HighLoad ++已经存在很长时间了,我们谈论定期使用PostgreSQL。 但是开发人员每个月,每年都仍然存在相同的问题。 在州没有DBA的小型公司中,在使用数据库时会出现错误,这不足为奇。 大型公司也需要数据库,即使使用调试过的流程,错误仍然会发生并且数据库会崩溃。 公司的规模大小无关紧要-错误仍然会发生,数据库会定期崩溃,崩溃。

当然,这永远不会发生在您身上,但是检查清单并不困难,并且可以节省以后的工作。 在标题下,我们将列出开发人员在使用PostgreSQL时犯下的最常见的典型错误,了解为什么我们不需要这样做,并找到方法。
关于演讲者:Alexey Lesovsky开始担任Linux系统管理员。 从虚拟化和监视系统的任务逐渐发展到PostgreSQL。 现在,
Data Egret中的 PostgreSQL DBA是一家咨询公司,它与许多不同的项目一起工作,并且看到许多重复出现的问题的示例。 这是HighLoad ++ 2018上报告呈现的
链接 。
问题从何而来
为了进行热身,提供了一些有关错误如何发生的故事。
历史1.功能
问题之一是公司在使用PostgreSQL时使用什么功能。 一切都从简单开始:PostgreSQL,数据集,使用JOIN进行简单查询。 我们获取数据,执行SELECT-一切都很简单。
然后我们开始使用PostgreSQL的附加功能,添加新功能,扩展。 功能越来越大。 我们连接流复制,分片。 各种实用程序和车身工具包出现了-pgbouncer,pgpool,patroni。 这样的东西。

每个关键字都是出现错误的原因。
历史记录2.数据存储
我们存储数据的方式也是错误的根源。
该项目首次出现时,其中包含许多数据和表格。 简单的查询就足以接收和记录数据。 但是,现在有越来越多的表。 从不同位置选择数据,将显示JOIN。 查询非常复杂,包括CTE构造,SUBQUERY,IN列表和LATERAL。 犯错误并编写曲线查询变得容易得多。
这只是冰山一角-在侧面的某个地方可以有另外400个表,分区,有时还可以从中读取数据。
历史3.生命周期
有关如何遵循产品的故事。 数据总是需要存储在某个地方,因此总会有一个数据库。 产品开发时如何开发数据库?
一方面,有些
开发人员忙于编程语言。 他们编写应用程序并开发软件开发领域的技能,而不关注服务。 通常,他们对Kafka或PostgreSQL的工作方式不感兴趣-他们在应用程序中开发了新功能,而对其余的内容一无所知。

另一方面
,管理员 。 他们在Bare-metal上筹集了新的Amazon实例,并忙于自动化:他们设置部署以使布局正常运行,并进行配置,以使服务彼此之间很好地交互。

在某些情况下,没有时间或没有时间精简组件和数据库的需求。 数据库使用默认配置工作,然后它们完全忘记了它们-“有效,请不要动它”。
结果,耙子散布在各个地方,然后不时飞入开发商的额头。 在本文中,我们将尝试将所有这些耙子收集在一个棚子中,以便您了解它们,并且在使用PostgreSQL时不要踩踏它们。
规划与监控
首先,假设我们有一个新项目-它始终是一个积极的开发,假设测试和新功能的实施。 当应用程序刚刚出现并正在开发时,它的流量,用户和客户都很少,它们都生成少量数据。 该数据库具有快速处理的简单查询。 无需拖动大量数据,没有问题。
但是有更多的用户,流量来了:出现了新数据,数据库不断增长,旧查询停止工作。 有必要完成索引,重写和优化查询。 存在性能问题。 所有这些都会导致凌晨4点发出警报,给管理员带来压力以及管理层不满。
怎么了
以我的经验,大多数情况下磁盘数量不足。
第一个例子 。 我们打开了监视磁盘利用率的计划,我们看到
磁盘上的可用空间已用完 。
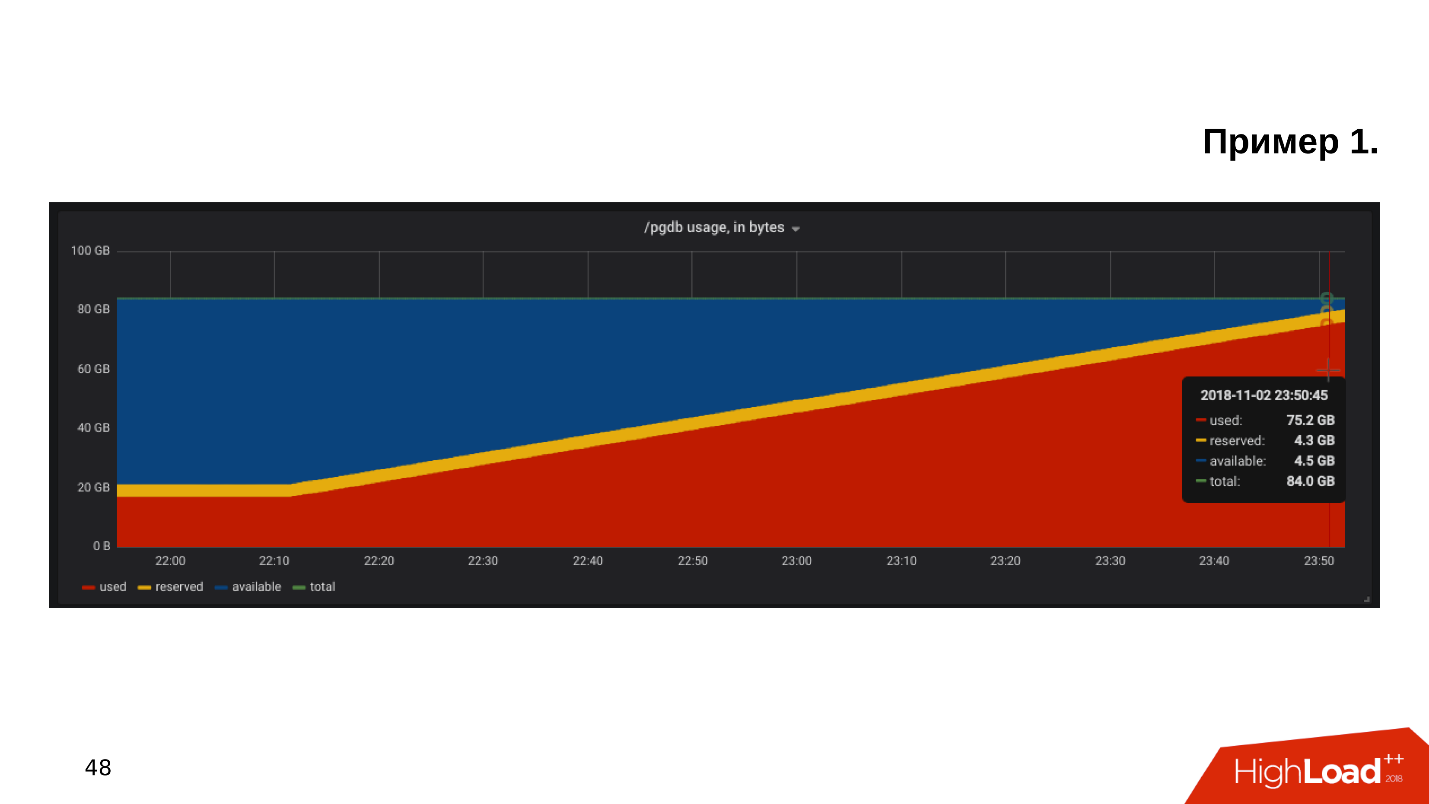
我们看一下有多少空间被吞噬了-原来有一个pg_xlog目录:
$ du -csh -t 100M /pgdb/9.6/main/* 15G /pgdb/9.6/main/base 58G /pgdb/9.6/main/pg_xlog 72G
数据库管理员通常知道此目录是什么,并且不触摸它-它存在并且存在。 但是,开发人员,尤其是如果他看舞台时,会挠头思考:
-某种日志...让我们删除pg_xlog!删除目录,数据库停止工作 。 删除事务日志后,您必须立即通过Google搜索如何引发数据库。
 第二个例子
第二个例子 。 再次,我们打开监视,发现空间不足。 这次这个地方被某种基地占据了。
$ du -csh -t 100M /pgdb/9.6/main/* 70G /pgdb/9.6/main/base 2G /pgdb/9.6/main/pg_xlog 72G
我们正在寻找占用最大空间的数据库,哪些表和索引。

原来,这是一个具有历史日志的表。 我们从不需要历史日志。 他们写的只是为了以防万一,如果不是因为这个地方的问题,在第二次出现之前没有人会看他们:
-让我们清理所有……十月份之前的东西!发出更新请求,运行它,它将解决并删除一些行。
=# DELETE FROM history_log -# WHERE created_at < «2018-10-01»; DELETE 165517399 Time: 585478.451 ms
查询运行10分钟,但表仍占用相同的空间。
PostgreSQL从表中删除行-一切正确,但是不会将其返回给操作系统。 PostgreSQL的这种行为对于大多数开发人员是未知的,并且可能非常令人惊讶。
第三个例子 。 例如,ORM提出了一个有趣的请求。 通常,每个人都责怪ORM进行了“坏”查询,这些查询读出了一些表。
假设有多个JOIN操作可以在多个线程中并行读取表。 PostgreSQL可以并行化数据操作并可以读取多个线程中的表。 但是,鉴于我们有几个应用程序服务器,此查询每秒读取所有表数千次。 事实证明,数据库服务器超载,磁盘无法应对,所有这些导致后端出现
502 Bad Gateway错误-数据库不可用。
但这还不是全部。 您可以调用PostgerSQL的其他功能。
- DBMS后台进程的缺点-PostgreSQL具有各种检查点,清除和复制。
- 虚拟化开销 。 当数据库在虚拟机上运行时,同一块铁上也有虚拟机,它们可能在资源上发生冲突。
- 储存来自中国制造商NoName ,其性能取决于摩 the 座上的月亮或土星的位置,并且没有办法弄清楚它为何如此工作。 基地正在遭受苦难。
- 默认配置 。 这是我最喜欢的主题:客户说他的数据库运行缓慢-您可以看到,并且他具有默认配置。 事实是,默认的PostgreSQL配置旨在在最弱的茶壶上运行 。 启动了基础,它可以工作,但是当它已经在中级硬件上工作时,则此配置还不够,需要对其进行调整。
通常,PostgreSQL缺少磁盘空间或磁盘性能。 幸运的是,对于处理器,内存和网络,通常情况下,一切都是有序的。
如何成为 需要监控和计划! 这似乎很明显,但是由于某些原因,在大多数情况下,没有人计划基础,并且监视无法涵盖PostgreSQL操作期间需要监视的所有内容。 有一套明确的规则,所有规则都可以正常运行,而不是“随意”进行。
规划中
毫不犹豫地将数据库托管在SSD上 。 SSD长期以来一直变得可靠,稳定和高效。 企业SSD型号已经存在多年了。
始终计划数据模式 。 不要向您怀疑需要的内容写入数据库-确保不需要。 一个简单的示例是我们的一个客户的表经过稍微修改的表。

这是一个日志表,其中有一个json类型的数据列。 相对而言,您可以在此列中编写任何内容。 从该表的最后一条记录可以看出,日志占用了8 MB。 PostgreSQL存储此长度的记录没有问题。 PostgreSQL有很好的存储空间,可以记录此类记录。
但是问题是,当应用程序服务器从该表中读取数据时,它们很容易阻塞整个网络带宽,而其他请求也会受到影响。 这是计划数据模式的问题。
对于需要存储两年以上的故事,请使用分区 。 分区有时看起来很复杂-您需要使用创建分区的函数来触发触发器。 在新版本的PostgreSQL中,情况要好一些,现在设置分区要简单得多-一旦完成就可以了。
在考虑的10分钟内删除数据的示例中,
DELETE可以用
DROP TABLE替换-在类似情况下的这种操作仅需几毫秒。
当按分区对数据进行排序时,该分区实际上会在几毫秒内删除,并且操作系统会立即接管工作。 管理历史数据更加容易,轻松和安全。
监控方式
监视是一个单独的大主题,但是从数据库的角度来看,有一些建议可以适合本文的一部分。
默认情况下,许多监视系统都提供对处理器,内存,网络,磁盘空间的监视,但是
通常不会丢弃磁盘设备 。 有关磁盘的负载情况,磁盘上当前的带宽以及延迟值的信息应始终添加到监视中。 这将帮助您快速评估驱动器的加载方式。
PostgreSQL监视选项很多,每种口味都有。 这里有一些要点。
- 关联客户 。 有必要监视他们使用的状态,迅速找到损害数据库的“有害”客户,然后将其关闭。
- 失误 有必要监视错误以跟踪数据库的运行状况:没有错误-很大,已经出现错误-有理由查看日志并开始了解问题所在。
- 请求(声明) 。 我们监视请求的数量和质量特征,以便粗略评估我们是否处理缓慢,冗长或资源密集的请求。
有关更多信息,请参见带有HighLoad ++ Siberia的
“ PostgreSQL监视基础知识”报告和PostgreSQL Wiki中的“
监视”页面。
当我们计划一切并通过监视“发现自己”时,我们仍然会遇到一些问题。
缩放比例
通常,开发人员会在配置中看到数据库行。 他对内部的排列方式(检查点,复制,调度程序的工作方式)并不特别感兴趣。 开发人员已经有事要做-在要做事时,他想尝试很多有趣的事情。
“给我基地的地址,然后给我我自己。” ©匿名开发人员。
当开发人员开始编写在该数据库中工作的查询时,对主题的无知会导致非常有趣的后果。 编写查询时的幻想有时会产生惊人的效果。
有两种类型的交易。
OLTP事务是快速,简短,轻量级的,只需几毫秒的时间。 它们工作很快,并且有很多。
OLAP-分析查询 -缓慢,冗长,繁重,读取大量表并读取统计信息。
在过去的2-3年中,缩写
HTAP经常听起来是-混合事务/分析处理或
混合事务-分析处理 。 如果您没有时间考虑OLAP和OLTP请求的扩展和多样性,则可以说:“我们有HTAP!” 但是经验和错误的痛苦表明,毕竟,由于长的OLAP请求会阻塞轻量级的OLTP请求,因此不同类型的请求毕竟必须彼此分开。
因此,我们提出了如何扩展PostgreSQL以便分散负载的问题,每个人都感到满意。
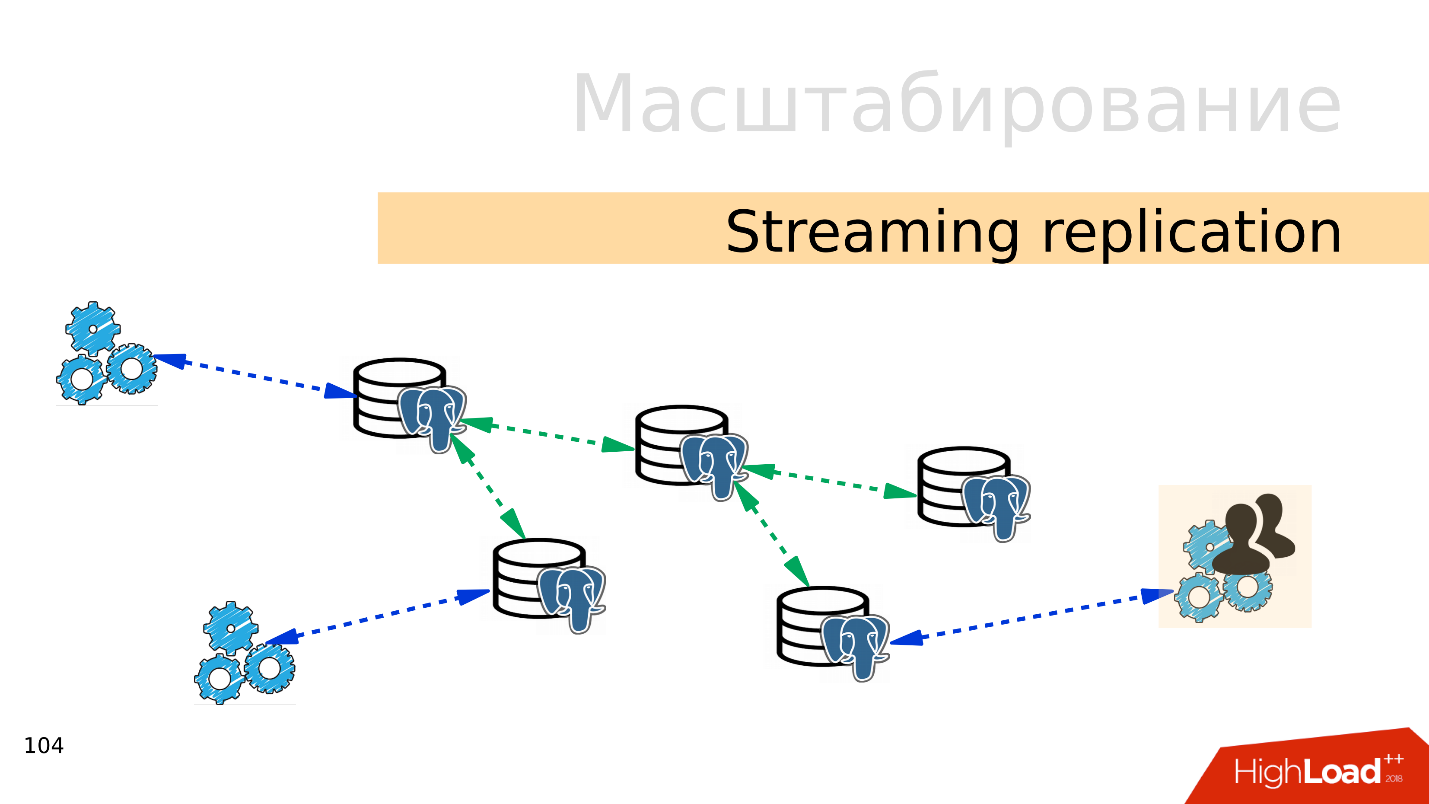
流式复制 。 最简单的选择是
流式复制 。 当应用程序与数据库一起使用时,我们将多个副本连接到该数据库并分配负载。 记录仍归主数据库,并读取副本。 此方法使您可以非常广泛地扩展。
另外,您可以将更多副本连接到单个副本,并获得
级联复制 。 可以将单独的用户组或应用程序(例如,读取分析)移动到单独的副本中。
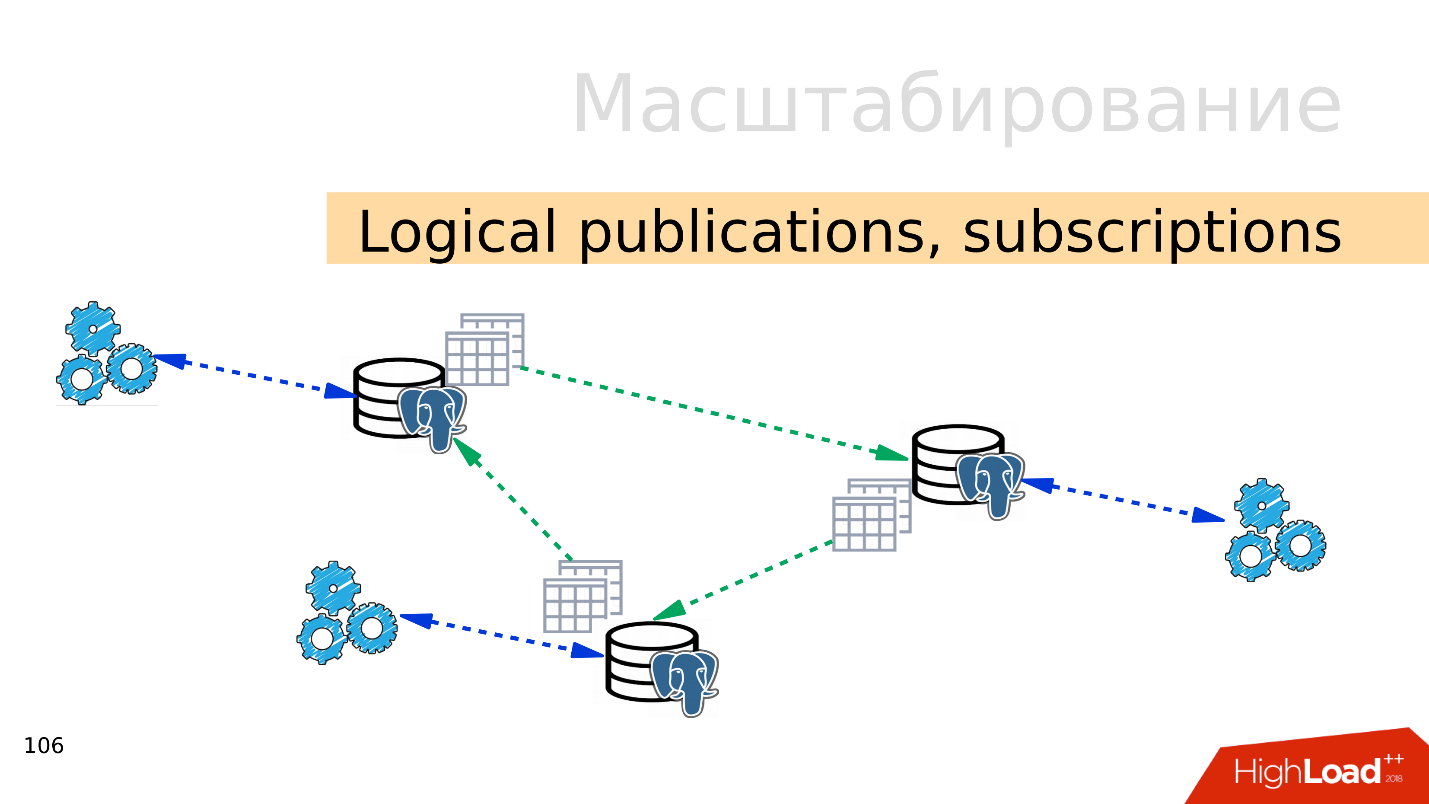
 逻辑发布,订阅
逻辑发布,订阅 -逻辑发布和订阅的机制意味着存在多个具有独立数据库和表集的独立PostgreSQL服务器。 这些表集可以连接到相邻数据库,可以正常使用它们的应用程序将看到它们。 也就是说,源中发生的所有更改都将复制到目标库,并且在此可见。 与PostgreSQL 10。
 外部表,声明性分区-声明性分区和外部表
外部表,声明性分区-声明性分区和外部表 。 您可以使用多个PostgreSQL并在其中创建几组表,这些表将存储所需的数据范围。 这可以是特定年份的数据,也可以是任何范围内收集的数据。
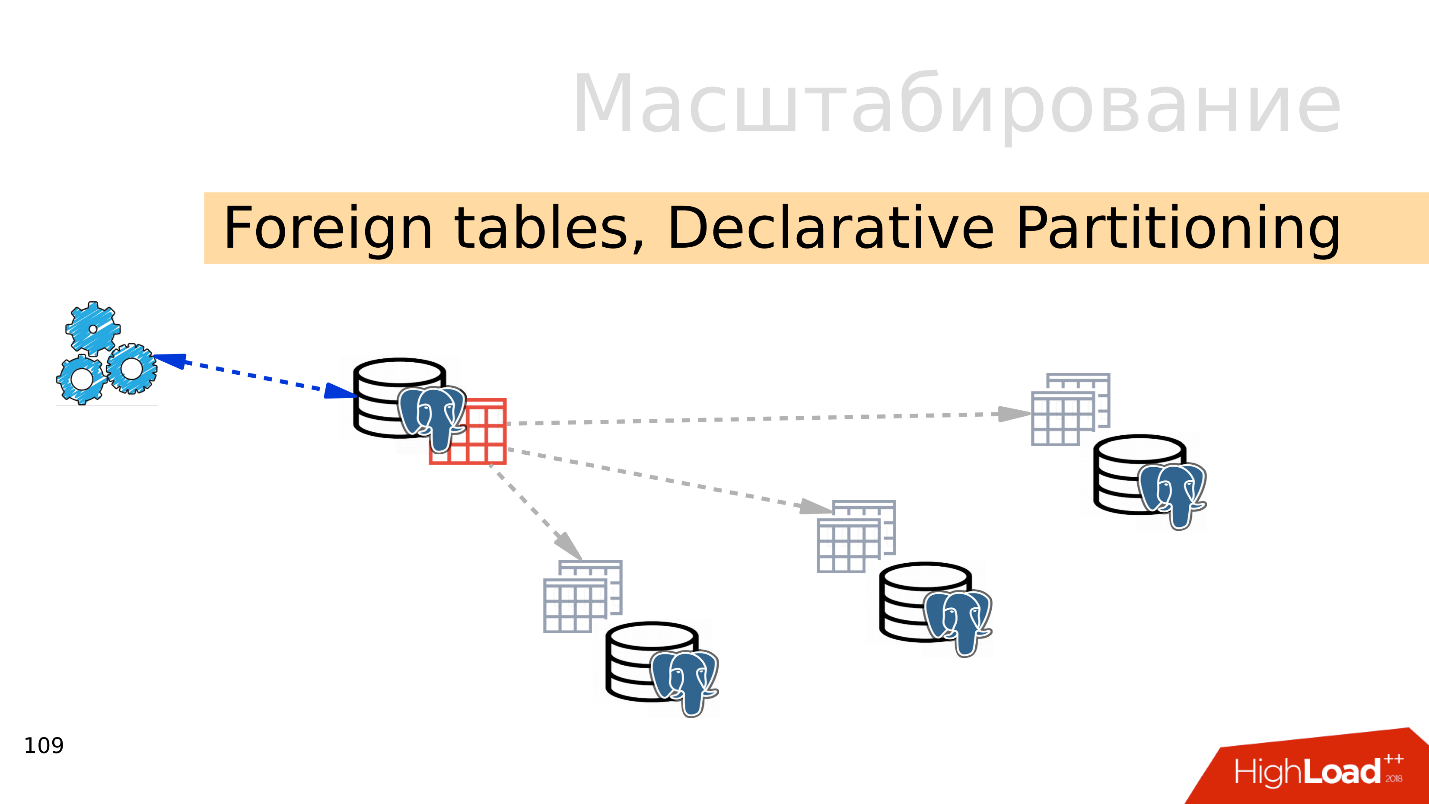
使用外部表机制,可以将所有这些数据库以分区表的形式组合在单独的PostgreSQL中。 应用程序可能已经可以使用该分区表,但是实际上,它将从远程分区读取数据。 当数据量超过单个服务器的功能时,这就是分片。

所有这些都可以组合成扩展的配置,以提供不同的PostgreSQL复制拓扑,但是所有这些如何工作以及如何对其进行管理是另一份报告的主题。
从哪里开始?
最简单的选择是
复制 。 第一步是分散读取和写入的负载。 即,写入主服务器,然后从副本服务器读取。 因此,我们调整了负载并从向导中进行读取。 此外,不要忘了分析师。 分析查询的工作时间很长,它们需要具有单独设置的单独副本,以便较长的分析查询不会干扰其他查询。
下一步是
平衡 。 在开发人员进行操作的配置中,我们仍然有同一行。 他需要一个可以写作和阅读的地方。 这里有几个选项。
理想的方法是
在应用程序本身知道从何处读取数据并知道如何选择副本时,在应用
程序级别实现平衡。 假设始终需要最新的帐户余额,并且需要从主数据库读取帐户余额,并且可以延迟读取产品图片或有关其的信息并从副本中完成。
- 在我看来, DNS Round Robin并不是一个非常方便的实现,因为有时它可以工作很长时间,并且在发生故障转移时在服务器之间切换向导角色时并没有给出必要的时间。
- 一个更有趣的选项是使用Keepalived和HAProxy 。 主代理和副本集的虚拟地址在HAProxy服务器之间引发,并且HAProxy已经在平衡流量。
- Patroni,DCS以及诸如ZooKeeper,etcd,Consul之类的东西-我认为是最有趣的选择。 也就是说,服务发现负责信息,谁现在是主服务器,谁是副本。 Patroni管理PostgreSQL的集群,执行切换-如果拓扑已更改,此信息将出现在服务发现中,并且应用程序可以快速找到当前拓扑。
复制存在细微差别,其中最常见的是
复制滞后 。 您可以像GitLab一样进行操作,并且当滞后现象累积时,只需降低基准值即可。 但是我们有全面的监控-我们会仔细查看并查看多头交易。
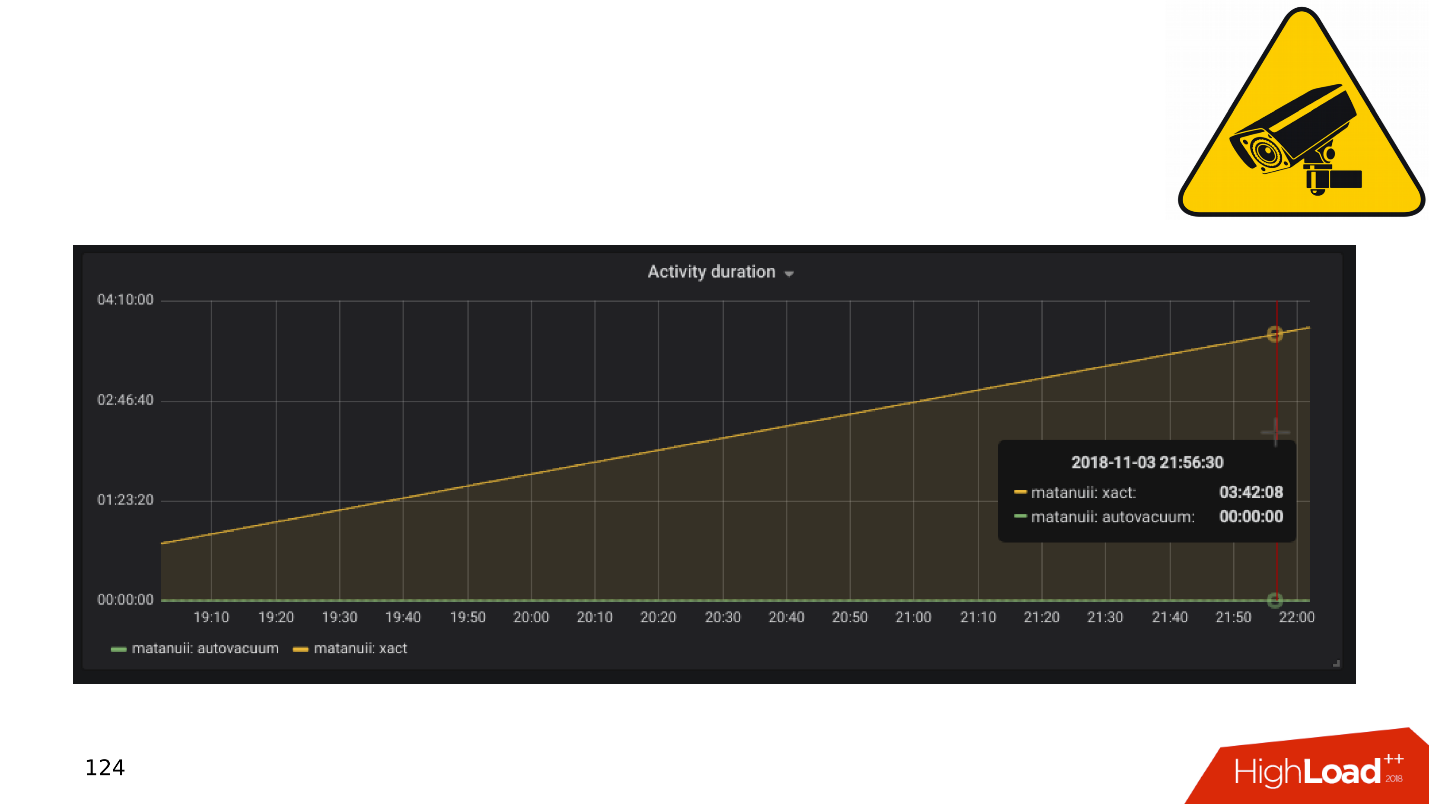
应用程序和DBMS事务
通常,慢速和空闲的事务导致:
- 生产力下降 -并非剧烈痉挛,而是平稳;
- 锁和死锁 ,因为长事务在行上持有锁并阻止其他事务工作;
- 50 *后端出现HTTP错误 ,接口错误或其他错误。
让我们看一下有关这些问题如何产生以及为什么长时间闲置事务机制有害的一些理论。
PostgreSQL具有MVCC-相对而言,是数据库引擎。 它使客户可以竞争性地使用数据而不会互相干扰:读者不会干扰读者,作者不会干扰作者。 当然,有一些例外,但是在这种情况下,它们并不重要。
事实证明,在数据库的一行中,可以有多个版本用于不同的事务。 客户端连接,数据库为他们提供数据快照,并且在这些快照中,可能存在同一行的不同版本。 因此,在数据库的生命周期中,事务被转移,彼此替换,并且出现了行版本,这些行都不需要。
因此,
需要一种垃圾收集器-自动吸尘器 。 存在长事务,并防止自动清理清除不必要的行版本。 此垃圾数据开始从内存到磁盘,从磁盘到内存徘徊。 为了存储此垃圾,浪费了CPU和内存资源。
交易时间越长,垃圾越多,性能也越低。
从“谁应该受到责备?”的角度来看,该应用程序应归咎于长期交易的出现。 如果数据库将自己存在,那么长而无所事事的交易将不会从任何地方进行。 实际上,对于空闲事务,有以下几种选择。
“让我们去找一个外部资源 。
” 该应用程序打开一个事务,在数据库中执行某项操作,然后决定转向外部资源,例如Memcached或Redis,希望它随后将返回数据库,继续工作并关闭事务。 但是,如果外部源发生错误,则应用程序将崩溃,并且事务将保持关闭状态,直到有人注意到并杀死它为止。
没有错误处理 。 另一方面,可能存在处理错误的问题。 当应用程序再次打开事务,解决数据库中的某些问题,返回代码执行,执行一些功能和计算时,才能继续在事务中工作并关闭它。 在进行这些计算时,应用程序操作因错误而中断,代码返回到循环的开始,并且事务再次未关闭。
人为因素 。 例如,一个管理员,开发人员,分析师在某些pgAdmin或DBeaver中工作-打开一个事务,在其中做某事。 然后,这个人分心了,他转向另一项任务,然后转到第三项,忘记了交易,离开了周末,交易继续进行。 基本性能受损。
让我们看看在这些情况下该怎么做。
- 我们有监视;因此,我们需要监视中的警报 。 挂起一个多小时且不执行任何操作的任何事务,都是查看其来源和了解错误的机会。
- 下一步是通过任务中的任务 (pg_terminate_backend(pid)) 拍摄此类事务,或在PostgreSQL配置中进行配置。 需要10到30分钟的阈值,之后交易会自动完成。
- 应用程序重构 。 当然,您需要找出空闲事务来自何处,发生的原因并消除这些地方。
不惜一切代价避免长时间的事务,因为它们会极大地影响数据库性能。
当挂起的任务出现时,一切都会变得更加有趣,例如,您需要仔细计算单位。 我们谈到了自行车制造的问题。
自行车构造
痛的话题。 应用程序端的业务需要执行事件的后台处理。 例如,要计算合计:最小值,最大值,平均值,向用户发送通知,向客户开具发票,注册后设置用户帐户或在相邻服务中注册-进行延迟处理。
这些任务的本质是相同的-将它们推迟到以后。 表出现在仅执行队列的数据库中。

这是任务的标识符,创建任务的时间,更新的时间,采用该任务的处理程序以及完成尝试的次数。 如果您有一张甚至与之相似的表,那么您将拥有
自写队列 。
所有这些都可以正常工作,直到出现长事务为止。 之后,
与队列配合使用的表的大小会增加 。 始终添加新作业,删除旧作业,进行更新-获得具有密集记录的表。 应该定期清除过时版本的字符串,以免影响性能。
处理时间在增加 -长时间的交易会锁定行的过时版本,或者阻止清理行。 当表的大小增加时,处理时间也会增加,因为您需要读取很多带有垃圾的页面。 时间增加了,
排队在任何时候都停止了 。
下面是一个有一个队列的客户的顶部示例。 所有请求都与队列有关。

请注意这些请求的执行时间-除了一个请求外,其他所有请求的工作时间都超过二十秒。
为了解决这些问题,
很早就发明了PostgreSQL的队列管理器
Skytools PgQ 。 不要重新发明您的自行车-拿起PgQ,将它设置一次,而不必理会线路。
没错,他也有特色。 Skytools PgQ的
文档很少 。 阅读官方页面后,人们会觉得自己什么都不懂。 当您尝试做某事时,感觉会增高。 一切正常,但是
如何运作尚不清楚 。 某种绝地魔法。 但是可以在
Mailing-lists中找到很多信息。 这不是一种很方便的格式,但是有很多有趣的东西,您必须阅读这些表。
尽管存在弊端,Skytools PgQ仍遵循“设置并忘记”的原则。
创建了一个触发器函数,该函数挂在我们要用来接收更改的表上,并且一切正常运行。当您需要向队列中添加另一个表时,几乎记得有关PgQ的信息。使用PgQ比支持和设置单个经纪人便宜。如果您面临某人最有可能遇到的任务,请寻找已经发明的工具。对于队列尤其如此。
在我们的实践中,我们看到了许多自写的突发,并用PgQ代替了它们。当然,例如在Avito中有大量的PostgreSQL安装,而其中的PgQ功能还不够。但是这些都是单独决定的情况。自动化技术
, . , , , - , , , . , , , alter.
auto-failover — PostgreSQL - , , . , auto-failover.
Split-brain . PostgreSQL , , — . , . PostgreSQL fencing, Kubernets . - , . Split-brain.

. GitHub Split-brain, .
Cascade failover . , . , .
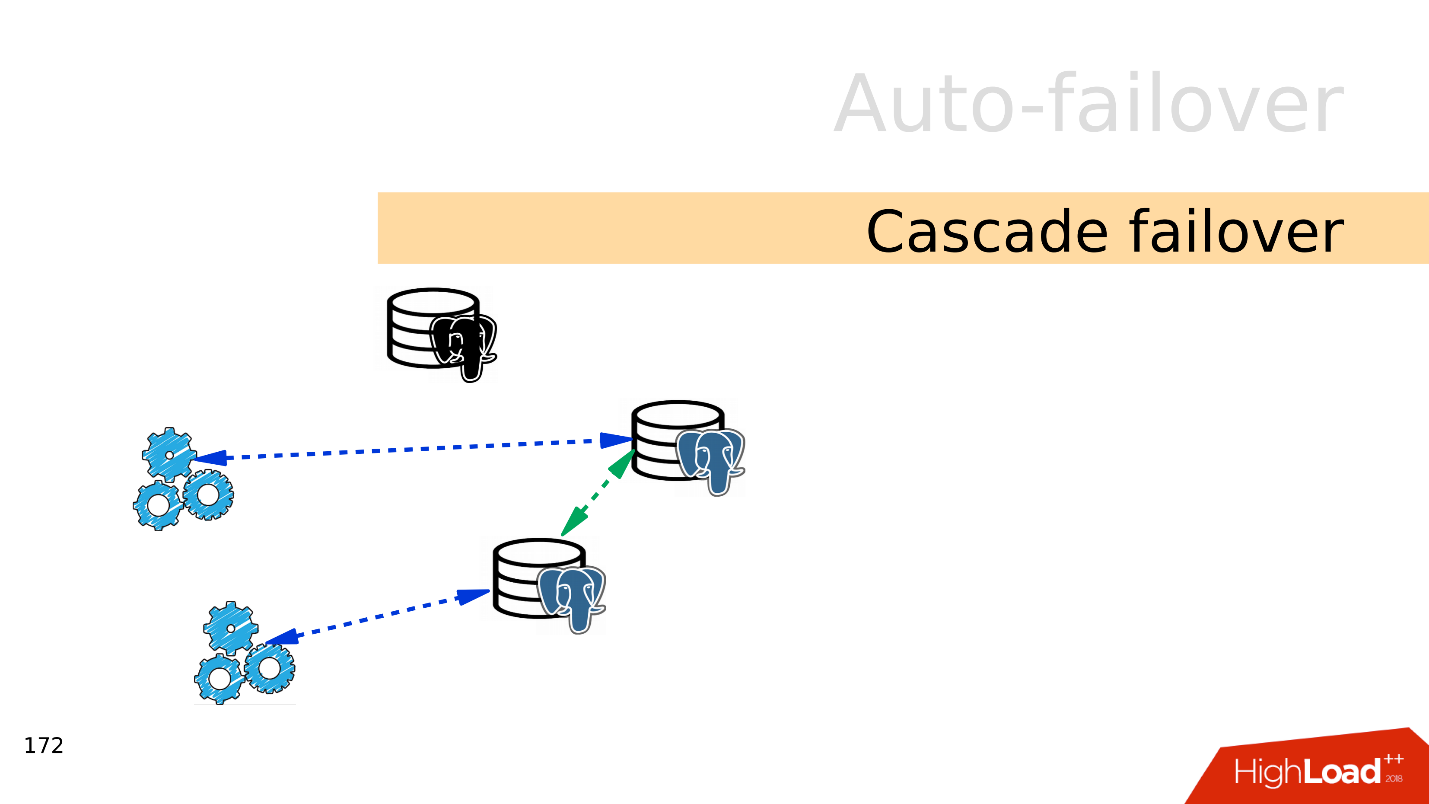
, . , .
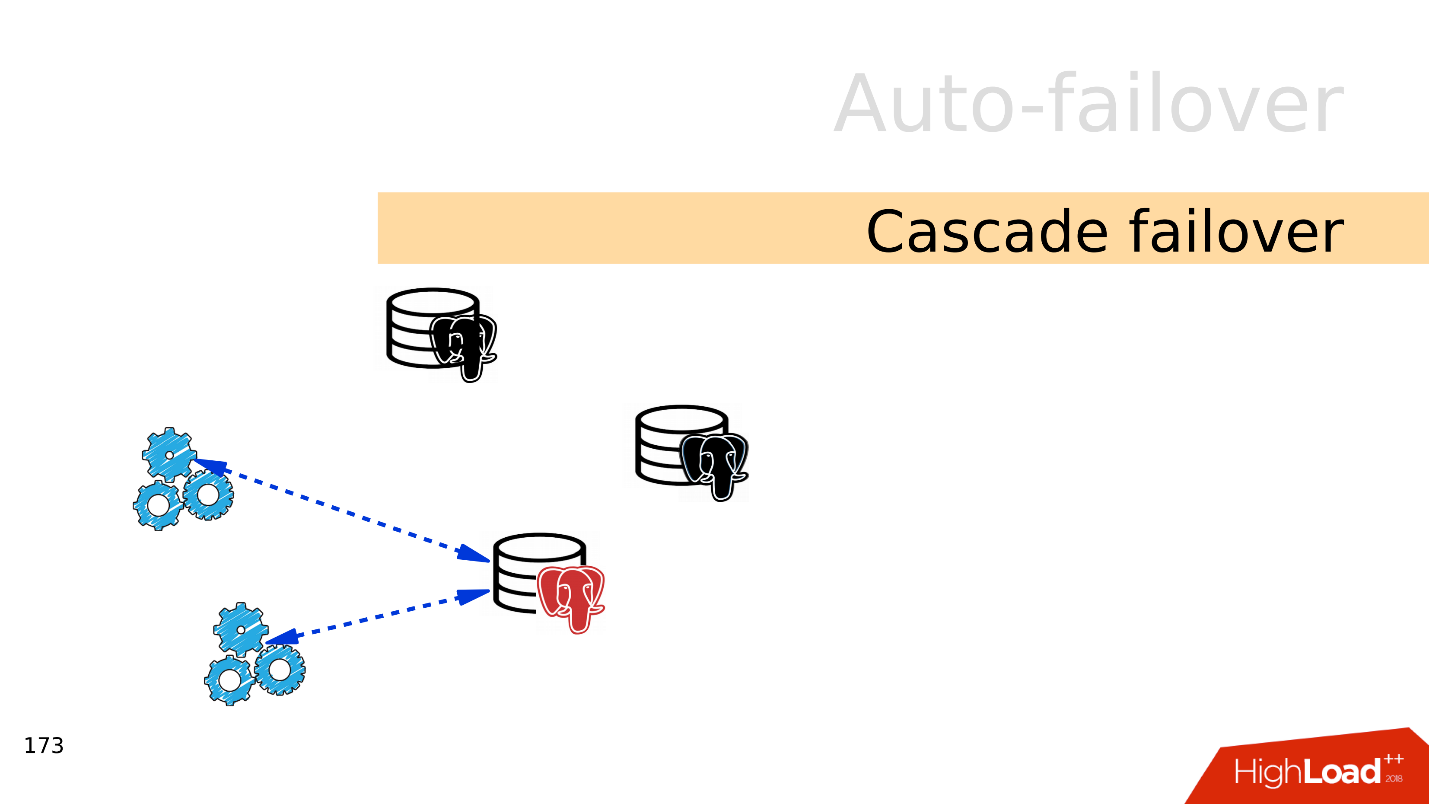
— failover.
auto-failover, .
Bash — , . , , . - , , . .
Ansible playbooks — bash- . , , .
Patroni — , , auto-failover, , service discovery.
PAF —
Pacemaker . auto-failover PostgreSQL, Pacemaker.
Stolon . Kubernetes, . Stolon Patroni, .
Docker Kubernetes . , .
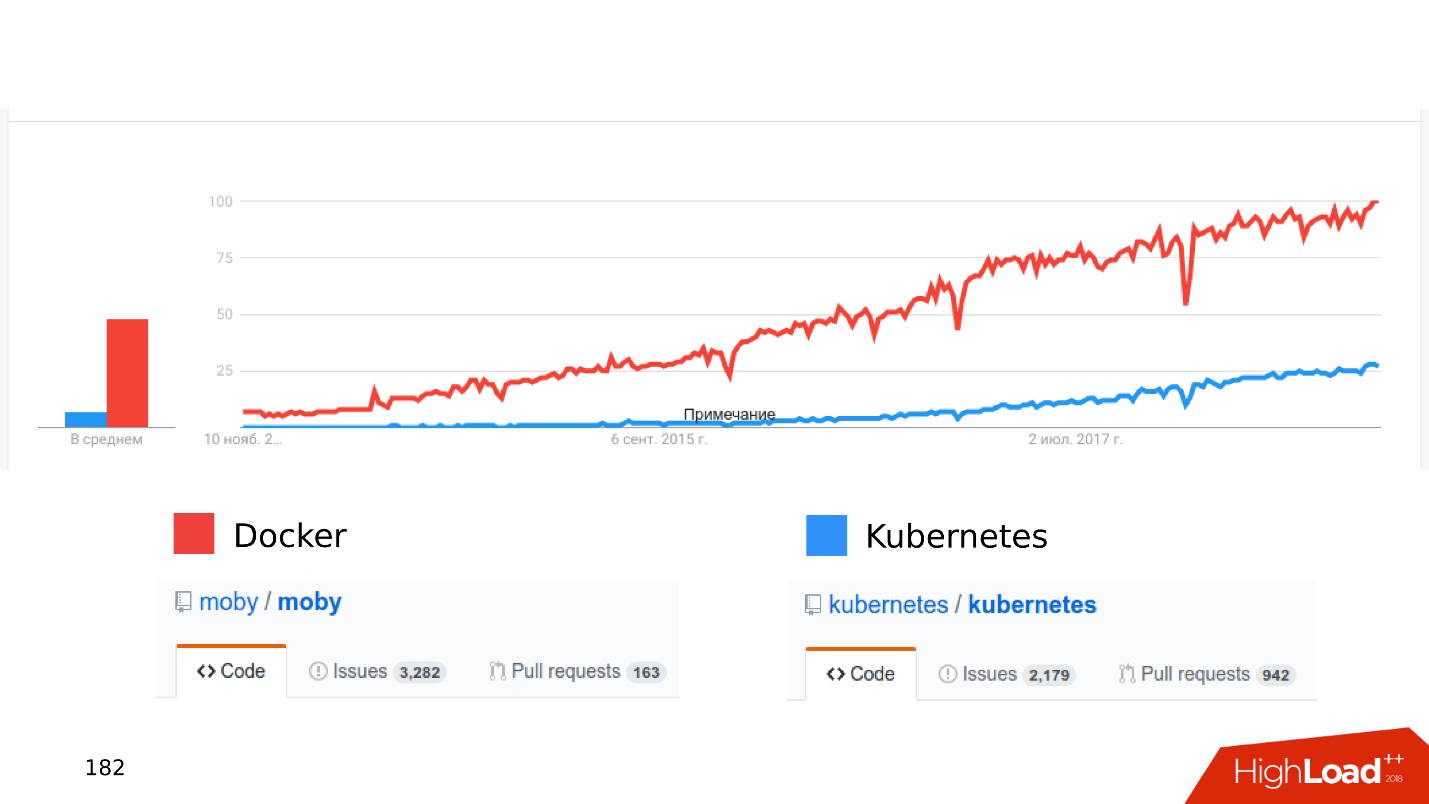
, .
« Kubernetes...» .
— stateful , - . 在哪 . Open Source: CEPH, GlusterFS, LinStor DRBD. , , , .
—
. , Kubernetes, CEPH. — . , .
- , .
- latency . latency — .
- . Kubernetes , - . , shared storage Kubernetes, . - .
, Kubernetes Docker staging dev- . , , Kubernetes .
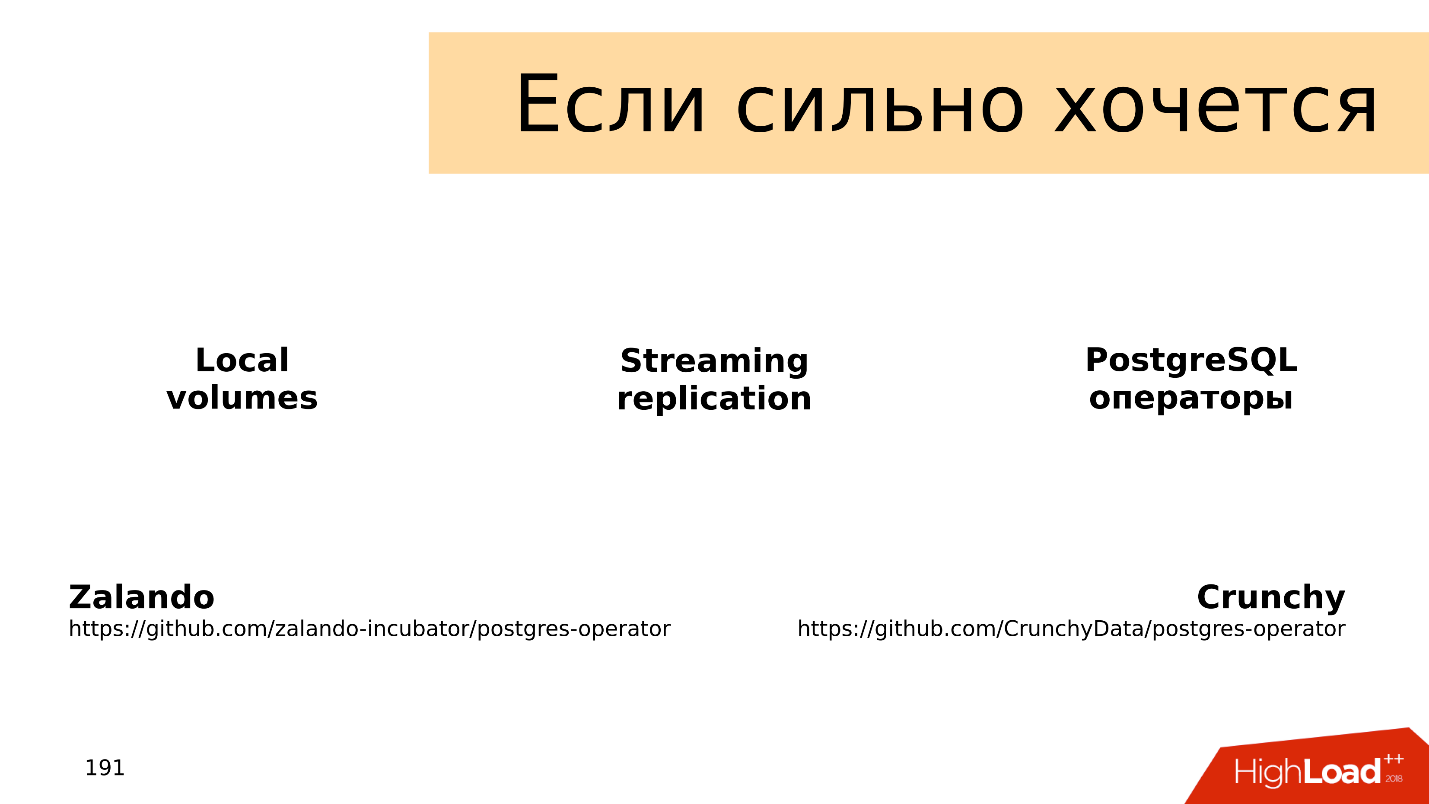
,
local volumes — ,
streaming replication — ,
PostgreSQL- , — , . :
Zalando Crunchy .
, . issues pull requests. , , .
总结
SSD — , .
. JSON 8 — , .
, . PostgreSQL, .
— Postgres is ready . . PostgreSQL , . :
streaming replication; publications, subscriptions; foreign Tables; declarative partitioning .
. , .
-, , —
. . , Skytools PgQ!
Kubernetes, local volumes, streaming replication PostgreSQL . - , , .
. , 24 25 HighLoad++ Siberia , , . 38 — !