Stitch Fix团队的一篇文章建议在市场营销和产品A / B测试中使用非劣效性临床研究方法。 当我们测试具有无法通过测试衡量的优点的新解决方案时,此方法确实适用。
最简单的例子是骨丢失。 例如,我们使分配第一堂课的过程自动化,但是我们不想过多地放弃直通转化。 或者,我们测试着重于某一部分用户的更改,同时确保跨其他部分的转化不会产生太大影响(在测试多个假设时,请不要忘记进行更正)。
在效率设计方面选择正确的边界会在测试设计阶段增加额外的困难。 文章中如何选择Δ的问题并未得到很好的揭示。 在临床试验中,这种选择似乎并不完全透明。 一份关于非自卑性
的医学出版物
的评论指出,只有一半的出版物对边界的选择是合理的,而且这些理由常常是模棱两可的或不详尽的。
无论如何,这种方法似乎很有趣,因为 通过减少所需的样本数量,可以提高测试速度,从而提高决策速度。
-Skyeng移动应用程序的产品分析师Daria Mukhina。Stitch Fix团队喜欢测试不同的事物。 原则上,整个技术社区都喜欢进行测试。 网站的哪个版本吸引了更多用户-A或B? 推荐模型的版本A是否比版本B带来更多收益? 几乎总是为了检验假设,我们使用基本统计课程中最简单的方法:
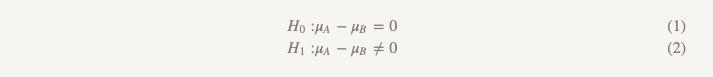
尽管我们很少使用该术语,但这种形式的测试称为“优势测试假设”。 使用这种方法,我们假设两个选项之间没有区别。 我们坚持这个想法,只有在获得的数据足以令人信服的情况下才拒绝这样做-也就是说,它们表明一个选择(A或B)优于另一个选择。
测试优势假设适合解决许多问题。 仅当推荐模型的B版本明显优于已使用的版本A时,我们才发布B版本。但是在某些情况下,此方法效果不佳。 让我们看几个例子。
1)我们使用有助于识别伪造银行卡
的第三方服务 。 我们发现另一项服务的成本大大降低。 如果一种便宜的服务能够像我们现在使用的那样运作良好,我们将选择它。 它不必比所使用的服务更好。
2)我们想要放弃数据源 A并用数据源B替换它。如果B产生的结果很差,我们可能会延迟放弃A,但是无法继续使用A。
3)我们不希望从方法 A
过渡到模型 A,而是因为期望B更好的结果,而是因为它给我们带来了极大的操作灵活性。 我们没有理由相信B会变得更糟,但是如果是这种情况,我们将不会开始过渡。
4)我们对网站的设计(版本B)
进行了一些定性更改 ,我们认为此版本优于版本A。我们不期望转换或更改通常用于评估网站的任何关键性能指标的更改。 但是,我们认为参数不可估量的优势,或者我们的技术不足以衡量。
在所有这些情况下,研究卓越并不是最佳的解决方案。 但是在这些情况下,大多数专家默认使用它。 我们认真进行了一项实验,以正确确定效果的大小。 如果确实版本A和版本B非常相似,则我们有可能无法拒绝原假设。 我们是否可以得出结论,A和B通常工作相同? 不行 无法拒绝原假设和采用原假设不是同一回事。
样本大小的计算(当然是您要执行的)通常是针对第一种错误(错误地拒绝原假设的概率,通常称为alpha),而不是第二种错误(无法拒绝原假设的概率)进行严格的边界计算。假设原假设是错误的,通常称为beta)。 alpha的典型值为0.05,而beta的典型值为0.20,它的统计功效为0.80。 这意味着我们无法检测出在功效计算中显示的值的真实影响,概率为20%,这是一个相当严重的信息缺口。 例如,让我们考虑以下假设:
 H0:我的背包不在房间里(3)
H0:我的背包不在房间里(3)
H1:我的背包在我的房间里(4)如果我搜索了房间并找到了背包,那很好,我可以拒绝原假设。 但是,如果我环顾四周,却找不到背包(图1),我应该得出什么结论? 我确定他不在吗? 我搜索是否足够彻底? 如果我只搜索80%的房间怎么办? 结论是背包绝对不在房间里,这将是一个轻率的决定。 毫不奇怪,我们不能“接受零假设”。
 我们搜寻的区域
我们搜寻的区域
我们没有找到一个背包-我们应该接受原假设吗?图1.搜索80%的房间与进行80%容量的研究大致相同。 如果您在检查了80%的房间后仍未找到背包,是否可以得出结论认为背包不在其中?那么,数据专家在这种情况下会做什么? 您可以大大提高研究能力,但是您需要大得多的样本,并且结果仍然不能令人满意。
幸运的是,此类问题已在临床研究领域中得到了长期的研究。 药物B比药物A便宜; 预计药物B的副作用要小于药物A; 药物B易于运输,因为它不需要存储在冰箱中,因此需要药物A。 我们检验了效率不低于这一假设。 有必要表明版本B与版本A一样好-至少在“不低于效率”Δ的某个预定限制内。 稍后,我们将更多地讨论如何设置此限制。 但是,现在假设这是在实际中有意义的最小差异(在临床试验中,通常称为临床相关性)。
效率低下的假设使一切都颠倒了:
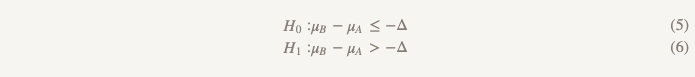
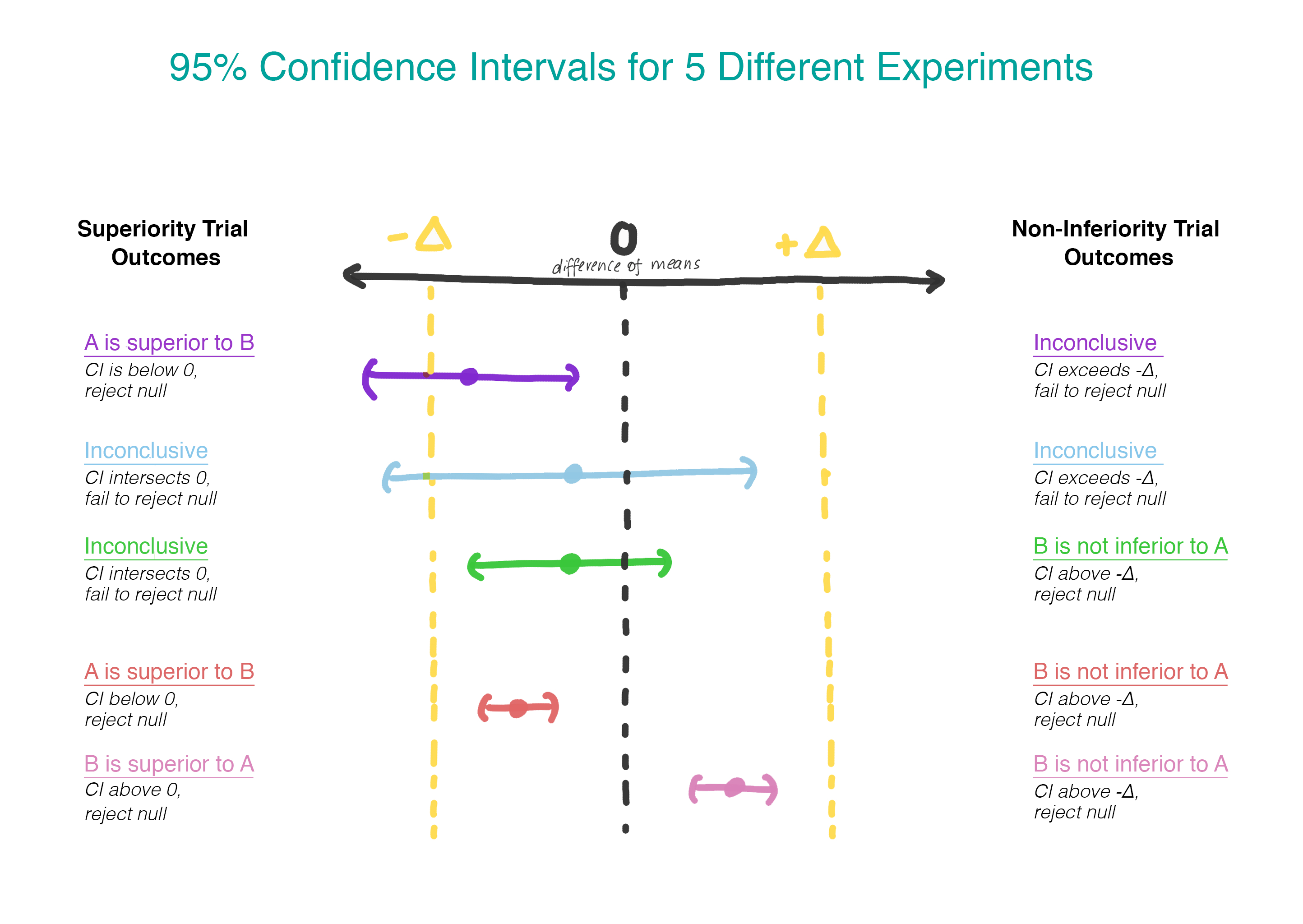
现在,我们假设版本B比版本A差,而不是假设没有区别,并且我们将坚持这个假设,直到证明事实并非如此。 这正是使用单方面假设的检验有意义的时刻! 实际上,这可以通过构造一个置信区间并确定该区间是否确实大于Δ来实现(图2)。
Δ选择
如何选择Δ? 选择过程Δ包括统计理由和对象评估。 在临床试验领域中存在一些规范性建议,从中可以得出结论,差异应该是最小的临床显着差异-在实践中将是相关的。 这是欧洲领导人的一句话,您可以进行自我检查:“如果正确选择了差异,则完全位于–∆到0 ...之间的置信区间仍足以证明效率不低。 如果这个结果似乎不可接受,则表明未正确选择∆。”
相对于真实控制(安慰剂/缺乏治疗),增量绝对不应超过版本A的效果,因为这使我们相信版本B比真实控制差,同时显示出“不少于效率”。 假设当引入版本A时,版本0已被替换或该功能根本不存在(请参见图3)。
根据检验优越性假设的结果,揭示了效应E的大小(即,μ^ A-μ^ 0 = E)。 现在,A是我们的新标准,我们要确保B不次于A。编写μB-μA≤-Δ(无效假设)的另一种方法是μB≤μA-Δ。 如果我们假设这样做等于或大于E,则μB≤μA-E≤安慰剂。 现在我们看到,我们对μB的估计完全超过μA-E,从而完全驳斥了原假设,并允许我们得出结论:B不逊于A,但同时μB可能≤μ安慰剂,但这不是我们需要什么。 (图3)。
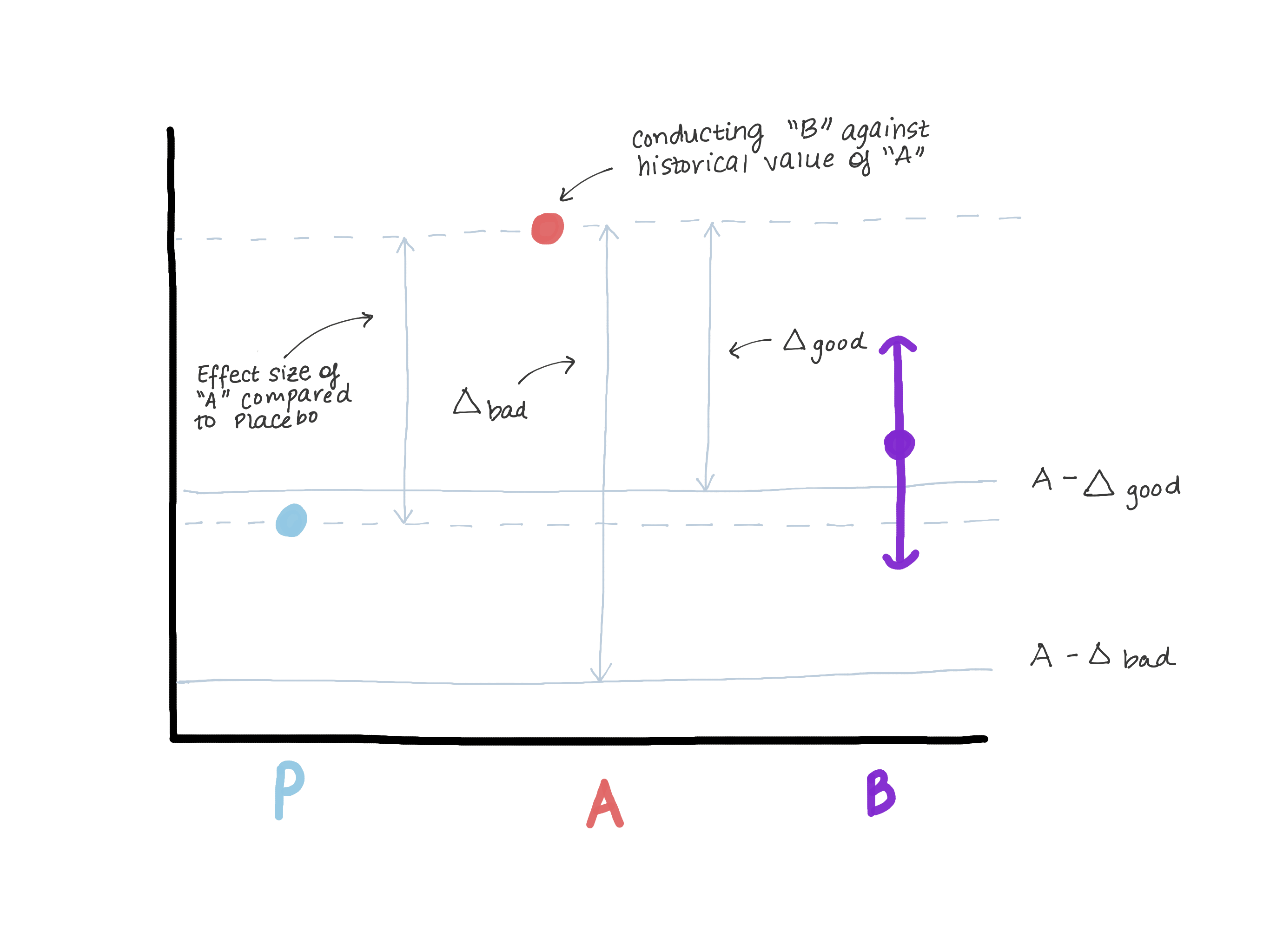 图3.演示选择效率不低于边界的风险。 如果该限制太大,我们可以得出结论,B不逊于A,但同时与安慰剂没有区别。 我们不会在与安慰剂具有相同效力的药物上改变明显比安慰剂(A)更有效的药物。
图3.演示选择效率不低于边界的风险。 如果该限制太大,我们可以得出结论,B不逊于A,但同时与安慰剂没有区别。 我们不会在与安慰剂具有相同效力的药物上改变明显比安慰剂(A)更有效的药物。选择α
我们转到α的选择。 您可以使用标准值α= 0.05,但这并不完全是诚实的。 例如,当您在Internet上购买某种商品并一次使用多个折扣代码时,尽管不应该对它们进行汇总,但开发人员只是犯了一个错误,而您却避免了。 根据规则,α的值应等于α的一半,该值用于检验优越性假设,即0.05 / 2 = 0.025。
样本量
如何估算样本量? 如果您认为A和B之间的真实平均差为0,则样本量的计算将与检验优越性假设时的计算相同,不同之处在于,您要用不小于效率的限制替换效应量,但前提是您必须至少使用a
效率= 1/2优势 (α非劣等= 1/2优势)。 如果您有理由相信选项B可能比选项A稍差,但是您想证明它的差值不超过Δ,那么您很幸运! 实际上,这可以减小样本的大小,因为如果您确实认为B比A差一些,则更容易证明B比A差。
解决方案示例
假设您要升级到版本B,前提是它在5点客户满意度量表上比版本A差不超过0.1点...我们将使用优越性假设来完成此任务。
为了检验优势假设,我们将按以下方式计算样本量:

也就是说,如果您的组中有2103个观测值,则可以90%的确定将发现0.10或更大的效果。 但是,如果0.10的值对您来说太大了,也许您不应该检验它的优越性假设。 也许出于可靠性考虑,您决定进行较小影响范围的研究,例如0.05。 在这种情况下,您将需要8407个观测值,也就是说,样本将增加近4倍。 但是,如果我们坚持原始样本大小,但将功效提高到0.99,这样我们就不会怀疑是否获得了阳性结果怎么办? 在这种情况下,一组的n将为3676,这更好,但样本量增加了50%以上。 结果,我们都无法反驳原假设,也无法得到我们问题的答案。
相反,如果我们检验了有效性不减的假设怎么办?
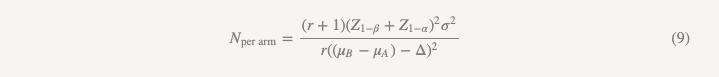
除分母外,将使用相同的公式计算样本数量。
与用于检验优越性假设的公式的差异如下:
-Z1 −α/ 2被Z1 −α代替,但是如果您按照规则进行所有操作,则将α= 0.05替换为α= 0.025,即,这是相同的数字(1.96)
-分母出现(μB-μA)
-θ(效果的幅度)由Δ(效率的极限)代替
如果我们假设µB = µA,那么(µB-µA)= 0并计算不小于效率极限的样本大小,正是我们在计算0.1效果值的优越性时所得到的! 我们可以使用不同的假设和不同的结论方法来进行相同规模的研究,而我们将得到我们真正想要回答的问题的答案。
现在假设我们并不真正认为µB = µA且
我们认为µB稍差一些,可能为0.01个单位。 这增加了我们的分母,将每组的样本量减少到1737。
如果B版本实际上比A版本好,会发生什么? 我们驳斥了B比A差Δ的原假设,并接受了B的另一种假设,如果更糟,则B不比Δ差,并且可能更好。 尝试将这个结论放在跨功能的演示文稿中,然后看看结果如何(认真尝试)。 在需要着眼于未来的情况下,没有人愿意同意“更差Δ并可能更好”。
在这种情况下,我们可以进行一项研究,简称为“测试以下假设:一个选项优于另一个选项或劣于该选项”。 它使用两组假设:
第一组(与检验效率不低于这一假设时相同):
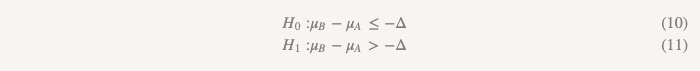
第二组(与检验优越性假设时相同):

仅当第一个假设被拒绝时,我们才检验第二个假设。 在顺序测试中,我们保持第一类错误的总体水平(α)。 实际上,这可以通过为均值之间的差异创建95%的置信区间并检查以确定整个区间是否超过-Δ来实现。 如果间隔不超过-Δ,则无法拒绝零值并停止。 如果整个间隔确实超过-Δ,我们继续查看间隔是否包含0。
我们还没有讨论另一种类型的研究-等价研究。
这种类型的研究可以用研究来检验有效性不减的假设,反之亦然,但是实际上它们有重要的区别。 检验效率不低于假设的测试旨在证明选项B至少与A一样好。等效研究旨在证明选项B至少与A一样好,并且选项A和B一样好,这更复杂。 本质上,我们试图确定整个置信区间是否在于-Δ和Δ之间的均值差。 此类研究需要更大的样本量,且频率较低。 因此,下次您进行一项主要任务是确保新版本不会更差的研究时,请不要接受“无法反驳原假设”的要求。 如果要检验一个非常重要的假设,请考虑各种选择。