迄今为止,Bitrix24服务还没有数百吉比特的流量,也没有庞大的服务器群(尽管当然有很多现有的服务器)。 但是对于许多客户来说,它是在公司工作的主要工具,它是真正的关键业务应用程序。 因此,跌倒-没办法。 但是,如果跌倒确实发生了,但是服务却如此“反叛”如此之快,以至于没人注意到任何事情怎么办? 您如何在不损失工作质量和客户数量的情况下实现故障转移? Bitrix24云服务主管Alexander Demidov在我们的博客中介绍了备份系统在产品存在7年后的演变。

“以SaaS的形式,我们在7年前推出了Bitrix24。 可能的主要困难如下:在以SaaS形式公开发布之前,此产品仅以盒装解决方案的形式存在。 客户从我们这里购买了产品,将其放置在服务器上,建立了公司门户网站-员工通讯,文件存储,任务管理,CRM的通用解决方案。 到2012年,我们决定希望将其作为SaaS推出,由自己管理,以提供容错能力和可靠性。 我们在此过程中积累了经验,因为在那之前我们还完全没有-我们只是软件制造商,而不是服务提供商。
启动服务时,我们了解最重要的是确保服务的容错性,可靠性和持续可用性,因为例如,如果您有一个简单的常规网站,例如一家商店,而该商店已经从您那里走了一个小时,那么,只有您自己受苦,您才能失去订单,您会失去客户,但对于您自己的客户来说-对于他来说,这不是很关键。 当然,他很沮丧,但是去了另一个网站上买了。 如果这是公司内部所有工作,通信,解决方案都捆绑在一起的应用程序,那么最重要的是赢得用户的信任,即,不要让他们失望也不要倒下。 因为如果里面的东西不起作用,所有的工作都会起床。
Bitrix.24作为SaaS
我们在2011年公开发布的前一年组装了第一台原型机。 大约一个星期的聚会,看起来,扭曲着-他甚至还在工作。 也就是说,可以进入表格,在那里输入门户网站的名称,正在展开新的门户网站,正在建立用户群。 我们研究了它,原则上评估了该产品,将其关闭,并在一年后完成了它。 因为我们有一项艰巨的任务:我们不想创建两个不同的代码库,所以我们不想支持单独的盒装产品,单独的云解决方案-我们希望在同一代码中完成所有这些工作。

当时的典型Web应用程序是一台服务器,在该服务器上运行一些php代码,mysql库,正在下载文件,将文档,图片放在上载爸爸中-很好,这一切正常。 las,不可能在此基础上运行至关重要的可持续性Web服务。 那里不支持分布式缓存,不支持数据库复制。
我们提出了以下要求:这种能力必须位于不同的位置,以支持复制,最好是位于不同的地理分布的数据中心。 将产品的逻辑与实际上的数据分开。 能够根据负载动态缩放,一般会产生静态。 基于这些考虑,实际上,我们在这一年中才开发出该产品的需求。 在这段时间里,在一个统一的平台(用于盒装解决方案,用于我们自己的服务)中,我们为需要的那些东西提供了支持。 在产品本身的级别上支持mysql复制:也就是说,编写代码的开发人员不会考虑他的请求将如何分配,他使用了我们的api,并且我们可以在主从服务器之间正确分配写和读请求。
我们为各种云对象存储提供了产品级别的支持:谷歌存储,亚马逊s3,以及对开放堆栈swift的支持。 因此,对于我们即服务和使用盒装解决方案的开发人员而言,这都非常方便:如果仅使用我们的api进行工作,他们就不会认为文件将保存在本地文件系统或目标文件存储中的位置。
结果,我们立即决定保留整个数据中心的级别。 在2012年,我们已经完全在Amazon AWS中启动,因为我们已经有使用该平台的经验-我们自己的网站托管在那里。 我们被亚马逊的每个区域都有多个访问区的事实所吸引-实际上,就其术语而言,几个数据中心彼此或多或少相互独立,并允许我们在整个数据中心级别进行保留:它突然失败,复制了master-master数据库,保留了Web应用程序服务器,并将静态变量移至s3对象存储。 负载是平衡的-当时是Amazonel弯头,但不久之后,我们来到了自己的平衡器,因为我们需要更复杂的逻辑。
他们想要的是,他们得到了...
我们想要提供的所有基本功能-服务器本身,Web应用程序和数据库的容错能力-一切正常。 最简单的方案:如果某些Web应用程序出现故障,那么一切就很简单-将它们从天平上关闭。

使机器本身崩溃的机器平衡器(当时是一个Amazonelb),标记为不正常,从而关闭了机器上的负载分配。 亚马逊自动缩放工作:当负载增加时,将新车添加到自动缩放组中,将负载分配给新车-一切都很好。 使用我们的均衡器,逻辑大致相同:如果应用程序服务器出了点问题,我们会从中删除请求,将这些计算机丢弃,启动新计算机,然后继续工作。 这些年来的计划虽然有所变化,但是仍然有效:它简单,易于理解,并且没有任何困难。
我们在全球范围内开展工作,客户的高峰负载完全不同,而且,以良好的方式,我们应该能够对系统的任何组件随时进行某些维护工作-对客户而言是无形的。 因此,我们有机会关闭数据库,重新分配第二个数据中心上的负载。
一切如何运作? -我们将流量切换到正常工作的数据中心-如果这是数据中心发生的意外,则完全是,如果这是我们在任何一个基地的计划工作,那么我们为这些客户提供服务的部分流量,切换到第二个数据中心,它将停止复制。 如果您需要用于Web应用程序的新计算机,则随着第二个数据中心上的负载增加,它们会自动启动。 我们完成了工作,还原了复制,然后将整个负载返回。 例如,如果我们需要在第二个DC中镜像某些工作,例如安装系统更新或更改第二个数据库中的设置,那么通常,我们将以另一种方式重复同一件事。 如果这是意外事故,那么我们将不费吹灰之力地进行所有操作:在监视系统中,我们使用事件处理程序机制。 如果有几项检查对我们有用,并且状态变得很关键,则将启动此处理程序,该处理程序可以执行此逻辑或该逻辑。 对于每个数据库,我们都已为其注册了哪个服务器进行故障转移,如果该服务器不可用,则需要在何处切换流量。 我们-从历史上看-以一种形式或另一种nagios或它的任何叉子使用。 原则上,几乎所有监视系统中都存在类似的机制,我们还没有使用更复杂的东西,但是也许有一天我们会使用。 现在,监视是由不可访问性触发的,并且具有切换某些功能的能力。
我们保留了一切吗?
我们有许多来自美国的客户,许多来自欧洲的客户,以及距离东方较近的许多客户-日本,新加坡等。 当然,俄罗斯的客户比例很高。 也就是说,工作远不止一个地区。 用户需要快速响应,有遵守各种当地法律的要求,并且我们在每个区域内为两个数据中心预留空间,此外,有些附加服务又可以方便地放置在一个区域内-对于处于此区域的客户地区工作。 REST处理程序,授权服务器,它们对于整个客户端来说并不那么重要,您可以在可接受的较小延迟之间切换它们,但是您不想发明自行车,如何监视自行车以及如何使用它们。 因此,在最大程度上,我们正在尝试使用现有的解决方案,而不是在其他产品中开发某些功能。 在某个地方,我们很少使用dns级别的交换,并且我们确定具有相同dns的服务的活跃性。 亚马逊提供Route 53服务,但您不仅可以在其中记录所有内容的dns,还更加灵活方便。 通过它,您可以使用地理位置来构建地理分布的服务,当您使用它来确定客户端来自何处并向他们提供某些记录时,就可以使用它来构建故障转移体系结构。 在Route 53本身中配置了相同的运行状况检查,您指定了要监视的端点,设置了指标并指定了哪些协议确定了服务的活动性-tcp,http,https; 设置确定服务是否有效的检查频率。 并且在dns本身中,您规定了什么是主要的,什么是次要的,如果触发了路由53内部的健康检查,则在哪里进行切换。所有这些操作都可以通过其他一些工具完成,但是更方便的是-我们将其设置一次,然后再考虑我们如何进行检查,如何切换:一切都可以独立进行。
第一个“ but” :如何以及如何保留53号路线本身? 如果他发生什么事情会发生吗? 幸运的是,我们从来没有踩过这种耙子,但是再次,在我面前,我将有一个故事,为什么我们认为我们仍然需要保留。 在这里,我们提前打草了。 一天几次,我们会完全卸载路线53中所有区域的信息。 亚马逊的API允许将它们安全地提交给JSON,并且我们已经筹集了几台冗余服务器,在这些服务器上进行转换,以配置形式上载并具有备份配置。 在这种情况下,我们可以手动快速部署它,而不会丢失dns设置数据。
第二个“但是” :此图片中没有保留什么? 平衡器自己! 我们使按地区的客户分布非常简单。 我们有bitrix24.ru,bitrix24.com,.de域-现在有13个不同的域在非常不同的区域中工作。 我们得出以下结论:每个地区都有自己的平衡器。 根据网络上的峰值负载,按区域分布更方便。 如果这是任何一个平衡器级别的故障,则只需将其退役并从dns中删除。 如果一组平衡器发生某种问题,那么它们会保留在其他站点,并使用相同的路由53进行切换,因为由于短暂的ttl,切换最多会发生2、3、5分钟。
第三个“但是” :还没有保留什么? S3,对。 我们将用户存储的文件放置在s3中,我们真诚地认为这是穿甲的,不需要在此保留任何内容。 但是历史表明发生了不同的事情。 通常,Amazon将S3描述为一项基本服务,因为Amazon本身使用S3来存储计算机,配置,AMI图像,快照的图像……如果s3崩溃(如这7年中曾经发生的那样),我们已经使用了多少bitrix24,其后是风扇。拉动了很多东西-无法启动虚拟机,api故障等。
S3可能会掉落-它曾经发生过一次。 因此,我们采用以下方案:几年前,在俄罗斯没有严重的公共存储对象,并且我们正在考虑选择自己做某事的方法...幸运的是,我们没有开始这样做,因为我们会深入研究我们没有拥有,并且可能会做到。 现在,Mail.ru具有s3兼容存储,Yandex拥有,而且许多提供商仍然拥有它。 结果,我们得出的结论是,我们首先要具有备份功能,其次要具有使用本地副本的功能。 对于特定的俄罗斯地区,我们使用Mail.ru Hotbox服务,该服务与s3 api兼容。 我们不需要对应用程序内部的代码进行任何严重的修改,并且我们执行了以下机制:在s3中,有一些触发器可用于创建/删除对象,Amazon具有Lambda之类的服务-这是无服务器代码执行,它将仅执行当某些触发器被触发时。
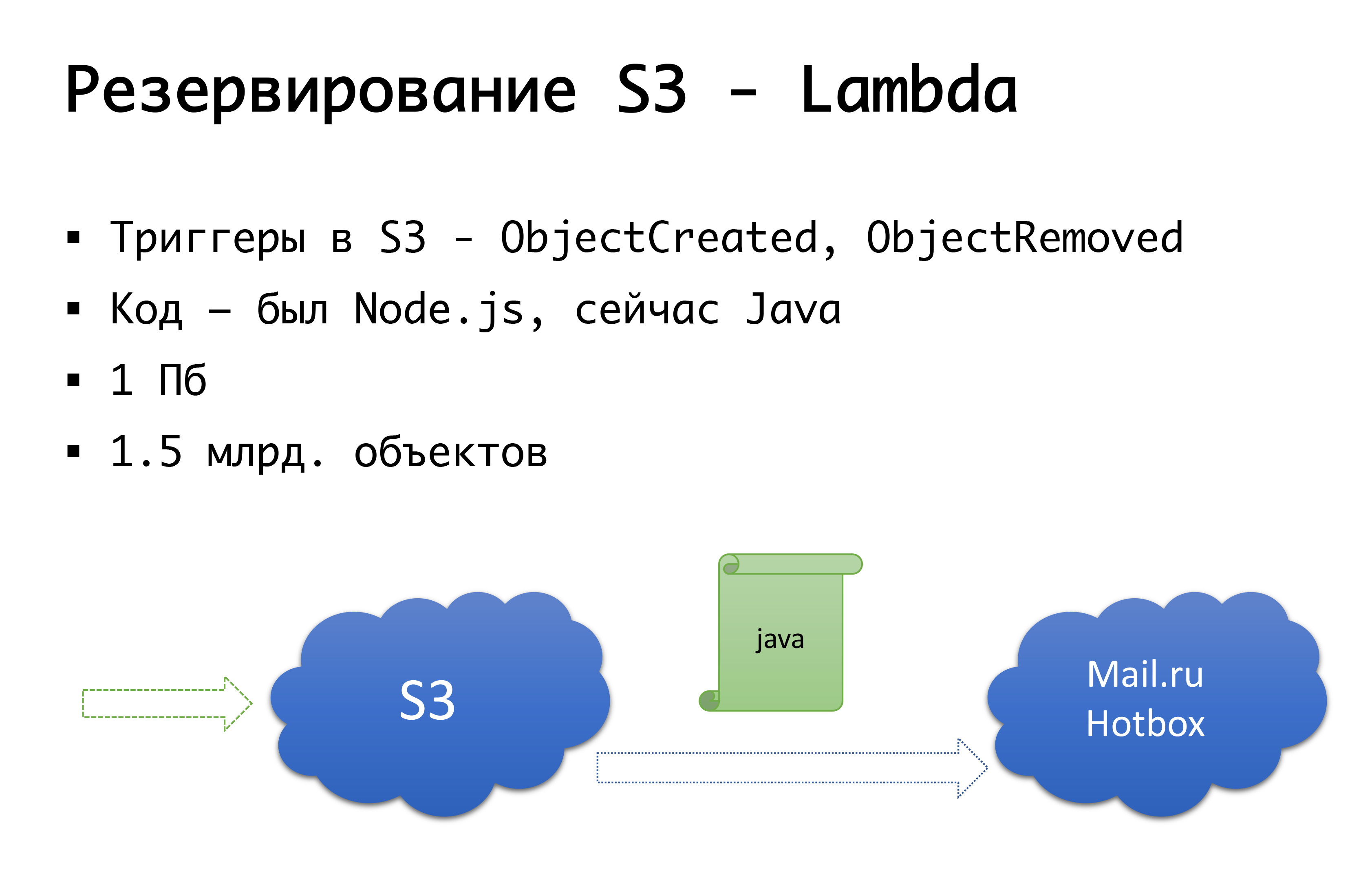
我们做的非常简单:如果触发触发器,我们将执行将对象复制到Mail.ru存储库的代码。 为了完全开始使用本地数据副本,我们还需要反向同步,以便位于俄罗斯市场的客户可以使用距离他们最近的存储。 Mail即将完成其存储库中的触发器-已经可以在基础结构级别执行反向同步,但是现在我们在我们自己的代码级别执行此操作。 如果我们看到客户端放置了某种文件,则在代码级别,我们将事件放入队列,进行处理并进行反向复制。 为什么不好:如果我们在产品之外对对象进行某种形式的工作,也就是说,通过某种外部手段,我们将不会考虑到这一点。 因此,我们要等到触发器出现在存储级别的末尾,以便无论我们从何处运行代码,都将以另一种方式复制到达我们的对象。
在代码级别,对于每个客户端,两个存储库均已注册:一个存储库被视为主要存储库,另一个存储库被视为备份存储库。 如果一切顺利,我们将与离我们更近的存储合作:也就是说,在亚马逊的客户使用S3,在俄罗斯工作的客户在Hotbox。 如果该复选框有效,则故障转移应连接到我们,我们会将客户端切换到另一个存储。 我们可以按区域独立设置此标志,并可以来回切换它们。 实际上,我们还没有使用过,但是我们已经设想了这种机制,并且我们认为有一天我们将需要并使用这种开关。 一旦它已经发生。
哦,您的亚马逊逃脱了...
今年4月是俄罗斯电报锁开始运营的周年纪念日。 受此影响最大的提供商是亚马逊。 而且,不幸的是,在世界各地开展业务的俄罗斯公司遭受的损失更大。
如果该公司是全球性公司,而俄罗斯仅占很小的一部分,占3-5%,那么,可以以一种或另一种方式捐赠。
如果这是一家纯粹的俄罗斯公司-我确定您需要在本地定位-那么,只是用户自己会感到方便,舒适,并且风险会降低。
如果这是一家在全球开展业务的公司,并且在俄罗斯和全球其他地方拥有大约相等的来自俄罗斯的客户份额? 段的连通性很重要,并且无论如何它们都必须相互配合。
在2018年3月底,Roskomnadzor给最大的运营商写了一封信,称他们计划封锁数百万个ip亚马逊以封锁Zello Messenger。 感谢这些提供者-他们成功地将这封信泄露给了每个人,并且据了解,与Amazon的连接性可能会崩溃。 星期五是,我们从servers.ru慌张地跑到同事那里,说:“朋友们,我们需要几台不在俄罗斯,不在亚马逊,但例如在阿姆斯特丹某个地方的服务器”为了至少能够以某种方式将我们自己的vpn并在此处代理一些根本无法影响的终结点,例如相同s3的终结点-我们无法尝试提供新服务并获得另一个ip,您仍然需要到达那里。 几天后,我们安装了这些服务器,将它们提升了,并为锁定的开始做好了准备。 奇怪的是,ILV看着炒作和引发的恐慌说:“不,我们现在不会阻止任何事情。” (但这要等到它们开始阻止电报的那一刻。)设置了旁路选项并意识到它们没有进入锁定状态之后,我们仍然没有拆除整个东西。 所以,以防万一。

而在2019年,我们仍然生活在锁的条件下。 我昨晚看了一下:大约一百万ip继续被阻止。 没错,亚马逊几乎完全畅通无阻,在高峰期达到了2000万个地址。总的来说,现实是连通性,良好的连通性-事实并非如此。 突然之间 可能不是出于技术原因-火灾,挖掘机等等。 或者,正如我们所见,还不完全是技术性的。 因此,拥有自己的AS-kami的大大小小的人可能可以通过其他方式进行控制-直接连接和其他事物已经处于二级水平。 但是,在一个简单的版本中(就像我们甚至更小),以防万一,可以在其他位置提升的服务器级别上具有冗余性,并预先配置VPN,代理,并能够在具有关键连接性的那些网段中快速切换配置。 这对我们不止一次有用,当亚马逊锁启动时,在最坏的情况下我们让S3流量通过,但逐渐都出错了。
以及如何预定整个供应商?
现在,我们没有整个亚马逊失败的情况。 俄罗斯也有类似的情况。 我们在俄罗斯由一个提供商托管,我们从中选择了多个站点。 一年前,我们遇到了一个问题:尽管这是两个数据中心,但是提供商网络配置方面可能已经存在问题,无论如何它们都会影响这两个数据中心。 而且我们在两个站点上都无法访问。 当然,这就是发生的事情。 我们最终重新定义了内部架构。 它并没有太大变化,但是对于俄罗斯来说,我们现在有两个站点,它们不是一个提供商,而是两个不同的站点。 如果其中一个失败,我们可以切换到另一个。
假设地,我们正在考虑让亚马逊保留其他提供商的级别; 也许是谷歌,也许还有其他人……但是到目前为止,我们在实践中已经观察到,如果亚马逊在同一可用区级别上崩溃,那么在整个区域级别上崩溃的情况就很少见。 因此,从理论上讲,我们可能会保留“亚马逊不是亚马逊”的保留,但实际上这还不存在。
关于自动化的几句话
您是否总是需要自动化? 回忆一下邓宁-克鲁格效应是合适的。 在x轴上,我们正在获得的知识和经验,在y轴上,对我们的行动充满信心。 起初,我们什么都不知道,也不确定。 然后我们知道了一点,就变得非常有信心-这就是所谓的“愚蠢之峰”,图片“痴呆和勇气”很好地说明了这一点。 此外,我们已经学到了一点,并准备投入战斗。 然后我们踩着一些严重的耙子,在我们似乎了解某些事情时陷入绝望的山谷,但实际上我们并不了解。 然后,随着您的经验积累,我们变得更加自信。
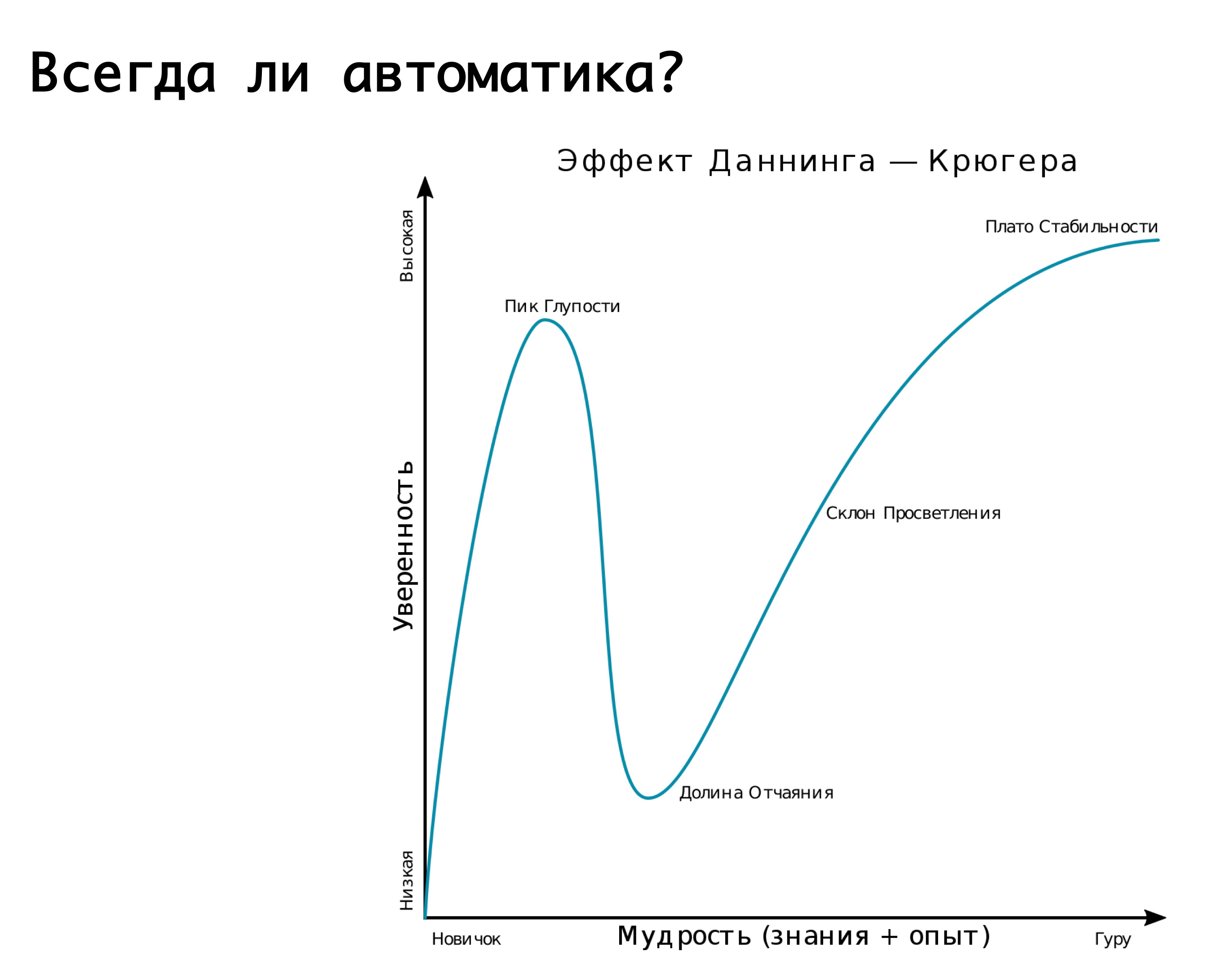
该图很好地描述了我们关于自动切换到一个或另一个事故的各种逻辑。 — , . , , , . -: false positive, - , , -, . , - — . , . , . 但是! , , , , , , …
结论
7 , , - , — -, , , , — — . - , , , . — , , — . , - — s3, , . , , - - . . , , — : , — ? , - , , - «, ».
完美主义与实际力量,时间和金钱之间的合理折衷,可以花在最终拥有的方案上。本文是亚历山大·德米多夫(Alexander Demidov)在第4天正常运行时间会议上的报告的补充和扩展版本。