可以在
此链接上找到完整的俄语课程。
此链接提供原始英语课程。
 每2-3天安排一次新的讲座。
每2-3天安排一次新的讲座。塞巴斯蒂安访谈
-因此,我们将再次与塞巴斯蒂安一起参加本课程的第三部分。 塞巴斯蒂安,我知道您已经使用卷积神经网络进行了大量开发。 您能否告诉我们更多有关这些网络的信息,它们是什么? 我相信我们课程的学生会以同样的兴趣倾听,因为在这一部分,他们将不得不自己开发卷积神经网络。
-太好了! 因此,卷积神经网络是在网络中进行结构构建,建立所谓的不变性(不变特征的分配)的一种好方法。 例如,假设在舞台或照片上有模式识别的想法,您想了解是否在其上描绘了塞巴斯蒂安。 我位于照片的哪个部分,头部位于哪里都无所谓-在照片的中心还是在角落。 识别我的头,无论脸在图像中的位置如何,脸都应该出现。 这是不变性,位置可变性,这是通过卷积神经网络实现的。
-非常有趣! 您能告诉我们使用卷积神经网络的主要任务吗?
-在处理音频和视频(包括医学图像)时,相当紧密地使用了卷积神经网络。 它们还用于语言技术中,其中专家使用深度学习来理解和复制语言构造。 实际上,这项技术有很多应用,我什至会说它们是无止境的! 她的技术可以用于金融和其他领域。
“我使用了卷积神经网络来分析卫星图像。”
-太好了! 标准任务!
-您如何看待,我们能否将卷积神经网络视为深度学习发展中最后也是最先进的工具?
-哈! 我已经学会了永不言败。 永远会有新奇的东西!
“所以我们还有工作要做?” :)
-将会有足够的工作!
-太好了! 在本课程中,我们只是在教导未来的机器学习先驱。 在我们的学生开始构建第一个卷积神经网络之前,您对他们有什么希望吗?
-这是一个有趣的事实。 卷积神经网络是在1989年发明的,这是很久以前的事了! 你们中的大多数人甚至还没有出生,这意味着重要的不是算法的天才,而是算法所依据的数据。 我们生活在一个有大量数据可以分析和搜索模式的世界中。 我们有能力使用大量数据来模拟人脑的功能。 当您使用卷积神经网络时,请尝试着重于找到正确的数据并应用它们-查看发生了什么,有时甚至可以证明是真正的魔力,就像我们解决皮肤癌检测问题时的情况一样。
-太好了! 好吧,让我们终于开始魔术吧!
引言
在上一课中,我们学习了如何开发深度神经网络,该网络能够从Fashion MNIST数据集中对服装元素的图像进行分类。

我们在神经网络上工作时获得的结果令人印象深刻-88%的分类精度。 这是几行代码(不考虑图形和图像构造代码)!
model = tf.keras.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28, 1)), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
NUM_EXAMPLES = 60000 train_dataset = train_dataset.repeat().shuffle(NUM_EXAMPLES).batch(32) test_dataset = test_dataset.batch(32)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/32))
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/32)) print(': ', test_accuracy)
: 0.8782
我们还试验了隐藏层中神经元数量和训练迭代次数对模型准确性的影响。 但是,我们如何使该模型更好,更准确? 实现此目的的一种方法是使用卷积神经网络,简称SNA。 与我们在先前课程中遇到的标准全连接神经网络相比,SNA在解决图像分类问题方面显示出更高的准确性。 正是由于这个原因,SNA如此流行,并且由于他们,机器视觉领域的技术突破才成为可能。
在本课程中,我们将学习使用TensorFlow和Keras从头开始开发SNA分类器有多么容易。 我们将使用与上一课相同的Fashion MNIST数据集。 在本课程的最后,我们将前一神经网络的服装元素分类与本课程中的卷积神经网络的准确性进行比较。
在深入研究开发之前,有必要深入了解卷积神经网络的工作原理。
卷积神经网络中的两个基本概念:
让我们仔细看看它们。
卷积
在本课的这一部分中,我们将学习一种称为卷积的技术。 让我们看看它是如何工作的。
以灰色阴影拍摄图像,例如,假设其尺寸为高6像素,宽6像素。

我们的计算机将图像解释为二维像素阵列。 由于我们的图像是灰色阴影,因此每个像素的值将在0到255之间。0-黑色,255-白色。
在下面的图像中,我们看到6px x 6px图像的表示形式以及相应的像素值:
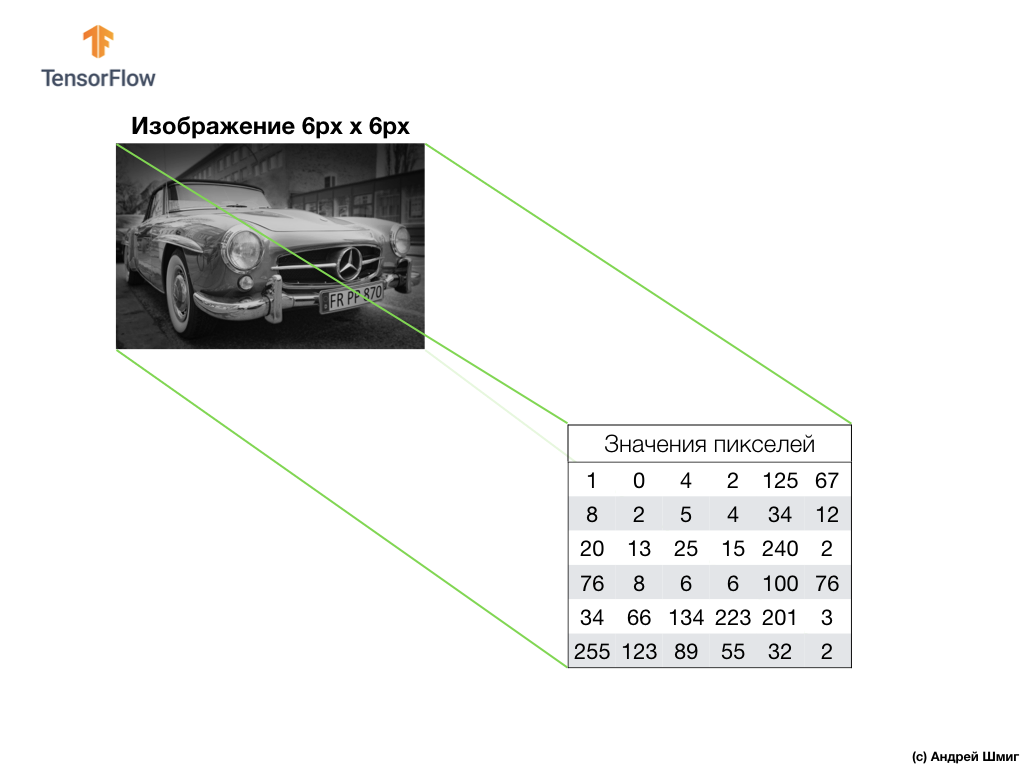
如您所知,在处理图像之前,您需要规范化像素值-将这些值设置为介于0到1之间的间隔。但是,在此示例中,为了便于说明,我们将保存图像的像素值并且不对其进行规范化。
卷积的本质是创建另一组值,称为内核或过滤器。 在下图中可以看到一个示例-3 x 3矩阵:

然后,我们可以使用内核扫描图像。 我们图像的尺寸为6x6px,核心为3x3px。 卷积层应用于输入图像的核心和每个部分。
假设我们要对一个值为25(3行3列)的像素进行卷积,而要做的第一件事就是将核心置于该像素的中心:

在图像中,核心位置以黄色突出显示。 现在,我们将仅查看黄色矩形中的像素值,这些像素值的大小与卷积核的大小相对应。
现在,我们获取图像和内核的像素值,将图像的每个像素与内核的相应像素相乘,然后将所有乘积值相加,然后将结果像素值分配给新图像。

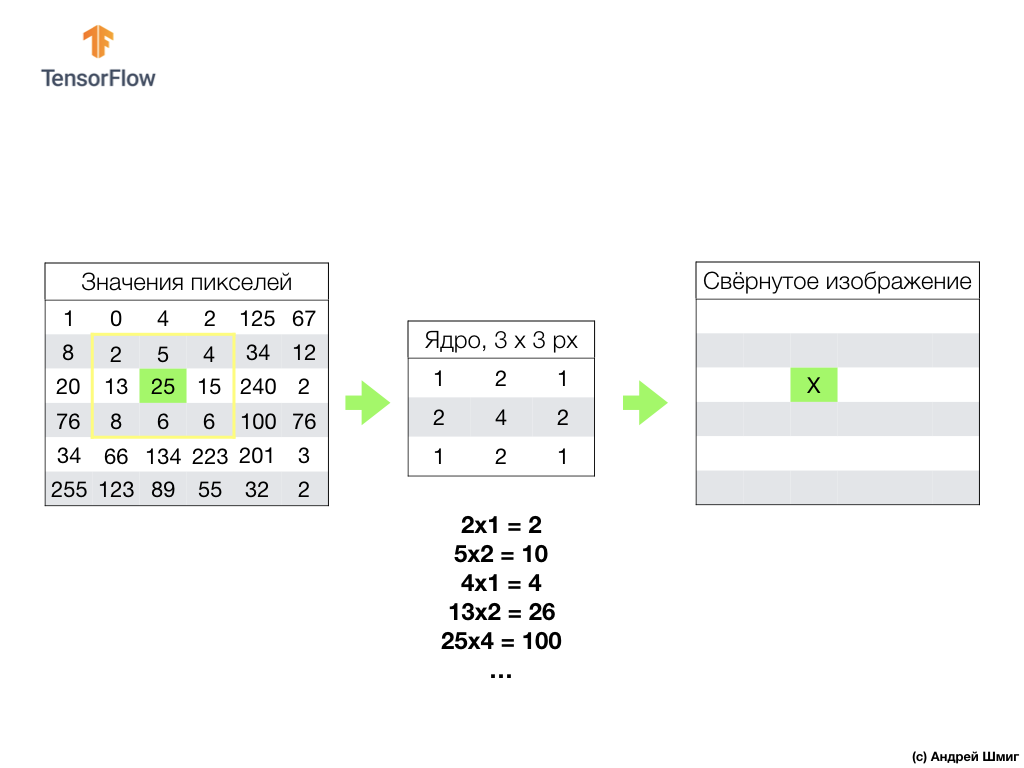

我们对图像中的所有像素执行类似的操作。 但是边界处的像素会发生什么?
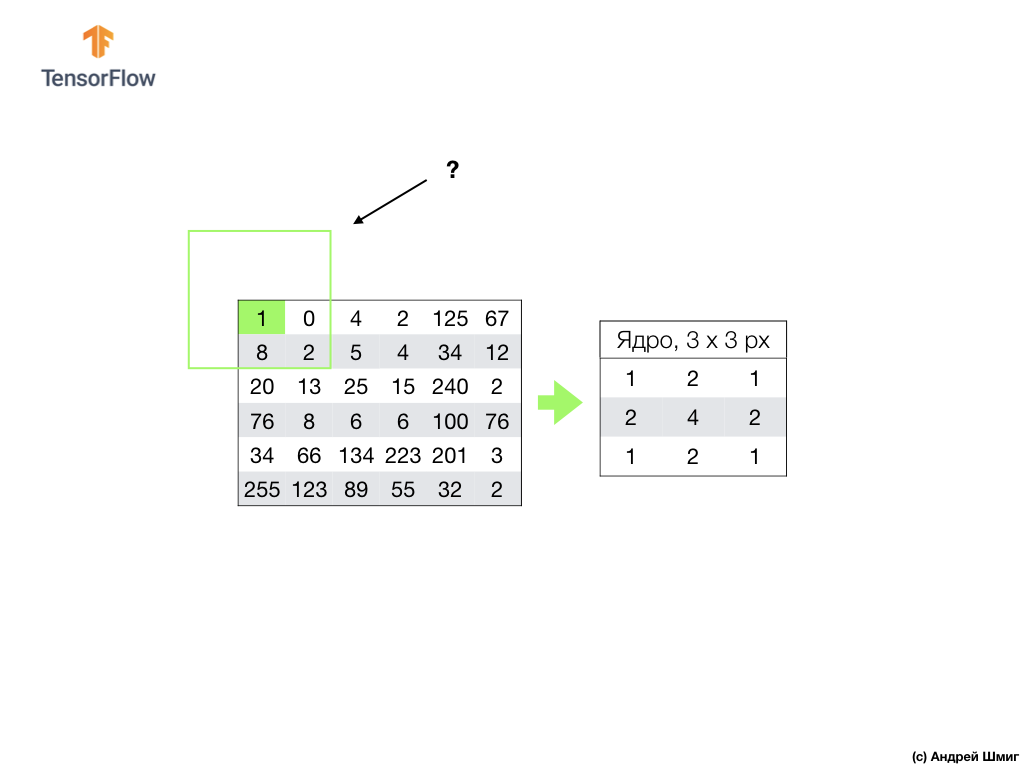
有几种解决方案。 首先,我们可以简单地忽略这些像素,但是在这种情况下,我们将丢失有关图像的信息,这可能变得很重要,并且最小化后的图像将变得比原始图像小。 其次,我们可以简单地用零值“杀死”那些核心值超出图像范围的像素。 该过程称为对齐。

现在我们已经使用零像素值进行了对齐,我们可以像以前一样计算最小化图像中最终像素的值。
卷积是将核心(滤波器)应用于输入图像的每个部分的过程,类似于完全连接的层(密集层),我们将看到卷积在Keras中是同一层。
现在让我们看一下卷积神经网络的第二个概念-二次采样的操作(池化,最大池化)。
二次采样操作(池化,最大池化)
现在,我们将考虑卷积神经网络背后的第二个基本概念-子采样(合并,最大合并)的操作。 简而言之,二次采样操作是通过添加像素块的值来压缩(缩小)图像的过程。 让我们看一下如何在一个具体示例上工作。

要执行二次采样操作,我们需要确定此过程的两个组成部分-样本大小(矩形网格的大小)和步长。 在此示例中,我们将使用3x3矩形网格和第3步。该步骤确定执行子采样操作时应移动矩形网格的像素数。
在确定了网格大小和步长之后,我们需要找到落入所选网格的最大像素值。 在上面的示例中,值1、0、4、8、2、5、20、13、25落入网格中,最大值为25。该值被“传输”到新图像。 将网格向右移动3个像素,并重复选择最大值并将其传输到新图像的过程。

结果,与原始输入图像相比,将获得较小的图像。 在我们的示例中,获得的图像是原始图像大小的一半。 最终图像的大小将根据矩形网格的大小和步长的选择而变化。
让我们看看这将如何在Python中工作!
总结
我们熟悉了卷积和最大池运算等概念。
卷积是对图像应用滤镜(“核心”)的过程。 通过最大值进行二次采样的操作是通过将一组像素组合为来自该组的单个最大值来减小图像尺寸的过程。
正如我们将在实际部分中看到的那样,可以使用
Conv2D中的
Conv2D层将卷积层添加到神经网络。 该层类似于密集层,并包含经过优化(选择)的权重和偏移量。
Conv2D层还包含过滤器(“内核”),其值也已优化。 因此,在
Conv2D层中,过滤器矩阵内的值是经过优化的变量。
我们设法遇到的一些术语:
- SNS-卷积神经网络。 包含至少一个卷积层的神经网络。 典型的SNA包含其他层,例如样本层和完全连接的层。
- 卷积是对图像应用滤镜(“核心”)的过程。
- 过滤器(核心)是一个矩阵,其大小小于输入数据,旨在用于按块转换输入数据。
- 对齐是向图像边缘添加(通常为零)值的过程。
- 二次采样操作是通过采样减小图像尺寸的过程。 有几种类型的子采样层,例如,平均的子采样层(对平均值进行采样),但是,最常使用最大值的子采样。
- 通过最大值进行二次采样是二次采样过程,在此过程中,许多值都转换为单个值-采样中的最大值。
- 步骤 -图像中滤镜(核心)的位移像素数。
- 采样(下采样) -缩小图像尺寸的过程。
CoLab:使用卷积神经网络对Fashion MNIST服装元素进行分类
我们盘绕在手指上! 仅在完成
前一部分之后才执行此实际部分,这是有意义的-除一个块外,所有代码均保持不变。 我们的神经网络的结构正在发生变化,这是卷积神经层和子样本层处于最大值(最大池)的另外四行。
model = tf.keras.Sequential([ tf.keras.layers.Conv2D(32, (3,3), padding='same', activation=tf.nn.relu, input_shape=(28, 28, 1)), tf.keras.layers.MaxPooling2D((2, 2), strides=2), tf.keras.layers.Conv2D(64, (3,3), padding='same', activation=tf.nn.relu), tf.keras.layers.MaxPooling2D((2, 2), strides=2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ])
关于工作方式的所有详细说明,他们承诺在下一部分给我们-4部分。
哦是的 该模型在训练阶段的准确度等于97%(该模型在
epochs=10时“重新训练”),并且遍历测试数据集时,它的准确度为91%。 相对于以前的架构,我们仅使用完全连接的层-88%,其准确性显着提高。
总结
在本部分课程中,我们研究了一种新型的神经网络-卷积神经网络。 我们熟悉诸如“卷积”和“最大池操作”之类的术语,从零开始开发和训练了卷积神经网络。 结果,我们看到卷积神经网络比上一课开发的神经网络具有更高的准确性。
PS翻译作者的注释。
该课程称为“使用TensorFlow进行深度学习入门”,因此我们不会抱怨缺乏对卷积神经网络(层)原理的详细解释-接下来的两篇文章将介绍卷积神经网络的原理及其内部结构(文章与本课程无关,但StackOverflow参与者推荐使用这些文章,以更好地了解正在发生的事情)。
...和标准号召性用语-注册,加号并分享:)
YouTube的电报VKontakte