嗨,我正在为
Tarantool DBMS创建应用程序-这是Mail.ru Group开发的平台,该平台在Lua中结合了高性能DBMS和应用程序服务器。 基于Tarantool的解决方案的高速实现,尤其是通过支持内存DBMS模式以及在具有数据的单个地址空间中执行业务应用程序逻辑的能力而实现的。 这样可以确保使用ACID事务进行数据持久化(WAL日志保留在磁盘上)。 Tarantool具有内置的复制和分片支持。 从2.1版开始,支持SQL查询。 Tarantool是开源的,并根据简化的BSD获得许可。 还有一个商业企业版。
 感受力量! (又名欣赏表演)
感受力量! (又名欣赏表演)以上所有这些使Tarantool成为创建高负载数据库应用程序的有吸引力的平台。 在这样的应用程序中,数据复制通常变得必要。
如上所述,Tarantool具有内置的数据复制功能。 它的工作原理是在向导日志(WAL)中包含的所有事务的副本上顺序执行。 通常,这种复制(以下将称为
低级复制)用于提供应用程序的容错能力和/或在集群节点之间分配读取负载。
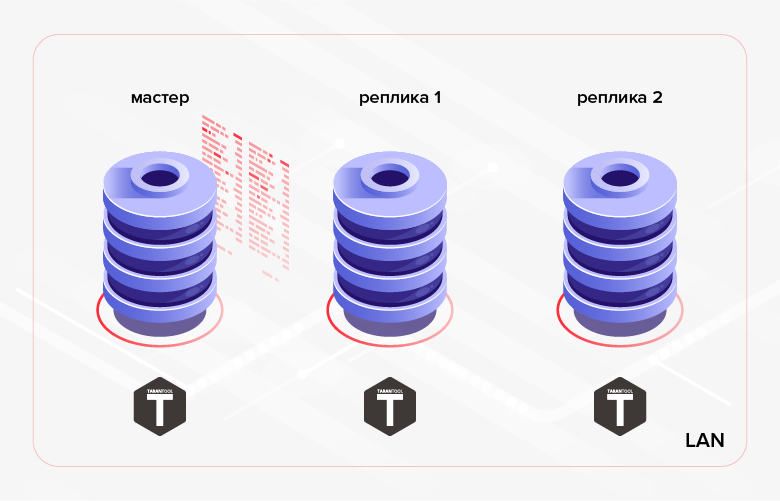 图 1.在集群内复制
图 1.在集群内复制替代方案的一个示例是将一个数据库中创建的数据传输到另一个数据库以进行处理/监视。 在后一种情况下,更方便的解决方案可能是使用
高级复制-在应用程序的业务逻辑级别进行数据复制。 即 我们没有使用内置在DBMS中的现成解决方案,但是我们自己在正在开发的应用程序中实现复制。 这种方法既有优点也有缺点。 我们列出了优点。
1.节省流量:
- 您不能传输所有数据,而只能传输一部分数据(例如,您只能传输某些表,其中某些列或满足特定条件的记录);
- 低级复制与异步(在当前版本的Tarantool-1.10中实现)或同步(将在将来的Tarantool的将来版本中)连续执行的低级复制不同,高级复制可以由会话执行(即应用程序首先执行数据同步-交换会话)数据,那么复制就会暂停,然后再进行下一个交换会话,等等);
- 如果记录已更改多次,则只能传输其最新版本(与低级复制不同,在低级复制中,向导上所做的所有更改将在副本上依次播放)。
2.通过HTTP进行交换没有任何困难,这使您可以同步远程数据库。
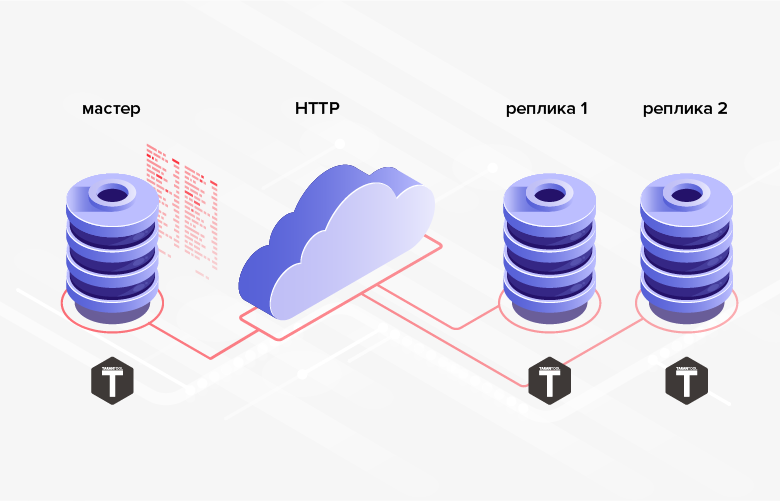 图 2. HTTP复制
图 2. HTTP复制3.在其间传输数据的数据库结构不必相同(此外,在一般情况下,甚至可以使用不同的DBMS,编程语言,平台等)。
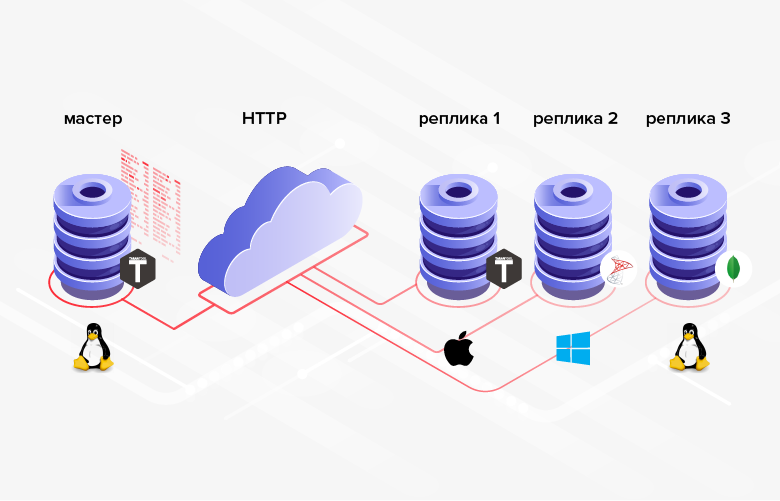 图 3.在异构系统中复制
图 3.在异构系统中复制缺点是,与配置相比,编程平均而言更复杂/更昂贵,并且您必须设置自己的功能,而不是设置内置功能。
如果在您的情况下上述优点起着决定性的作用(或是必要条件),则使用高级复制是有意义的。 让我们考虑在Tarantool DBMS中实现高级数据复制的几种方法。
流量最小化
因此,高级复制的好处之一就是节省流量。 为了充分体现这一优势,有必要将每个交换会话期间传输的数据量减到最少。 当然,不应忘记,在会话结束时,数据接收器必须与源同步(至少对于复制中涉及的部分数据)。
如何最大程度地减少高级复制期间传输的数据量? “在额头上”的解决方案可以是按日期时间选择数据。 为此,您可以使用表中已有的日期时间字段(如果有)。 例如,文档“订单”可以具有字段“订单执行所需的时间”
delivery_time 。 该解决方案的问题在于该字段中的值不必按照与订单创建相对应的顺序进行。 因此,我们不记得在上一个交换会话期间发送的
delivery_time字段的最大值,并且在下一个交换会话中,选择所有具有
delivery_time字段较高值的记录。 在交换会话之间的间隔中,可以添加具有较小
delivery_time字段值的记录。 此外,订单可能会发生更改,但这并不会影响
delivery_time字段。 在两种情况下,更改都不会从源发送到接收器。 为了解决这些问题,我们将需要“重叠”传输数据。 即 在每次交换会话期间,我们将传送所有
delivery_time字段值超过过去某个时间点(例如,从当前时刻起N个小时)的数据。 但是,很明显,对于大型系统,此方法非常冗余,可以减少我们目标的流量节省。 另外,发送的表可能没有日期时间字段。
在实现方面更复杂的另一种解决方案是确认数据的接收。 在这种情况下,在每个交换会话中,所有数据都被发送,接收者未确认其接收。 为了实现,您需要在源表中添加一个布尔列(例如,
is_transferred )。 如果接收方确认已收到记录,则将相应字段设置为
true ,之后该记录将不再参与交换。 此实现选项具有以下缺点。 首先,对于每个传输的记录,必须生成并发送确认。 粗略地说,这可以相当于使传输的数据量增加一倍,并导致往返次数增加一倍。 其次,不可能将相同的记录发送给多个接收者(第一个接收者将为自己和其他所有人确认收据)。
避免上述缺点的方法是在要发送的表中添加列以跟踪其行中的更改。 这样的列可以是日期时间类型,并且每次添加/更改记录时(在原子上添加/更改),应用程序都必须在当前时间设置/更新该列。 例如,我们将其称为
update_time列。 在为传输的记录保存了该列的字段的最大值之后,我们可以从该值开始下一个交换会话(选择具有
update_time字段的值超过先前保存的值的记录)。 后一种方法的问题在于,数据更改可能以批处理模式发生。 结果,
update_time列中的字段值
update_time不是唯一的。 因此,此列不能用于批处理(页面)数据输出。 对于逐页数据输出,有必要发明效率可能很低的其他机制(例如,从数据库中检索
update_time高于指定值的所有记录,并从样本开头的特定偏移量开始发出一定数量的记录)。
您可以通过稍微改进以前的方法来提高数据传输的效率。 为此,我们将使用整数类型(长整数)作为用于跟踪更改的列字段的值。
row_ver列
row_ver 。 每次创建/修改记录时,仍应设置/更新此列的字段值。 但是在这种情况下,不会为该字段分配当前日期时间,而是将某个计数器的值增加一。 结果,
row_ver列将包含唯一值,不仅可以用于输出“增量”数据(在上一个交换会话结束后添加/更改的数据),而且还可以用于简单而有效的分页。
在我看来,最后提出的最小化作为高级复制的一部分传输的数据量的方法是最优化和通用的。 让我们更详细地讨论它。
使用行版本计数器进行数据传输
服务器/主控实施
在MS SQL Server中,要实现此方法,有一个特殊的列类型
rowversion 。 每个数据库都有一个计数器,每当您添加或更改具有
rowversion类型列的表中的记录时,该计数器就会增加一个。 该计数器的值自动分配给添加/更改记录中此列的字段。 Tarantool DBMS没有类似的内置机制。 但是,在Tarantool中,手动实现它并不困难。 考虑一下如何完成。
首先,使用一些术语:Tarantool中的表称为空间,而记录称为元组。 在Tarantool中,您可以创建序列。 序列不过是整数有序值的命名生成器。 即 这正是我们需要的目的。 下面我们将创建这样的序列。
在Tarantool中执行任何数据库操作之前,必须运行以下命令:
box.cfg{}
结果,Tarantool将开始将快照和事务日志写入当前目录。
创建一个
row_version序列:
box.schema.sequence.create('row_version', { if_not_exists = true })
if_not_exists选项允许
if_not_exists多次运行创建脚本:如果对象存在,Tarantool将不会尝试重新创建它。 此选项将在所有后续DDL命令中使用。
让我们为示例创建一个空间。
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' }, { name = 'row_ver', type = 'unsigned' } }, if_not_exists = true })
在这里,我们设置空间的名称(
goods ),字段的名称及其类型。
Tarantool自动增量字段也使用序列创建。 为
id字段创建一个自动递增的主键:
box.schema.sequence.create('goods_id', { if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
Tarantool支持几种类型的索引。 大多数情况下,使用TREE和HASH类型的索引,这些索引基于与名称相对应的结构。 TREE是最通用的索引类型。 它允许您以有序的方式检索数据。 但是对于相等性的选择,HASH更适合。 因此,建议对主键使用HASH(我们已经这样做了)。
要使用
row_ver列传输更改的数据,必须将
row_ver序列值绑定到此列中的字段。 但是与主键不同的是,不仅在添加新记录时,而且在更改现有记录时,
row_ver列中的字段值都应增加一。 为此,您可以使用触发器。 Tarantool有两种用于空间的触发器:
before_replace和
on_replace 。 每次更改空间中的数据都会触发触发器(对于受更改影响的每个元组,都会触发触发器功能)。 与
on_replace不同,
before_replace触发器允许您修改为其执行触发器的元组的数据。 因此,最后一种触发器适合我们。
box.space.goods:before_replace(function(old, new) return box.tuple.new({new[1], new[2], new[3], box.sequence.row_version:next()}) end)
此触发器将存储的元组的
row_ver字段的值替换为下一个
row_version序列
row_version 。
为了能够从
row_ver列上的
goods空间中提取数据,请创建一个索引:
box.space.goods:create_index('row_ver', { parts = { 'row_ver' }, unique = true, type = 'TREE', if_not_exists = true })
索引类型是树(
TREE ),因为 我们需要按
row_ver列中值的升序检索数据。
在空间中添加一些数据:
box.space.goods:insert{nil, 'pen', 123} box.space.goods:insert{nil, 'pencil', 321} box.space.goods:insert{nil, 'brush', 100} box.space.goods:insert{nil, 'watercolour', 456} box.space.goods:insert{nil, 'album', 101} box.space.goods:insert{nil, 'notebook', 800} box.space.goods:insert{nil, 'rubber', 531} box.space.goods:insert{nil, 'ruler', 135}
因为 第一个字段是自动递增计数器,我们改为传递nil。 Tarantool将自动替换下一个值。 同样,您可以将nil作为
row_ver列中字段的值传递-或根本不指定该值,因为 该列在空间中的最后位置。
检查插入结果:
tarantool> box.space.goods:select()
如您所见,第一个和最后一个字段是自动填写的。 现在,很容易编写一个用于分页卸载
goods的函数:
local page_size = 5 local function get_goods(row_ver) local index = box.space.goods.index.row_ver local goods = {} local counter = 0 for _, tuple in index:pairs(row_ver, { iterator = 'GT' }) do local obj = tuple:tomap({ names_only = true }) table.insert(goods, obj) counter = counter + 1 if counter >= page_size then break end end return goods end
该函数将接收到的最后一条记录的
row_ver值(第一次调用为0)作为参数,并返回下一批已更改的数据(如果有,则为空数组,否则为空数组)。
Tarantool中的数据检索是通过索引完成的。
get_goods函数使用
row_ver索引
row_ver检索更改的数据。 迭代器类型为GT(大于,大于)。 这意味着迭代器将从传递的键之后的下一个值开始顺序遍历索引值。
迭代器返回元组。 为了随后能够通过HTTP传输数据,必须将元组转换为便于后续序列化的结构。 在示例中,
tomap使用了标准的
tomap函数。 您可以编写自己的函数
tomap而不必使用
tomap 。 例如,我们可能想重命名
name字段,而不传递
code字段,而添加
comment字段:
local function unflatten_goods(tuple) local obj = {} obj.id = tuple.id obj.goods_name = tuple.name obj.comment = 'some comment' obj.row_ver = tuple.row_ver return obj end
输出数据的页面大小(一部分中的记录数)由
page_size变量确定。 在示例中,
page_size值为5。在实际程序中,页面大小通常更为重要。 它取决于空间元组的平均大小。 通过测量数据传输时间,可以凭经验选择最佳页面大小。 页面越大,发送方和接收方之间的往返次数越少。 因此,您可以减少上传更改的总时间。 但是,如果页面大小太大,我们将花费服务器太长时间来序列化选择。 结果,在处理到达服务器的其他请求时可能会有延迟。 可以从配置文件中加载
page_size参数。 对于每个传输空间,您可以设置自己的值。 但是,对于大多数空格,默认值(例如100)可能是合适的。
get_goods函数放入模块中。 创建一个repl.lua文件,其中包含
page_size变量和
get_goods函数的描述。 在文件末尾,添加导出功能:
return { get_goods = get_goods }
要加载模块,执行:
tarantool> repl = require('repl')
让我们执行
get_goods函数:
tarantool> repl.get_goods(0)
从最后一行
row_ver字段的值,然后再次调用该函数:
tarantool> repl.get_goods(5)
再一次:
tarantool> repl.get_goods(8)
如您所见,通过这种用法,该功能可以逐页返回
goods空间的所有记录。 最后一页后面是空白选择。
我们将对空间进行更改:
box.space.goods:update(4, {{'=', 6, 'copybook'}}) box.space.goods:insert{nil, 'clip', 234} box.space.goods:insert{nil, 'folder', 432}
我们更改了一条记录的
name字段的值,并添加了两条新记录。
重复最后一个函数调用:
tarantool> repl.get_goods(8)
该函数返回更改和添加的记录。 因此,
get_goods函数允许
get_goods获取自上次调用以来已发生更改的数据,这是所考虑的复制方法的基础。
我们不在本文讨论范围之内,以JSON形式通过HTTP保留结果的输出。 您可以在这里阅读有关内容:
https :
//habr.com/ru/company/mailru/blog/272141/客户端/从机部分的实现
考虑一下接收方的实现。 在接收方创建一个空间来存储下载的数据:
box.schema.space.create('goods', { format = { { name = 'id', type = 'unsigned' }, { name = 'name', type = 'string' }, { name = 'code', type = 'unsigned' } }, if_not_exists = true }) box.space.goods:create_index('primary', { parts = { 'id' }, sequence = 'goods_id', unique = true, type = 'HASH', if_not_exists = true })
空间的结构类似于源中空间的结构。 但是由于我们不会将接收到的数据传输到其他地方,因此接收者空间中
row_ver列。 在
id字段中将写入源的标识符。 因此,在接收器端,无需使其自动递增。
另外,我们需要一个空间来保存
row_ver值:
box.schema.space.create('row_ver', { format = { { name = 'space_name', type = 'string' }, { name = 'value', type = 'string' } }, if_not_exists = true }) box.space.row_ver:create_index('primary', { parts = { 'space_name' }, unique = true, type = 'HASH', if_not_exists = true })
对于每个加载空间(字段
space_name ),我们将在此处保存最后一个加载值
row_ver (字段
value )。 主键是
space_name列。
让我们创建一个通过HTTP加载
goods空间数据的函数。 为此,我们需要一个实现HTTP客户端的库。 以下行加载该库并实例化HTTP客户端:
local http_client = require('http.client').new()
我们还需要一个用于json反序列化的库:
local json = require('json')
这足以创建数据加载功能:
local function load_data(url, row_ver) local url = ('%s?rowVer=%s'):format(url, tostring(row_ver)) local body = nil local data = http_client:request('GET', url, body, { keepalive_idle = 1, keepalive_interval = 1 }) return json.decode(data.body) end
该函数在url上执行HTTP请求,将
row_ver作为参数传递给它,然后返回请求的反序列化结果。
保存接收到的数据的功能如下:
local function save_goods(goods) local n = #goods box.atomic(function() for i = 1, n do local obj = goods[i] box.space.goods:put( obj.id, obj.name, obj.code) end end) end
将数据存储在
goods空间中的循环放在事务中(
box.atomic使用
box.atomic函数),以减少磁盘操作的次数。
最后,本地空间
goods与源的同步功能可以实现如下:
local function sync_goods() local tuple = box.space.row_ver:get('goods') local row_ver = tuple and tuple.value or 0
首先,我们读取先前保存的
goods空间
row_ver值。 如果不存在(第一个交换会话),那么我们将零作为
row_ver 。 接下来,在循环中,我们将修改后的数据从源分页到指定的url。 在每次迭代时,我们将接收到的数据保存在相应的本地空间中,并更新
row_ver值(在row_ver
row_ver和
row_ver变量中)-我们从已加载数据的最后一行获取
row_ver值。
为了防止意外循环(在程序出错的情况下),
while可以替换
for :
for _ = 1, max_req do ...
由于
sync_goods函数,接收
sync_goods的
goods将包含源中所有
goods空间记录的最新版本。
显然,不能以这种方式广播数据删除。 如果存在这种需要,可以使用删除标记。
is_deleted布尔字段
is_deleted goods空间,而不是物理删除记录,而是使用逻辑删除-将
is_deleted字段的值设置为
true 。 有时,代替
is_deleted布尔字段,使用
deleted字段更为方便,该字段存储逻辑删除记录的日期时间。 在执行逻辑删除之后,标记为删除的记录将从源传输到接收方(根据上述逻辑)。
row_ver序列可用于从其他空间传输数据:无需为每个传输空间创建单独的序列。
我们研究了使用Tarantool DBMS在应用程序中进行高级数据复制的有效方法。
结论
- Tarantool DBMS是用于创建高负载应用程序的有吸引力的,很有前途的产品。
- 与低级复制相比,高级别复制为数据传输提供了更灵活的方法。
- 本文考虑的高级复制方法允许通过仅传输自上次交换会话以来已发生更改的那些记录来最大程度地减少传输的数据量。