大家好 我在Tinkoff的团队正在构建推荐系统。 如果您对每月的现金返还感到满意,那么这就是我们的业务。 我们还建立了合作伙伴特别优惠的推荐系统,并在Tinkoff应用程序中收集了个人故事集。 而且,我们喜欢参加机器学习竞赛,以保持自己的健康状态。
从2月18日到4月18日,为期两个月的竞赛在Boosters.pro上进行,目的是基于来自俄罗斯最大的在线电影院Okko的真实数据构建推荐系统。 组织者旨在改善现有的推荐系统。 目前,竞赛以沙盒模式进行,您可以在其中测试您的方法并磨练构建推荐系统的技能。
资料说明
可通过电视或智能手机上的应用程序或通过Web界面来访问Okko中的内容。 内容可以租用,购买(P)或按订阅查看(S)。 比赛的组织者提供了N天(N> 60)的观看数据,此外,还提供了有关评分和添加的书签的信息。 值得牢记的一个重要细节是,如果用户多次观看一部电影或该系列的几集,那么平板电脑中只会记录最后一次交易的日期和每单位内容花费的总时间。
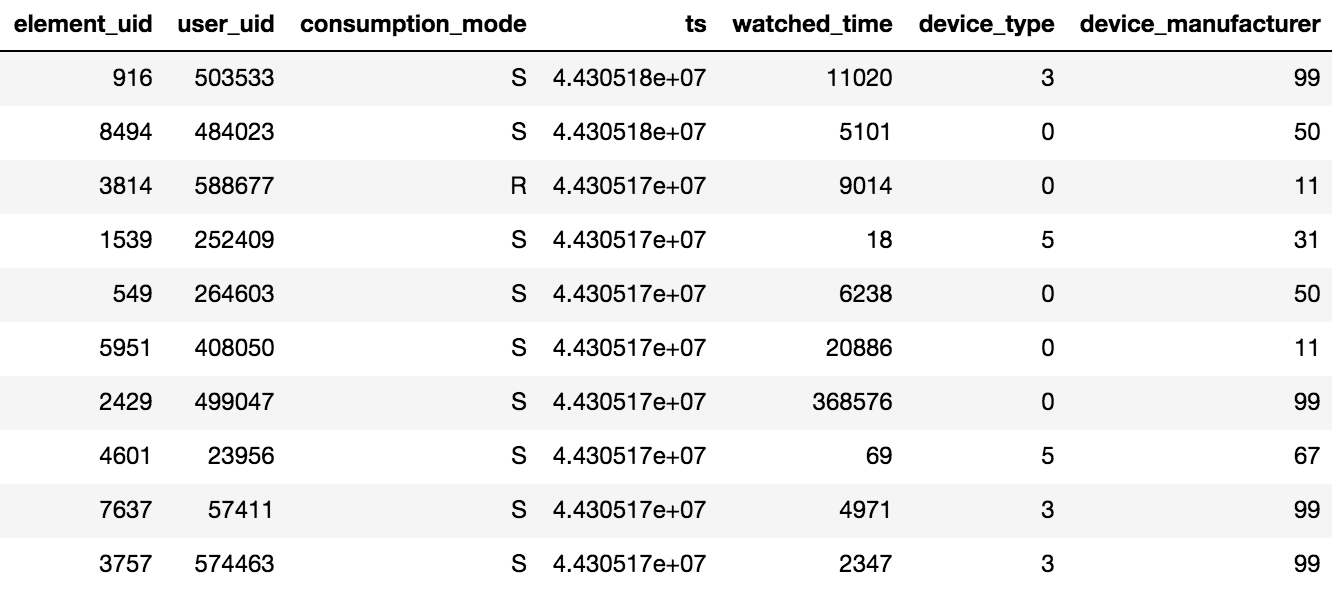
为50万用户提供了约1000万笔交易,45万个评级和95万个书签事实。
该样本不仅包含活跃用户,还包含在整个时期内观看了几部电影的用户。
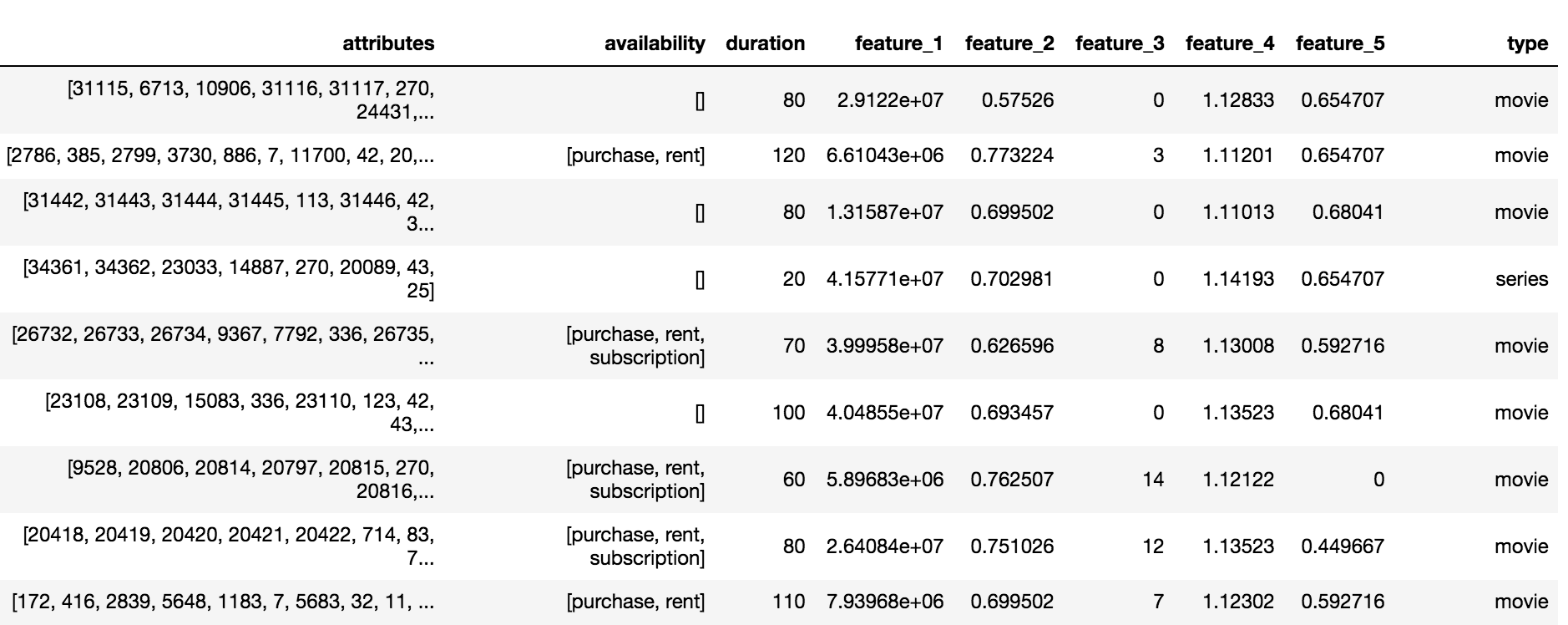
Okko目录包含三种类型的内容:电影(电影),系列(系列)和系列电影(multipart_movie),总共10,200个对象。 对于每个对象,都有一组匿名属性和属性(feature_1,...,feature_5),订阅,出租或购买的可用性和持续时间。
目标变量和指标
该任务需要预测用户在未来60天内将要使用的大量内容。 据信,如果用户:
- 买或租
- 通过订阅观看电影的一半以上
- 订阅观看该系列节目的三分之一以上
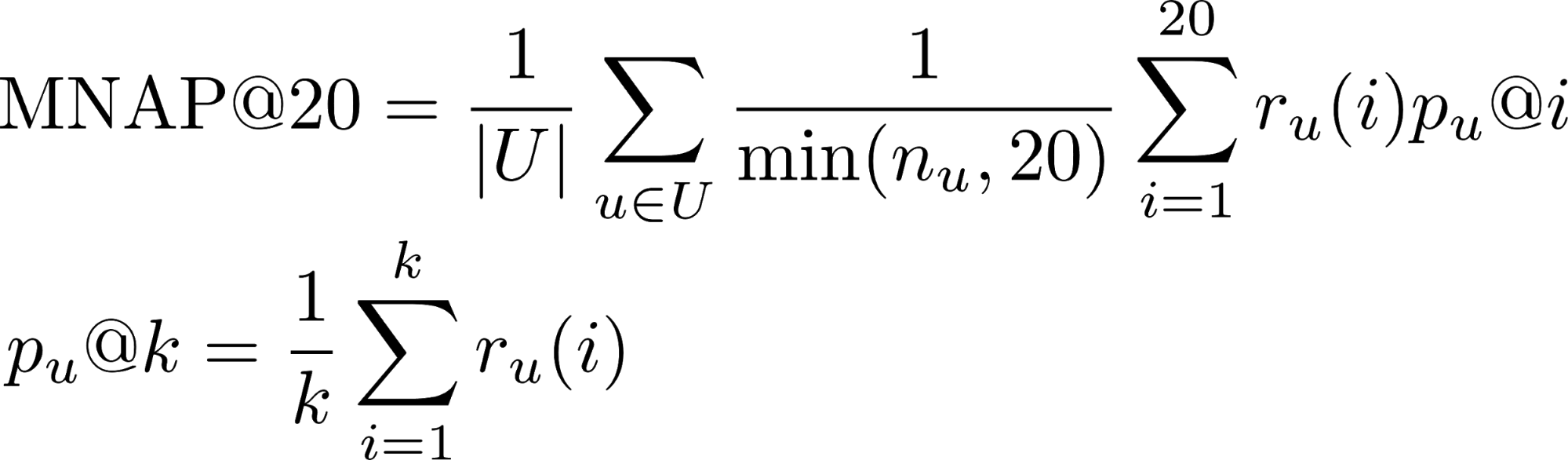
- r_u(i) -用户u是否在位置i(1或0)处消费了对其预测的内容
- n_u-用户在测试期间消耗的元素数
- U-许多测试用户
您可以从这篇文章中了解有关排名任务的指标的更多信息 。
大多数用户都看完电影为止,因此,积极类别的交易份额为65%。 使用来自所提供样本的5万名用户的子集评估了算法的质量。
综合评分
竞争决定始于将所有用户与内容的互动汇总到一个评分等级中。 假定如果用户购买了内容,则意味着最大的兴趣。 电影比系列短,因此,要从整体上观看该系列,您需要给出更多分数。 结果,根据以下规则形成了总评级:
- 电影份额* 5
- 电视节目分享* 10
- [给电影添加书签] * 0.5
- [为系列添加书签] * 1.5
- [内容的购买/租赁] * 15
- 评分+ 2
一级模型
组织者提供了基于Tf-IDF量表的协作过滤的基本解决方案。 将所有类型的互动添加到汇总评分中,将最近邻居的数量从20增加到150,并用BM25权重替换Tf-IDF,从而在LB(排行榜)上淘汰了约0.03 。
受在2018年RecSys挑战赛中获得第三名的团队的启发,我选择了WARP损失的LightFM模型作为第二基本模型。 带有选定超参数的LightFM(学习率,no_components,item_alpha,user_alpha,max_sampled)在LB上给出0.033 。

模型的验证是按时进行的:互动的前80%落入了火车,其余的20%进入了验证。 对于LB提交,使用选择用于验证的参数对整个数据集训练模型。
模型融合
在上一阶段,事实证明建立了两个强有力的基准,此外,他们的建议平均相交了建议内容的60%。 如果有两个强相关且同时弱相关的模型,则将它们融合是一个合理的步骤。
在这种情况下,模型得分属于不同的分布并且具有不同的等级,因此决定使用等级的总和来组合两个模型。 模型混合在LB上产生0.0347 。

二级模型
推荐系统通常使用两级方法来构建模型:首先,通过简单的第一级模型选择排名靠前的候选人,然后通过添加大量功能的更复杂的模型对排名靠前的候选人进行排名。

数据集在时间上分为训练和验证部分。 为每个用户的验证部分收集了一系列建议,其中包括结合顶级200预测的第一级模型和已观看电影的预测。 此外,还需要教导模型为每个用户重新排列最终的顶部。 该问题是根据二进制分类提出的。 仅当用户在验证期间消费了内容时,对(用户,内容)才属于肯定类别。 作为第二级模型,使用了梯度增强,即LightGBM软件包。
迹象
配对(用户,内容)的第一级模型以速度的形式评估相关性,并按降序排序以获得排名。 对模型进行了等级和速度标志训练,再加上内容目录中的标志,在LB上剔除了0.0359 。
从第一个匿名特征的发行形式可以得出结论,这是电影在目录中出现的日期,因此,使用选定的验证方案对该模型进行了严格的重新训练。 从样品中去除特征会导致LB增加至0.0367
除了为用户预测内容的相关性之外,LightFM模型还返回两个向量:项目偏好和用户偏好,这两个向量分别与内容的受欢迎程度和用户观看的电影数量相关。 添加符号将LB的速度提高到0.0388 。
您可以在删除已观看的电影之前或之后为一对(用户,内容)分配等级。 方法的改变后者使LB增加到0.0395 。
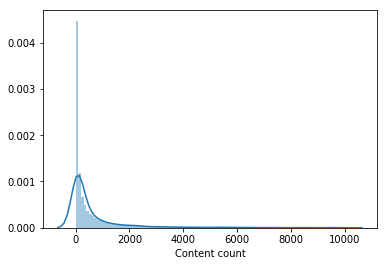
几乎没有人看过电影目录中的很大一部分。 从样本中删除了少于100个用户观看的内容,以训练第二级模型,这使目录减少了一半。 移除不受欢迎的内容使得从第一级模型中进行选择更加相关,并且只有在此之后,LightFM的用户向量才提高了验证速度,并将LB增加到0.0429 。
此外,添加了一个标志-用户将书签添加到了书中,但没有查看火车时间段,这将LB的速度提高到0.0447 。 另外,添加了有关第一次和最后一次交易的日期的标志,它们使LB的速度提高到0.0457 。

我们将最终考虑该模型。 最重要的是来自第一级模型的标志和来自内容目录的匿名标志。
以下功能并未增加到最终模型中:
- 书签数量+书签中已查看内容的份额-0.0453磅
- 购买的胶片数量0.0451磅
但是当与最终模型融合时,他们在LB上淘汰了0.0465 。 受融合结果的启发,以下模型分别进行了训练:
- 在第一级模型中使用不同比例的训练样本。 90%/ 10%的分配增加了,而95%/ 5%和70%/ 30%的分配却有所增加。
- 使用改良的评分汇总方法。
- 在第二级模型的训练集中增加了不受欢迎的电影。 对于每个内容单元,共编译了1000个用户。
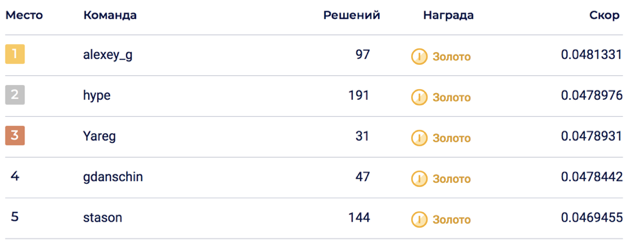
6个模型的最终融合使LB达到0.0469678 ,对应第5位。

在私密部分,发生了一场大变革,将解决方案推到了第二位。 我认为,由于大量模型的融合,该解决方案证明是可持续的。
未输入
在解决比赛的过程中,产生了许多似乎肯定会进入的迹象,但可惜。 最值得信赖的标志和方法:
- 匿名内容属性。 不确定其中包含的内容,但是比赛中的所有参与者都认为它们包含有关演员,导演,作曲家的信息。在我的决定中,我尝试将它们添加为几种格式:最受欢迎的二进制字符,列出了内容矩阵使用LightFM和BigARTM设置属性,然后拉出向量并将其添加到第二级模型。
- 二级模型中LigthFM模型的内容向量。
- 用户从中查看内容的设备的属性。
- 降低二级模型流行内容的权重。
- 电影/电视节目相对于已观看内容总数的比例。
- 来自CatBoost的排名指标。
有关比赛的有趣事实
- 事实证明,Top1解决方案比Okko产品型号0.048和0.062差。 应该记住的是,产品模型在采样时已经启动。
- 比赛开始大约一周后,数据集发生了变化,对于那些从一开始就参加比赛的人,他们添加了30份参赛作品,但在两支球队合并后却被意外烧毁。
- 验证并不总是与LB相关,这表明可能会发生变化。
决策代码
该解决方案以两个jupyter-laptop的形式在github上可用:评级聚合,第一和第二级的训练模型。
第三名的解决方案也可以在github上找到 。
组织者的决定
我附上了组织者的主要特点,而不是一千个字。
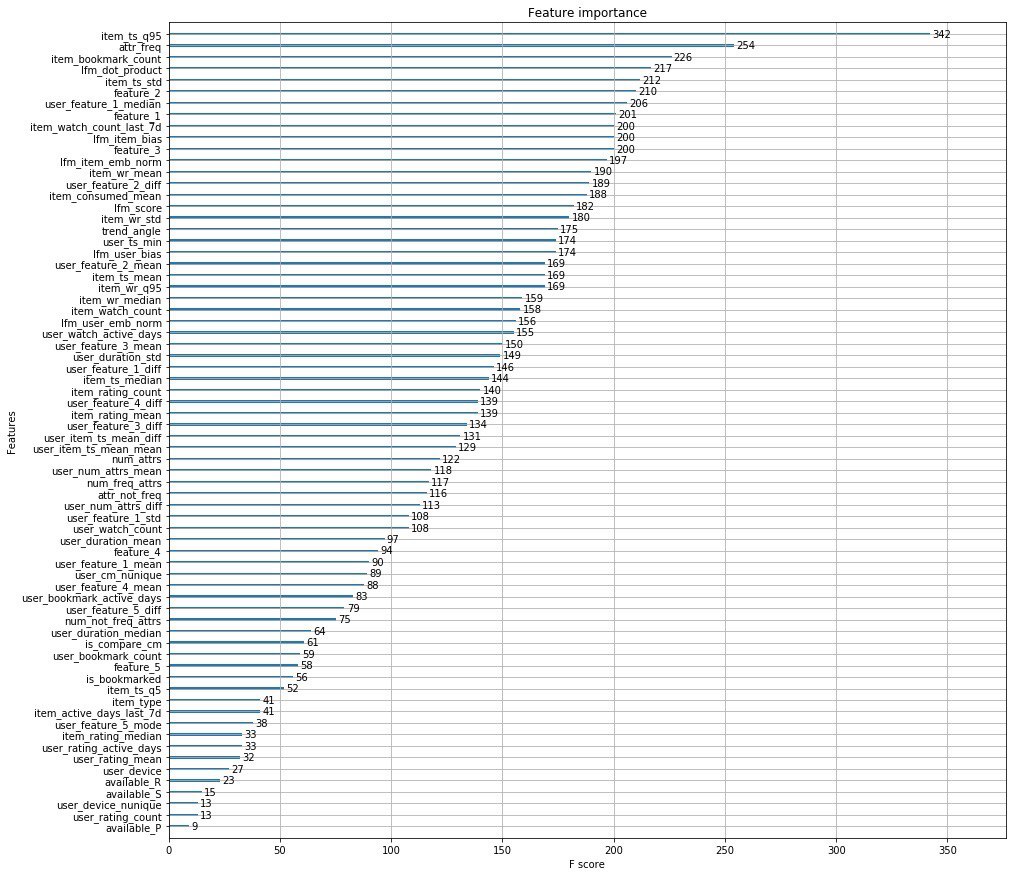
此外,来自Okko的家伙发表了一篇文章 ,讨论了推荐引擎的开发阶段。
在这里的 PS中,您可以在Data Fest 6上看到有关此问题解决方案的性能。