
自2018年8月发布以来,Julia通过进入Github上的前10种语言和根据Upwork进入的前20种 最受欢迎的专业技能 ,一直在积极获得欢迎。 对于初学者, 课程开始并出版书籍 。 朱莉娅(Julia)用于太空任务计划 , 药理学和气候建模 。
在开始使用Julia进行分布式计算之前,让我们转向那些已经尝试过使用新的PL解决应用问题的机会的人,这些经历包括从两个核上的扩散方程到超级计算机上的天文图。
并行计算及影响并行计算性能的因素
大多数现代计算机都具有一个以上的处理器,并且可以将多台计算机组合为一个群集。 利用多个处理器的功能,您可以更快地执行许多计算。 性能受两个主要因素影响:处理器本身的速度和其内存访问的速度。 在群集中,此CPU将以最快的速度访问同一计算机或主机上的RAM。 更加令人惊讶的是,由于主内存和缓存速度的差异,此类问题在典型的多核笔记本电脑上还是很重要的。 因此,良好的多处理器环境应允许您控制特定处理器对部分内存的使用。
Julia中的并行计算
Julia在每个级别都有几个用于并行计算的内置原语:矢量化(SIMD),多线程和分布式计算。
Julia自己的多线程功能允许用户使用多核笔记本电脑的功能,而远程调用和远程访问原语则允许您在集群中的许多进程之间分配工作。 除了这些内置原语之外,Julia生态系统中的许多软件包还提供了有效的并行处理。
Julia中的自动向量化
现代英特尔芯片提供了许多命令集扩展。 其中包括各种版本的Streaming SIMD扩展(SSE)和几代矢量扩展(在最新的处理器系列中可用)。 这些扩展以单指令多数据(SIMD)的方式提供编程,从而极大地加速了代码,使其更适合于这种编程风格。 LLia强大的Julia编译器可以自动为任何体系结构上的基本功能和用户定义功能生成高效的机器代码,例如SIMD硬件 (由LLVM支持),这使用户不必担心为每种体系结构编写专用代码。 使用编译器而不是在程序集中手动编码“热循环”来提高性能的另一个优点是,它对将来有明显的改善。 每当下一代指令集体系结构出现时,Julia自定义代码都会自动变得更快。
多线程
Julia中的多线程通常采用并行循环的形式。 还有一些用于锁和原子的原语,允许用户同步其代码。 朱莉娅的平行原语很简单,但功能强大。 结果表明,它们可以扩展到数千个节点并处理TB级的数据 。
分布式计算
尽管Julia的内置原语足以用于大规模并行部署,但仍有许多软件包可用于更专业的工作。 ClusterManagers.jl为许多通常在计算集群中使用的作业排队系统提供接口,例如Sun Grid Engine和Slurm 。 DistributedArrays.jl为跨集群分布的数据阵列提供了一个方便的接口。 这样可以合并多台计算机的内存资源,从而可以使用太大而无法容纳在一台计算机上的阵列。 每个进程都在其拥有的阵列部分上运行,从而为如何在计算机之间分配程序这一问题提供了现成的答案。
在某些旧版应用程序中,用户不希望重新考虑其并行模型,而是希望继续使用MPI风格的并发。 对于他们, MPI.jl提供了围绕MPI的精简包装,允许用户使用MPI样式的消息传递过程。
朱莉娅在战斗中
Celeste项目是Julia Computing,英特尔实验室,JuliaLabs @ MIT,劳伦斯·伯克利国家实验室和加利福尼亚大学伯克利分校之间的合作。
Celeste是一个完全生成的分层模型,它使用统计推断来数学确定天空中光源的位置和特征。 该模型使天文学家能够确定有前途的星系以瞄准光谱仪,并有助于理解暗能量,暗物质和宇宙几何的作用。

斯隆数字天空调查(SDSS)的示例
Celeste研究团队使用Julia自身的并行计算功能,在短短15分钟内处理了55 TB的视觉数据,并对1.88亿个天文物体进行了分类,从而得出了Sloan Digital Sky Survey中所有可见物体的第一个完整目录。 这是人类有史以来最大的数学优化问题之一。

Celeste项目在NERSC Cori II超级计算机上使用了9,300个Knights Landing (KNL)节点,以在650,000个KNL内核上执行130万个线程,这些应用程序的组合速度超过每秒1 petaflops ,这使Julia成为唯一的动态对象一种曾经取得过如此成就的高级语言。 ?? 但是,望远镜的同步和对10.04.19上的黑洞图像的数据处理是否打破了该记录? 似乎在那里最常使用Python。
使用MPI与Julia并行编程
来自克劳迪奥等离子体物理学博客的材料翻译2018-09-30
Julia自2012年以来一直存在,经过6年多的发展,终于发布了1.0版。 这是一个重要的阶段,启发了我创建一个新职位(经过几个月的沉默)。 这次,我们将看到如何通过Open MPI开源库使用消息传递接口(MPI)范例在Julia中进行并行编程。 我们将通过解决一个实际的物理问题来做到这一点:热量通过二维区域扩散。

图1. LLNL中的红杉超级计算机,具有近160万个处理器,可用于核武器的数值模拟。 hpc.llnl.gov
这将是一个相当先进的MPI应用程序,面向已经对并行计算有所了解的人。 因此,我不会一步一步走,而是专注于我认为感兴趣的特定方面(特别是虚影单元的使用和二维网格中消息的传输)。 按照他最近的帖子的传统,此处讨论的代码将仅部分布局。 这是一个功能全面的解决方案,您可以在Github- Diffusion.jl上找到它。
在过去的几年中,并行计算已进入“商业世界”。 这是ETL(提取-转换-加载)应用程序的标准解决方案,其中所考虑的问题令人尴尬地并行:每个过程都独立于所有其他过程执行,并且不需要网络连接(直到最后的“还原”步骤发生,每个本地解决方案都组装在其中)全局解决方案)。
在许多科学应用中,有必要通过集群网络传输信息。 这些“挤压平行”问题通常是数值模拟:天体物理学,天气模型,生物学,量子系统等问题。 在某些情况下,这些模拟是在数十个甚至数百万个处理器上执行的(图1),并且内存分布在不同的处理器之间。 通常,这些处理器通过消息传递接口(MPI)范例在超级计算机中进行交互。
从事高性能计算的任何人都应该熟悉MPI。 它允许在非常低的级别使用群集体系结构。 从理论上讲,研究人员可以为每个CPU分配自己的计算负载。 他/她可以准确地确定何时以及在处理器之间传输什么信息,以及该信息应同步发生还是异步发生。
现在让我们回到这篇文章的内容,在这里我们将看到如何使用MPI为扩散类型方程编写解决方案。 我们已经讨论了这种一维方程的显式方案( 顺便说一下,我们也对此进行了讨论 )。 但是,在本文中,我们将考虑一个二维解决方案。
这里显示的Julia代码本质上是Fabien Durnak在那篇精彩文章中解释的C / Fortran代码的翻译。
在本文中,我将不详细分析扩展速度和处理器数量。 主要是因为我只有两个处理器可以在家玩(MacBook Pro上有Intel Core i7处理器)……但是,我仍然可以自豪地说,本文中的Julia代码,当使用两个处理器对一个处理器时,显示出明显的加速。 无论如何: 它比等效的Fortran和C代码快! (稍后会详细介绍)
以下是我们将在本文中介绍的主题:
- 朱莉娅:我的第一印象
- 如何在计算机上安装Open MPI
- 问题:通过二维域传播
- 处理器间通信:需要鬼单元
- 使用MPI
- 解决方案可视化
- 性能表现
- 结论
1.朱莉娅的第一印象
实际上,我最近遇到了朱莉娅(Julia),所以我决定在这里重点关注几个“第一印象”。
我对Julia感兴趣的主要原因是,她承诺将成为性能与C和Fortran相当的通用框架,同时保留Matlab或Python之类的脚本语言的灵活性和易用性。 实际上,Julia应该能够编写在本地计算机,云或公司超级计算机上运行的数据科学 / 高性能计算应用程序。
我不喜欢的一个方面是工作流,对于像我这样每天使用IntelliJ和PyCharm的人来说,这似乎不是最佳选择(IntelliJ Julia插件太糟糕了)。 我还尝试了Juno IDE ,这可能是目前最好的解决方案,但我仍然需要适应它。
证明Julia尚未达到其“成熟度”的一个方面是许多软件包的文档有多么多样和过时( 对于已浮动的软件包,自去年以来已铲除了一切 )。 我仍然没有找到一种将格式化的浮点数矩阵写入磁盘的方法( 现在很容易找到 )。 当然,您可以在double-for循环中将矩阵的每个元素写入磁盘,但是应该有更好的解决方案。 只是很难找到此信息,并且文档必须是全面的。
首次使用Julia的另一个方面是选择使用数组索引。 尽管从实用的角度来看,这让我感到有些烦恼,但是由于它不是Julia独有的,因此它肯定不会破坏协议(Matlab和Fortran也使用从一个开始的索引)。
现在,到最重要的方面:朱莉娅真的可以很快。 我为这篇文章编写的Julia代码比同等的Fortran和C代码更好地工作感到印象深刻,即使我基本上只是将其翻译为Julia。 如果您有兴趣,请查看效果部分。
2.安装Open MPI
Open MPI是一个开源消息传递接口库。 其他知名的库包括MPICH和MVAPICH。 MVAPICH由俄亥俄州立大学开发,是目前最先进的库,因为它还可以支持GPU群集-这对于深度学习应用程序特别有用(实际上,NVIDIA与MVAPICH团队之间有着密切的合作)。
所有这些库都建立在一个公共接口上:MPI API。 因此,使用一个或另一个库都没关系:您编写的代码可能保持不变。
Github上的MPI.jl项目是MPI的包装。 在后台,它使用C和Fortran MPI安装。 尽管缺少某些其他语言提供的功能,但它的效果很好。
要在Julia上运行MPI,您将需要在计算机上单独安装Open MPI。 如果您使用Mac,我会发现本指南非常有用。 需要特别注意的是,由于Open MPI需要Fortran和C编译器,因此您还需要安装gcc (GNU编译器),我安装了Open MPI 3.1.1的版本,该版本也由我的终端上的mpiexec --version确认。
在计算机上安装Open MPI之后,应该安装cmake 。 同样,如果您使用的是Mac,则就像在终端上键入brew install cmake一样容易。
目前,您已经准备好在Julia中安装MPI软件包。 打开Julia REPL并using Pkg Pkg.add («MPI»)键入。 通常,此时您应该能够使用MPI导入包。 但是,我还必须通过Pkg.build («MPI»)来构建程序包。
3.问题:二维扩散方程
扩散方程是抛物线偏微分方程的一个示例。 他描述了诸如热扩散或浓度扩散的现象(菲克第二定律)。 在两个空间维度上,扩散方程写为
解决方案 展示了温度/浓度在空间和时间上如何变化(取决于我们研究热量的分布还是物质的扩散)。 实际上,变量x和y表示空间坐标,而时间分量由变量t表示。 数量D是“扩散系数”,它确定例如热量将在物理区域中传播的速度。 类似于先前博客中讨论的内容(更详细),可以使用解决方案的“显式方案”离散上式。 我将不讨论您可以在博客上找到的详细信息,仅以以下形式编写数值解决方案:
其中i和k沿着空间网格(时间j运行k索引。 从初始条件开始填充第一时间层,随后的每个时间层都填充 使用上一层的值计算得出。 在图中,红色节点表示该层的节点 计算该点的值所需要的

方程(1)实际上是在每个后续时间步长上找到整个区域的解决方案所需的全部。 实现在CPU上通过一个进程按顺序执行此操作的代码非常简单。 但是,这里我们要讨论使用多个过程的并行实现。
每个过程将负责在整个空间域的一部分中找到解决方案。 诸如热扩散之类的问题并不是分布式计算的明确候选对象,它们需要在过程之间交换信息。 为了澄清这一点,让我们看一下图片
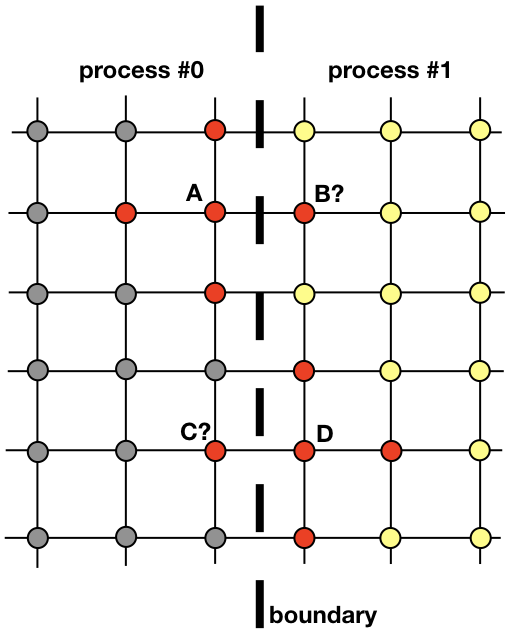
两个相邻进程必须进行交互才能在边界附近找到解决方案。 进程0必须知道B中的解的值才能计算出网格点A的解。类似地,进程1必须知道点C的值才能计算出网格点D的解。这些值对于进程是未知的,直到进程0和1之间存在联系为止。 。
它显示了过程0和1如何需要相互作用才能评估边界附近的解决方案。 这是MPI进入现场的地方。 在下一节中,我们将探讨一种有效的消息传递方式。
4.进程之间的通信:鬼单元
计算流体动力学中的一个重要概念是幻影单元的概念。 每当将空间域分解为几个子域(每个子域由一个过程解决)时,此概念就很有用。
要了解什么是鬼单元格,让我们再次看一下上图中的两个相邻区域。 流程0负责在左侧找到解决方案,而流程1则在空间域的右侧找到解决方案。 但是,由于模板的形状(图2)靠近边界,因此两个过程都必须彼此交换数据。 这就是问题所在:进程0和进程1每次需要来自相邻进程的节点时,通信效率都非常低:这将导致无法接受的通信成本。
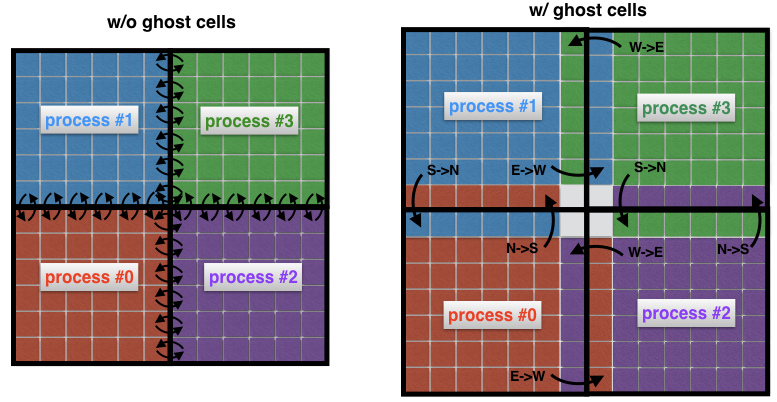
图4没有(左)和有(右)幻像元的过程之间的连接。 如果没有中间单元,则子域边界上的每个单元都必须将其自身的消息传输到相邻进程。 使用重影单元可以使传输的消息数量最小化,因为属于进程边界的许多单元一次只交换一条消息。 例如,此处的流程0将整个北部边界转移到流程1,而整个东部边界转移到流程2。
取而代之的是,通常的做法是将“真实”子域与称为“伪单元”的其他单元围绕起来,如图4(右)所示。 这些鬼单元是相邻子域边界处解决方案的副本。 在每个时间步长,每个子域的旧边界都传递给邻居。 这使您可以在子域的边界处计算新的解决方案,从而大大减少了通信开销。 最终效果是代码加速。
5.使用MPI
有许多MPI教程。 在这里,我只想描述用于解决二维扩散问题的Julia的MPI.jl shell语言中表示的命令。 这些是几乎每个MPI实现中都使用的一些基本命令。
MPI命令MPI.init () -初始化运行时
MPI.COMM_WORLD代表通信器,即,可通过MPI应用程序使用的所有进程(每个消息必须与通信器关联)
MPI.Comm_rank (MPI. COMM_WORLD) -定义流程的内部等级(id)
MPI.Barrier (MPI.COMM_WORLD) -阻止执行,直到所有进程都达到此过程
MPI.Bcast! (Buf, n_buf, rank_root, MPI.COMM_WORLD) MPI.Bcast! (Buf, n_buf, rank_root, MPI.COMM_WORLD) -从具有rank_root的进程到通信器MPI.COMM_WORLD的所有其他进程的广播消息缓冲区buf,大小为n_buf
MPI.Waitall! (reqs) MPI.Waitall! (reqs) -等待所有MPI请求的完成(该请求是用于异步消息传输的描述符,换句话说,是一个链接)
MPI.REQUEST_NULL指示该请求与任何正在进行的连接都不相关
MPI.Gather (buf, rank_root, MPI.COMM_WORLD) -将buf变量简化为获取rank_root的过程
MPI.Isend (buf, rank_dest, tag, MPI.COMM_WORL D) -将buf消息从当前进程异步发送到rank_dest进程,并使用参数标记该消息
MPI.Irecv! (Buf, rank_src, tag, MPI.COMM_WORLD) MPI.Irecv! (Buf, rank_src, tag, MPI.COMM_WORLD) -从原始rank_src排名进程到本地buf缓冲区接收带有标签标签的消息
MPI.Finalize () -终止MPI运行时
5.1查找过程邻居
对于我们的任务,我们将把二维区域分解为许多矩形子域,如下图所示。

图5.分为12个子域的二维区域的笛卡尔分解。 请注意,MPI等级(进程标识符)从零开始。
请注意, x和y轴相对于正常使用是反转的,以将x轴与行关联,而y轴与解决方案矩阵的列关联。
要在不同进程之间进行通信,每个进程必须了解其邻居。 有一个非常方便的MPI命令可以自动执行此操作,称为MPI_Cart_create 。 不幸的是,Julia MPI shell不包含此高级命令(添加它似乎并不简单),因此我决定创建一个执行相同任务的函数。 为了使其更紧凑,我经常使用三元运算符 。 您可以在下面找到此功能。
代号 function neighbors(my_id::Int, nproc::Int, nx_domains::Int, ny_domains::Int) id_pos = Array{Int,2}(undef, nx_domains, ny_domains) for id = 0:nproc-1 n_row = (id+1) % nx_domains > 0 ? (id+1) % nx_domains : nx_domains n_col = ceil(Int, (id + 1) / nx_domains) if (id == my_id) global my_row = n_row global my_col = n_col end id_pos[n_row, n_col] = id end neighbor_N = my_row + 1 <= nx_domains ? my_row + 1 : -1 neighbor_S = my_row - 1 > 0 ? my_row - 1 : -1 neighbor_E = my_col + 1 <= ny_domains ? my_col + 1 : -1 neighbor_W = my_col - 1 > 0 ? my_col - 1 : -1 neighbors = Dict{String,Int}() neighbors["N"] = neighbor_N >= 0 ? id_pos[neighbor_N, my_col] : -1 neighbors["S"] = neighbor_S >= 0 ? id_pos[neighbor_S, my_col] : -1 neighbors["E"] = neighbor_E >= 0 ? id_pos[my_row, neighbor_E] : -1 neighbors["W"] = neighbor_W >= 0 ? id_pos[my_row, neighbor_W] : -1 return neighbors end
建造迷宫时我们做过类似的事情
该函数的输入是my_id ,它是进程的等级(或标识符),进程数nproc ,在x方向上的划分数nx_domains以及在y方向上的划分数ny_domains 。
让我们现在检查此功能。 例如,再次看图。 参见图5,我们可以检查输出的等级4和等级11的过程。让我们进入REPL:
julia> neighbors(4, 12, 3, 4) Dict{String,Int64} with 4 entries: "S" => 3 "W" => 1 "N" => 5 "E" => 7
和
julia> neighbors(11, 12, 3, 4) Dict{String,Int64} with 4 entries: "S" => 10 "W" => 8 "N" => -1 "E" => -1
如您所见,我使用基本方向“ N”,“ S”,“ E”,“ W”指示邻居的位置。 例如,过程4将过程3作为邻居放置在其位置的南部。 假设第二个示例中的“ -1”表示在过程11的“北”和“东”侧未发现任何邻居,则可以验证上述所有结果都是正确的。
5.2消息传递
如我们先前所见,在每次迭代中,每个进程都将其边界发送给相邻进程。 同时,每个进程都从其邻居接收数据。 这些数据由每个过程以“鬼单元”的形式存储,并用于计算每个子域边界附近的解。
MPI有一个非常有用的MPI_Sendrecv命令,它使您可以在两个进程之间同时发送和接收消息。 不幸的是,MPI.jl不提供此功能,但是仍然可以单独使用MPI_Send和MPI_Receive来获得相同的结果。
这是下一个updateBound!函数完成的工作updateBound! ,它会在每次迭代时更新鬼单元。 此功能的输入是全局2D解决方案u,其中包括虚影单元以及与执行该功能的特定过程有关的所有信息(其等级是什么,其子域的坐标是什么,其邻居是什么)。 该函数首先将其边界发送给邻居,然后接收其边界。 接收部分正在通过MPI.Waitall!团队完成MPI.Waitall! ,以确保在更新感兴趣的特定子域的边单元之前,已收到所有预期的消息。
代号 function updateBound!(u::Array{Float64,2}, size_total_x, size_total_y, neighbors, comm, me, xs, ys, xe, ye, xcell, ycell, nproc) mep1 = me + 1
5.解决方案可视化
用边界周围的恒定值u = +10初始化域,这可以解释为边界处存在恒温源。 区域内部的初始条件u = −10 (左图6)。 随着时间的流逝,边界处的值u = 10扩散到该区域的中心。 例如,在步骤j = 15203解决方案类似于图11所示。 6在右边。
随着时间t的增加,解决方案变得越来越均匀,而理论上 在整个域中,它不会变成u = +10 。

图 6.初始条件(左)和步骤15203中的解决方案(右)。 该区域的边界始终存储在u = +10处。 随着时间的流逝,解决方案变得越来越均匀,并且在整个区域中趋于变得越来越接近值u = +10。
6.表现
与Fortran和C相比,测试Julia实现的性能给我留下了深刻的印象:我发现Julia实现是最快的!
在进行比较之前,我们先来看一下Julia代码本身的MPI性能。 图7显示了使用进程1到2(CPU)时的运行时比率。 理想情况下,您希望此数字接近2,即 使用两个处理器的速度应该是使用单个处理器的速度的两倍。 而是观察到,对于较小的任务大小(128x128单元的网格),编译时间和通信开销对总体执行时间有负面影响:加速小于1。 仅对于较大的任务,使用多个过程的优势才变得明显。
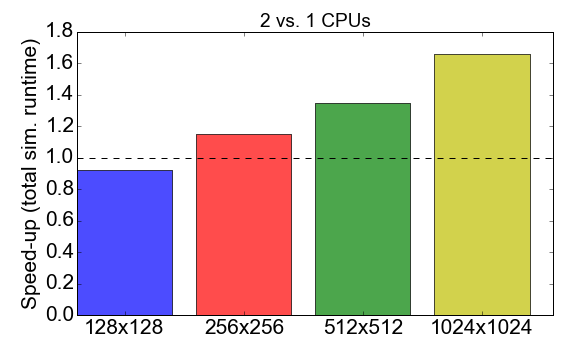
图7.根据任务的复杂性(网格大小),使用两个进程而不是一个进程来加快Julia MPI的实现。 “加速”是指使用1个进程对2个进程的总执行时间的比率。
现在发生了意外的转折:无花果。 图8显示,对于大小为256x256和512x512(仅是我测试的任务)的任务,Julia实现比Fortran和C更快。 在这里,我仅测量完成主迭代循环所需的时间。 我认为这是一个公平的比较,因为对于冗长的仿真,这将是整个运行时的最大贡献。
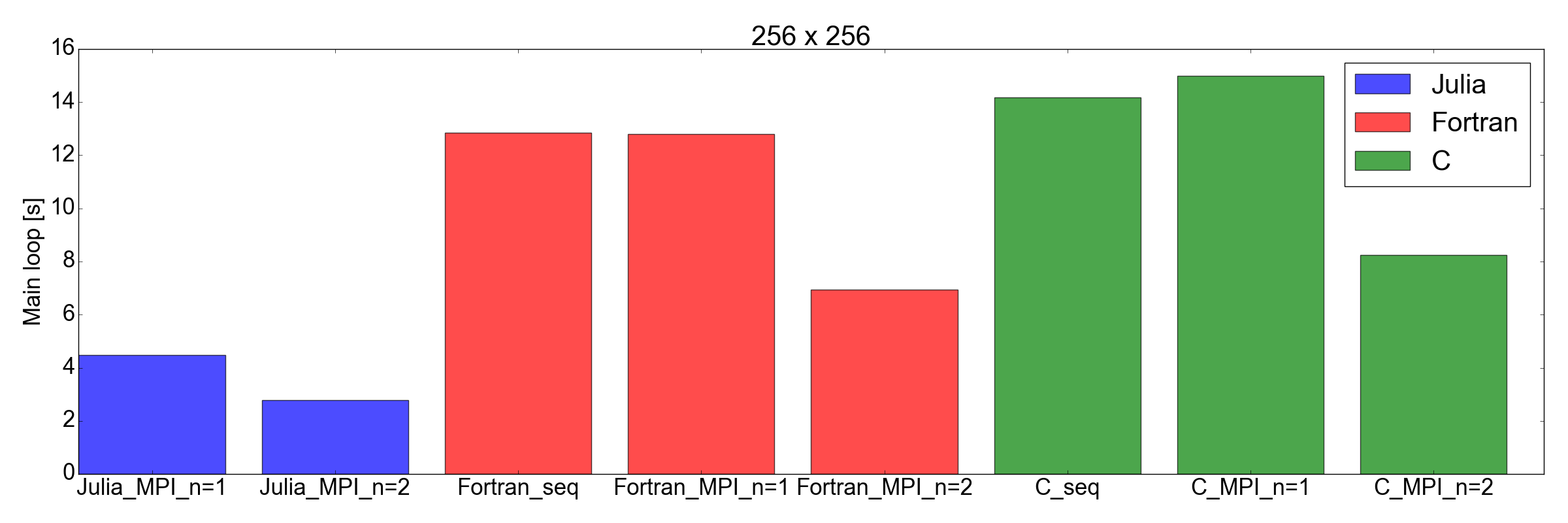

图8.在两种网格尺寸下,Julia vs. Fortran vs. C的性能:256x256(顶部)和512x512(底部)。 这表明朱莉娅是表现最好的语言。 性能是指在主代码循环中执行固定数量的迭代所花费的时间。
结论
在开始发布这篇文章之前,我怀疑Julia能否与Fortran和C的速度竞争科学应用。 主要原因是我之前已经将包含大约2,000行的学术代码从Fortran转换为Julia 0.6,并且发现性能下降了大约3倍。
但是这次...给我留下了深刻的印象。 我实际上只是将用Fortran和C编写的现有MPI实现转换为Julia 1.0。 结果见图。 8,自言自语:茱莉亚似乎是迄今为止最快的。 请注意,我没有考虑到Julia编译器耗时较长的编译时间,因为这对于需要数小时才能完成的“实际”应用程序来说是微不足道的因素。
我还必须补充一点,我的测试当然不像应该进行全面比较时那样全面。 实际上,我很想知道代码如何与两个以上的处理器(仅限于家用个人笔记本电脑)以及其他设备(请参阅Diffusion.jl )一起工作。
无论如何,这项练习使我相信,花更多的时间研究和使用Julia进行数据科学和科学应用是值得的。 取得新成就!
参考文献