
引言
现在该谈论异常或例外情况了。 在开始之前,让我们看一下定义。 有什么例外情况?
这种情况会使当前或后续代码的执行不正确。 我的意思是与设计或意图不同。 这种情况损害了应用程序或其部分(例如对象)的完整性。 它将应用程序置于异常或异常状态。
但是为什么我们需要定义这个术语呢? 因为它将使我们保持一定的界限。 如果我们不遵循术语,那么我们可能会偏离设计概念,而设计概念可能会导致很多歧义。 让我们看一些实际的例子:
struct Number { public static Number Parse(string source) { // ... if(!parsed) { throw new ParsingException(); } // ... } public static bool TryParse(string source, out Number result) { // .. return parsed; } }
这个例子似乎有些奇怪,这是有原因的。 我将这段代码做得有些虚假,以表明其中出现问题的重要性。 首先,让我们看一下Parse方法。 为什么要抛出异常?
- 因为它接受的参数是一个字符串,但其输出是一个数字,这是一个值类型。 该数字不能表示计算的有效性:它只是存在。 换句话说,该方法在其界面中没有传达潜在问题的手段。
- 另一方面,该方法需要包含一些数字且没有多余字符的正确字符串。 如果不包含该方法,则该方法的先决条件就会出现问题:调用我们方法的代码传递了错误的数据。
因此,此方法获取带有错误数据的字符串的情况非常特殊,因为该方法既不能返回正确的值,也不能返回任何值。 因此,唯一的方法是引发异常。
该方法的第二种变体可以表示输入数据存在一些问题:此处的返回值是boolean ,表示该方法已成功执行。 此方法不需要使用异常来表示任何问题:它们都由false返回值覆盖。
总览
异常处理看起来像ABC一样容易:我们只需要放置try-catch块并等待相应的事件。 但是,由于CLR和CoreCLR团队的巨大工作将来自各个方向和来源的所有错误统一到CLR中,因此这种简化变得可能。 为了理解接下来要讨论的内容,让我们看一下图:
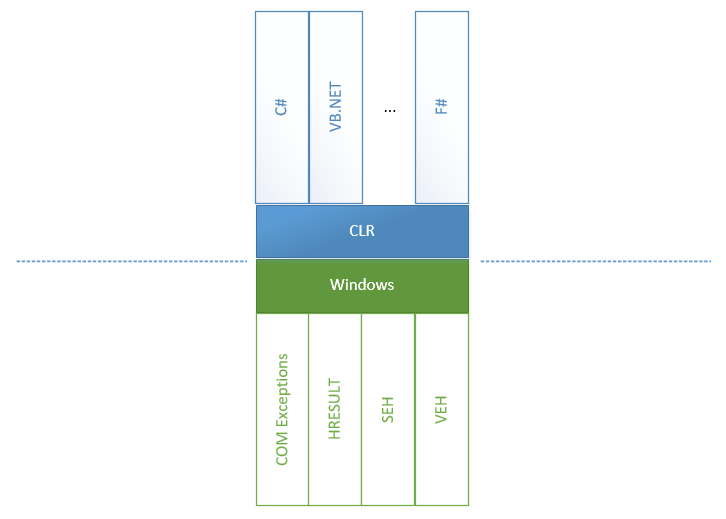
我们可以看到,在大型.NET Framework中,有两个世界:属于CLR的所有事物和不属于CLR的所有事物,包括Windows和不安全世界其他部分中出现的所有可能的错误。
- 结构化异常处理(SEH)是Windows处理异常的一种标准方式。 当调用
unsafe方法并引发异常时,在两个方向上都有不安全的<-> CLR异常转换:从不安全到CLR以及向后。 这是因为CLR可以调用不安全的方法,而该方法又可以依次调用CLR方法。 - 向量异常处理(VEH)是SEH的基础,它使您可以将处理程序放置在可能引发异常的地方。 特别是,它用于放置
FirstChanceException 。 - 当问题的根源是COM组件时,将出现COM +异常。 在这种情况下,COM和.NET方法之间的一层必须将COM错误转换为.NET异常。
- 当然,还有HRESULT的包装器。 引入它们是为了将WinAPI模型(返回值中包含错误代码,而返回值是使用方法参数获取)转换为异常模型,因为这是.NET的标准异常。
另一方面,CLI之上有一些语言,每种语言或多或少都具有处理异常的功能。 例如,最近VB.NET或F#具有更丰富的异常处理功能,该功能以许多C#中不存在的过滤器表示。
返回码与 例外
另外,我应该提到一个使用返回码处理应用程序错误的模型。 简单地返回错误的想法是显而易见的。 此外,如果我们将异常视为goto运算符,则返回码的使用将变得更加合理:在这种情况下,方法的用户将看到错误的可能性,并可以了解可能发生的错误。 但是,我们不要猜测什么是更好的,什么是什么,而要使用合理的理论来讨论选择问题。
假设所有方法都有接口来处理错误。 然后所有方法看起来像:
public bool TryParseInteger(string source, out int result); public DialogBoxResult OpenDialogBox(...); public WebServiceResult IWebService.GetClientsList(...); public class DialogBoxResult : ResultBase { ... } public class WebServiceResult : ResultBase { ... }
它们的用法如下所示:
public ShowClientsResult ShowClients(string group) { if(!TryParseInteger(group, out var clientsGroupId)) return new ShowClientsResult { Reason = ShowClientsResult.Reason.ParsingFailed }; var webResult = _service.GetClientsList(clientsGroupId); if(!webResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.ServiceFailed, WebServiceResult = webResult }; } var dialogResult = _dialogsService.OpenDialogBox(webResult.Result); if(!dialogResult.Successful) { return new ShowClientsResult { Reason = ShowClientsResult.Reason.DialogOpeningFailed, DialogServiceResult = dialogResult }; } return ShowClientsResult.Success(); }
您可能会认为此代码因错误处理而超载。 但是,我希望您重新考虑自己的立场:这里的所有内容都是对引发和处理异常的机制的仿真。
方法如何报告问题? 它可以通过使用用于报告错误的界面来做到这一点。 例如,在TryParseInteger方法中,此类接口由返回值表示:如果一切正常,该方法将返回true 。 如果不正常,它将返回false 。 但是,这里有一个缺点:实际值是通过out int result参数返回的。 缺点是,一方面返回值在逻辑上是合理的,并且根据感知,它的“返回值”本质比out参数更重要;另一方面,我们并不总是关心错误。解析来自生成该字符串的服务,我们不需要检查它是否存在错误:该字符串将始终是正确的并且很适合解析。但是,假设我们采用了该方法的另一种实现方式:
public int ParseInt(string source);
然后,有一个问题:如果字符串确实有错误,该方法应该做什么? 它应该返回零吗? 这是不正确的:字符串中没有零。 在这种情况下,我们存在利益冲突:第一个变量的代码太多,而第二个变量没有报告错误的方法。 但是,实际上很容易决定何时使用返回码以及何时使用异常。
如果遇到错误是正常现象,请选择返回码。 例如,当文本解析算法在文本中遇到错误时,这是正常现象,但是,如果使用解析字符串的另一种算法从解析器中获取错误,则这可能很关键,或者换句话说,是例外情况。
最后简单尝试
一个try块涵盖了程序员期望遇到的一种危急情况,该情况被外部代码视为规范。 换句话说,如果某些代码根据某些规则认为其内部状态不一致并引发异常,则对相同情况有更广泛了解的外部系统可以使用catch块捕获此异常并规范应用程序代码的执行。 。 因此, 您可以通过捕获异常使代码在此部分中合法化 。 我认为,这是一个重要的想法,可以禁止所有try-catch(Exception ex){ ...}异常,以防万一 。
这并不意味着捕捉例外与某些意识形态相矛盾。 我说您应该只捕获特定代码段中预期的错误。 例如,您不能指望从ArgumentException继承的所有类型的异常,也不能获取NullReferenceException ,因为通常这意味着问题出在代码中而不是被调用中。 但是可以期望您将无法打开预期的文件。 即使您200%确信可以,也请不要忘记检查。
finally一块也是众所周知的。 它适用于try-catch块涵盖的所有情况。 除少数几种特殊情况外,此块将始终有效。 为什么要引入这样的性能保证? 清理那些在try块中分配或捕获并且由该块负责的资源和对象组。
当我们不在乎哪个错误导致算法catch时,通常使用此块而没有catch块,但是我们需要清理为该算法分配的所有资源。 让我们看一个简单的示例:文件复制算法需要两个打开的文件和一个现金缓冲区的存储范围。 想象一下,我们分配了内存并打开了一个文件,但是无法打开另一个文件。 为了原子地将所有内容包装在一个“事务”中,我们将所有三个操作都放在一个try块中(作为实现的变体),并finally清除了资源,这似乎是一个简化的示例,但最重要的是展示其本质。
C#实际上缺少的是一个fault块,每当发生错误时,该fault块就会被激活。 就像finally在类固醇上一样。 如果有这个,我们可以例如创建一个入口点来记录特殊情况:
try { //... } fault exception { _logger.Warn(exception); }
在本简介中,我应该提到的另一件事是异常过滤器。 它不是.NET平台上的新功能,但C#开发人员可能是新手:异常过滤仅在v中出现。 6.0。 当单一类型的异常结合了多种类型的错误时,过滤器应将情况标准化。 当我们要处理特定的情况,但必须先捕获整个错误组,然后再过滤它们时,它应该对我们有帮助。 当然,我的意思是以下类型的代码:
try { //... } catch (ParserException exception) { switch(exception.ErrorCode) { case ErrorCode.MissingModifier: // ... break; case ErrorCode.MissingBracket: // ... break; default: throw; } }
好了,我们现在可以正确地重写以下代码:
try { //... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingModifier) { // ... } catch (ParserException exception) when (exception.ErrorCode == ErrorCode.MissingBracket) { // ... }
此处的改进并非缺少switch结构。 我相信这种新构造在以下几方面会更好:
- 使用
when进行过滤,我们可以准确地捕获我们想要的东西,并且在意识形态方面是正确的; - 代码以这种新形式变得更具可读性。 通过查看代码,我们的大脑可以在最初搜索
catch而不是switch-case更轻松地识别用于处理错误的块; - 最后但并非最不重要的一点:在进入catch块之前进行初步比较。 这意味着,如果我们对潜在情况做出了错误的猜测,那么在再次引发异常的情况下,此构造的工作将比
switch更快。
许多消息来源说,此代码的独特功能是在堆栈展开之前进行过滤。 在抛出异常的地方和进行过滤检查的地方之间没有其他调用(通常除外)的情况下,您会看到这种情况。
static void Main() { try { Foo(); } catch (Exception ex) when (Check(ex)) { ; } } static void Foo() { Boo(); } static void Boo() { throw new Exception("1"); } static bool Check(Exception ex) { return ex.Message == "1"; }
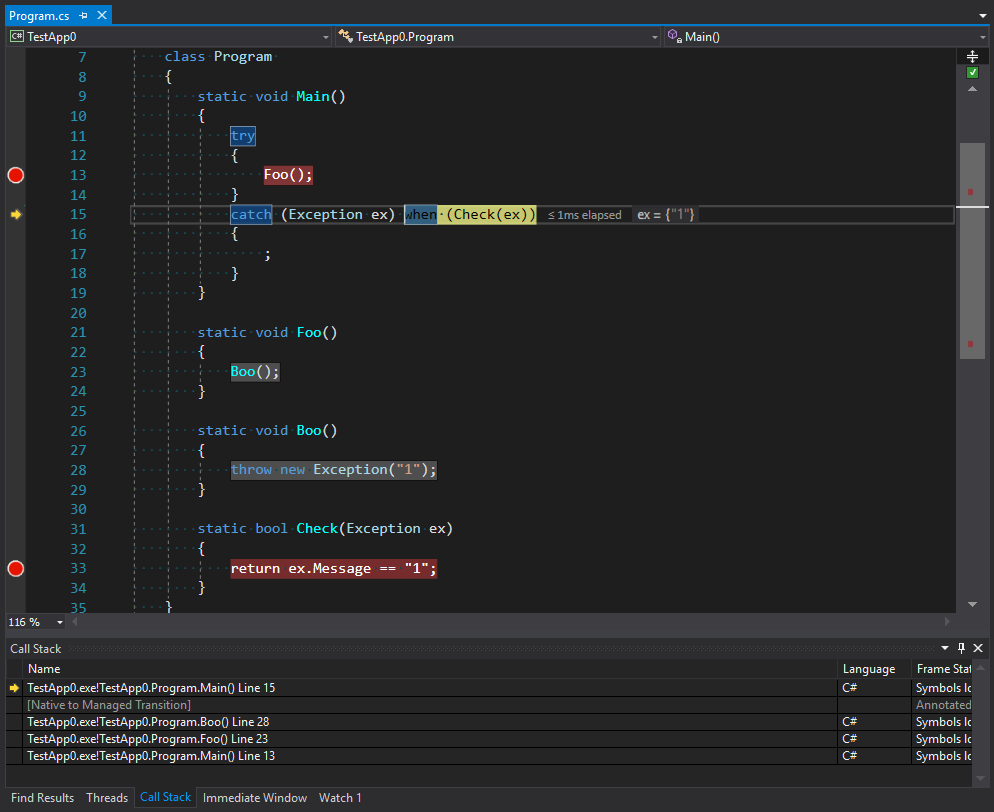
从图中可以看到,堆栈跟踪不仅包含Main的第一个调用作为捕获异常的点,而且还包含抛出异常之前的整个堆栈以及通过非托管代码进入Main的第二个堆栈。 我们可以假设该代码正是在过滤和选择最终处理程序阶段抛出异常的代码。 但是, 如果没有堆栈展开 , 并非所有调用都可以处理 。 我相信平台的过度统一会对它产生太大的信心。 例如,当一个域从另一域调用方法时,就代码而言绝对是透明的。 但是,方法调用的工作方式完全不同。 我们将在下一部分中讨论它们。
序列化
让我们从运行以下代码的结果开始(我添加了跨越两个应用程序域之间的边界的调用转移)。
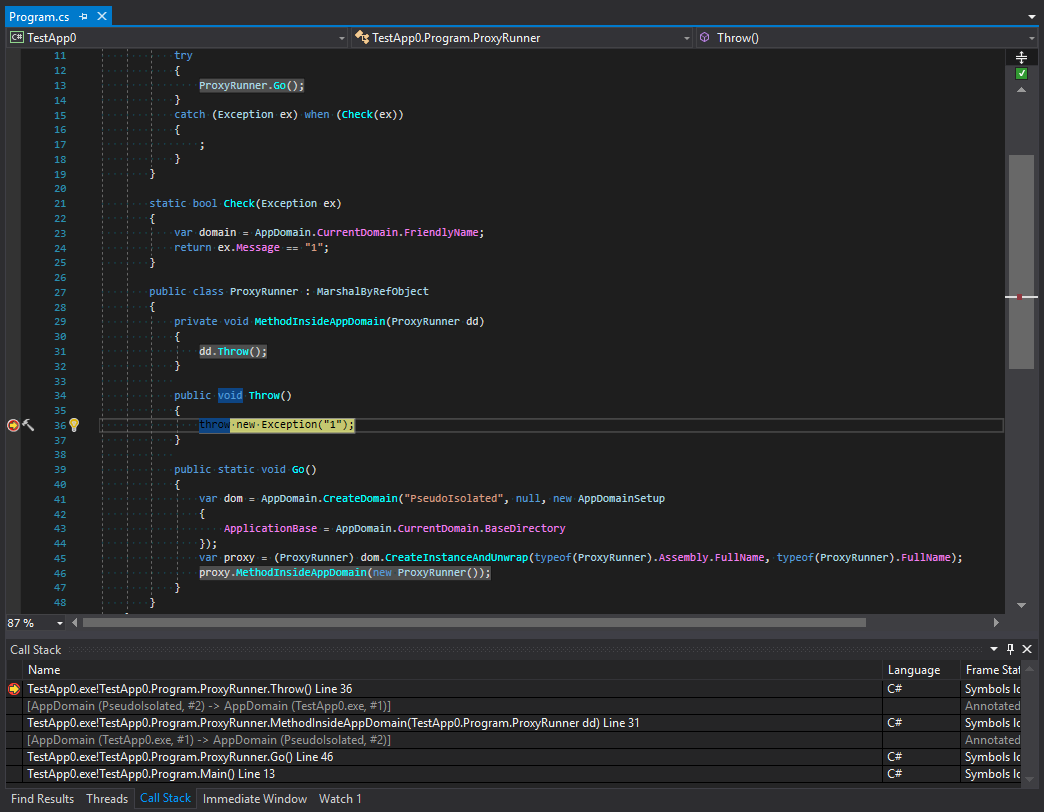
class Program { static void Main() { try { ProxyRunner.Go(); } catch (Exception ex) when (Check(ex)) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { throw new Exception("1"); } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner) dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } } }
我们可以看到堆栈展开在进行过滤之前发生。 让我们看一下屏幕截图。 第一个是在生成异常之前进行的:
第二个是:
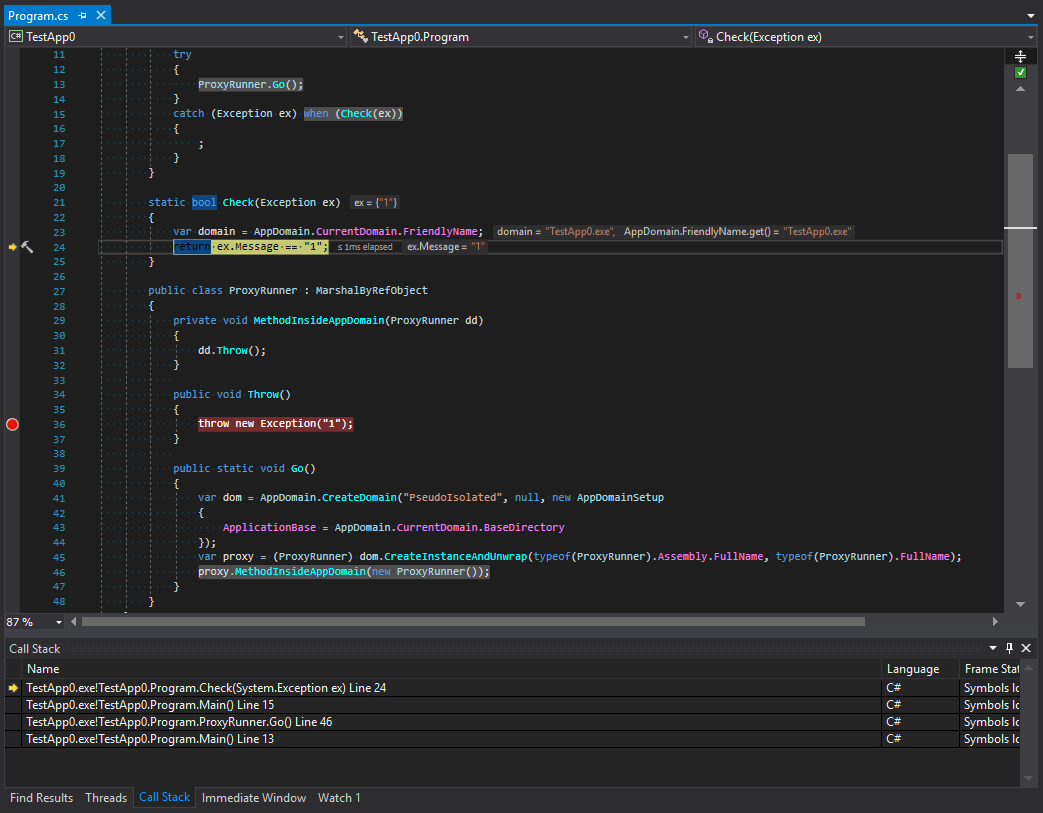
让我们研究过滤异常之前和之后的调用跟踪。 这里会发生什么? 我们可以看到,平台开发人员所做的事情乍一看就像是对子域的保护。 跟踪是在调用链中的最后一个方法之后进行的,然后转移到另一个域。 但是我认为这看起来很奇怪。 要了解为什么会发生这种情况,让我们记住组织域之间交互的类型的主要规则。 这些类型应该继承MarshalByRefObject并且可以序列化。 但是,尽管C#严格,但异常类型可以是任何性质。 什么意思 这意味着当子域内的异常可以在父域中捕获时,可能会发生这种情况。 此外,如果可能陷入异常情况的数据对象具有某些在安全性方面很危险的方法,则可以在父域中调用它们。 为避免这种情况,首先对异常进行序列化,然后它越过应用程序域之间的边界,并再次出现新的堆栈。 让我们检查一下这个理论:
[StructLayout(LayoutKind.Explicit)] class Cast { [FieldOffset(0)] public Exception Exception; [FieldOffset(0)] public object obj; } static void Main() { try { ProxyRunner.Go(); Console.ReadKey(); } catch (RuntimeWrappedException ex) when (ex.WrappedException is Program) { ; } } static bool Check(Exception ex) { var domain = AppDomain.CurrentDomain.FriendlyName; // -> TestApp.exe return ex.Message == "1"; } public class ProxyRunner : MarshalByRefObject { private void MethodInsideAppDomain() { var x = new Cast {obj = new Program()}; throw x.Exception; } public static void Go() { var dom = AppDomain.CreateDomain("PseudoIsolated", null, new AppDomainSetup { ApplicationBase = AppDomain.CurrentDomain.BaseDirectory }); var proxy = (ProxyRunner)dom.CreateInstanceAndUnwrap(typeof(ProxyRunner).Assembly.FullName, typeof(ProxyRunner).FullName); proxy.MethodInsideAppDomain(); } }
因为C#代码可能会抛出任何类型的异常(我不想用MSIL来折磨您),所以在此示例中我做了一个技巧,将类型转换为不可比拟的类型,因此我们可以抛出任何类型的异常,但是翻译器会认为我们使用Exception类型。 我们创建一个肯定不能序列化的Program类型的实例,并使用此类型作为工作负荷抛出异常。 好消息是,您获得了RuntimeWrappedException非Exception异常的包装器,该包装器将在其中存储我们的Program类型对象的实例,并且我们将能够捕获此异常。 但是,有一个坏消息支持我们的想法:调用proxy.MethodInsideAppDomain(); 将生成SerializationException :
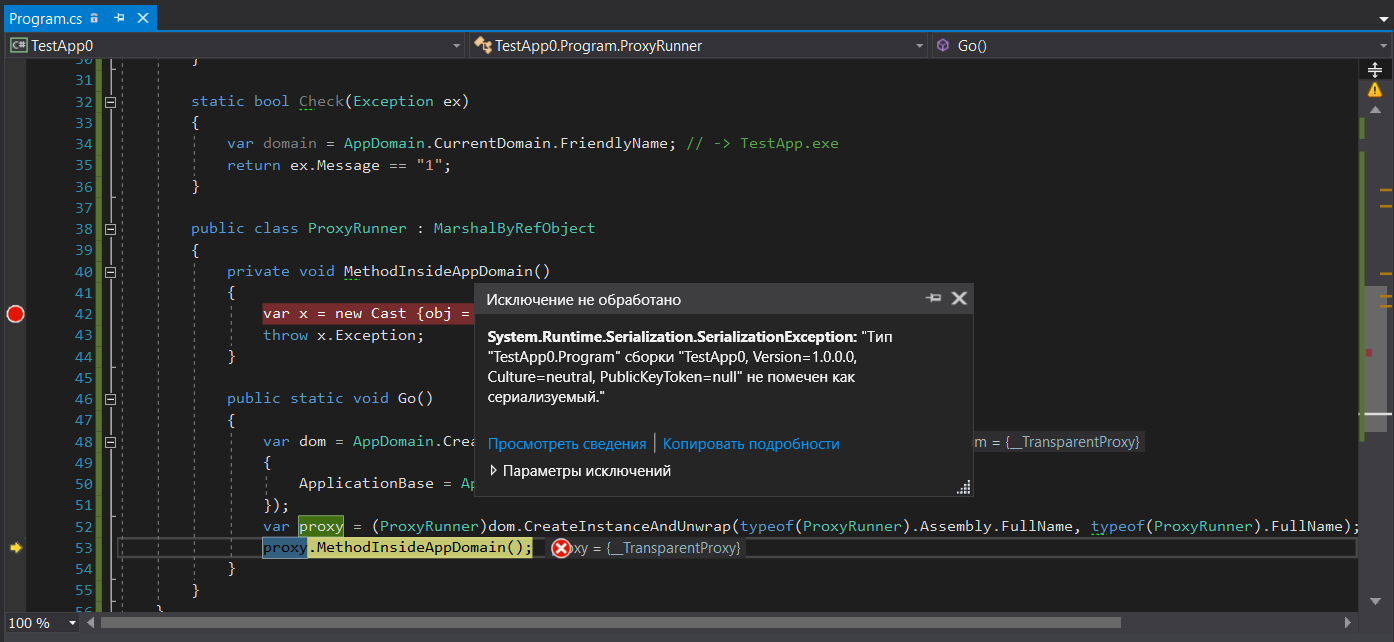
因此,您无法在域之间传输这样的异常,因为无法对其进行序列化。 反过来,这意味着尽管使用子域的FullTrust设置似乎不需要序列化,但是使用异常过滤器包装其他域中的方法调用仍会导致堆栈展开。
我们应该特别注意域之间进行序列化的必要性。 在我们的人工示例中,我们创建了一个没有任何设置的子域。 这意味着它以FullTrust方式工作。 CLR完全信任其内容,并且不会运行任何其他检查。 但是,当您插入至少一个安全设置时,完全信任将消失,CLR将开始控制子域内发生的所有事情。 因此,当您拥有完全受信任的域时,不需要序列化。 承认,我们不需要保护自己。 但是序列化的存在不仅是为了保护。 每个域第二次加载所有必需的程序集并创建其副本。 因此,它将创建所有类型和所有VMT的副本。 当然,当将一个对象从一个域传递到另一个域时,您将获得相同的对象。 但是它的VMT不会是它自己的,并且不能将此对象转换为其他类型。 换句话说,如果我们创建Boo类型的实例并将其放在另一个域中,则(Boo)boo将不起作用。 在这种情况下,序列化和反序列化将解决该问题,因为对象将同时存在于两个域中。 它将与创建时的所有数据一起存在,并作为代理对象存在于使用范围内,以确保调用原始对象的方法。
通过在域之间传输序列化的对象,您可以从一个域中的另一个域中获得对象的完整副本,同时在内存中保留一定的界限。 但是,这种划界是虚构的。 它仅用于Shared AppDomain中没有的那些类型。 因此,如果您抛出不可序列化的异常作为异常,但是从Shared AppDomain抛出,则不会出现序列化错误(我们可以尝试抛出Action而不是Program )。 但是,在这种情况下,无论如何都会发生堆栈展开:因为两种变体都应该以标准方式工作。 这样没人会感到困惑。
 本章由作者和专业翻译员共同译自俄语。 您可以帮助我们将俄语或英语翻译成任何其他语言,主要是中文或德语。
本章由作者和专业翻译员共同译自俄语。 您可以帮助我们将俄语或英语翻译成任何其他语言,主要是中文或德语。
另外,如果您想感谢我们,最好的方法是在github上给我们加星号或分支存储库  github / sidristij / dotnetbook
github / sidristij / dotnetbook