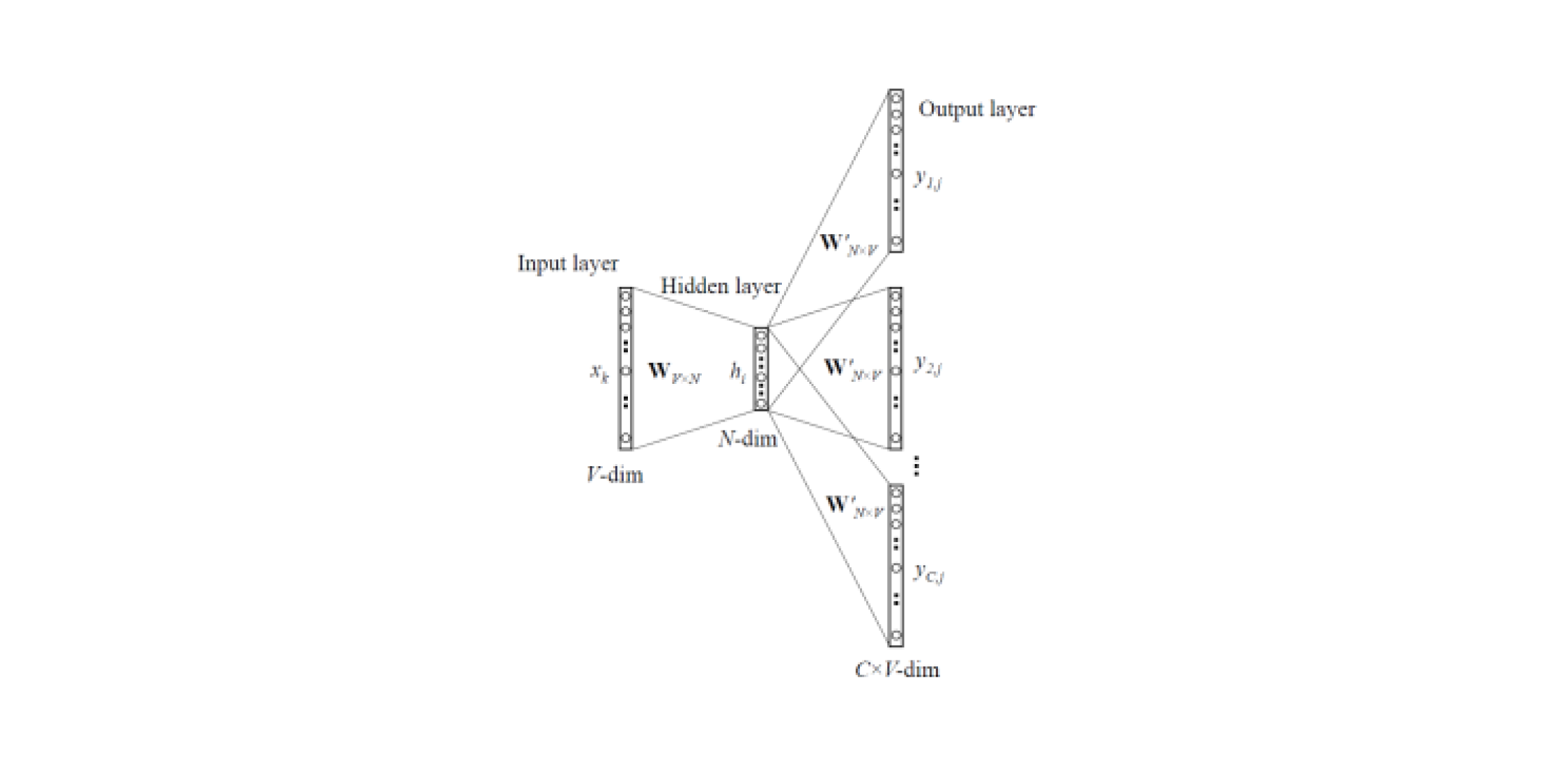
此类模型在大量文本上进行训练,并允许您从训练有素的神经网络的隐藏层中获取单词的矢量表示。 这种体系结构的缺点是该模型从语料库中包含的一组有限词中学习。 这意味着在培训阶段,对于不在正文中的所有单词,都将没有嵌入。 当使用预训练的模型执行任务时,通常会发生这种情况:对于某些单词,将不会有任何嵌入,因此会丢失大量有用的信息。
为了解决词典中没有的单词(OOV,词汇不足)的问题,存在一种改进的嵌入模型
-FastText 。 FastText不是使用单个单词来训练神经网络,而是将单词分解为n-gram(子单词)并从中学习。 要获取单词的向量表示,您需要获取该单词的n-gram的向量表示并将其相加。
因此,可以使用经过预训练的Word2Vec和FastText模型从消息中获取特征向量。 可以使用经典ML分类器或完全连接的神经网络对获得的特征进行分类。
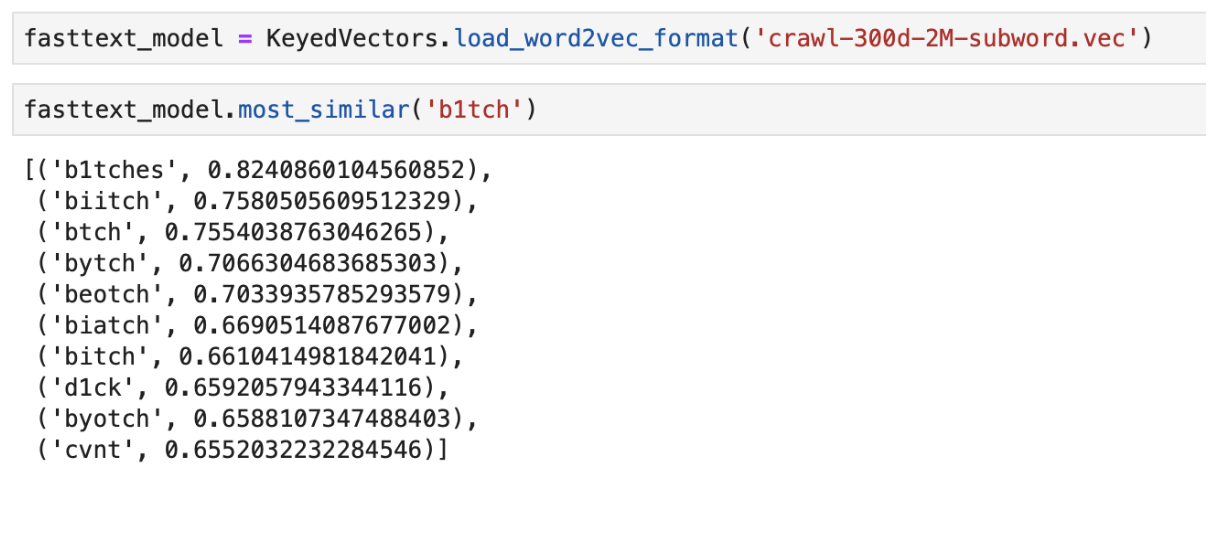 使用预先训练的FastText输出“最接近”的意思的示例
使用预先训练的FastText输出“最接近”的意思的示例CNN分类器
对于来自神经网络算法的文本处理和分类,更经常使用递归网络(LSTM,GRU),因为它们与序列配合得很好。 卷积网络(CNN)最常用于图像处理,但是它们也
可以用于文本分类任务。 考虑如何做到这一点。
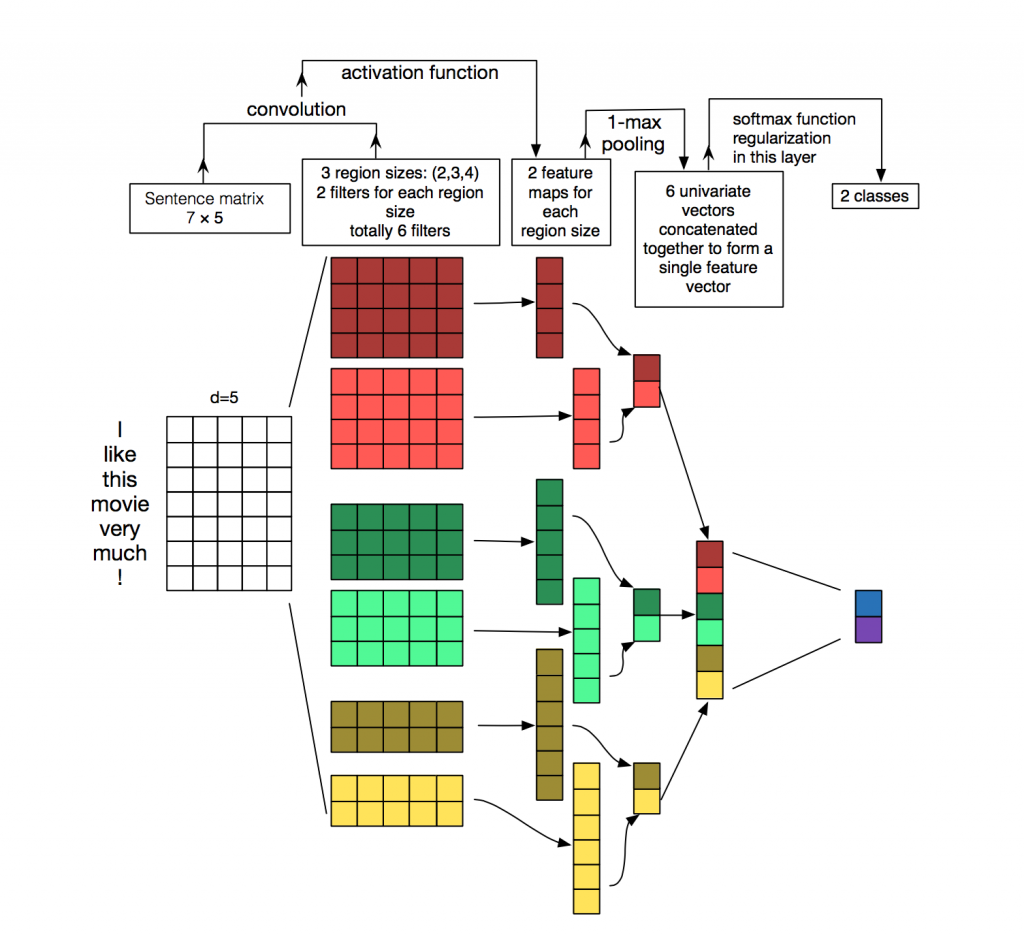
每个消息都是一个矩阵,在该矩阵中,令牌(单词)的每一行都记录了其向量表示。 卷积以某种方式应用于这种矩阵:卷积滤波器在矩阵的整个行(单词向量)上“滑行”,但一次捕获多个单词(通常为2-5个单词),从而在相邻单词的上下文中处理这些单词。 在
图片中可以看到有关此情况的详细信息。
可以使用递归时,为什么要使用卷积网络进行文字处理? 事实是,卷积工作得更快。 使用它们对消息进行分类,可以大大节省培训时间。
艾莫
ELMo(来自语言模型的嵌入)是基于
最近引入的语言模型的嵌入模型。 新的嵌入模型不同于Word2Vec和FastText模型。 ELMo单词向量具有某些优点:
- 每个单词的显示方式取决于使用该单词的整个上下文。
- 表示法是基于符号的,它可以为OOV(词汇量)单词形成可靠的表示法。
ELMo可用于NLP中的各种任务。 例如,对于我们的任务,可以将使用ELMo接收到的消息向量发送到经典ML分类器,或者使用卷积或完全连接的网络。
ELMo预训练的嵌入对于您的任务而言非常易于使用,可以在
此处找到使用示例。
实施功能
烧瓶API
API原型使用Flask编写,因为它易于使用。
两个Docker映像
对于部署,我们使用了两个docker映像:基本的docker映像,其中安装了所有依赖项,主要的一个映像用于启动应用程序。 由于很少重建第一个映像,因此大大节省了组装时间,并且节省了部署期间的时间。 建立和下载机器学习库花费了大量时间,这对于每次提交来说都是不必要的。
测试中
实施大量机器学习算法的独特之处在于,即使在验证数据集上具有很高的指标,该算法在生产中的实际质量也可能很低。 因此,为了测试算法的操作,整个团队都在Slack中使用了该机器人。 这非常方便,因为团队的任何成员都可以检查算法对特定消息的响应。 该测试方法使您可以立即查看算法如何处理实时数据。
一个不错的选择是在Yandex Toloka和AWS Mechanical Turk等公共站点上启动该解决方案。
结论
我们研究了解决自动消息审核问题的几种方法,并描述了我们实现的功能。
工作期间获得的主要意见:
- 基于TF-IDF和逻辑回归的字典搜索和机器学习算法可以对消息进行快速分类,但并不总是正确。
- 神经网络算法和嵌入的预训练模型可以更好地应对此任务,并可以确定消息含义内的毒性。
当然,我们在
Facebook机器人上发布了开放的
Poteha Toxic Comment Detection演示。 帮助我们使机器人更好!
我很高兴在评论中回答问题。